







Blog
2018年3月1日 13:57:47
在使用Bs4的find方法时,一定要注意其参数不同:
find(tag)----tag是标签,其返回值是Tag类型,可以对返回值再次调用find或findall方法
find(class_="className")-----这里对应的是类名
soup.find("div", id='article_show')----标签和ID混用
rticle.find('div',class_="article_text")---标签和类混用
soup.find_all(attrs={'id':'li1'})---按属性查找
soup.find_all(id='li1')-----按ID查找
同时,BS4的find方法,支持级联查找,如下所示:
content_list = soup.find(class_='grid_view').find_all('li')
find_all的返回值类型为bs4.element.ResultSet,这说明,可以对其再次使用find或find_all方法。
也就是bs4.element.ResultSet具备可迭代操作性。
如下图所示:
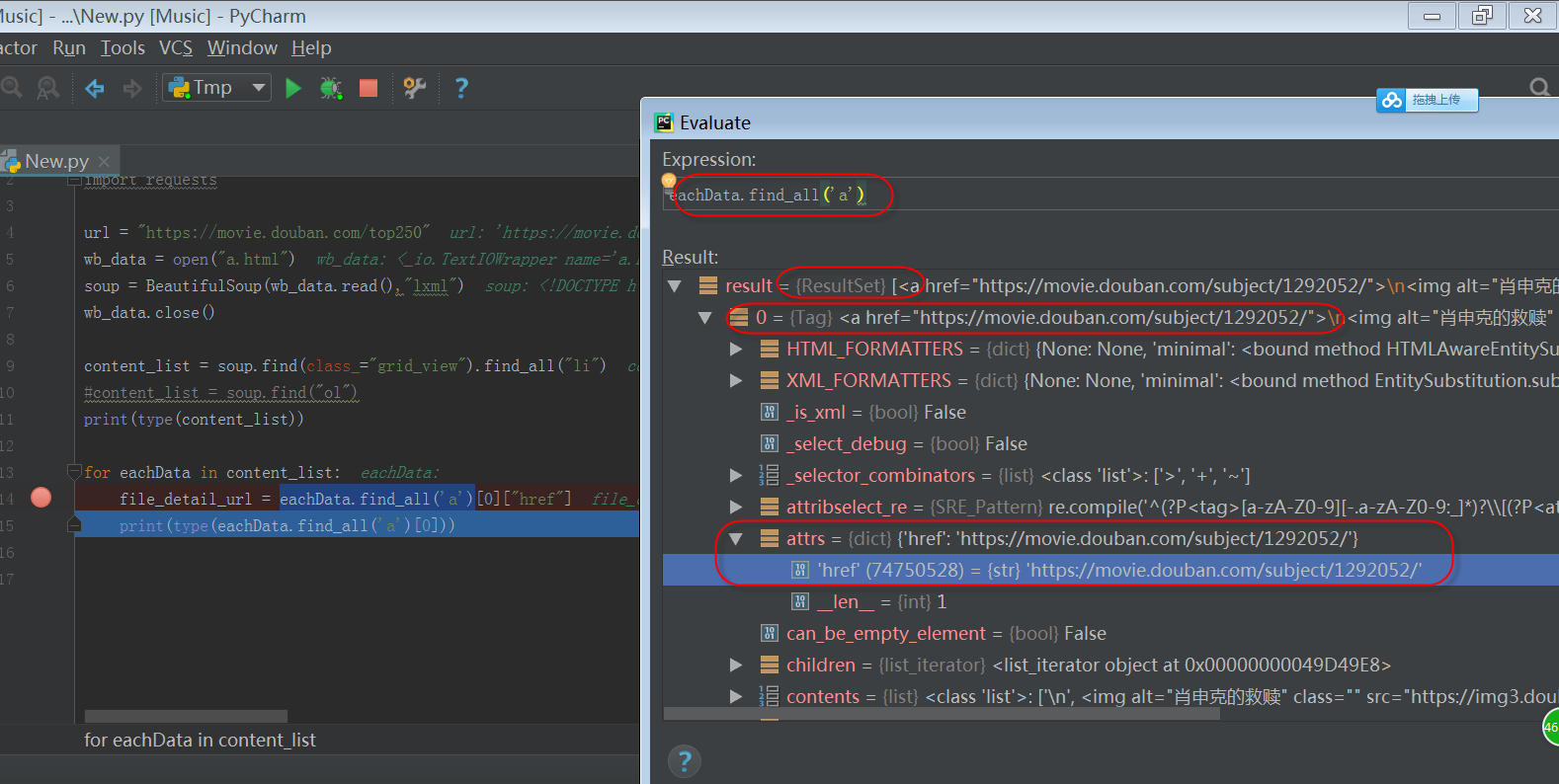
从上图可以看出,find_all返回的是个ResultSet类型,其中第一个元素是Tag类型,Tag类型中有个属性,属性类型为dict,属性名是href,所以可以取属性:

写的示例代码:
from bs4 import BeautifulSoup
import requests
import urllib
import Image
url = "https://movie.douban.com/top250"
wb_data = open("a.html")
soup = BeautifulSoup(wb_data.read(),"lxml")
wb_data.close()
content_list = soup.find(class_="grid_view").find_all("li")
#content_list = soup.find("ol")
print(type(content_list))
for eachData in content_list:
属性值是dict,所以可直接索引
file_detail_url = eachData.find_all('a')[0]["href"]
film_pic = eachData.find_all('a')[0].find('img')['src']
fileName = eachData.find_all('a')[1].find('span').text
desc=eachData.find(class_ = 'quote').find(class_="inq").text
rate = eachData.find(class_ = "rating_num").text
rateNum = eachData.find(class_="star").find_all("span")[3].text
reateNumNew = eachData.find(attrs={'class':'star'}).find_all('span')[3].text
print(file_pic)
print(fileName)
print(type(eachData.find_all('a')[0]))















 676
676











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









