







学习openmv第一天(openmv脱机处理 颜色识别 寻找色块 模板匹配ncc 特征点检测)
1_openmv脱机处理
将代码保存到内置的flash里即可

选择5v锂电池供电即可
2_openmv颜色识别 寻找色块
更改阈值 想要的颜色调为白色
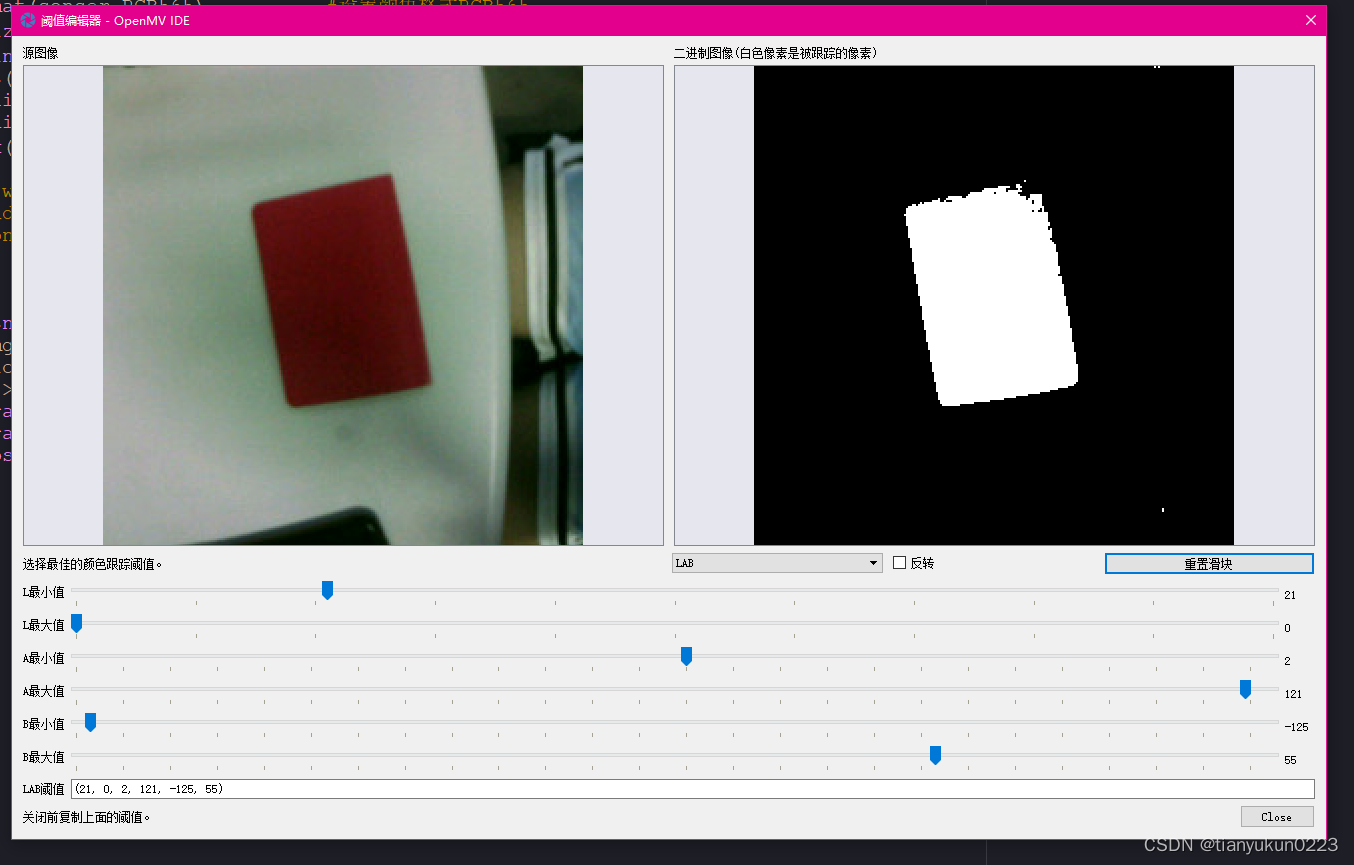
识别的效果 识别出红色并且标出白框
代码如下 已打注释
# IR Beacon RGB565 Tracking Example
#
# This example shows off IR beacon RGB565 tracking using the OpenMV Cam.
import sensor, image, time
thresholds = ((21, 0, 2, 121, -125, 55)) # thresholds for bright white light from IR.设置阈值
sensor.reset() #重置感光元件
sensor.set_pixformat(sensor.RGB565) #设置颜色格式RGB565
sensor.set_framesize(sensor.QVGA) #设置图像大小QVGA
sensor.set_windowing((240, 240)) # 240x240 center pixels of VGA # 从VGA图像中裁剪出240x240大小的中心区域
sensor.skip_frames(time = 2000) # 跳过2000ms(2秒)的帧以让感光元件稳定
sensor.set_auto_gain(False) # must be turned off for color tracking
sensor.set_auto_whitebal(False) # must be turned off for color tracking #关闭白平衡和自动增益 会影响颜色识别的效果
clock = time.clock()
# Only blobs that with more pixels than "pixel_threshold" and more area than "area_threshold" are
# returned by "find_blobs" below. Change "pixels_threshold" and "area_threshold" if you change the
# camera resolution. "merge=True" merges all overlapping blobs in the image.
while(True):
