









 布隆过滤器是一种高效的数据结构,用于快速判断元素是否存在于集合中,尤其适用于大数据量场景,如垃圾邮件过滤、网页爬虫去重等。本文介绍了布隆过滤器的工作原理及其与其他解决方案的对比。
布隆过滤器是一种高效的数据结构,用于快速判断元素是否存在于集合中,尤其适用于大数据量场景,如垃圾邮件过滤、网页爬虫去重等。本文介绍了布隆过滤器的工作原理及其与其他解决方案的对比。
Bloom Filter是一个占用空间很小、效率很高的随机数据结构,它由一个bit数组和一组Hash算法构成。可用于判断一个元素是否在一个集合中,查询效率很高(1-N,最优能逼近于1)。
在很多场景下,我们都需要一个能迅速判断一个元素是否在一个集合中。譬如:
网页爬虫对URL的去重,避免爬取相同的URL地址;
反垃圾邮件,从数十亿个垃圾邮件列表中判断某邮箱是否垃圾邮箱(同理,垃圾短信);
缓存击穿,将已存在的缓存放到布隆中,当黑客访问不存在的缓存时迅速返回避免缓存及DB挂掉。
可能有人会问,我们直接把这些数据都放到数据库或者redis之类的缓存中不就行了,查询时直接匹配不就OK了?
是的,当这个集合量比较小,你内存又够大时,是可以这样做,你可以直接弄个HashSet、HashMap就OK了。但是当这个量以数十亿计,内存装不下,数据库检索极慢时该怎么办。
以垃圾邮箱为例
方案比较
1.将所有垃圾邮箱地址存到数据库,匹配时遍历
2.用HashSet存储所有地址,匹配时接近O(1)的效率查出来
3.将地址用MD5算法或其他单向映射算法计算后存入HashSet,无论地址多大,保存的只有MD5后的固定位数
4.布隆过滤器,将所有地址经过多个Hash算法,映射到一个bit数组
优缺点
方案1和2都是保存完整的地址,占用空间大。一个地址16字节,10亿即可达到上百G的内存。HashSet效率逼近O(1),数据库就不谈效率了,不在一个数量级。
方案3保存部分信息,占用空间小于存储完整信息,存在冲突的可能(非垃圾邮箱可能MD5后和某垃圾邮箱一样,概率低)
方案4将所有地址经过Hash后映射到
同一个bit数组,看清了,只有一个超大的bit数组,保存所有的映射,占用空间极小,冲突概率高。
大家知道,java中的HashMap有个扩容参数默认是0.75,也就是你想存75个数,至少需要一个100的数组,而且还会有不少的冲突。实际上,Hash的存储效率是0.5左右,存5个数需要10个的空间。算起来占用空间还是挺大的。
而布隆过滤器就不用为每个数都分配空间了,而是直接把所有的数通过算法映射到同一个数组,带来的问题就是冲突上升,只要概率在可以接受的范围,用时间换空间,在很多时候是好方案。布隆过滤器需要的空间仅为HashMap的1/8-1/4之间,而且它不会漏掉任何一个在黑名单的可疑对象,问题只是会误伤一些非黑名单对象。
原理
初始化状态是一个全为0的bit数组

为了表达存储N个元素的集合,使用K个独立的函数来进行哈希运算。x1,x2……xk为k个哈希算法。
如果集合元素有N1,N2……NN,N1经过x1运算后得到的结果映射的位置标1,经过x2运算后结果映射也标1,已经为1的报错1不变。经过k次散列后,对N1的散列完成。
依次对N2,NN等所有数据进行散列,最终得到一个部分为1,部分位为0的字节数组。当然了,这个字节数组会比较长,不然散列效果不好。
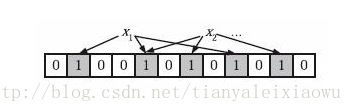
那么怎么判断一个外来的元素是否已经在集合里呢,譬如已经散列了10亿个垃圾邮箱,现在来了一个邮箱,怎么判断它是否在这10亿里面呢?
很简单,就拿这个新来的也依次经历x1,x2……xk个哈希算法即可。
在任何一个哈希算法譬如到x2时,得到的映射值有0,那就说明这个邮箱肯定不在这10亿内。
如果是一个黑名单对象,那么可以肯定的是所有映射都为1,肯定跑不了它。也就是说是坏人,一定会被抓。
那么误伤是为什么呢,就是指一些非黑名单对象的值经过k次哈希后,也全部为1,但它确实不是黑名单里的值,这种概率是存在的,但是是可控的。



上面的几个图看起来很高深,但那不是我们关心的问题,归根到底意思其实就是你想让错误率降低,就得增大数组的长度,就是这样。
我们使用BloomFilter的目的就是想省空间,所以我们需要做的就是在错误率上做个权衡就OK。
很多时候这个错误率我们是能接受的,譬如垃圾邮箱问题,是坏人一定会被抓,这个能保证。无非是一些好人也被抓,这个可以通过给这些可伶的被误伤的设置个白名单就OK。至于爬虫Url重复这个就更没问题了,会缺掉一些网页而已。
至于在缓存穿透上的应用,是为了避免恶意用户频繁请求缓存中不存在DB也不存在的值,会导致缓存失效、DB负载过大,可以使用BloomFilter把所有数据放到bit数组中,当用户请求时存在的值肯定能放行,部分不存在的值也会被放行,绝大部分会被拦截,这些少量漏网之鱼对于DB的影响就会比大量穿透好的多了。
讲了这么多,可以看到,原理很简单,但要实际做一个BloomFilter可就麻烦了,已经属于科学家的范畴了,好在早早有人已经搞定了java版的实现,用法很简单,下一篇看看。


















 916
916

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











