






 本文介绍了一种在浏览器端实现多种格式文件预览的方法,包括压缩包解压、PDF及文档预览等,降低了服务器负担并提高了用户体验。
本文介绍了一种在浏览器端实现多种格式文件预览的方法,包括压缩包解压、PDF及文档预览等,降低了服务器负担并提高了用户体验。
背景
浏览器端普通的文件上传,通常为图片上传,假如为压缩包(zip,rar,7z),docx,ppt,pdf ,md 以及项目代码等格式 要在上传阶段实现预览,内容提取该如何实现呢? 如何确定该压缩包是否加密了呢?
本方案参考了众多资料, 针对不同的文件格式上传阶段预览进行了实践探索
价值
1.本项目的价值就是能够在客户端快速解压缩压缩包以及预览压缩包内容。 能预览 'zip', 'rar', '7z', 'docx', 'pptx', 'xlsx', 'pdf', 'gif', 'jpg', 'jpeg', 'bmp', 'tiff', 'tif', 'png', 'svg', 'txt', 'json', 'js', 'css', 'java', 'py', 'html', 'jsx', 'ts', 'tsx', 'xml', 'md', 'log', 'editorconfig', 'browserslistrc', 'project', 'gitignore', 'cfg', 'sh', 'yml', 'mp4'等格式内容 ,能对压缩包内容在前端方向上进行敏感信息审查,降低服务器解压缩的成本
2. pdf ,docx等预览 ,编辑者可以指定用户试读哪几页 ,复制pdf内容等
3.可以 在内容编辑 修改的时候 ,依赖压缩包里的内容 进行文字转移编辑 ,而不用进行注意力转移。
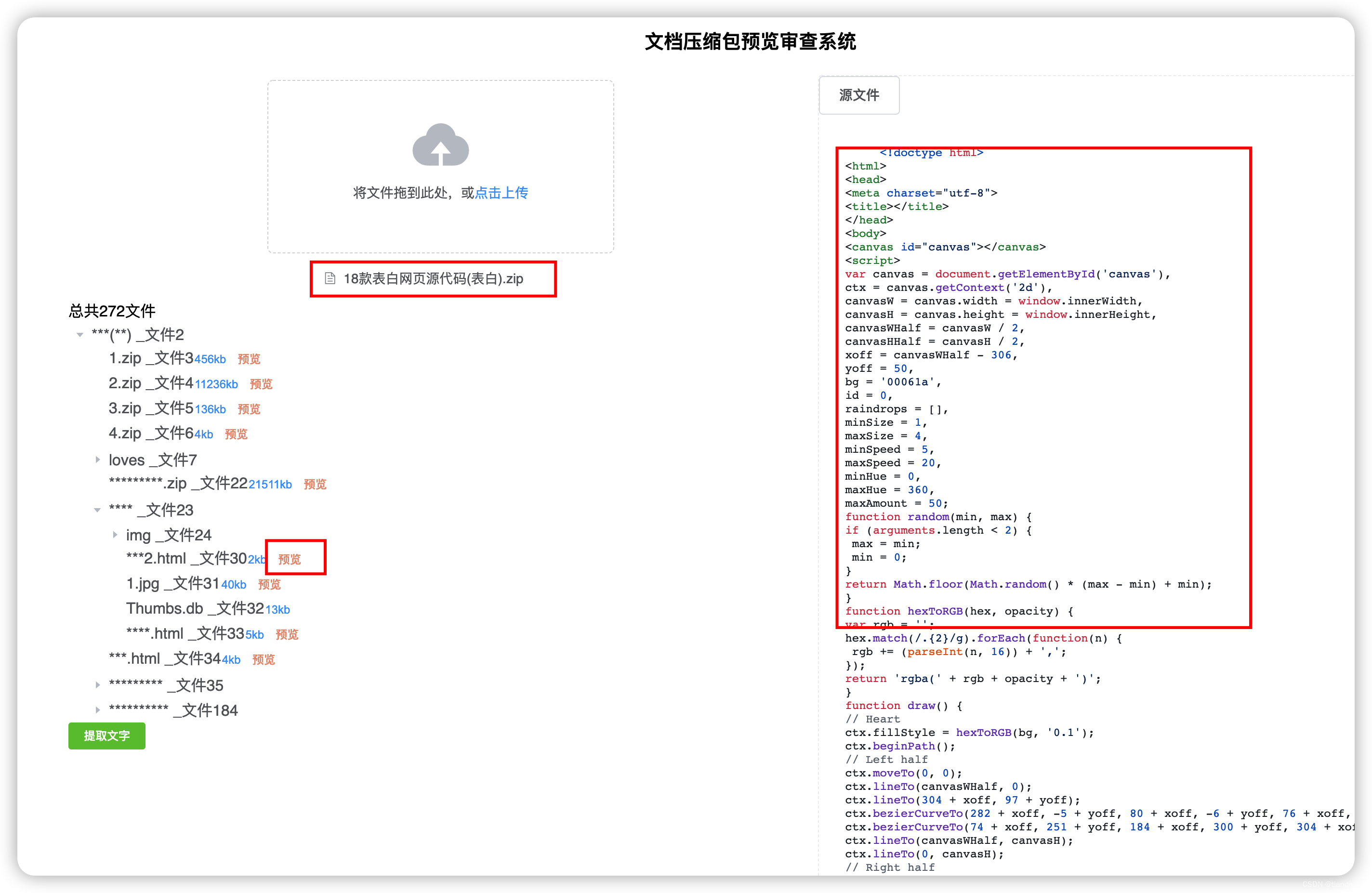
方案
1.浏览器端实现的压缩包解压缩
方案1:jszip ,rarjs 等开源库
方案2: Libarchivejs 【性能优】
能解压zip,rar以及7z等常见的压缩格式
Libarchivejs 是一个用于浏览器的归档工具,可以提取各种类型的压缩,它是libarchive到 WebAssembly 和 javascript 包装器的一个端口,使其更易于使用。由于它在 WebAssembly 上运行,因此性能应该接近原生。支持的格式:ZIP、7-Zip、RAR v4、RAR v5、TAR。支持的压缩:GZIP、DEFLATE、BZIP2、LZMA
1.初始code
import {Archive} from '../lib/libarchive';
if (typeof window !== 'undefined') {
// browser environment
window.Archive = Archive;
Archive.init({
workerUrl: '/dist/worker-bundle.js'
});
} else {
