







论文:https://arxiv.org/abs/2104.01136
代码(刚刚开源):
https://github.com/facebookresearch/LeViT
ABSTRACT
我们设计了一系列的图像分类体系结构,在优化精度和效率之间权衡。我们的工作利用了基于最新发现注意力的架构,该架构在高度并行处理硬件上具有竞争力。我们回顾了许多文献中的卷积神经网络原理,将其应用于 transformers,特别是分辨率降低的激活图。我们还介绍了视觉 transformers中位置信息整合的新方法——注意偏差。为此,我们提出了一种用于图像快速推理分类的混合神经网络LeVIT。我们在不同的硬件平台上考虑不同的效率度量,最好地反映广泛的应用场景。我们的大量实验验证了我们的技术选择,并表明它们适用于大多数架构。总的来说,LeViT在速度/精度权衡方面显著优于现有的卷积网络和视觉 transformers。例如,在ImageNet top-1的80%精度下,LeViT在CPU上比EfficientNet快5倍。
Intruction
transformers神经网络最初是为自然语言处理应用[1]而引入的。他们现在在这一领域的大多数应用中占主导地位。它们操纵提供给残差结构的可变大小的嵌入序列。该模型包括两种残块:多层感知器(multilayer Perceptron, MLP)和一种原始类型的层:自我注意,它允许输入中的所有符号通过双线性函数组合.这与一维卷积方法相反,后者被限制在一个固定大小的邻域。近年来,视觉transformers(ViT)架构[2]在大规模数据集的预训练与速度精度的权衡中获得了最先进的图像分类结果。当仅在ImageNet[4]上训练ViT模型时,数据效率高的图像转换器[3]获得了最有竞争力的性能。它还引入了适合于高吞吐量推理的更小的模型。在本文中,我们探索了在中小型架构中提供比ViT/DeiT模型更好的权衡的设计空间。我们对优化性能精度的折衷特别感兴趣,比如图1中Imagenet-1k-val[5]所描述的吞吐量(图像/秒)性能。
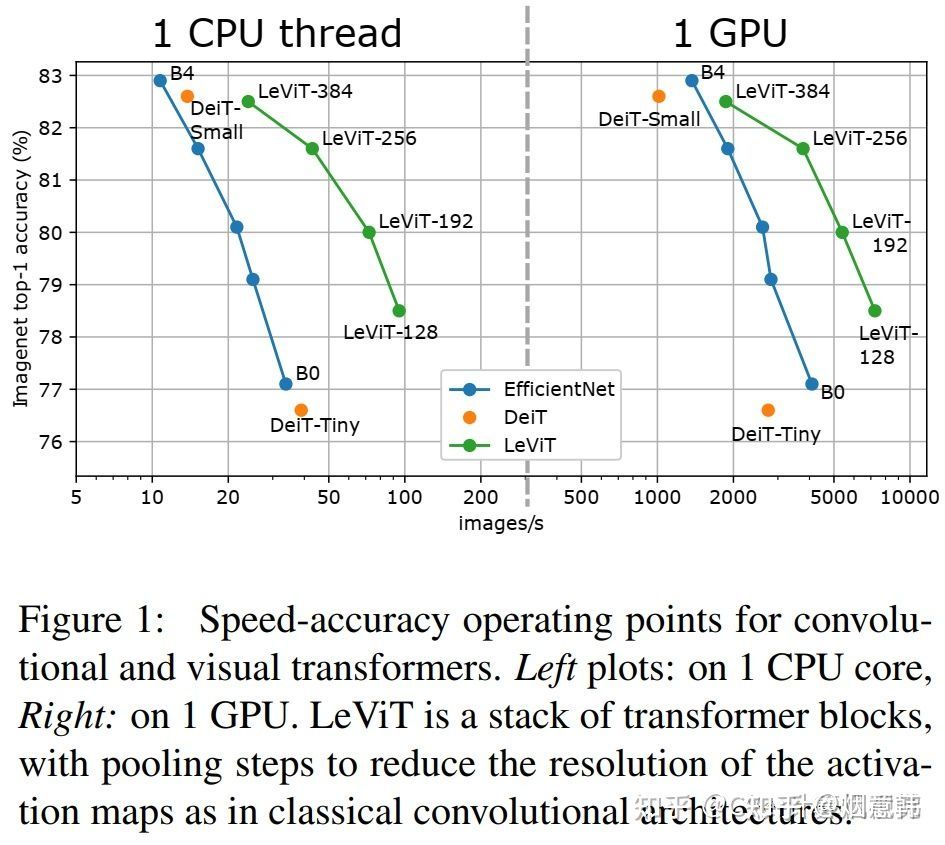
虽然许多研究的目标是减少分类器和特征提取器的内存占用,但推理速度同样重要,高吞吐量对应更好的能量效率。在这项工作中,我们的目标是开发一个基于Vision transformer的模型家族,在GPU、常规Intel cpu和移动设备中常见的ARM硬件等高度并行架构上具有更好的推理速度。我们的解决方案重新引入了卷积组件,以取代学习卷积类特性的transformers组件。特别是,我们将Transformer的统一结构替换为带池的金字塔,类似于LeNet[11]架构。因此我们称之为LeViT。在给定的计算复杂度下,transformers比卷积架构更快,这是有令人信服的原因的。大多数硬件加速器(gpu、TPUs)都经过优化以执行大型矩阵乘法。在transformers中,注意和MLP块主要依赖于这些操作。相反,卷积需要复杂的数据访问模式,因此它们的操作通常是io绑定的。这些考虑对于我们探索速度/准确性的权衡是很重要的。
本文的贡献是允许ViT模型在宽度和空间分辨率方面缩小的技术:使用注意力作为降采样机制的多级变压器体系结构;一个计算效率高的 patch descriptor,可以在第一层中减少特征的数量;一个习得的,不变的注意偏差,取代了ViT的位置嵌入;一个重新设计的Attention-MLP块,在给定的计算时间内提高网络容量。
Related Work
从LeNet演化而来的卷积网络随着时间的推移已经有了很大的发展。最近的体系结构家族关注于在效率和性能之间找到一个好的平衡点。例如,通过在FLOPs约束下仔细设计单个组件,然后进行超参数搜索,发现了EfficientNet[17]系列。
transformer架构最初是由Vaswani等人[1]为机器翻译引入的。 transformer编码器主要依靠与前馈层结合的自注意操作,为学习长期依赖关系提供了一种强大而显式的方法。变压器随后被用于NLP任务,在各种基准上提供最先进的性能[20,21]。已经有许多尝试将 transformer架构应用于图像[22,23],首先是将它们应用于像素上。由于二次计算复杂性和注意机制涉及的参数数量,大多数作者[23,24]最初考虑的是小尺寸的图像,如CIFAR或Imagenet64[25]。混合文本和图像嵌入已经使用带有检测边界框的变压器作为输入[2
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 576
576











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











