






概念
聚类中的样本都没有对应的类别,通过观察样本的特点,根据特点的亲密度,将亲密度高的划分为一组,分成几个组,每个组之间的亲密度低。专业名词称为:类内聚力和类间距离。聚类是一种无需标记训练样本的机器学习方法,K-means聚类是常用的无监督的基本聚类算法。
原理
采用循环迭代法,以聚类结果的损失函数最小为目标,寻找K个类别。类别也称为“簇”(Cluster)。其中,损失函数可通俗理解为该点分到此类中与自身作为一个类别的损失,可以定义为各个样本与类别中心点之间距离大小的平方和:
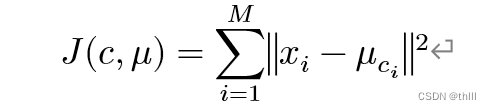
式中:
xi代表第i个样本;
ci是xi所属的簇;
μci 代表簇对应的中心点;
M 是样本总数。
操作流程
K-Means的主要目的是把一个已知的数据集合划分为K 个类(K 为根据需求设定的值),然后给出每个类的中心位置。下列四点为操作流程:
1、数据预处理。将数据标准化、异常点过滤。
2、随机选取K 个中心,记为μ10,μ20…μk0
3、定义损失函数:
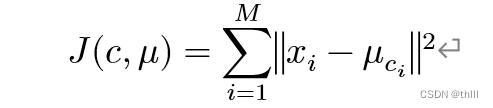
4、令迭代步数t=0,1,2,....,重复如下过程直到损失函数收敛:
4.1、对于每一个样本xi ,将其分配到距离最近的中心
![]()
4.2、对于每一个类中心k,重新计算该类的中心
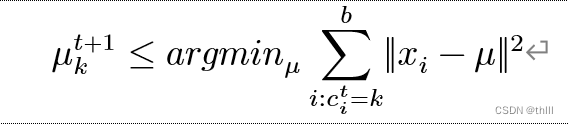
K均值法的关键在于使J 单调地降低至最(极)小值,且中间点与样本分类的类同时收敛。首先确定中心点,然后对每一个样本进行分类,从而减小J 值;再把每一个样品的类都固定下来,然后调节中间的点,继续缩小J 。这两种方法相互循环,即可达到目的。
优化
1、数据预处理:归一化和异常点过滤
由于离群点的存在,会严重影响平均线的计算,从而使中心发生偏离,因此,对于存在噪声的样本,应事先进行滤波处理,再进行分类。K-Means实质上是以欧几里得测度为基础得一种分类法,其分类法中最大得维数和最大得变数对分类法得效果有很大得影响。因此,在进行聚类之前,必须对所有的数据进行标准化,并且将所有的属性都统一起来。
2、合理选择K值
K值的选择一般基于实验和多次实验结果。
(1)拐点法(肘法):就是在k值不同的情况下,求出各种偏差的平方和,当 k值增大时,类中得点就会减少,离差平方和会逐渐变小,离差平方和的大小变化的斜率是考虑的对象,当斜率突然由大变小时,且之后趋于平稳,则认为拐点的k值为合适k值。
(2)轮廓系数法:该方法综合考虑了类的密集性和类间的分散性等于(类间距离的最大值-类内的平均距离)/(类间距离的最大值-类内的平均距离);很明显该值小于0时表明聚类很不合理,很多样本混淆了;值为0时表明样本落在了模糊地带;值趋近于1时表明聚类效果时比较好的。
3、改进初始值的选择
在随机选择K个中心的做法中,有一定的概率会导致不同类别的中心点距离很近,损失函数需要更多的迭代次数才能收敛。在选择初始中心点时尽可能让不同中心点距离较大,会达到更好的效果。















 672
672











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