Archive.init();
}2.调用函数
async function getPackageInfo(file) {
let obj = null;
const archive = await Archive.open(file);
obj = await archive.extractFiles();
console.log(obj)
removeMacInfo(obj)
return {
extractInfo: obj,
// filesInfo:filesObj
};
}3. 获得input 的file对象 ,对file 进行 getPackageInfo(file) 解压缩处理 ,返回 {extractInfo: data} ,
data数据结构如下
{
".gitignore": {File},
"addon": {
"addon.py": {File},
"addon.xml": {File}
},
"README.md": {File}
}附加:检查压缩包是否加密
const archive = await Archive.open(file);
await archive.hasEncryptedData();
// true - yes
// false - no
// null - can not be determined更多了解参考对应的github库 https://github.com/nika-begiashvili/libarchivejs
2.PDF 预览
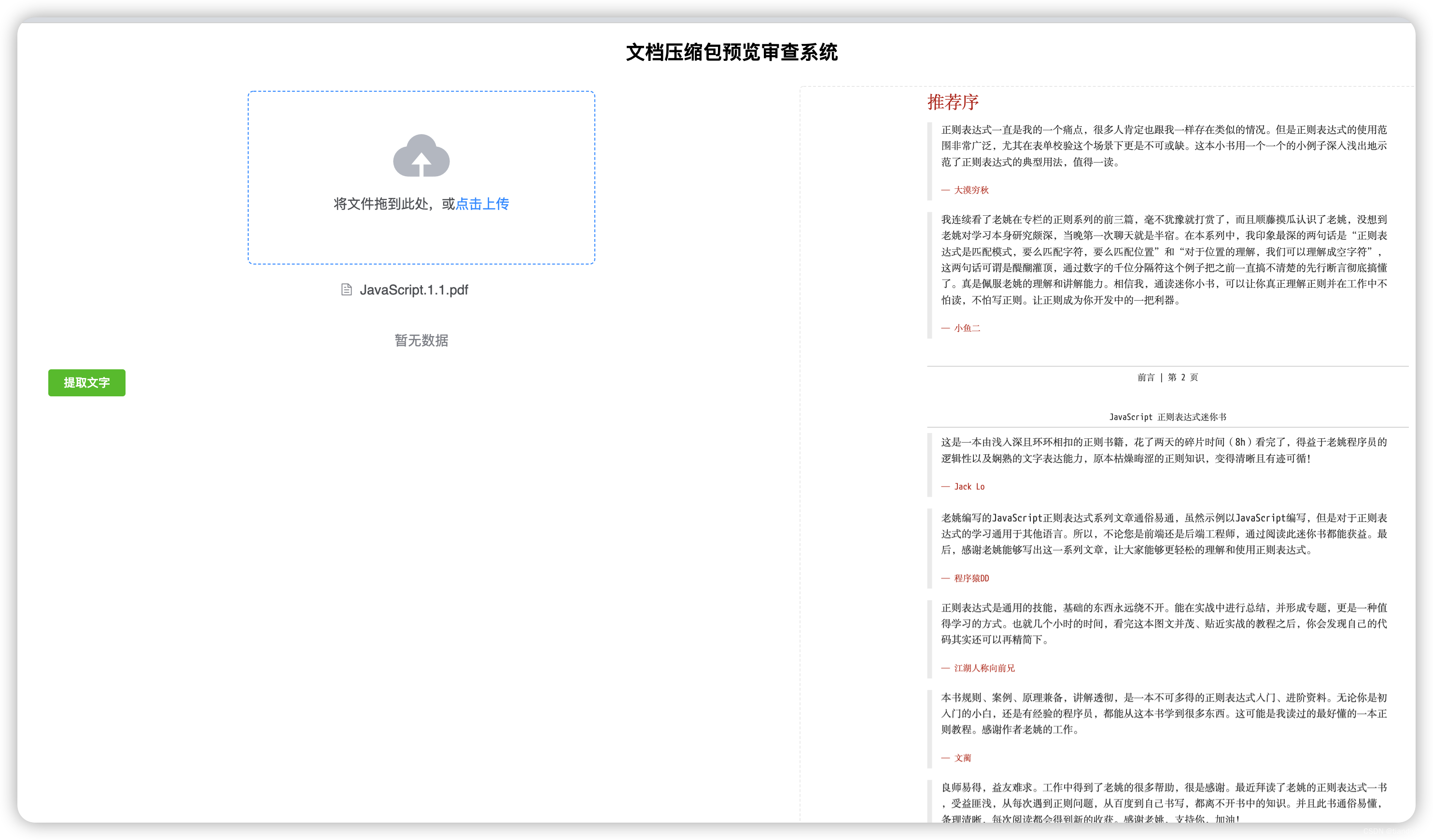
- iframe
- object
- embed
将文件File转为buffer 然后利用FileReader将buffer 转为URL
export async function readDataURL (buffer) {
return new Promise((resolve, reject) => {
const reader = new FileReader()
reader.onload = loadEvent => resolve(loadEvent.target.result)
reader.onerror = e => reject(e)
reader.readAsDataURL(new Blob([buffer]))
})
}个性化方案 pdf-dist (svg,canvas,html)
pdf.js 能实现个性话的阅读pdf ,而拜托当前浏览器的默认设置,但是实现难度也是最为复杂的
pdf-dist 这个开源项目的例子很多,需要认真研究
下面分享一下 pdf-dist的使用流程
1.初始化js载入 ,并创建容器元素
import PDFJS from 'pdfjs-dist';
