







我们先看一下携程网的信息
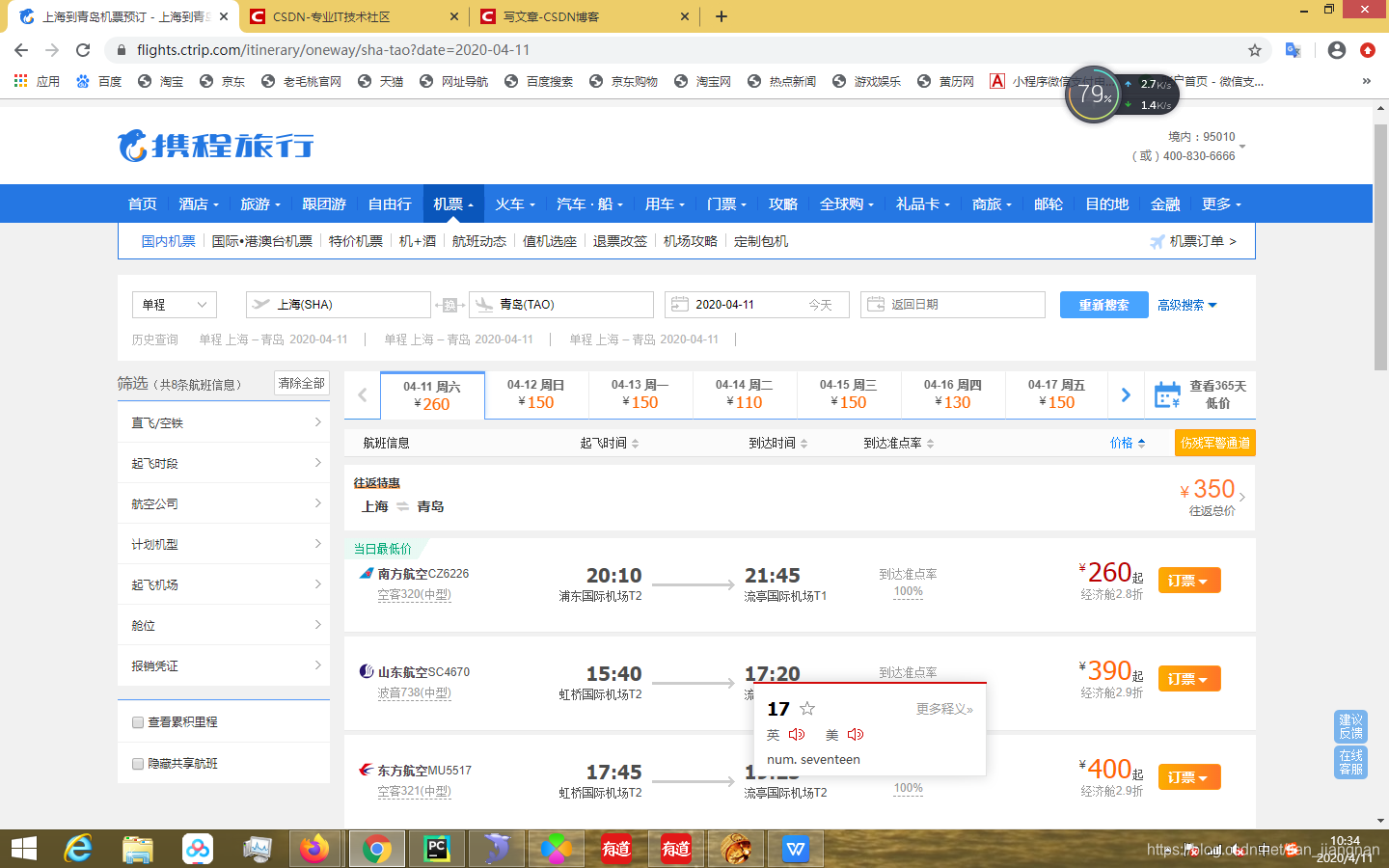

从以上我们可以获取两个信息
1、我是从上海到成都的
2、7条航班信息
教你如何爬虫
我不教静态网页的爬虫,因为太简单了;我们直接上手携程网
我们到这个上述这个页面以后,我推荐用谷歌浏览器,方便;
1、谷歌浏览器
2、携程网显示机票信息页面
3、f12

