







堆排序
堆排序算法结合了插入排序和归并排序算法的优点,和插入排序一样,堆排序不需要额外申请空间。它是一种原地排序的算法;和归并排序一样,堆排序的运行时间也是O(nlgn)。堆排序利用“堆”这种数据结构管理算法执行中的信息。堆这种数据结构不只是在堆排序中有用,还可以构成一个有效的优先队列。
堆:
(二叉)堆数据结构是一种数组对象,它可以是一个完全二叉树。树中的每个结点与数组中存放的那个元素对应。树的每一层都是填满的。最后一层(叶子结点)除外。(最后一层从一个结点的左子树开始填)。如图:
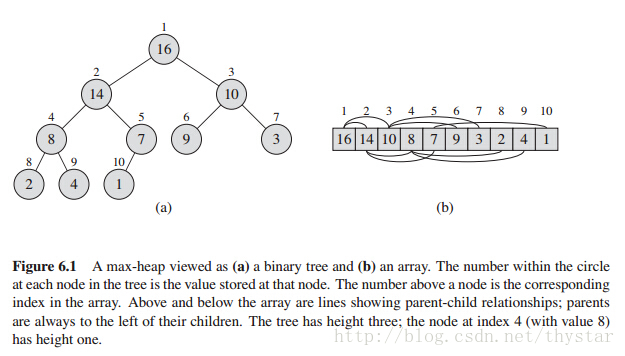
表示堆的数组A是一个具有两个属性的对象: length(A)是数组中的元素个数, heap-size[A]是存放在A中的堆的元素个数。就是说,虽然A[1 .. length[A]]中都可以包含有效值,但A[heap-size[A]]之后的元素都不属于相应的堆,此处heap-size[A]<=length[A]。树的根为A[1]。 给定了某个元素的下标i, 其父节点PARENT(i), 左儿子LEFT(i)和右儿子RIGHT(i)的下标可以简单的计算出来:

在大多数计算机上,LEFT过程计算2i,可将i的二进制表示左移一位。RIGHT过程则将i左移一位并在地位中加1.PARENT过程可以把i右移一位。
二叉堆有两种: 最大堆和最小堆(有的书上叫大顶堆和小顶堆),在最大堆中,父结点大于子结点 A[PARENT(i)] >=A[i], 反之,最小堆中A[PARENT(i)] <=A[i].
在堆排序中,我们用的是最大堆,最小堆通常在构造优先队列时使用。
堆可以被看做一棵树,结点在堆中的高度定义为本结点到叶子的最长简单下降路径上边的数目。堆的高度为树根的高度。因为有n个元素的堆是基于一棵完全二叉树的,其高度为O(lgn)。堆结构上一些基本操作的时间最多与堆的高度成正比。
保持堆的性质
MAX-HEAPIFY的输入为数组A和下标i, 当A[i]不符合最大堆的序列是,调整A[i]中元素的顺序,直至符合要求。
如图所示:
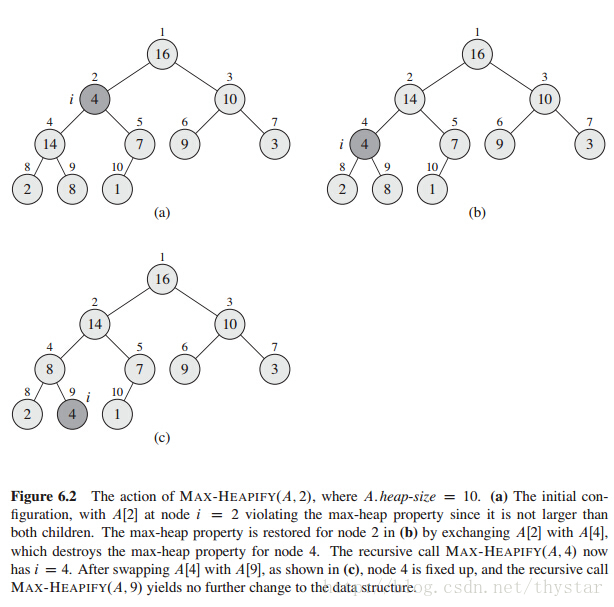
可见,当构造的二叉树不是大顶堆时,则违反规则的结点和其左子树和右子数比较找出最大的元素交换位置,直到构建的数符合标准。
算法过程如图:

建堆
我们可以自底向上的用MAX-HEAPIFY来将一个数组A[1 .. n] 变成一个最大堆。子数组A[(n/2)+1 .. n]中的元素都是树中的叶子,因此每个都可以看做是只含有一个元素的堆。建堆的过程中对树中的每个结点调用一次MAX-HEAPIFY
建堆的过程:

下图为一个完整的建堆过程:
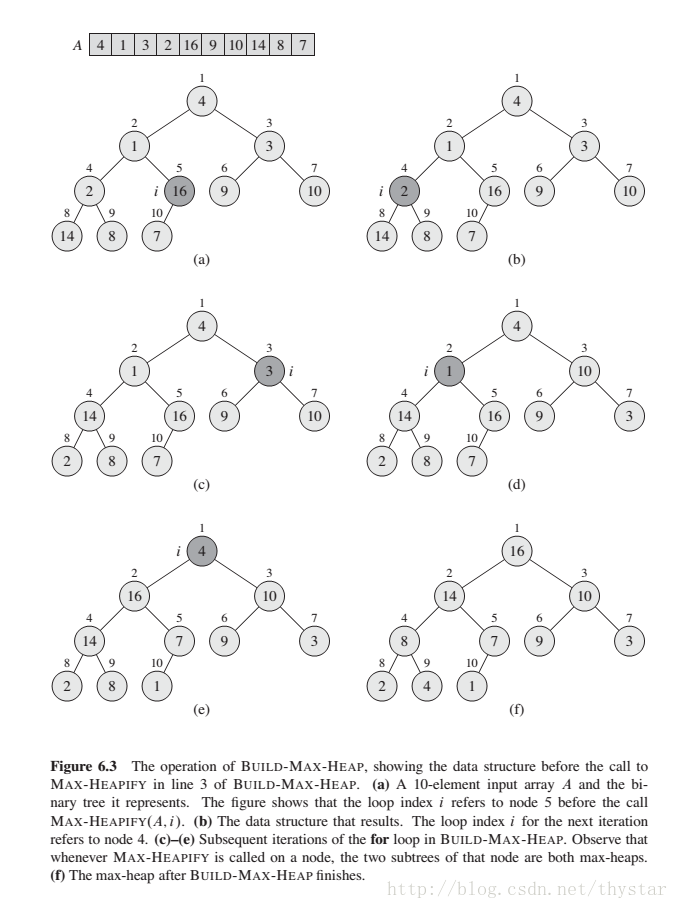
初始化: 在第一轮迭代之前 i = 【n/2】. 结点 n=【n/2】+1 ... n都是叶节点也是平凡大顶堆的根
保持: 要证明每次迭代都保持了循环不变式,注意到结点 i 的子结点的编号均比 i 大。于是,根据循环不变式, 这些子结点都是最大堆的根。这也是调用函数MAX-HEAPIFY(A,i), 以使结点 i 成为最大堆的根的前提条件。 此外, MAX-HEAPIFY(A,i)的调用保持了结点i+1, i+2,...,n为最大根的性质。在for循环中递减i, 即为下一次迭代重新建立了循环不变式。
终止: 过程终止时,i=0. 根据循环不变式,我们知道结点1,2, ... ,n中,每个都是最大的根。特别的,结点1就是最大的根。
堆排序算法
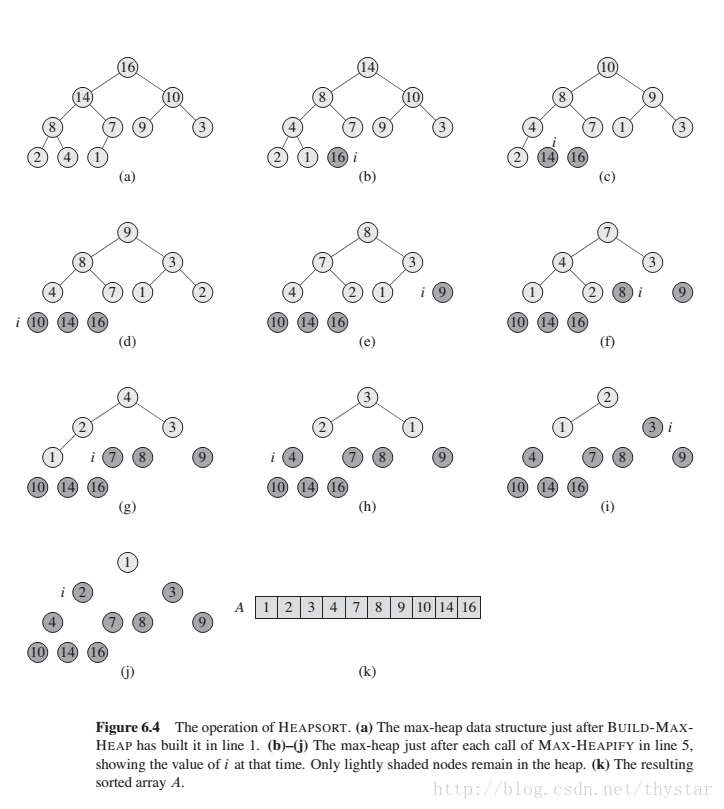
开始时,堆排序算法先用BUILD-MAP-HEAP将输入数据A[1 .. n]构造成一个大顶堆。因为数组中最大的元素在根A[1], 则可以通过把它与A[n]呼唤来达到最终正确的位置。 现在,如果从堆中“去掉”结点n, 可以很容易的将A[1 .. n-1]建成大顶堆。原来的子女仍是大顶堆。而新元素违背了大顶堆的性质。这是调用MAX-HEAPIFY(A,1),就可以保持这一性质。在A{1 .. n-1}中构造出大顶堆。堆排序算法不断重复这个过程。堆的大小由n-1 一直降到2.
其过程如下:

下图为一个完整的排序过程:
完整的实现代码:
/*
堆排序算法实现
*/
#include<iostream>
using namespace std;
int HeapSize = 10; // 暂定为这个数,假设需要排序的数有10个
/*
这三个过程在一个好的堆排序中通过内联和宏实现
*/
//父结点
int Parent(int i)
{
return i/2;
}
//左子结点
int Left(int i)
{
return 2*i;
}
//右子节点
int Right(int i)
{
return 2*i+1;
}
// 维持大顶堆
void MaxHeapify(int A[], int i)
{
int largest; //临时变量存放A[i]及左右子树的最大值的下标
int l = Left(i); //用l存放A[i]的左子树
int r = Right(i); //用r存放A[i]的右子树
// 判断A[i]与其左子树的大小
// 将其中的最大值赋给largest
if(A[l] > A[i] && l < HeapSize)
{
largest = l;
}
else
{
largest = i;
}
// 判断A[i]与其右子树的大小
// 将其中的最大值赋给largest
if(A[r] > A[largest] && r <= HeapSize)
{
largest = r;
}
// 如果largest不是父结点A[i],则交换A[largest]与A[i]的位置
int temp;
if(largest != i)
{
temp = A[i];
A[i] = A[largest];
A[largest] = temp;
// 继续向下一层的子树寻找
MaxHeapify(A, largest);
}
}
// 建堆
void BuildMaxHeap(int A[], int i) // n为数组的长度,省去了算法描述的第一步
{
//每一次迭代开始时,结点i+1,i+2,...,n都是大顶堆的根
for(i = i/2; i > 0; i--)
{
MaxHeapify(A, i);
}
}
// 实现堆排序
/*
这里A数组从1开始计数,也就是A【0】元素不要。
取A[1,..,n]
调用函数HeapSort(A, HeapSize);
*/
void HeapSort(int A[], int n)
{
int temp;
BuildMaxHeap(A, n); // 构造大顶堆
for(int i = n; i > 1; i--)
{
//将最后一个元素与堆的第一个元素交换位置
temp = A[1];
A[1] = A[i];
A[i] = temp;
// 堆的=规模随之缩小1个
HeapSize = HeapSize-1;
// 重新维持堆
MaxHeapify(A,1);
}
}注: 这里只是简单实现了《算法导论》中的算法。有些地方就偷工减料了。
结果:A【0】不参加排序。
















 1454
1454

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









