









本人自学Hadoop也有一段时间了,由于最近工作不太忙,想利用业余空闲时间来实现一下基于Hadoop的ETL,不过本人不太清楚别人是怎么实现的,而且网上资料有限,可能会是一个坑,不过感觉和大家分享下,还是有些帮助的,也借此做下笔记。
现在阶段的大数据的ETL主要分为三个阶段:抽取、转换、加载,如图
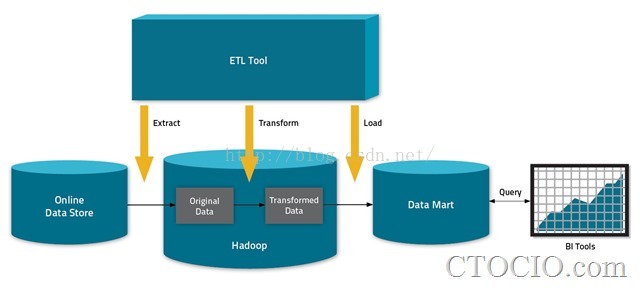
这三个阶段具体到实际项目中也就是数据的导入、数据的分析以及数据的导出。
数据的导入:一般来说我们操作的数据分为三种:结构化的数据(如mysql等结构化的数据)、半结构化的数据(Mogodb、Hbase等)以及分结构话的数据(如一些日志信息等);而对于数据的导入就是把这些需要处理的数据从本地磁盘移到Hadoop的HDFS中,以便后续的利用Hadoop的进行大数据的分析;我们一般对于结构化与半结构化数据的导入使用Sqoop工具进行数据的导入,而对于非结构话的数据一般是使用HDFS的命令进行数据的操作;
数据的分析:所谓数据的分析,就是根据项目需要,利用Hadoop的大数据分析的能力对数据进行处理,转换出我们想要的数据,这个阶段对于非结构话的数据的处理一般需要自己编写MapReduce程序,但是对于结构和半结构化的数据我们就不需要那么麻烦了,可以使用Hive进行数据的处理;
数据的导出:这一阶段就是把上一阶段分析的结果,导出到磁盘上数据库中,用于页面展示等用途。这一阶段主要是应用sqoop工具进行数据的导出。
分析到这里,基本上的实现思路也就明了了,我们需要三个核心处理过程,对应于import.sh、hive.sh、export.sh、flow.sh(用于数据处理流程的处理)以及sqoop.sh(用于封装一些sqoop的基本参数和命令,简化导入导出命令)。在这里我们暂时只对结构化数据处理进行分析,其他的数据暂不做分析。在下一篇中我们将进行数据的导入篇。















 1485
1485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