4、然后我们刷新页面,network下就有很多的文件了
选择XHR,然后出现以下几条信息
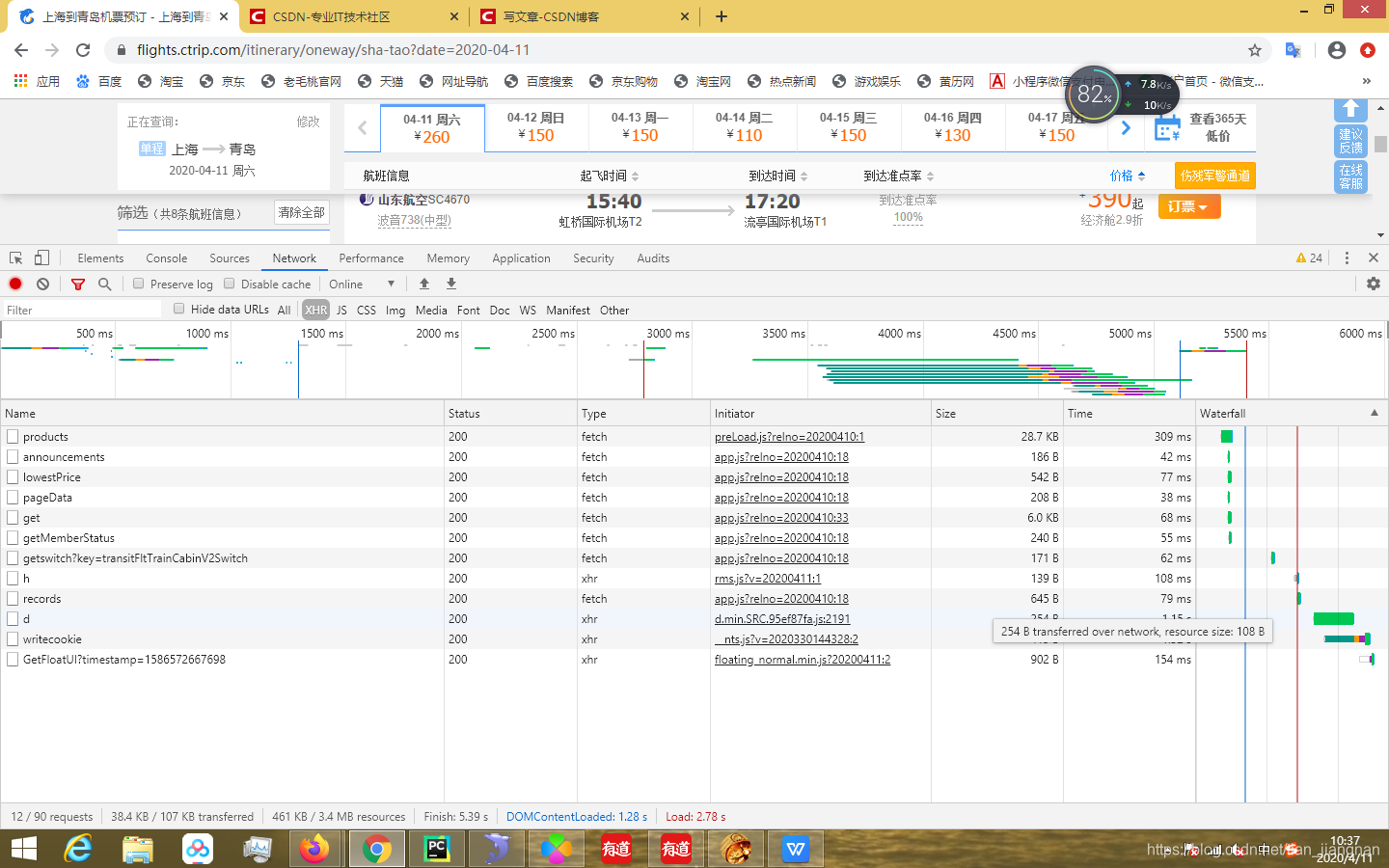
点击其中一条,然后点击右侧的preview

