






参考:Linux就该这么学
一、 常用系统工作命令
1. echo [字符串|$变量] --终端输出字符串或者提取后的值
2. data [选项] [+指定格式] --时间
[root@linuxprobe ~]# date "+%Y-%m-%d %H:%M:%S"
2017-08-24 16:29:12
%j 今年中的第几天
3. reboot --重启,需要root权限
4. poweroff #关机,需要root权限
5. wget [参数] #下载地址 。 在终端中下载网络文件
-b 后台下载模式
-P 下载到指定目录
-t 最大尝试次数
-c 断点续传
-p 下载页面内所有资源,包括图片、视频等
-r 递归下载
6. ps [参数] #查看系统进程状态
$ ps --help all
Usage:
ps [options]
Basic options:
-A, -e all processes
-a all with tty, except session leaders
a all with tty, including other users
-d all except session leaders
-N, --deselect negate selection
r only running processes
T all processes on this terminal
x processes without controlling ttys
Selection by list:
-C <command> command name
-G, --Group <GID> real group id or name
-g, --group <group> session or effective group name
-p, p, --pid <PID> process id
--ppid <PID> parent process id
-q, q, --quick-pid <PID>
process id (quick mode)
-s, --sid <session> session id
-t, t, --tty <tty> terminal
-u, U, --user <UID> effective user id or name
-U, --User <UID> real user id or name
The selection options take as their argument either:
a comma-separated list e.g. '-u root,nobody' or
a blank-separated list e.g. '-p 123 4567'
Output formats:
-F extra full
-f full-format, including command lines
f, --forest ascii art process tree
-H show process hierarchy
-j jobs format
j BSD job control format
-l long format
l BSD long format
-M, Z add security data (for SELinux)
-O <format> preloaded with default columns
O <format> as -O, with BSD personality
-o, o, --format <format>
user-defined format
s signal format
u user-oriented format
v virtual memory format
X register format
-y do not show flags, show rss vs. addr (used with -l)
--context display security context (for SELinux)
--headers repeat header lines, one per page
--no-headers do not print header at all
--cols, --columns, --width <num>
set screen width
--rows, --lines <num>
set screen height
Show threads:
H as if they were processes
-L possibly with LWP and NLWP columns
-m, m after processes
-T possibly with SPID column
Miscellaneous options:
-c show scheduling class with -l option
c show true command name
e show the environment after command
k, --sort specify sort order as: [+|-]key[,[+|-]key[,...]]
L show format specifiers
n display numeric uid and wchan
S, --cumulative include some dead child process data
-y do not show flags, show rss (only with -l)
-V, V, --version display version information and exit
-w, w unlimited output width
--help <simple|list|output|threads|misc|all>
display help and exit
For more details see ps(1).