PDFJS.GlobalWorkerOptions.workerSrc = 'pdfjs-dist/build/pdf.worker.js';<div id="container"></div>
2. 运行 div#container为最外层节点,在该div中,我们会为PDF的每个页面创建自己的div,在每个页面的div中,都会有Canvas元素。
接着,我们修改JS代码:
var container, pageDiv;
function getPDF(url) {
PDFJS.getDocument(url).then((pdf) => {
pdfDoc = pdf;
container = document.getElementById('container');
for (var i = 1; i<= pdf.numPages; i++) {
renderPDF(i);
}
})
}
function renderPDF(num) {
pdf.getPage(num).then((page) => {
var scale = 1.5;
var viewport = page.getViewport(scale);
pageDiv = document.createElement('div');
pageDiv.setAttribute('id', 'page-' + (page.pageIndex + 1));
pageDiv.setAttribute('style', 'position: relative');
container.appendChild(pageDiv);
var canvas = document.createElement('canvas');
pageDiv.appendChild(canvas);
var context = canvas.getContext('2d');
canvas.height = viewport.height;
canvas.width = view.width;
var renderContext = {
canvasContext: context,
viewport: viewport
};
page.render(renderContext);
});
}3.分析
现在,PDF已经成功渲染在界面上了。我们来分析一下使用到的函数:
- getDocument():用于异步获取PDf文档,,类似发送多个Ajax请求以块的形式下载文档。它返回一个Promise,该Promise的成功回调传递一个对象,该对象包含PDF文档的信息,该回调中的代码将在完成PDf文档获取时执行。
- getPage():用于获取PDF文档中的各个页面。
- getViewport():针对提供的展示比例,返回PDf文档的页面尺寸。
- render():渲染PDF。
4. 增强
使用Text-Layers渲染