clock.tick() # 记录时间
img = sensor.snapshot() # 捕获图像
for blob in img.find_blobs([thresholds], pixels_threshold=200, area_threshold=200, merge=True):
# 对找到的斑点进行处理,过滤掉非近似正方形的斑点
ratio = blob.w() / blob.h() # 计算斑点的宽高比
if (ratio >= 0.5) and (ratio <= 1.5): # 过滤掉宽高比不在0.5和1.5之间的斑点,保留近似正方形的斑点
img.draw_rectangle(blob.rect()) # 在图像上绘制斑点的矩形边界框
img.draw_cross(blob.cx(), blob.cy()) # 在图像上绘制斑点的中心交叉十字
print(clock.fps()) # 打印帧率
3_模板匹配ncc
缺点识别精度有点低 必须和模板图片一样位置 一样大小角度 才有几率识别到,21年电赛送药小车 数字识别 可以用openmv ncc模板怕匹配 但精度实在是太低 根本用不了 后面转神经网络训练目标检测了
图片中例子 识别出4 标上白框 低下print识别出为4
图片必须是pgm格式 放到openmv里面
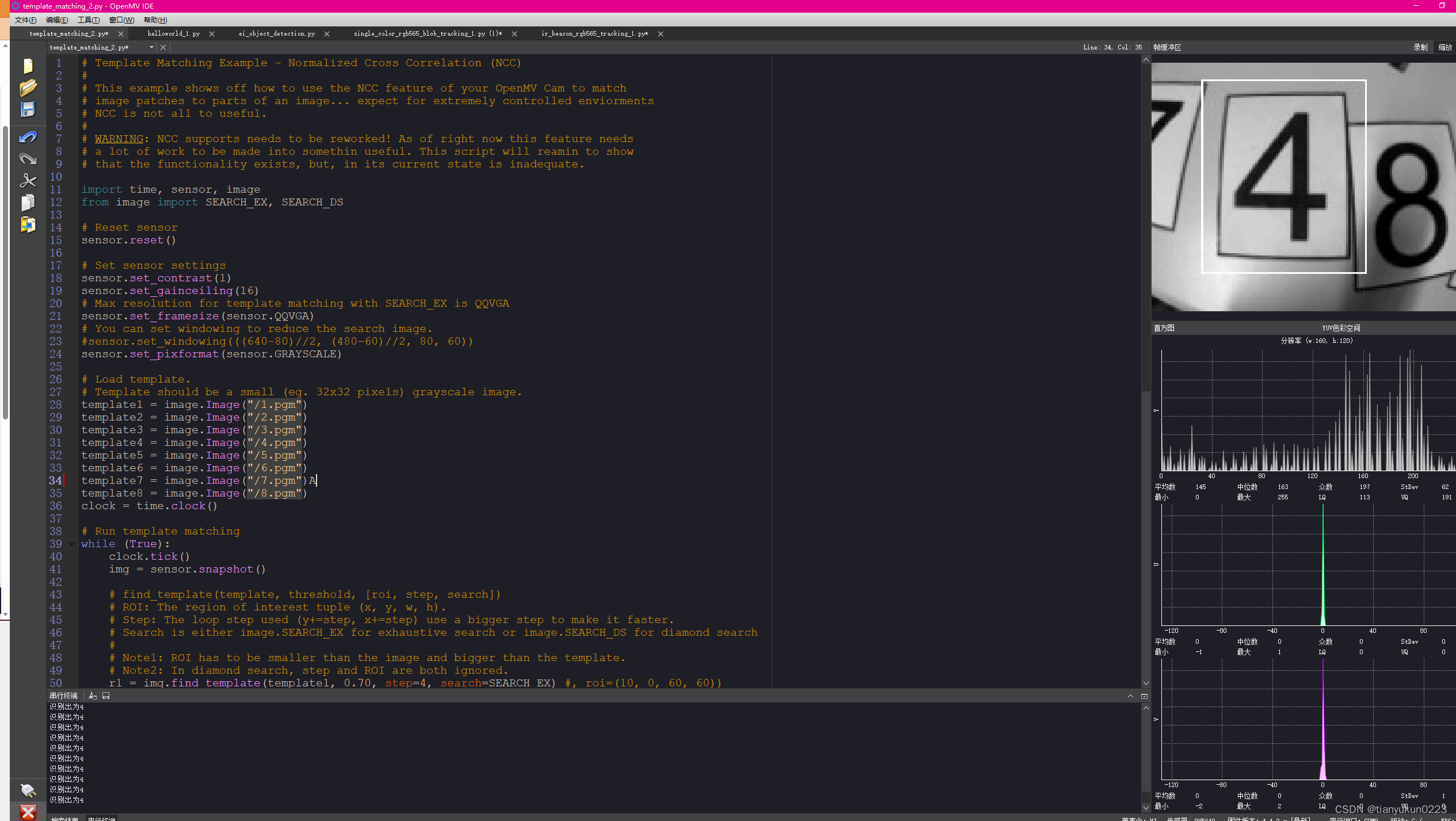
代码块
# Template Matching Example - Normalized Cross Correlation (NCC)
#
# This example shows off how to use the NCC feature of your OpenMV Cam to match
# image patches to parts of an image... expect for extremely controlled enviorments
# NCC is not all to useful.
#
# WARNING: NCC supports needs to be reworked! As of right now this feature needs
# a lot of work to be made into somethin useful. This script will reamin to show
# that the functionality exists, but, in its current state is inadequate.
import time, sensor, image
from image import SEARCH_EX, SEARCH_DS
# Reset sensor
sensor.reset()
# Set sensor settings
sensor.set_contrast(1)
sensor.set_gainceiling(16)
# Max resolution for template matching with SEARCH_EX is QQVGA
sensor.set_framesize(sensor.QQVGA)
# You can set windowing to reduce the search image.
#sensor.set_windowing(((640-80)//2, (480-60)//2, 80, 60))
sensor.set_pixformat(sensor.GRAYSCALE)
# Load template.
# Template should be a small (eg. 32x32 pixels) grayscale image.
template1 = image.Image("/1.pgm")
template2 = image.Image("/2.pgm")
template3 = image.Image("/3.pgm")
template4 = image.Image("/4.pgm")
template5 = image.Image("/5.pgm")
template6 = image.Image("/6.pgm")
template7 = image.Image("/7.pgm")A
template8 = image.Image("/8.pgm")
clock = time.clock()
# Run template matching
while (True):
clock.tick()
img = sensor.snapshot()