pstree 显示进程树
进程状态
R(运行):进程正在运行或在运行队列中等待。
S(中断):进程处于休眠中,当某个条件形成后或者接收到信号时,则脱离该 状态。
D(不可中断):进程不响应系统异步信号,即便用kill命令也不能将其中断。
Z(僵死):进程已经终止,但进程描述符依然存在, 直到父进程调用wait4()系统函数后将进程释放。
T(停止):进程收到停止信号后停止运行。
7. top #动态监视进程活动与系统负载信息
8. pidof [参数] [服务名称] #查询某个服务进程的pid
9. kill [参数] [PID] #终止某个指定pid的服务进程
10. killall [参数] [服务名称] #中止某个指定名称的服务对应的全部进程
11. curl [参数] 查看网站信息
-i 返回响应头信息+网站内容
二、 系统状态检测命令
1. ifconfig [网络设备] [参数] #获取网卡配置&网络状态etc
2. uname [-a] 查看系统内核&系统版本etc
a. 如需要查看当前系统版本详细信息,查看redhat-release文件
b. cat /etc/redhat-release
3. uptime #查看系统负载信息
它可以显示当前系统时间、系统已运行时间、启用终端数量以及平均负载值等信息。平均负载值指的是系统在最近1分钟、5分钟、15分钟内的压力情况(下面加粗的信息部分);负载值越低越好,尽量不要长期超过1,在生产环境中不要超过5。
4. free [-h] #显示当前系统中内存的使用量
5. who [参数] #查看当前登入主机的用户终端信息
6. last [参数] #查看所有系统的登录记录
7. history [-c] #显示历史执行过的命令
8. sosreport #收集系统配置及架构信息并输出诊断文档
三、 工作目录切换命令
1. pwd [选项] #显示用户当前所处工作目录
2. cd [目录名称] #切换工作路径
3. ls [选项] [文件] #显示目录中的文件信息
a. -a 全部文件 -l 可以查看文件属性大小etc--》-al
b. -ld /etc 查看/etc目录的权限&属性
四、 文本文件编辑命令
1. cat [选项] [文件] #查看纯文本文件(内容较少)
a. -n 显示行数
2. more [选项] [文件] #查看纯文本文件(内容较多)空格/回车翻页
3. head [选项] [文件] #查看纯文本文件前N行
a. head -n 20 xxx.cfg #查看前20行
4. tail [选项] [文件] #查看纯文本文件后N行/持续刷新内容
a. tail -n 20 xxx.xxx 查看后20行
b. tail -f xxx.xxx 持续刷新(log)
5. tr [原始字符] [目标字符] #替换文本文件中的字符
cat anaconda-ks.cfg | tr [a-z] [A-Z] 替换小写为大写
6. wc [参数] [文本] #统计行数、字数、字节数
-l 只显示行数
-w 只显示单词数
-c 只显示字节数
7. stat [文件名称] #查看文件存储信息和时间etc
8. diff [参数] [文件] 比较多个文本文件的差异
a. --brief 判断文件是否相同
b. -c 详细比较出多个文件的差异之处 diff xxx xxx.xxx xxx.yyy
五、 文件目录管理命令
1. touch [选项] [参数] #创建空白文件或者设置文件时间
-a 仅修改“读取时间”(atime)
-m 仅修改“修改时间”(mtime)
-d 同时修改atime与mtime
2. mkdir [选项] 目录 #创建空白的目录
a. -p #递归创建嵌套层叠关系的文件目录
3. cp [选项] 源文件 目标文件 #复制文件/目录
如果目标文件是目录,则会把源文件复制到该目录中;
如果目标文件也是普通文件,则会询问是否要覆盖它;
如果目标文件不存在,则执行正常的复制操作
-p 保留原始文件的属性
-d 若对象为“链接文件”,则保留该“链接文件”的属性
-r 递归持续复制(用于目录)
-i 若目标文件存在则询问是否覆盖
-a 相当于-pdr(p、d、r为上述参数)
4. mv [选项] 源文件 [目标路径|目标文件名] #剪切文件or重命名
5. rm [选项] 文件 #删除文件or目录
a. -f 强制删除
b. -r 删除目录
6. dd [参数] #按照指定大小和个数的数据块来复制文件or转换文件
if 输入的文件名称
of 输出的文件名称
bs 设置每个“块”的大小
count 设置要复制“块”的个数
7. file 文件名 #查看文件的类型
a. Linux文本、目录、设备etc都成为文件
六、 打包压缩&搜索
1. tar [选项] [文件] 对文件进行打包压缩or解压
-c 创建压缩文件
-x 解开压缩文件
-t 查看压缩包内有哪些文件
-z 用Gzip压缩或解压
-j 用bzip2压缩或解压
-v 显示压缩或解压的过程
-f 目标文件名
-p 保留原始的权限与属性
-P 使用绝对路径来压缩
-C 指定解压到的目录
tar xzvf etc.tar.gz -C /root/etc 解压到指定路径
2. grep [选项] [文件] #在文本中执行关键词搜索
-b 将可执行文件(binary)当作文本文件(text)来搜索
-c 仅显示找到的行数
-i 忽略大小写
-n 显示行号
-v 反向选择——仅列出没有“关键词”的行。
-C 1
-A 1
-B 1 前后1行(Context)
后一行(After)
前一行(Before)
$ grep --help
Usage: grep [OPTION]... PATTERN [FILE]...
Search for PATTERN in each FILE or standard input.
PATTERN is, by default, a basic regular expression (BRE).