PDF.js支持在使用Canvas渲染的PDF页面上渲染文本图层。然而,这个功能需要用到额外的两个文件:text_layer_builder.js和text_layer_builder.css。我们可以在GitHub的repo中获取到。
如果是使用npm,则需要做如下引用:
import { TextLayerBuilder } from 'pdfjs-dist/web/pdf_viewer';
import 'pdfjs-dist/web/pdf_viewer.css';以上代码只是实现了多页渲染,接下来,开始渲染文本图层。我们需要将page.render(renderContext)修改为以下代码:
page.render(renderContext).then(() => {
return page.getTextContent();
}).then((textContent) => {
// 创建文本图层div
const textLayerDiv = document.createElement('div');
textLayerDiv.setAttribute('class', 'textLayer');
// 将文本图层div添加至每页pdf的div中
pageDiv.appendChild(textLayerDiv);
// 创建新的TextLayerBuilder实例
var textLayer = new TextLayerBuilder({
textLayerDiv: textLayerDiv,
pageIndex: page.pageIndex,
viewport: viewport
});
textLayer.setTextContent(textContent);
textLayer.render();
});最终能实现 ,pdf 转为html 格式实现愉快的复制 ,pdf-dist 功能强大,版本多 ,有问题可以要多查查资料哦
其他文稿效果
1.docx pptx 等格式

点击提取文字 ,还可以抽取里面文字 ,有需要的话可以对文字内容进行 敏感词词扫描
项目源码 :
GitHub - liuwei2016/file-viewer: 一个客户端压缩包和文件预览系统
感谢你的阅读,要是有更好的方案 欢迎留言分享
使用到的工具库
- jszip 【zip解压缩】
- libarchive.js 【压缩包解压缩】
- exceljs 【excel】预览
- highlight.js 【文本高亮】
- marked 【md 预览】
- pdf-dist 【pdf 预览】
- web-worker 【worker】
- v-viewer 【图片查看】
- docx-preview【docx 预览】
- html2canvas 【html 转图片】


















 17万+
17万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











