






数据准备
这边使用的数据来源:kaggle官网。
具体的数据有:训练数据8000张,猫和狗各4000张;验证数据2000张,猫和狗各1000张。
数据放置位置:D:\cat_dog\data\cat and dog
在cat and dog文件夹内分出train 和validation 两个子文件夹。

在train文件夹内需将4000张猫的图像放入cats内,4000张狗的图像放入dogs内。同样的validation内放1000张猫的图像放入cats内,1000张狗的图像放入dogs内。

做好这些数据准备后,开始写代码。
未数据增强的代码
未数据增强的
import os
import warnings
warnings.filterwarnings("ignore")
import tensorflow as tf
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# 数据所在文件夹
base_dir = 'D:\cat_dog\data\cat and dog'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
# 训练集
train_cats_dir = os.path.join(train_dir, 'cats')
train_dogs_dir = os.path.join(train_dir, 'dogs')
# 验证集
validation_cats_dir = os.path.join(validation_dir, 'cats')
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(128, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
# 为全连接层准备
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
# 二分类sigmoid就够了
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.summary()
model.compile(loss='binary_crossentropy',
optimizer=Adam(lr=1e-4),
metrics=['acc'])
# 归一化处理
train_datagen = ImageDataGenerator(rescale=1. / 255)
test_datagen = ImageDataGenerator(rescale=1. / 255)
# 训练数据的生成器
train_generator = train_datagen.flow_from_directory(
train_dir, # 文件夹路径
target_size=(64, 64), # 统一图片数据大小,要与CNN输入大小一致
batch_size=10, # 分批次训练
# 二分类用binary就可以
class_mode='binary')
#验证数据的生成器
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(64, 64),
batch_size=10,
class_mode='binary')
# fit是数据放入内存中,generator是一个生成器,动态产生数据
history = model.fit_generator(
train_generator,
steps_per_epoch=800, # 8000 images = batch_size * steps
epochs=50,
validation_data=validation_generator,
validation_steps=200, # 2000 images = batch_size * steps
verbose=2)
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training accuracy')
plt.plot(epochs, val_acc, 'b', label='Validation accuracy')
plt.title('Training and validation accuracy')
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training Loss')
plt.plot(epochs, val_loss, 'b', label='Validation Loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
运行之后的结果图为:
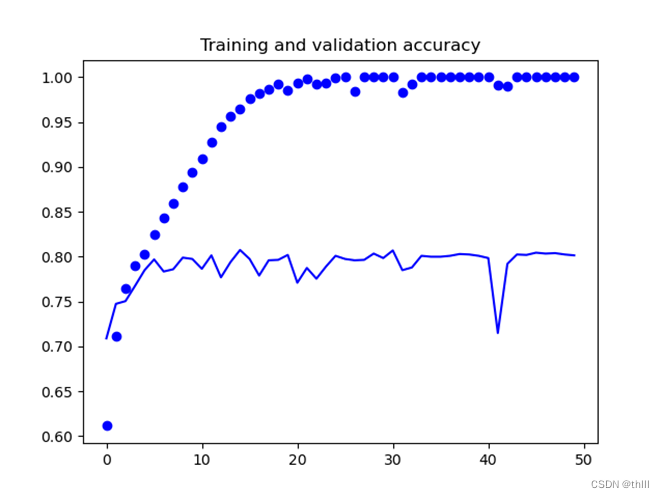
运行结果出现了过拟合现象。下面采用数据增强和加入dropout层缓解过拟合现象。
数据增强后的代码
增强后的代码:
import os
import warnings
warnings.filterwarnings("ignore")
import tensorflow as tf
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# 数据所在文件夹
base_dir = 'D:\cat_dog\data\cat and dog'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
# 训练集
train_cats_dir = os.path.join(train_dir, 'cats')
train_dogs_dir = os.path.join(train_dir, 'dogs')
# 验证集
validation_cats_dir = os.path.join(validation_dir, 'cats')
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(128, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
# 为全连接层准备
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
# 二分类sigmoid就够了
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.summary()
model.compile(loss='binary_crossentropy',
optimizer=Adam(lr=1e-4),
metrics=['acc'])