Example: grep -i 'hello world' menu.h main.c
Regexp selection and interpretation:
-E, --extended-regexp PATTERN is an extended regular expression (ERE)
-F, --fixed-strings PATTERN is a set of newline-separated fixed strings
-G, --basic-regexp PATTERN is a basic regular expression (BRE)
-P, --perl-regexp PATTERN is a Perl regular expression
-e, --regexp=PATTERN use PATTERN for matching
-f, --file=FILE obtain PATTERN from FILE
-i, --ignore-case ignore case distinctions
-w, --word-regexp force PATTERN to match only whole words
-x, --line-regexp force PATTERN to match only whole lines
-z, --null-data a data line ends in 0 byte, not newline
Miscellaneous:
-s, --no-messages suppress error messages
-v, --invert-match select non-matching lines
-V, --version display version information and exit
--help display this help text and exit
Output control:
-m, --max-count=NUM stop after NUM matches
-b, --byte-offset print the byte offset with output lines
-n, --line-number print line number with output lines
--line-buffered flush output on every line
-H, --with-filename print the file name for each match
-h, --no-filename suppress the file name prefix on output
--label=LABEL use LABEL as the standard input file name prefix
-o, --only-matching show only the part of a line matching PATTERN
-q, --quiet, --silent suppress all normal output
--binary-files=TYPE assume that binary files are TYPE;
TYPE is 'binary', 'text', or 'without-match'
-a, --text equivalent to --binary-files=text
-I equivalent to --binary-files=without-match
-d, --directories=ACTION how to handle directories;
ACTION is 'read', 'recurse', or 'skip'
-D, --devices=ACTION how to handle devices, FIFOs and sockets;
ACTION is 'read' or 'skip'
-r, --recursive like --directories=recurse
-R, --dereference-recursive
likewise, but follow all symlinks
--include=FILE_PATTERN
search only files that match FILE_PATTERN
--exclude=FILE_PATTERN
skip files and directories matching FILE_PATTERN
--exclude-from=FILE skip files matching any file pattern from FILE
--exclude-dir=PATTERN directories that match PATTERN will be skipped.
-L, --files-without-match print only names of FILEs containing no match
-l, --files-with-matches print only names of FILEs containing matches
-c, --count print only a count of matching lines per FILE
