







本系列为《模式识别与机器学习》的读书笔记。
一,最大边缘分类器
考察线性模型的⼆分类问题,线性模型的形式为
y ( x ) = w T ϕ ( x ) + b (7.1) y(\boldsymbol{x})=\boldsymbol{w}^{T}\boldsymbol{\phi}(\boldsymbol{x})+b\tag{7.1} y(x)=wTϕ(x)+b(7.1)
其中 ϕ ( x ) \boldsymbol{\phi}(\boldsymbol{x}) ϕ(x) 表⽰⼀个固定的特征空间变换,并且显式地写出了偏置参数 b b b 。训练数据集由 N N N 个输⼊向量 x 1 , … , x N \boldsymbol{x}_1,\dots,\boldsymbol{x}_N x1,…,xN 组成,对应的⽬标值为 t 1 , … , t N t_1,\dots,t_N t1,…,tN ,其中 t n ∈ { − 1 , 1 } t_n\in\{−1, 1\} tn∈{ −1,1} , 新的数据点 x \boldsymbol{x} x 根据 y ( x ) y(\boldsymbol{x}) y(x) 的符号进⾏分类。
现阶段,假设训练数据集在特征空间中是线性可分的,即根据定义,存在⾄少⼀个参数 w \boldsymbol{w} w 和 b b b 的选择⽅式,使得对于 t n = + 1 t_n = +1 tn=+1 的点,函数(7.1)都满⾜ y ( x n ) > 0 y(\boldsymbol{x}_n)>0 y(xn)>0 ,对于 t n = − 1 t_n = −1 tn=−1 的点,都有 y ( x n ) < 0 y(\boldsymbol{x}_n)<0 y(xn)<0 ,从⽽对于所有训练数据点,都有 t n y ( x n ) > 0 t_ny(\boldsymbol{x}_n)>0 tny(xn)>0 。
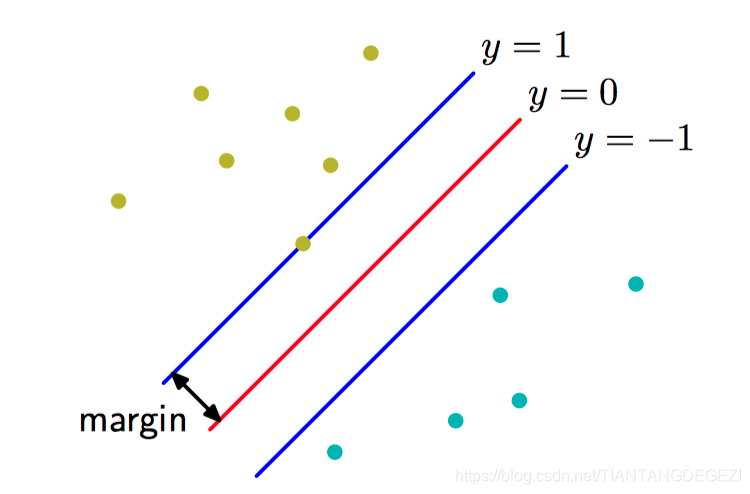
如果有多个能够精确分类训练数据点的解,那么应该尝试寻找泛化错误最⼩的那个解。 ⽀持向量机解决这个问题的⽅法是:引⼊边缘(margin) 的概念,这个概念被定义为决策边界与任意样本之间的最⼩距离,如图7.1所⽰。
如图7.2,最⼤化边缘会⽣成对决策边界的⼀个特定的选择,这个决策边界的位置由数据点的⼀个⼦集确定,被称为⽀持向量,⽤圆圈表⽰。
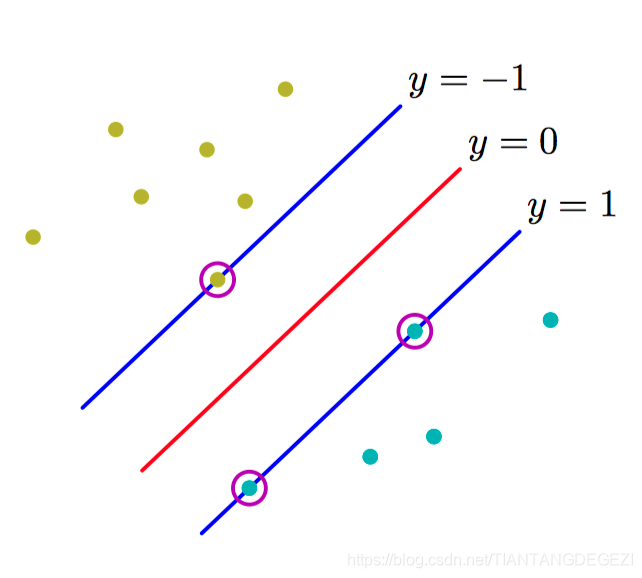
在⽀持向量机中,决策边界被选为使边缘最⼤化的那个决策边界。
点 x \boldsymbol{x} x 距离由 y ( x ) = 0 y(\boldsymbol{x})=0 y(x)=0 定义的超平⾯的垂直距离为 ∣ y ( x ) ∣ ∥ w ∥ \frac{|y(\boldsymbol{x})|}{\|\boldsymbol{w}\|} ∥w∥∣y(x)∣ ,其中 y ( x ) y(\boldsymbol{x}) y(x) 的函数形式由公式(7.1)给出,我们感兴趣的是那些能够正确分类所有数据点的解,即对于所有的 n n n 都有 t n y ( x n ) > 0 t_ny(\boldsymbol{x}_n)>0 tny(xn)>0 ,因此点 x n \boldsymbol{x}_n xn 距离决策⾯的距离为
t n y ( x n ) ∥ w ∥ = t n ( w T ϕ ( x n ) + b ) ∥ w ∥ (7.2) \frac{t_ny(\boldsymbol{x}_n)}{\|\boldsymbol{w}\|}=\frac{t_n(\boldsymbol{w}^{T}\boldsymbol{\phi}(\boldsymbol{x}_n)+b)}{\|\boldsymbol{w}\|}\tag{7.2} ∥w∥tny(xn)=∥w∥tn(wTϕ(xn)+b)(7.2)
边缘由数据集⾥垂直距离最近的点 x n \boldsymbol{x}_n xn 给出,希望最优化参数 w \boldsymbol{w} w 和 b b b ,使得这个距离能够最⼤化。因此最⼤边缘解可以通过下式得到:
arg max w , b { 1 ∥ w ∥ min n [ t n ( w T ϕ ( x n ) + b ) ] } (7.3) \underset{\boldsymbol{w}, b}{\arg \max}\left\{\frac{1}{\|\boldsymbol{w}\|} \min _{n}\left[t_{n}\left(\boldsymbol{w}^{T} \boldsymbol{\phi}\left(\boldsymbol{x}_{n}\right)+b\right)\right]\right\}\tag{7.3} w,bargmax{ ∥w∥1nmin[tn(wTϕ(xn)+b)]}(7.3)
注意到如果进⾏重新标度 w → κ w \boldsymbol{w}\to\kappa\boldsymbol{w} w→κw 以及 b → κ b b\to\kappa{b} b→κb , 那么任意点 x n \boldsymbol{x}_n xn 距离决策⾯的距离 t n y ( x n ) ∥ w ∥ \frac{t_ny(\boldsymbol{x}_n)}{\|\boldsymbol{w}\|} ∥w∥tny(xn) 不会发⽣改变。利用这个性质,对于距离决策⾯最近的点,令
t n ( w T ϕ ( x n ) + b ) = 1 t_n(\boldsymbol{w}^{T}\boldsymbol{\phi}(\boldsymbol{x}_n)+b)=1 tn(wTϕ(xn)+b)=1
在这种情况下,所有的数据点会满⾜限制
t n ( w T ϕ ( x n ) + b ) ≥ 1 , n = 1 … , N t_n(\boldsymbol{w}^{T}\boldsymbol{\phi}(\boldsymbol{x}_n)+b)\ge1, n=1\dots,N tn(wTϕ(xn)+b)≥1,n=1…,N
这被称为决策超平⾯的标准表⽰。 对于使上式取得等号的数据点,我们说限制被激活(active),对于其他的数据点,我们说限制未激活(inactive)。根据定义,总会存在⾄少⼀个激活限制,因为总会有⼀个距离最近的点,并且⼀旦边缘被最⼤化,会有⾄少两个激活的限制。这样,最优化问题就简化为了最⼤化 ∥ w ∥ − 1 \|\boldsymbol{w}\|^{-1} ∥w∥−1 ,这等价于最⼩化 ∥ w ∥ 2 \|\boldsymbol{w}\|^2 ∥w∥2 ,因此我们要在上述限制条件下,求解最优化问题
arg min w , b 1 2 ∥ w ∥ 2 \underset{\boldsymbol{w},b}{\arg\min}\frac{1}{2}\|\boldsymbol{w}\|^{2} w,bargmin21∥w∥2
为了解决这个限制的最优化问题,引⼊拉格朗⽇乘数 a n ≥ 0 a_n\ge0 an≥0 。每个限制条件都对应着⼀个乘数 a n a_n an ,从⽽可得下⾯的拉格朗⽇函数
L ( w , b , a ) = 1 2 ∥ w ∥ 2 − ∑ n = 1 N a n { t n ( w T ϕ ( x n ) + b ) − 1 } (7.4) L(\boldsymbol{w},b,\boldsymbol{a})=\frac{1}{2}\|\boldsymbol{w}\|^{2}-\sum_{n=1}^{N}a_n\{t_n(\boldsymbol{w}^{T}\boldsymbol{\phi}(\boldsymbol{x}_n)+b)-1\}\tag{7.4} L(w,b,a)=21∥w∥2−n=1∑Nan{ tn(wTϕ(xn)+b)−1}(7.4)
其中 a = ( a 1 , … , a N ) T \boldsymbol{a} = (a_1,\dots,a_N)^{T} a=(a1,…,aN)T 。令 L ( w , b , a ) L(\boldsymbol{w},b,\boldsymbol{a}) L(w,b,a) 关于 w \boldsymbol{w} w 和 b b b 的导数等于零,有
w = ∑ n = 1 N a n t n ϕ ) ( x n ) ∑ n = 1 N a n t n = 0 \boldsymbol{w}=\sum_{n=1}^{N}a_nt_n\boldsymbol{\phi})(\boldsymbol{x}_n)\\ \sum_{n=1}^{N}a_nt_n=0 w=n=1∑Nantnϕ)(xn)n=1∑Nantn=0