我们可以看到里面有数据,不一定是第一条,我们查看里面的数据有没有我们要的信息
举个例子,其中的pageData,我们点击,然后发现previewer里面的数据很少,根本没有一条是我们需要的;所以肯定不是pageData这个文件
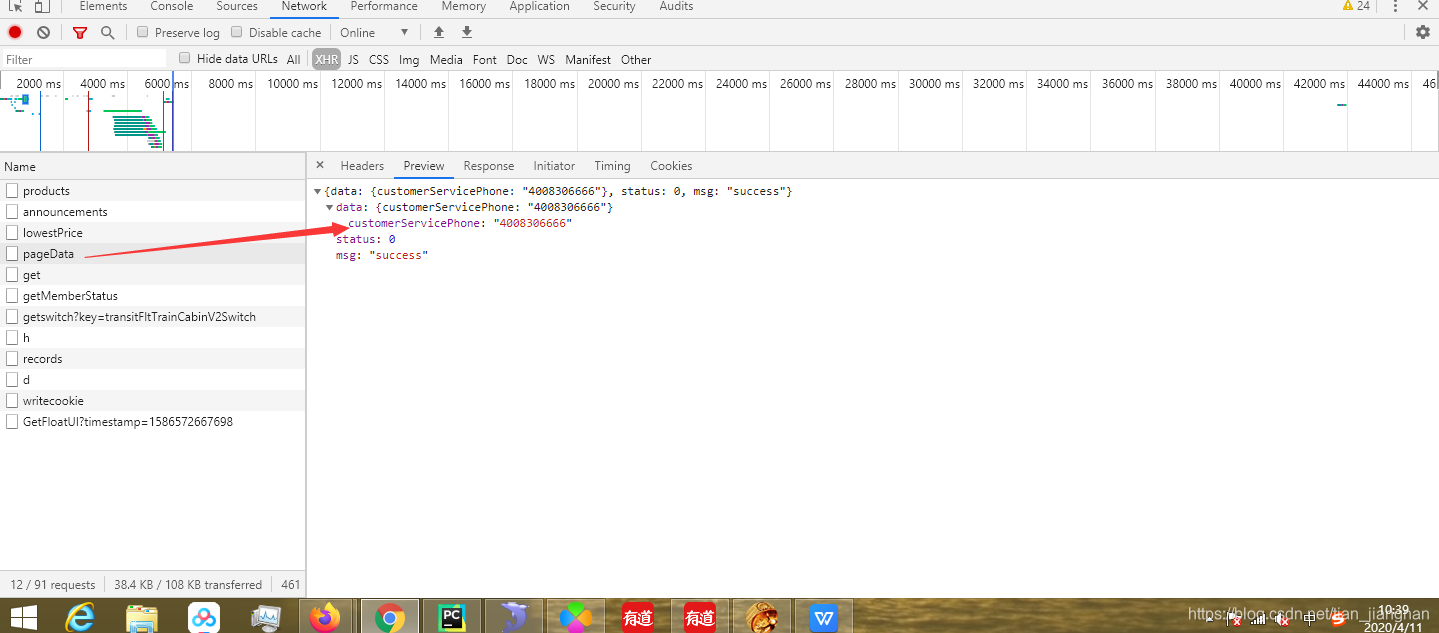 其实是第一条product
其实是第一条product

 现在已经有眉目了,我们需要这个product文件的信息,点击Headers
现在已经有眉目了,我们需要这个product文件的信息,点击Headers

从上面我们可以知道我们爬虫的地址是url = 'http://flights.ctrip.com/itinerary/api/12808/products'
这个请求是post请求;那么我们需要发送什么样的数据才会有这样的结果呢?


废话不多说,直接贴上代码
爬虫携程网
from prettytable import PrettyTable
import requests
import json
import pymysql
def xiecheng(dcity, acity, date):
date = date[0:4] + '-' + date[4:6] + '-' + date[6:8]
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:75.0) Gecko/20100101 Firefox/75.0",
"Content-Type": "application/json", # 声明文本类型为 json 格式
"referer": r"https://flights.ctrip.com/itinerary/oneway/SHA-TAO?date=2020-04-11"
}
city = {'阿尔山': 'YIE', '阿克苏': 'AKU', '阿拉善右旗': 'RHT', '阿拉善左旗': 'AXF', '阿勒泰': 'AAT', '阿里': 'NGQ', '澳门': 'MFM',
'安庆': 'AQG', '安顺': 'AVA', '鞍山': 'AOG', '巴彦淖尔': 'RLK', '百色': 'AEB', '包头': 'BAV', '保山': 'BSD', '北海': 'BHY',
'北京': 'BJS', '白城': 'DBC', '白山':  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