-T, --initial-tab make tabs line up (if needed)
-Z, --null print 0 byte after FILE name
Context control:
-B, --before-context=NUM print NUM lines of leading context
-A, --after-context=NUM print NUM lines of trailing context
-C, --context=NUM print NUM lines of output context
-NUM same as --context=NUM
--group-separator=SEP use SEP as a group separator
--no-group-separator use empty string as a group separator
--color[=WHEN],
--colour[=WHEN] use markers to highlight the matching strings;
WHEN is 'always', 'never', or 'auto'
-U, --binary do not strip CR characters at EOL (MSDOS/Windows)
-u, --unix-byte-offsets report offsets as if CRs were not there
(MSDOS/Windows)
'egrep' means 'grep -E'. 'fgrep' means 'grep -F'.
Direct invocation as either 'egrep' or 'fgrep' is deprecated.
When FILE is -, read standard input. With no FILE, read . if a command-line
-r is given, - otherwise. If fewer than two FILEs are given, assume -h.
Exit status is 0 if any line is selected, 1 otherwise;
if any error occurs and -q is not given, the exit status is 2.
Report bugs to: bug-grep@gnu.org
GNU Grep home page: <http://www.gnu.org/software/grep/>
General help using GNU software: <http://www.gnu.org/gethelp/>
3. find [查找路径] 寻找条件 操作 #按照指定条件来查找文件
-name 匹配名称
-perm 匹配权限(mode为完全匹配,-mode为包含即可)
-user 匹配所有者
-group 匹配所有组
-mtime -n +n 匹配修改内容的时间(-n指n天以内,+n指n天以前)
-atime -n +n 匹配访问文件的时间(-n指n天以内,+n指n天以前)
-ctime -n +n 匹配修改文件权限的时间(-n指n天以内,+n指n天以前)
-nouser 匹配无所有者的文件
-nogroup 匹配无所有组的文件
-newer f1 !f2 匹配比文件f1新但比f2旧的文件
--type b/d/c/p/l/f 匹配文件类型(后面的字幕字母依次表示块设备、目录、字符设备、管道、链接文件、文本文件)
-size 匹配文件的大小(+50KB为查找超过50KB的文件,而-50KB为查找小于50KB的文件)
-prune 忽略某个目录
-exec …… {}\; 后面可跟用于进一步处理搜索结果的命令
二、管道符、重定向、环境变量
1. 重定向
1.1. 输入重定向
命令 < 文件 将文件作为命令的标准输入
命令 << 分界符 从标准输入中读入,直到遇见分界符才停止
命令 < 文件1 > 文件2 将文件1作为命令的标准输入并将标准输出到文件2
1.2. 输出重定向:
命令 > 文件 将标准输出重定向到一个文件中(清空原有文件的数据)
命令 2> 文件 将错误输出重定向到一个文件中(清空原有文件的数据)
命令 >> 文件 将标准输出重定向到一个文件中(追加到原有内容的后面)
命令 2>> 文件 将错误输出重定向到一个文件中(追加到原有内容的后面)
命令 >> 文件 2>&1 将标准输出与错误输出共同写入到文件中(追加到原有内容的后面)
或
命令 &>> 文件
0 表示stdin标准输入
1 表示stdout标准输出
2 表示stderr标准错误
command > /dev/null相当于执行了command 1 > /dev/null。执行command产生了标准输出stdout(用1表示),重定向到/dev/null的设备文件中。
分析 2>&1
对于2>&1的理解,2就是标准错误,1是标准输出,那么这条命令不就是相当于把标准错误重定向到标准输出么?是的。
为什么是&1而不是1,这里& 符号是什么?& 符号可以理解为引用(reference)。&1 就是对标准输出的引用。
