






Linux中的spinlock机制[三] - qspinlock - 知乎
上文说到,MCS lock可以解决在锁的争用比较激烈的场景下,cache line无谓刷新的问题,但它内含一个指针,所以更消耗存储空间,但这个指针又是不可或缺的,因为正是依靠这个指针,持有spinlock的CPU才能找到等待队列中的下一个节点,将spinlock传递给它。本文要介绍的qspinlock,其首要目标就是把原生的MCS lock结构体进行改进,「塞」进4字节的空间里。
【MCS Lock的改进 - qspinlock】
先来看一下有3个以上的CPU持有或试图获取spinlock时,等待队列的全貌:
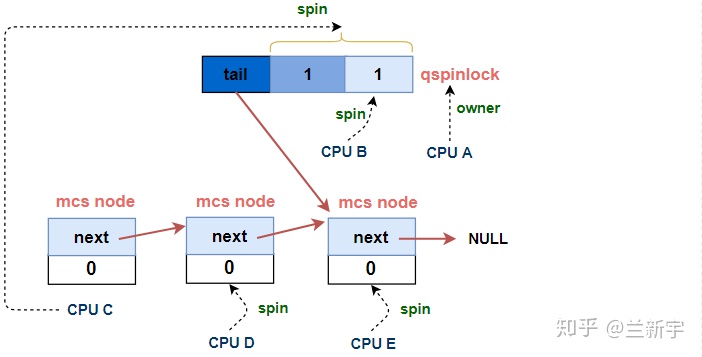
可见,这个等待队列是由一个qspinlock和若干个MCS lock节点组成的,或者说由一个qspinlock加上一个MCS node的队列组成,其中MCS node的队列和上文描述的那个队列基本是一样的,所以我们重点先来看下这个qspinlock是如何构成的(定义在/include/asm-generic/qspinlock_types.h):
typedef struct qspinlock {
union {
atomic_t val;
#ifdef __LITTLE_ENDIAN
struct {
u8 locked;
u8 pending;
};
struct {
u16 locked_pending;
u16 tail;
};
#else
...
}
}
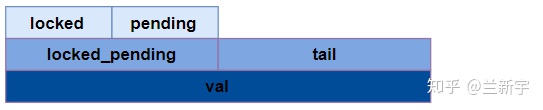
这里使用的是union,目的是既可以直接引用结构体的位域,又可以直接引用整个变量。如果处理器采用的是little endian,那么它们的内存排布关系如下图所示:
如果采用的是big endian,其内存排布则是这样的:

以32位系统为例,"val"作为一个32位的变量,包含了三个部分:"locked byte", "pending"和"tail","tail"又细分为"tail index"和"tail cpu":

下面来说一下这几个部分各自代表什么含义。
MCS lock中表示是否持有锁的"locked"占据了32个bits,但它其实只需要表示0和1两个值,在qspinlock中被压缩成了8个bits,即"locked byte"(其实只需要1个bit)。
此外,MCS lock的结构体中没有专门的标识等待队列末尾的元素,它使用的是一个全局的二级指针来指向队列末尾。而qspinlock使用的是一个per-CPU的数组来表示每个MCS node(用qnode结构体表示),通过CPU编号作为数组的index,就可以获得对应 MCS node的内存位置,因而qspinlock使用的是末尾 MCS node的CPU编号加1,即"tail cpu",来记录等待队列tail的位置(加1的原因将在后面解释)。
struct qnode {
struct mcs_spinlock mcs;
};
DEFINE_PER_CPU_ALIGNED(struct qnode, qnodes[MAX_NODES]);
除了14个bits的"tail cpu"(针对CPU数目小于16K的情况),还有2个bits是用作"tail index",这是因为Linux中一共有4种context,分别是task, softirq, hardirq和nmi,而一个CPU在一种context下,至多试图获取一个spinlock(原因将在下文给出),因而一个CPU至多同时试图获取4个spinlock,"tail index"就是用来标识context的编号的。