# find_template(template, threshold, [roi, step, search])
# ROI: The region of interest tuple (x, y, w, h).
# Step: The loop step used (y+=step, x+=step) use a bigger step to make it faster.
# Search is either image.SEARCH_EX for exhaustive search or image.SEARCH_DS for diamond search
#
# Note1: ROI has to be smaller than the image and bigger than the template.
# Note2: In diamond search, step and ROI are both ignored.
r1 = img.find_template(template1, 0.70, step=4, search=SEARCH_EX) #, roi=(10, 0, 60, 60))
if r1:
img.draw_rectangle(r1)
print("识别出为1")
r2 = img.find_template(template2, 0.70, step=4, search=SEARCH_EX) #, roi=(10, 0, 60, 60))
if r2:
img.draw_rectangle(r2)
print("识别出为2")
r3 = img.find_template(template3, 0.70, step=4, search=SEARCH_EX) #, roi=(10, 0, 60, 60))
if r3:
img.draw_rectangle(r3)
print("识别出为3")
r4 = img.find_template(template4, 0.70, step=4, search=SEARCH_EX) #, roi=(10, 0, 60, 60))
if r4:
img.draw_rectangle(r4)
print("识别出为4")
r5 = img.find_template(template5, 0.70, step=4, search=SEARCH_EX) #, roi=(10, 0, 60, 60))
if r5:
img.draw_rectangle(r5)
print("识别出为5")
r6 = img.find_template(template6, 0.70, step=4, search=SEARCH_EX) #, roi=(10, 0, 60, 60))
if r6:
img.draw_rectangle(r6)
print("识别出为6")
r7 = img.find_template(template7, 0.70, step=4, search=SEARCH_EX) #, roi=(10, 0, 60, 60))
if r7:
img.draw_rectangle(r7)
print("识别出为7")
r8 = img.find_template(template8, 0.70, step=4, search=SEARCH_EX) #, roi=(10, 0, 60, 60))
if r8:
img.draw_rectangle(r8)
print("识别出为8")
#print(clock.fps())
3_特征点检测
本例程会把程序运行最开始的十秒左右出现的物体作为目标特征,请在程序运行的最开始,将目标物体放在摄像头中央识别,直至出现特征角点,证明已经识别记录目标特征。
例如图片中这样

匹配过程中,如果画面出现十字和矩形框,证明匹配成功。

模板匹配和特征点检测的比较:
模板匹配(find_temolate)采用的是ncc算法,只能匹配与模板图片大小和角度基本一致的图案。局限性相对来说比较大,视野中的目标图案稍微比模板图片大一些或者小一些就可能匹配不成功。
模板匹配适应于摄像头与目标物体之间距离确定,不需要动态移动的情况。比如适应于流水线上特定物体的检测,而不适应于小车追踪一个运动的排球(因为运动的排球与摄像头的距离是动态的,摄像头看到的排球大小会变化,不会与模板图片完全一样)。
多角度多大小匹配可以尝试保存多个模板,采用多模板匹配。
特征点检测(find_keypoint): 如果是刚开始运行程序,例程提取最开始的图像作为目标物体特征,kpts1保存目标物体的特征。默认会匹配目标特征的多种比例大小和角度,而不仅仅是保存目标特征时的大小角度,比模版匹配灵活,也不需要像多模板匹配一样保存多个模板图像。
特征点检测,也可以提前保存目标特征,之前是不推荐这么做的,因为环境光线等原因的干扰,可能导致每次运行程序光线不同特征不同,匹配度会降低。但是最新版本的固件中,增加了对曝光度、白平衡、自动增益值的调节,可以人为的定义曝光值和白平衡值,相对来说会减弱光线的干扰。也可以尝试提前保存目标特征。
代码如下
# 利用特征点检测特定物体例程。
# 向相机显示一个对象,然后运行该脚本。 一组关键点将被提取一次,然后
# 在以下帧中进行跟踪。 如果您想要一组新的关键点,请重新运行该脚本。
# 注意:请参阅文档以调整find_keypoints和match_keypoints。
import sensor, time, image
# 重置传感器
sensor.reset()
# 传感器设置
sensor.set_contrast(3) #设置对比度3
sensor.set_gainceiling(16) #设置自动增益16
sensor.set_framesize(sensor.QVGA)
sensor.set_windowing((320, 240))
sensor.set_pixformat(sensor.GRAYSCALE) #设置灰度图
sensor.skip_frames(time = 2000)
sensor.set_auto_gain(False, value=100)
#画出特征点
def draw_keypoints(img, kpts):
if kpts:
print(kpts)
img.draw_keypoints(kpts)
img = sensor.snapshot()
time.sleep_ms(1000)
kpts1 = None
#kpts1保存目标物体的特征,可以从文件导入特征,但是不建议这么做。
#kpts1 = image.load_descriptor("/desc.orb")
#img = sensor.snapshot()
#draw_keypoints(img, kpts1)
clock = time.clock()
while (True):
clock.tick()
img = sensor.snapshot() #截取一张图片
if (kpts1 == None):