command>a 2>a 与 command>a 2>&1的区别
通过上面的分析,对于command>a 2>&1这条命令,等价于command 1>a 2>&1。
可以理解为执行command产生的标准输入重定向到文件a中,标准错误也重定向到文件a中。
那么是否就说command 1>a 2>&1等价于command 1>a 2>a呢?
其实不是,command 1>a 2>&1与command 1>a 2>a 还是有区别的,区别就在于前者只打开一次文件a,后者会打开文件两次,并导致stdout被stderr覆盖。&1的含义就可以理解为用标准输出的引用,引用的就是重定向标准输出产生打开的a。从IO效率上来讲,command 1>a 2>&1比 command 1>a 2>a的效率更高。
2. 管道命令符:
格式:命令A|命令B
作用:把前一个要输出到屏幕的标准正常数据当作是后一个命令的标准输入。
ls -l /etc/ | more
3. 通配符
a. 星号(*)代表匹配零个或多个字符,问号(?)代表匹配单个字符,中括号内加上数字[0-9]代表匹配0~9之间的单个数字的字符,而中括号内加上字母[abc]则是代表匹配a、b、c三个字符中的任意一个字符。
b. eg:ls -l /dev/sda*
4. 常用的转义字符
反斜杠(\):使反斜杠后面的一个变量变为单纯的字符串。
单引号(''):转义其中所有的变量为单纯的字符串。
双引号(""):保留其中的变量属性,不进行转义处理。
反引号(``):把其中的命令执行后返回结果。
eg:
PRICE=5
echo "Price is \$$PRICE"
Price is $5
5. 重要的环境变量
a. 每个路径值之间用:隔开
HOME 用户的主目录(即家目录)
SHELL 用户在使用的Shell解释器名称
HISTSIZE 输出的历史命令记录条数
HISTFILESIZE 保存的历史命令记录条数
MAIL 邮件保存路径
LANG 系统语言、语系名称
RANDOM 生成一个随机数字
PS1 Bash解释器的提示符
PATH 定义解释器搜索用户执行命令的路径
EDITOR 用户默认的文本编辑器
三、Vim & Shell脚本命令
“在Linux系统中一切都是文件,而配置一个服务就是在修改其配置文件的参数”
1. Vim三种模式
命令模式:控制光标移动,可对文本进行复制、粘贴、删除和查找等工作。
输入模式:正常的文本录入。
末行模式:保存或退出文档,以及设置编辑环境。
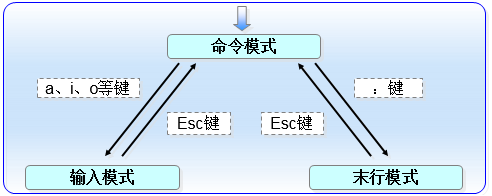
a键与i键分别是在光标后面一位和光标当前位置切换到输入模式,而o键则是在光标的下面再创建一个空行
命令 作用
dd 删除(剪切)光标所在整行
5dd 删除(剪切)从光标处开始的5行
yy 复制光标所在整行
5yy 复制从光标处开始的5行
n 显示搜索命令定位到的下一个字符串
N 显示搜索命令定位到的上一个字符串
u 撤销上一步的操作
p 将之前删除(dd)或复制(yy)过的数据粘贴到光标后面
:w 保存
:q 退出
:q! 强制退出(放弃对文档的修改内容)
:wq! 强制保存退出
:set nu 显示行号
:set nonu 不显示行号
:命令 执行该命令
:整数 跳转到该行
:s/one/two 将当前光标所在行的第一个one替换成two
:s/one/two/g 将当前光标所在行的所有one替换成two
:%s/one/two/g 将全文中的所有one替换成two
?字符串 在文本中从下至上搜索该字符串
/字符串 在文本中从上至下搜索该字符串
2. shell脚本
a. 交互式(Interactive):用户每输入一条命令就立即执行
b. 批处理(Batch):用户事先编写好一个完整的shell脚本,shell会一次性执行脚本中的诸多命令
c. 接收用户的参数
$0对应的是当前Shell脚本程序的名称,$#对应的是总共有几个参数,$*对应的是所有位置的参数值,$?对应的是显示上一次命令的执行返回值,而$1、$2、$3……则分别对应着第N个位置的参数值

d. 判断用户的参数

文件测试语句;
逻辑测试语句;
整数值比较语句;
字符串比较语句。
操作符 作用
-d 测试文件是否为目录类型
-e 测试文件是否存在
-f 判断是否为一般文件
-r 测试当前用户是否有权限读取
-w 测试当前用户是否有权限写入
-x 测试当前用户是否有权限执行
下面使用文件测试语句来判断/etc/fstab是否为一个目录类型的文件,然后通过Shell解释器的内设$?变量显示上一条命令执行后的返回值。如果返回值为0,则目录存在;如果返回值为非零的值,则意味着目录不存在:
[root@linuxprobe ~]# [ -d /etc/fstab ]
[root@linuxprobe ~]# echo $?
1
ii. “与”的运算符号是 && 或的运算符号是 || 非的运算符号是!
iii. 整数比较运算符
操作符 作用
-eq 是否等于
-ne 是否不等于
-gt 是否大于
-lt 是否小于
-le 是否等于或小于
-ge 是否大于或等于
iv. 常用的字符串比较运算符
操作符 作用
= 比较字符串内容是否相同
!= 比较字符串内容是否不同
-z 判断字符串内容是否为空
3. 流程控制语句
a. if条件测试语句