以上说的两点是qspinlock在MCS lock已有元素的基础上进行的改进,相比于MCS lock,qspinlock还新增了一个元素:占据1个bit的"pending",它的作用将随着本文叙述的推进,慢慢揭晓。
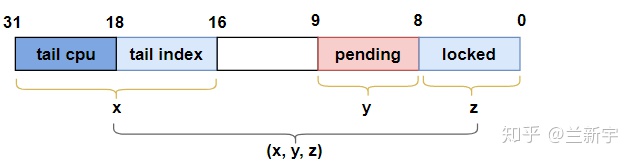
为了方便演示,我们把一个"val"对应的"locked", "pending"和"tail"作为一个三元组"(x,y,z)"来表示:
- 加锁
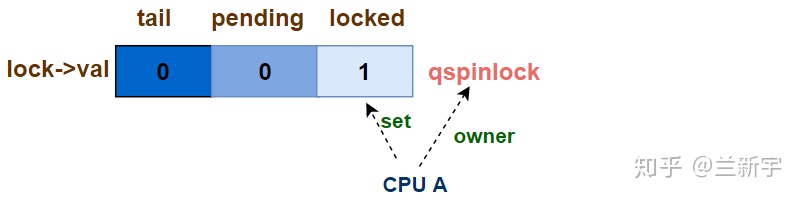
第一个CPU试图获取锁 - uncontended
三元组的初始值是(0, 0, 0),当第一个CPU试图获取锁时,可以立即成为该spinlock的owner,此时三元组的值变为(0, 0, 1):
对应的代码实现是queued_spin_lock()的前半部分(位于/include/asm-generic/qspinlock.h):
#define _Q_LOCKED_OFFSET 0
#define _Q_LOCKED_VAL (1U << _Q_LOCKED_OFFSET)
void queued_spin_lock(struct qspinlock *lock)
{
// (0,0,0) --> (0,0,1)
u32 val = atomic_cmpxchg_acquire(&lock->val, 0, _Q_LOCKED_VAL);
if (likely(val == 0))
return;
queued_spin_lock_slowpath(lock, val);
}
通过"cmpxchg()",和当前lock的"val"值进行比较,看是否为0,如果为0,那么获得spinlock,同时将lock的值设为1(即_Q_LOCKED_VAL)。
第二个CPU试图获取锁 - pending
在第一个CPU未释放锁之前,如果有第二个CPU试图获取锁,那么它必须等待,因而其获取锁的过程被称为"slow path",对应的代码实现是queued_spin_lock_slowpath()中的[part 1](该函数的完整实现在源代码中超过200行,本文是做了适当简化,并拆成几个部分来分开讲解)。
#define _Q_LOCKED_OFFSET 0
#define _Q_LOCKED_BITS 8
#define _Q_LOCKED_MASK ((1U << _Q_LOCKED_BITS) - 1) << _Q_LOCKED__OFFSET // (*,*,1)
// "val"是在queued_spin_lock中获取的当前lock的值
void queued_spin_lock_slowpath(struct qspinlock *lock, u32 val)
{
[part 2 - 第三个CPU试图获取spinlock]
...
goto queue; // 跳转到part 3
...
[part 1 - 第二个CPU试图获取spinlock]
// 设置pending位 (0,0,1) --> (0,1,1)
val = queued_fetch_set_pending_acquire(lock);
// 等待第一个CPU移交
if (val & _Q_LOCKED_MASK)
atomic_cond_read_acquire(&lock->val, !(VAL & _Q_LOCKED_MASK));
// 第二个CPU成功获取spinlock (0,1,0) --> (0,0,1)
clear_pending_set_locked(lock);
return;
[part 3 - 进入MCS lock队列]
queue:
...
[part 4 - 第三个CPU成功获取spinlock]
locked:
...