train_datagen = ImageDataGenerator(
rescale=1. / 255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
test_datagen = ImageDataGenerator(rescale=1. / 255)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(64, 64),
batch_size=10,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(64, 64),
batch_size=10,
class_mode='binary')
history = model.fit_generator(
train_generator,
steps_per_epoch=800, # 8000 images = batch_size * steps
epochs=80,
validation_data=validation_generator,
validation_steps=200, # 2000 images = batch_size * steps
verbose=2)
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training accuracy')
plt.plot(epochs, val_acc, 'b', label='Validation accuracy')
plt.title('Training and validation accuracy')
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training Loss')
plt.plot(epochs, val_loss, 'b', label='Validation Loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()采用数据增强后的结果图:
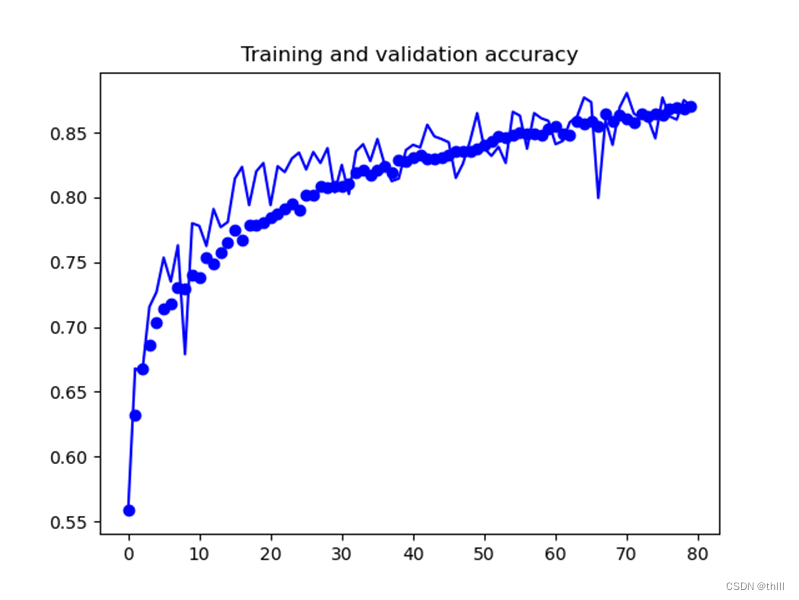
再加入dropout层:
加入dropout层的代码
加入dropout层
import os
import warnings
warnings.filterwarnings("ignore")
import tensorflow as tf
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# 数据所在文件夹
base_dir = 'D:\cat_dog\data\cat and dog'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
# 训练集
train_cats_dir = os.path.join(train_dir, 'cats')
train_dogs_dir = os.path.join(train_dir, 'dogs')
# 验证集
validation_cats_dir = os.path.join(validation_dir, 'cats')
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(128, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
# 为全连接层准备
tf.keras.layers.Flatten(),
#退出层
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(512, activation='relu'),
# 二分类sigmoid就够了
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.summary()
model.compile(loss='binary_crossentropy',
optimizer=Adam(lr=1e-4),
metrics=['acc'])
train_datagen = ImageDataGenerator(
rescale=1. / 255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
test_datagen = ImageDataGenerator(rescale=1. / 255)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(64, 64),
batch_size=10,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(64, 64),
batch_size=10,
class_mode='binary')
history = model.fit_generator(
train_generator,
steps_per_epoch=800, # 8000 images = batch_size * steps
epochs=150,
validation_data=validation_generator,
validation_steps=200, # 2000 images = batch_size * steps
verbose=2)
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training accuracy')
plt.plot(epochs, val_acc, 'b', label='Validation accuracy')
plt.title('Training and validation accuracy')
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training Loss')
plt.plot(epochs, val_loss, 'b', label='Validation Loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()运行结果为:
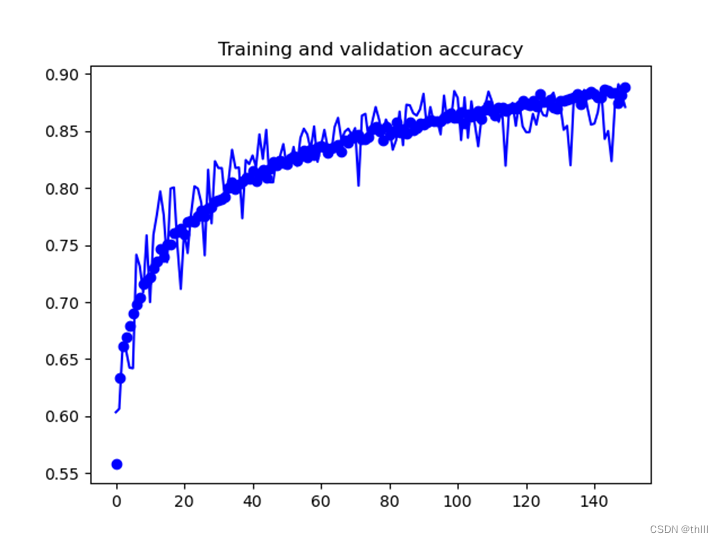
具体的代码如上(原理不想解释了,啊啊啊
运行的环境需要:GPU、Windows10、Python:3.9.13、Anaconda:1.11.0、Conda:22.9.0、Tensorflow:2.10.0、Torch:2.0.0、Keras:2.4.3)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