i. 技术角度:单分支结构,双分支结构,多分支结构;复杂度和灵活度逐级上升。
ii. 单分支结构由if、then、fi关键词组成

iii. 双分支结构由if、then、else、fi关键词组成

iv. 多分支结构由if、then、else、elif、fi关键词组成,进行多次条件匹配判断
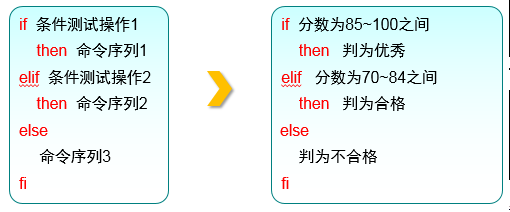
b. for条件循环语句

c. while条件循环语句

d. case条件测试语句
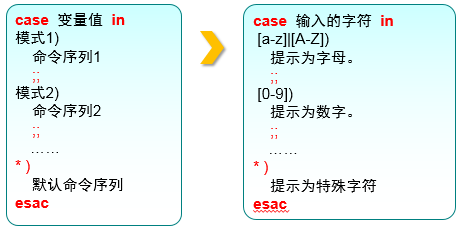
4. 计划任务服务程序
a. 一次性计划任务
i. at 时间 #一次性计划任务
ii. at -l #查看已设置好但还未执行的一次性计划任务
iii. atrm 任务序号 #删除计划任务
b. 周期性、有规律的执行某些具体任务
i. crontable -e #创建、编辑
ii. crontable -l #查看当前计划任务
iii. crontable -r #删除某条计划任务
iv. crontable -u # root身份可以编辑他人的计划任务
v. 参数格式
1) 分、时、日、月、星期 命令

字段 说明
分钟 取值为0~59的整数
小时 取值为0~23的任意整数
日期 取值为1~31的任意整数
月份 取值为1~12的任意整数
星期 取值为0~7的任意整数,其中0与7均为星期日
命令 要执行的命令或程序脚本
3) eg: 25 3 * * 1,3,5 /usr/bin/tar -czvf backup.tar.gz /home/wwwroot
a) 用逗号(,)来分别表示多个时间段,例如“8,9,12”表示8月,9月,12月,
b) 还可以用减号(-)来表示一段连续的时间周期,例如日的取值为”12-15“表示每月的12~15日
c) 用除号(/)表示执行任务的间隔时间,“*/2”表示每隔两分钟执行一次任务
d) 多条计划任务的命令语句,每行仅写一条,并以绝对路径的方式来写
i) 如果不知道绝对路径,用whereis命令查询
e) 可以以#号开头写上注册信息
f) 计划任务中的分必须有数值,不能为空或是*号,“日”和“星期”字段不能同时使用,否则会产生冲突。
四、用户身份与文件权限
root的UID(User Identification)的数值为0,所以是系统管理员
管理员UID为0: 系统的管理员用户
系统用户UID为1~999: Linux系统为了避免因某个服务程序出现漏洞而被黑客提权至整台服务器,默认服务程序会有独立的系统用户负责运行,进而有效控制被破坏范围。
普通用户UID从1000开始:是由管理员创建的用于日常工作的用户
为管理属于同一组的用户,引入了用户组的概念。通过使用用户组号码(GID, Group IDentification),可以把多个用户放到同一个组中,从而方便统一规划权限或指定任务。
系统创建用户时,将自动创建一个与其同名的基本用户组,而这个基本用户组只有该用户一个人。
1. useradd 命令
a. Useradd [选项] 用户名
参数 作用
-d 指定用户的家目录(默认为/home/username)
-e 账户的到期时间,格式为YYYY-MM-DD.
-u 指定该用户的默认UID
-g 指定一个初始的用户基本组(必须已存在)
-G 指定一个或多个扩展用户组
-N 不创建与用户同名的基本用户组
-s 指定该用户的默认Shell解释器
useradd -d /home/linux -u 8888 -s /sbin/nologin linuxprobe
id linuxprobe
uid=8888(linuxprobe) gid=8888(linuxprobe) groups=8888(linuxprobe)
用户不可登录系统
2. groupadd [选项] 群组名 #创建用户组
3. usermod [选项] 用户名 #修改用户属性
参数 作用
-c 填写用户账户的备注信息
-d -m 参数-m与参数-d连用,可重新指定用户的家目录并自动把旧的数据转移过去
-e 账户的到期时间,格式为YYYY-MM-DD
-g 变更所属用户组
-G 变更扩展用户组
-L 锁定用户禁止其登录系统
-U 解锁用户,允许其登录系统
-s 变更默认终端
-u 修改用户的UID
eg. usermod -G root fuseadm
4. passwd [选项] [用户名] #修改用户密码,过期时间,认证信息
参数 作用
-l 锁定用户,禁止其登录
-u 解除锁定,允许用户登录
--stdin 允许通过标准输入修改用户密码,如echo "NewPassWord" | passwd --stdin Username
-d 使该用户可用空密码登录系统
-e 强制用户在下次登录时修改密码
-S 显示用户的密码是否被锁定,以及密码所采用的加密算法名称
passwd username: 修改用户密码
passwd -l username:锁定用户不允许登录
5. userdel [选项] 用户名 #删除用户
参数 作用
-f 强制删除用户
-r 同时删除用户及用户家目录
二、 文件权限与归属
-:普通文件。
d:目录文件。
l:链接文件。
b:块设备文件。
c:字符设备文件。
p:管道文件。

可读(r-4)、可写(w-2)、可执行(x-1)