}
它首先通过queued_fetch_set_pending_acquire()函数设置"pending"为1,然后调用atomic_cond_read_acquire()函数,开始基于"locked byte"进行等待(或者说"spin"),此时三元组的值变为(0, 1, 1)。
像atomic_cond_read_acquire()这种函数,其实就是Linux中的原子操作这篇文章介绍的atomic_read()加上"cond"和"acquire",其中"cond"代表condition,表示spin基于的对象,而"acquire"用于设置Memory Barrier。这是为了保证应该在获取spinlock之后才能执行的代码,不要因为Memory Order的调换,在成功获取spinlock之前就执行了,那样就失去了保护Critical Section/Region的目的。
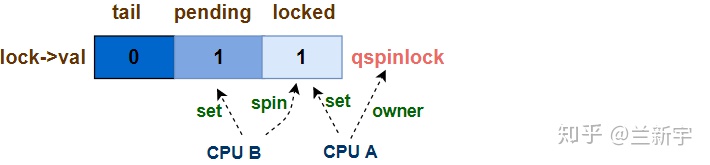
这第二个CPU可被视作是该spinlock的第一顺位继承人,可以做一个这样的类比:"locked byte"位域相当于是皇宫,而"pending"位域相当于是东宫,第二个CPU就是太子(假设按照立长的原则,先来后到),设置"pending"为1就相当于入主东宫,等待着继承大统。
皇帝大行之后(第一个CPU释放spinlock),皇位暂时空缺,三元组的的值变为(0, 1, 0)。之后,曾经的太子离开居住的东宫(将"pending"置0),进入皇宫,成为其新的主人(将"locked byte"置1)。这一过程对应的函数实现就是clear_pending_set_locked()。
第三个CPU试图获取锁 - uncontended queue
如果第二个CPU还在等待的时候,第三个CPU又来了,那么这第三个CPU就成了第二顺位继承人。它的等待路径的实现位于queued_spin_lock_slowpath()的[part 2]:
#define _Q_PENDING_OFFSET 8
#define _Q_PENDING_VAL (1U << _Q_PENDING_OFFSET) // (0,1,0)
[part 2A]
// (0,1,0)是spinlock移交的过渡状态
if (val == _Q_PENDING_VAL) {
// 等待移交完成 (0,1,0) --> (0,0,1)
int cnt = 1
val = atomic_cond_read_relaxed(&lock->val, (VAL != _Q_PENDING_VAL)|| !cnt--);
}
[part 2B]
// 已经有2个及以上的CPU持有或试图获取spinlock
if (val & ~_Q_LOCKED_MASK)
goto queue; // 进入MCS node队列
皇宫只有一个,东宫也只有一个,对于第二顺位继承人的王子来说,只能先去宫城外面自建府邸了。对应代码的实现就是[part 2B]的"goto queue",创建一个MCS node。
但前面提到,三元组的值为(0, 1, 0)时(即_Q_PENDING_VAL),是一个「政权移交」的过渡状态,此时第一顺位继承人即将成为spinlock新的持有者,那么作为第二顺位继承人,也即将递进成为第一顺位继承人,所以如果遇到了这个特殊时期,这第三个CPU会选择使用atomic_cond_read_relaxed()函数,先稍微等一会儿(即[part 2A]部分的代码)。
如果在它第二次读取"lock->val"的值时,已经不再是(0, 1, 0),说明移交已完成,变成了(0, 0, 1),那么它将绕过[part 2B],执行[part 1]的代码(也就是第二个CPU曾经走过的路)。
进入MCS node队列
(0, 1, 0)的状态毕竟是特例,大部分情况下,代码还是会跳转到名为"queue"的label位置,开始在MCS lock队列中的活动,对应的代码实现是queued_spin_lock_slowpath()的[part 3]。
首先是从前面提到的per-CPU的qnode[]数组中获取对应的MCS node,并初始化这个node,其中"idx"即表示context编号的"tail index"。
queue:
[part 3A]
struct mcs_spinlock *node = this_cpu_ptr(&qnodes[0].mcs);
int idx = node->count++;
node += idx;
node->locked = 0;
node->next = NULL;