#如果是刚开始运行程序,提取最开始的图像作为目标物体特征,kpts1保存目标物体的特征
#默认会匹配目标特征的多种比例大小,而不仅仅是保存目标特征时的大小,比模版匹配灵活。
# NOTE: By default find_keypoints returns multi-scale keypoints extracted from an image pyramid.
kpts1 = img.find_keypoints(max_keypoints=150, threshold=10, scale_factor=1.2)
#image.find_keypoints(roi=Auto, threshold=20, normalized=False, scale_factor=1.5, max_keypoints=100, corner_detector=CORNER_AGAST)
#roi表示识别的区域,是一个元组(x,y,w,h),默认与framsesize大小一致。
#threshold是0~255的一个阈值,用来控制特征点检测的角点数量。用默认的AGAST特征点检测,这个阈值大概是20。用FAST特征点检测,这个阈值大概是60~80。阈值越低,获得的角点越多。
#normalized是一个布尔数值,默认是False,可以匹配目标特征的多种大小(比ncc模版匹配效果灵活)。如果设置为True,关闭特征点检测的多比例结果,仅匹配目标特征的一种大小(类似于模版匹配),但是运算速度会更快一些。
#scale_factor是一个大于1.0的浮点数。这个数值越高,检测速度越快,但是匹配准确率会下降。一般在1.35~1.5左右最佳。
#max_keypoints是一个物体可提取的特征点的最大数量。如果一个物体的特征点太多导致RAM内存爆掉,减小这个数值。
#corner_detector是特征点检测采取的算法,默认是AGAST算法。FAST算法会更快但是准确率会下降。
draw_keypoints(img, kpts1)
#画出此时的目标特征
else:
# 当与最开始的目标特征进行匹配时,默认设置normalized=True,只匹配目标特征的一种大小。
# NOTE: When extracting keypoints to match the first descriptor, we use normalized=True to extract
# keypoints from the first scale only, which will match one of the scales in the first descriptor.
kpts2 = img.find_keypoints(max_keypoints=150, threshold=10, normalized=True)
#如果检测到特征物体
if (kpts2):
#匹配当前找到的特征和最初的目标特征的相似度
match = image.match_descriptor(kpts1, kpts2, threshold=85) #########来比较两个物体的相似度
#image.match_descriptor(descritor0, descriptor1, threshold=70, filter_outliers=False)。本函数返回kptmatch对象。
#threshold阈值设置匹配的准确度,用来过滤掉有歧义的匹配。这个值越小,准确度越高。阈值范围0~100,默认70
#filter_outliers默认关闭。
#match.count()是kpt1和kpt2的匹配的近似特征点数目。
#如果大于10,证明两个特征相似,匹配成功。
if (match.count()>10): ####提取到的特征点数量>10
# If we have at least n "good matches"
# Draw bounding rectangle and cross.
#在匹配到的目标特征中心画十字和矩形框。
img.draw_rectangle(match.rect())
img.draw_cross(match.cx(), match.cy(), size=10)
#match.theta()是匹配到的特征物体相对目标物体的旋转角度。
print(kpts2, "matched:%d dt:%d"%(match.count(), match.theta()))
# 不建议draw_keypoints画出特征关键点。
# 注意:如果你想绘制关键点,取消注释
#img.draw_keypoints(kpts2, size=KEYPOINTS_SIZE, matched=True)
#打印帧率。
img.draw_string(0, 0, "FPS:%.2f"%(clock.fps()))














 6665
6665











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