该文件的类型为普通文件,所有者权限为可读、可写(rw-),所属组权限为可读(r--),除此以外的其他人也只有可读权限(r--),文件的磁盘占用大小是34298字节,最近一次的修改时间为4月2日的凌晨23分,文件的名称为install.log。
三、文件的特殊权限
1. SUID
a. 一种对二进制程序进行设置的特殊权限,可以让二进制程序的执行者临时拥有属主的权限(仅对拥有执行权限的二进制程序有效)例如,所有用户都可以执行passwd命令来修改自己的用户密码,而用户密码保存在/etc/shadow中,默认权限是000。
b. Passwd 权限 rws,其中x改变成s意味着该文件被赋予了SUID权限。如果原权限是rw-,没有x执行权限,那么被赋予特殊权限后将变成大写的S。
[root@linuxprobe ~]# ls -l /etc/shadow
----------. 1 root root 1004 Jan 3 06:23 /etc/shadow
[root@linuxprobe ~]# ls -l /bin/passwd
-rwsr-xr-x. 1 root root 27832 Jan 29 2017 /bin/passwd
2. SGID
a. 让执行者临时拥有属组的权限(对拥有执行权限的二进制程序进行设置)
b. 在某个目录中创建的文件自动继承该目录的用户组(只可以对目录进行设置)
3. SBIT(Sticky Bit 粘滞位,(保护位))
a. SBIT 确保用户只能删除自己的文件,不能删除其他用户的文件。(该目录中的文件只能被其所有者执行删除操作。)
b. 当目录被设置为SBIT特殊权限位后,文件的其他人权限部分的x执行权限就会被替换成t或者T,原本有x执行权限会被写成t,原本没有x执行权限则会被写成T。
4. chmod / chown
a. chmod [参数] 权限 文件或目录名称 #设置文件或目录的权限
b. chown [参数] 所有者:所属组 文件或目录 #设置文件或目录的所有者和所属组
c. 针对目录操作时需要加 -R表示递归操作。
四、文件的隐藏属性
1. chattr 命令
a. chattr [参数] 文件 #设置文件的隐藏权限。如果想把某个隐藏功能添加到文件上,则需要在命令后面追加"+参数“,如果想要把某个隐藏功能移出文件,则需要追加”-参数“。
参数 作用
i 无法对文件进行修改;若对目录设置了该参数,则仅能修改其中的子文件内容而不能新建或删除文件
a 仅允许补充(追加)内容,无法覆盖/删除内容(Append Only)
S 文件内容在变更后立即同步到硬盘(sync)
s 彻底从硬盘中删除,不可恢复(用0填充原文件所在硬盘区域)
A 不再修改这个文件或目录的最后访问时间(atime)
b 不再修改文件或目录的存取时间
D 检查压缩文件中的错误
d 使用dump命令备份时忽略本文件/目录
c 默认将文件或目录进行压缩
u 当删除该文件后依然保留其在硬盘中的数据,方便日后恢复
t 让文件系统支持尾部合并(tail-merging)
x 可以直接访问压缩文件中的内容
e.g. chattr +a note.txt 无法删除note.txt文件
2. lsattr命令
a. lsattr用于显示文件的隐藏权限,格式为“lsattr [参数] 文件”。Linux中文件的隐藏权限必须使用lsattr命令来查看,平时使用的ls命令则无法查看。
五、文件访问控制列表
1. setfacl命令
a. 管理文件的ACL规则,格式:“setfacl [参数] 文件名称”。文件的ACL提供的是在所有者,所属组,其他人的读/写/执行权限之外的特殊权限控制,使用setfacl命令可以针对单一用户或用户组、单一文件或目录来进行读/写/执行权限的控制。其中针对目录文件需要使用-R递归传递参数;针对普通文件则使用-m参数;如果想要删除某个ACL,则可以使用-b参数。
[root@linuxprobe ~]# ls -ld /root
dr-xrwx---+ 14 root root 4096 May 4 2017 /root
+号表示设置了ACL权限
2. getfacl命令
a. 显示文件上设置的ACL信息,格式为“getfacl 文件名称”。
六、su命令与sudo服务
1. su命令可以切换用户身份
a. su - fuseadm #su命令和用户名中间有 - 号,意味着完全切换到新的用户,即把环境变量信息也变为新用户的详细信息,而不是保留原始的信息。
b. root到普通用户不需要密码验证,普通用户到root需要密码验证
2. sudo命令
a. 使用sudo把指定权限赋给指定用户
sudo服务的配置原则也很简单—在保证普通用户完成相应工作的前提下,尽可能少地赋予额外的权限。
b. sudo [参数] 命令名称
参数 作用
-h 列出帮助信息
-l 列出当前用户可执行的命令
-u 用户名或UID值 以指定的用户身份执行命令
-k 清空密码的有效时间,下次执行sudo时需要再次进行密码验证
-b 在后台执行指定的命令
-p 更改询问密码的提示语
五、存储结构和磁盘划分
















 1028
1028

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