然后是调用encode_tail()将自己的CPU编号和context编号「揉」进"tail"里,并通过xchg_tail()让qspinlock(即"lock")的"tail"指向自己。前面提到,"tail CPU"是CPU的编号加1,因为对于编号为0,tail index也为0的CPU,如果不加1,那么算出来的"tail"值就是0,而"tail"为0表示当前没有MCS node的队列。
[part 3B]
u32 tail = encode_tail(smp_processor_id(), idx);
// (p,1,1) -> (n,1,1)
u32 old = xchg_tail(lock, tail);
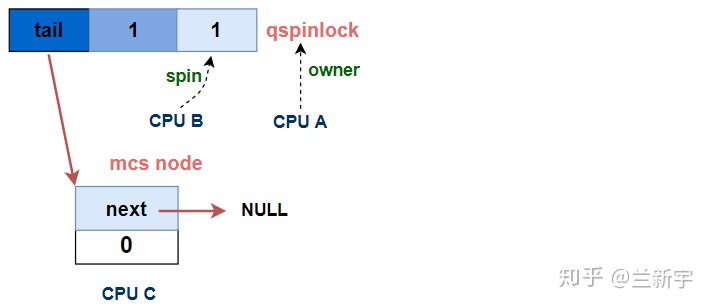
这里没有画出CPU C是基于哪个对象进行spin的,接下来的一节会给出答案。
第N个CPU试图获取锁 - contended queue
xchg_tail()除了在qspinlock中设置新的tail值,还返回了qspinlock中之前存储的tail值(即"old")。对于第N个(N > 3)试图获取spinlock的CPU,之前的tail值是指向上一个MCS node的,获得上一个node的目的是让它的"next"指向自己,这样才能加入MCS node的等待队列。
struct mcs_spinlock *prev, *next, *node;
[part 3C]
// 如果MCS node队列不为空 - 第N个CPU
if (old & _Q_TAIL_MASK) {
// 解析tail值,获取上一个MCS node
prev = decode_tail(old);
// 让上一个node指向自己,加入等待队列
WRITE_ONCE(prev->next, node); // prev->next = node
// 基于自己的locked值进行spin,在[part 4]中解除
arch_mcs_spin_lock_contended(&node->locked);
}
[part 3D]
#define _Q_LOCKED_PENDING_MASK (_Q_LOCKED_MASK | _Q_PENDING_MASK)
// 自己是MCS node队列的第一个节点 - 第二顺位继承
val = atomic_cond_read_acquire(&lock->val, !(VAL & _Q_LOCKED_PENDING_MASK));
加入MCS node组成的队列后,这第N个CPU会基于自己node的"locked"进行spin,这就完全回到了上文描述的MCS lock的路径里了。
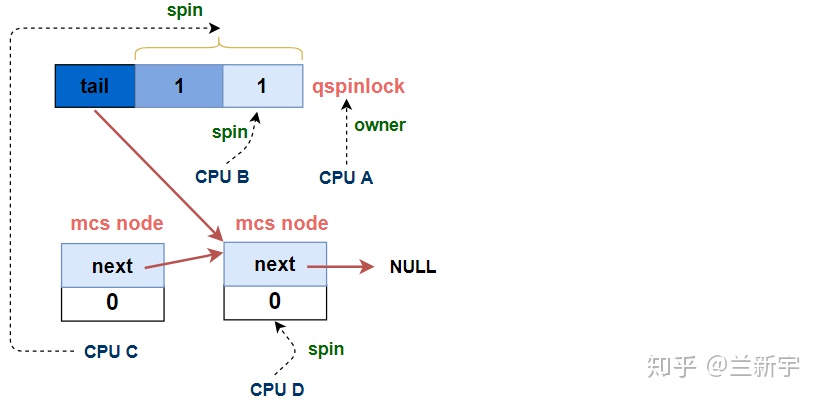
[part 3D]中的这个atomic_cond_read_acquire()函数,在本文已经是第二次出现了,上一次是在[part 1]里,所不同的是,[part 1]里是第二个CPU(第一顺位继承人,CPU B)基于代表「大位」的qspinlock的"locked byte"进行spin,而这里是第三个CPU(第二顺位继承人,CPU C)基于qspinlock的"locked byte"加上代表「嗣位」的"pending"进行spin。
也就是说,当第一顺位继承人获得spinlock,空出嗣位后,如果第二顺位继承人已经建立了MCS node,那它并不会马上占据嗣位,而是要等到CPU B也释放了spinlock,"locked byte"和"pending"都为0时,才直接获取spinlock。
[part 3D]是放在第N个CPU试图获取spinlock的代码位置之后的,说明第N个CPU在解除基于自己node的"locked"的spin之后,也会执行这段代码,原因在接下来介绍完[part 4]的代码之后,将会自然地浮出水面。
第三个CPU成功获取锁
经过等待,当qspinlock的"locked byte"和"pending"都变为0时,第三个CPU总算熬出头了,它终于可以结束spin,获取这个spinlock。
[part 4]
locked:
// 唯一node, 直接获取锁 (n,0,0) --> (0,0,1)
if (((val & _Q_TAIL_MASK) == tail) &&
atomic_try_cmpxchg_relaxed(&lock->val, &val, _Q_LOCKED_VAL))
goto release;
// 如果MSC node队列中还有其他node (n,0,0) --> (n,0,1)
set_locked(lock);
// 解除下一个node在MCS node队列中的spin
arch_mcs_spin_unlock_contended(&node->next->locked);
release:
__this_cpu_dec(mcs_nodes[0].count);
如果qspinlock的"tail"是指向自己的,说明它是当前MCS node队列中唯一的node,那么直接通过atomic_try_cmpxchg_relaxed()获取spinlock即可,三元组的值变为(0, 0, 1)。
如果不是,说明队列中还有其他的node在等待,那么按照上文描述的MCS node队列的规则,需要调用arch_mcs_spin_unlock_contended()函数,设置下一个node(CPU D)的"locked"为1。
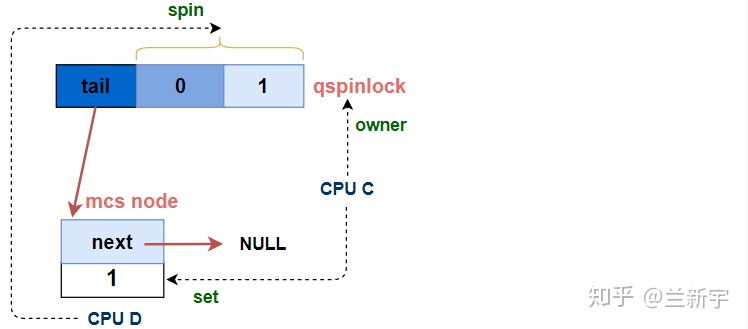
当CPU C获取spinlock,离开MCS node队列后,CPU D就成为了MCS node队列中的第一个node,它的"locked"也被CPU C设为了1。在上文描述的MCS lock实现中,"locked"为1就意味着spinlock被上一个owner递交给了自己。但在这里,"locked"为1只是结束了在MCS node队列中的的spin。
结束在MCS node队列中的的spin后,意味着CPU D在前面[part 3C]中的等待就结束了,它将执行[part 3D]的代码,切换为第二顺位继承人进行spin应该基于的对象,即qspinlock的"locked byte"加上"pending"(和之前的CPU C一样)。
可见,对于第N个(N > 3)CPU来说,从它加入MCS node等待队列,到最终成功获取spinlock,其spin基于的对象并不是从一而终的,在到达队首之前都是基于自己的node进行spin,到达队首后则是基于qspinlock进行spin。
- 解锁
相比起加锁,解锁的过程看起来简直简单地不像话:
void queued_spin_unlock(struct qspinlock *lock)
{
smp_store_release(&lock->locked, 0);
}
只需要把qspinlock中的"locked byte"置为0就可以了。这也不难理解,后面一直有CPU「盯」着呢,一旦大位空缺,马上就有人补齐,您只需要乖乖地把位子腾出来就行。
到这里,qspinlock加锁和解锁的过程就介绍完了,可以借助下面这张图片来一览它的全貌:

从中可以看出各种状态下CPU进行spin时基于的对象,以及状态之间的变化和迁移。
【总结与思考】
回过头来看一下qspinlock的组成和实现:如果只有1个或2个CPU试图获取锁,那么只需要一个4字节的qspinlock就可以了,其所占内存的大小和ticket spinlock一样。当有3个以上的CPU试图获取锁,需要一个qspinlock加上(N-2)个MCS node。
对于设计合理的spinlock,在大多数情况下,锁的争抢都不应该太激烈,最大概率是只有1个CPU试图获得锁,其次是2个,并依次递减。
这也是qspinlock中加入"pending"位域的意义,如果是两个CPU试图获取锁,那么第二个CPU只需要简单地设置"pending"为1,而不用「另起炉灶」创建一个MCS node。这是除了体积减小外,qspinlock相较于MCS lock所做的第二层优化。
试图加锁的CPU数目超过3个是小概率事件,但一旦发生,使用ticket spinlock机制就会造成多个CPU的cache line无谓刷新的问题,而qspinlock可以利用MCS node队列来解决这个问题。
可见,使用qspinlock机制来实现spinlock,具有很好的可扩展性,也就是无论当前锁的争抢程度如何,性能都可以得到保证。所以在Linux中,如果针对某个处理器架构的代码没有单独定义,qspinlock将是spinlock默认的实现方式。
#define arch_spin_lock(l) queued_spin_lock(l)
作为SMP系统中的一个高频操作,spinlock的性能毫无疑问会影响到整个系统运行的性能,所以,从ticket spinlock到MCS lock,再到qspinlock,见证了内核开发者对其一步步的优化历程。在优秀的性能背后,是对每一行代码的反复推敲和考量,最终铸就了qspinlock精妙但并不简单的实现过程。也许,它还有优化的空间……
至此,对Linux中不同处理器架构可能采用的三种spinlock的实现方式的介绍就告一段落了,下文将开始介绍Linux中spinlock的具体使用方法。
原创文章,转载请注明出处。















 2680
2680











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