使⽤这两个条件从 L ( w , b , a ) L(\boldsymbol{w},b,\boldsymbol{a}) L(w,b,a) 中消去 a \boldsymbol{a} a 和 b b b ,就得到了最⼤化边缘问题的对偶表⽰(dual representation),其中要关于 a \boldsymbol{a} a 最⼤化
L ~ ( a ) = ∑ n = 1 N a n − 1 2 ∑ n = 1 N ∑ m = 1 N a n a m t n t m k ( x n , x m ) (7.5) \tilde{L}(\boldsymbol{a})=\sum_{n=1}^{N}a_n-\frac{1}{2}\sum_{n=1}^{N}\sum_{m=1}^{N}a_na_mt_nt_mk(\boldsymbol{x}_n,\boldsymbol{x}_m)\tag{7.5} L~(a)=n=1∑Nan−21n=1∑Nm=1∑Nanamtntmk(xn,xm)(7.5)
其中 k ( x , x ′ ) = ϕ ( x ) T ϕ ( x ′ ) k(\boldsymbol{x},\boldsymbol{x}^{\prime})=\boldsymbol{\phi}(\boldsymbol{x})^{T}\boldsymbol{\phi}(\boldsymbol{x}^{\prime}) k(x,x′)=ϕ(x)Tϕ(x′),限制条件为
a n ≥ 0 , n = 1 … , N ∑ n = 1 N a n t n = 0 a_n\ge0,n=1\dots,N\\ \sum_{n=1}^{N}a_nt_n=0 an≥0,n=1…,Nn=1∑Nantn=0
通过使⽤公式消去 w \boldsymbol{w} w , y ( x ) y(\boldsymbol{x}) y(x) 可以根据参数 { a n } \{a_n\} { an} 和核函数表⽰,即
y ( x ) = ∑ n = 1 N a n t n k ( x , x n ) + b (7.6) y(\boldsymbol{x})=\sum_{n=1}^{N}a_nt_nk(\boldsymbol{x},\boldsymbol{x}_n)+b\tag{7.6} y(x)=n=1∑Nantnk(x,xn)+b(7.6)
满足如下性质:
a n ≥ 0 t n y ( x n ) − 1 ≥ 0 a n { t n y ( x n ) − 1 } = 0 a_n\ge0\\ t_ny(\boldsymbol{x}_n)-1\ge0\\ a_n\{t_ny(\boldsymbol{x}_n)-1\}=0 an≥0tny(xn)−1≥0an{ tny(xn)−1}=0
因此对于每个数据点,要么 a n = 0 a_n = 0 an=0 ,要么 t n y ( x n ) = 1 t_n y(\boldsymbol{x}_n) = 1 tny(xn)=1 。任何使得 a n = 0 a_n = 0 an=0 的数据点都不会出现在公式(7.5)的求和式中,因此对新数据点的预测没有作⽤。剩下的数据点被称为⽀持向量(support vector)。
解决了⼆次规划问题,找到了 a \boldsymbol{a} a 的值之后,注意到⽀持向量 x n \boldsymbol{x}_n xn 满⾜ t n y ( x n ) = 1 t_ny(\boldsymbol{x}_n)=1 tny(xn)=1,就可以确定阈值参数 b b b 的值,可得
t n ( ∑ m ∈ S a m t m k ( x n , x m ) + b ) = 1 (7.7) t_n\left(\sum_{m\in{\mathcal{S}}}a_mt_mk(\boldsymbol{x}_n,\boldsymbol{x}_m)+b\right)=1\tag{7.7} tn(m∈S∑a
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1808
1808











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









