




本文主要交流设计思路,在本博客已给出相关博文一百多篇,希望对初学者有用。注意这里只是抛砖引玉,切莫认为参考这就可以完成商用IP设计。若有NVME或RDMA 产品及项目需求,请看B站视频后联系。
延迟是评估存储系统响应能力的核心指标, 更低的延迟代表着存储系统拥有更快
的响应速度。 NoP 逻辑加速引擎内部的性能监测单元提供了 NVMe 指令的延迟信息,
经过不同队列数量和深度的配置后, 执行 4KB 随机读写获取延迟, 计算得到平均延
迟信息。 使用 970EVO Plus、 970PRO 和 A2000 固态硬盘测试的延迟统计信息分别如
图 1、 图 2 和图 3 所示。
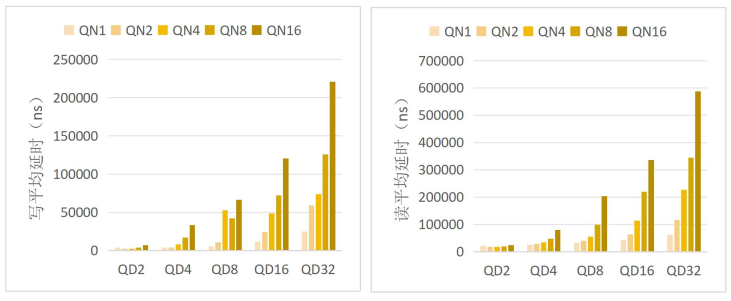
图1 970EVO Plus 4KB 随机读写平均延迟
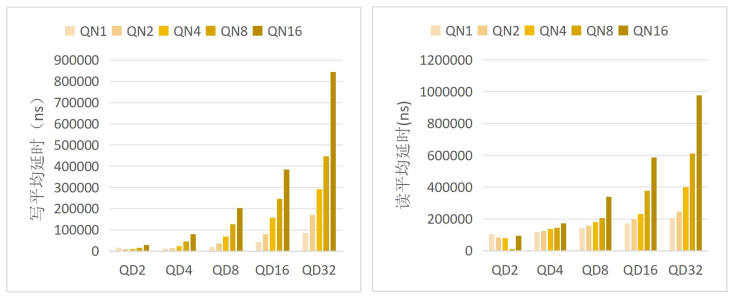
图2 970PRO 4KB 随机读写平均延迟
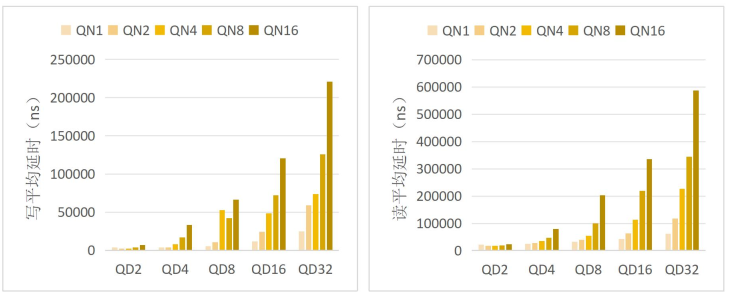
图3 A2000 4KB 随机读写平均延迟
从图中可以看到, 当队列数量不变时, 延迟随着队列深度的增加而增加, 当队列深度不变时, 队列数量的增加也会使延迟增加。 当队列数量和深度小时, 每当有指令放入 NVMe 提交队列, 就会触发 NVMe 指令提交与完成机制, SSD 在短时间内从 NoP逻辑加速引擎获取指令进行处理, 延迟也相对较小; 当队列深度增加时, 由于 SSD处理指令需要一定的时间, 指令在队列中排队的时间增加, 使得延迟增加; 当队列数量增加时, 请求仲裁的数量增加, 当多个队列同时请求仲裁时, 只有一个队列能够得到响应, 其余队列仍在排队, 因此增加了延迟。
B站已给出相关性能的视频,如想进一步了解,请搜索B站用户:专注与守望
链接:https://space.bilibili.com/585132944/dynamic?spm_id_from=333.1365.list.card_title.click

















 377
377

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









