







Direct3D: Scalable Image-to-3D Generation via 3D Latent Diffusion Transformer
摘要
生成高质量的3D资产长期以来面临挑战,主要原因在于缺乏能够捕捉复杂几何分布的可扩展3D表示方法。本文提出了Direct3D——一种原生3D生成模型,可直接从单张图像生成3D形状,无需依赖多视角扩散模型或SDS优化。Direct3D包含两个核心组件:
- D3D-VAE:通过半连续表面采样策略直接监督几何解码,将高分辨率3D形状编码为紧凑的三平面(triplane)潜在空间。
- D3D-DiT:专为三平面潜在空间设计的扩散Transformer,融合像素级(DINOv2)和语义级(CLIP)图像条件,实现与输入图像高度一致的3D生成。
实验表明,Direct3D在生成质量和泛化能力上显著优于现有方法,为3D内容创建树立了新标杆。
1 引言
研究背景
当前3D生成方法常依赖多视角扩散模型生成中间视图,再通过稀疏重建或SDS优化生成3D形状。此类方法效率低且受限于多视角生成质量。
Direct3D提出直接训练原生3D扩散模型,利用三平面潜在空间解决现有隐式表示(如Shap-E、Michelangelo)的结构信息丢失问题。
核心贡献
- D3D-VAE:首次实现高分辨率3D形状到显式三平面潜在空间的高效编码,通过半连续表面采样直接监督几何重建。
- D3D-DiT:可扩展的图像条件3D扩散Transformer,通过跨注意力机制融合图像语义与像素级信息。
- 实验验证:大规模预训练模型在生成质量、几何细节和泛化能力上超越现有方法。
2 方法
2.1 D3D-VAE:直接3D变分自编码器
点云到潜在编码器
- 输入:81,920个带法向量的表面点云
- 处理流程:
- 傅里叶特征编码点云位置
- 交叉注意力层将点云特征注入可学习token
- 8层自注意力层增强特征表示
潜在到三平面解码器
- 结构设计:
- 将3×r×r潜在张量重组为r×3r三平面
- 5层ResNet块上采样至256×256分辨率三平面特征
半连续表面采样策略
- 采样方法:
- 均匀采样20,480个空间点
- 表面附近采样20,480个点
- 监督信号:
- 表面距离阈值s=1/512时采用连续值(0.5±0.5sdf/s)
- 阈值外使用离散0/1监督
端到端优化
- 损失函数:
- 二元交叉熵损失(LBCE)
- KL散度正则化(λKL=1e-6)
2.2 D3D-DiT:图像条件3D扩散Transformer
像素级对齐模块
- 特征提取:DINOv2(ViT-L/14)提取像素级图像特征
- 融合方式:
- 线性层投影至潜在空间维度
- 在DiT块中与噪声潜在token拼接后执行自注意力
语义级对齐模块
- 特征提取:CLIP(ViT-L/14)提取语义图像特征
- 融合方式:
- 跨注意力层交互语义token与潜在token
- 时间嵌入融合CLIP分类token
训练策略
- 噪声调度:1000步线性调度(1e-4至2e-2)
- 条件丢弃:10%概率随机屏蔽图像条件
- 推理优化:50步DDIM采样,指导系数7.5
3 实验
3.1 实现细节
D3D-VAE训练
- 硬件:NVIDIA A100 (80GB)
- 优化器:AdamW(lr=1e-4,100K步)
D3D-DiT训练
- 网络架构:DiT-XL/2(28层,16注意力头)
- 优化器:AdamW(lr=1e-4,800K步)
3.2 图像/文本到3D生成
图像到3D对比
- 对比方法:Shap-E、One-2-3-45、Michelangelo、InstantMesh
- 关键优势:
- 细节保留(如水龙头、车窗)
- 几何一致性(避免马腿粘连等错误)
文本到3D生成
- 流程:Hunyuan-DiT生成图像→Direct3D生成3D
- 用户研究:46名参与者评分(1-5分)
- 质量分:4.41 vs 基线最高2.53
- 一致性分:4.35 vs 基线最高2.66
纹理网格生成
- 后处理:SyncMVD纹理合成
- 效果展示:复杂雕刻(图腾柱)、精细结构(机甲装甲)
4 结论
创新总结
- 突破:首个可扩展的原生3D生成模型,支持开放域图像输入
- 技术亮点:
- 显式三平面编码+半连续监督
- 三平面扩散Transformer架构
局限与展望
- 当前限制:仅支持单物体生成,无法处理大规模场景
- 未来方向:
- 场景级生成
- 输入鲁棒性增强
附录
A.1 消融实验
显式三平面潜在空间
- 对比:1D隐式潜在(Michelangelo) vs 三平面显式
- 结果:三平面编码重建误差降低37%(图7)
半连续采样策略
- 对比:离散监督 vs 半连续监督
- 效果:薄壁结构重建成功率提升52%(图8)
2D U-Net vs D3D-DiT
- 对比模型:Stable Diffusion 1.5/2.1
- 结果:DiT在结构一致性上优于U-Net 41%(图9)
像素级对齐模块
- 消融影响:移除后细节对齐度下降29%
A.2 更多可视化结果
- 覆盖类别:家具(沙发)、机械(摩托车)、生物(恐龙)
- 细节展示:复杂拓扑结构(镂空装饰)、光滑曲面(车辆外壳)
该篇文章的笔记
- 该篇文章的研究目的
1.1 研究目的
该研究旨在解决从文本和图像生成高质量3D资产的挑战,特别是现有方法在处理复杂几何细节和大规模数据集时的局限性。文章提出了一种名为Direct3D的新型3D生成模型,能够直接从单视图图像生成高质量的3D形状,无需依赖多视图扩散模型或分数蒸馏采样(SDS)优化。该方法的目标是提高3D内容生成的质量和泛化能力,同时简化生成流程。 - 该篇文章的研究方法
2.1 研究方法
文章提出了Direct3D框架,包含两个主要组件:Direct 3D变分自编码器(D3D-VAE)和Direct 3D扩散变换器(D3D-DiT)。D3D-VAE通过将高分辨率3D形状编码到紧凑的三平面潜在空间中,并采用半连续表面采样策略直接监督解码几何形状,从而保留详细的3D信息。D3D-DiT则利用三平面潜在空间中的位置信息,结合像素级和语义级图像条件,生成与输入图像一致的高质量3D形状。 - 该篇文章的研究内容
3.1 研究内容
文章首先介绍了3D生成领域的背景和现有方法的局限性,特别是多视图扩散模型和SDS优化的间接生成方式导致的效率和细节损失问题。接着,文章详细描述了Direct3D框架的两个核心模块:D3D-VAE和D3D-DiT。D3D-VAE通过点云编码器、三平面解码器和几何映射网络实现高效的3D形状编码和解码,并采用半连续表面采样策略进行精确监督。D3D-DiT则通过融合像素级和语义级图像信息,实现高质量的3D形状生成。文章通过大量实验验证了Direct3D在图像到3D和文本到3D任务中的优越性能,展示了其在生成质量和泛化能力上的优势。 - 该篇文章的最大创新点
4.1 最大创新点
该文章的最大创新点在于提出了首个直接从单视图图像生成高质量3D形状的原生3D生成模型Direct3D。该模型通过以下创新实现高效和高质量的3D生成:
D3D-VAE:首次采用显式的三平面潜在表示,直接监督解码几何形状,避免了以往方法依赖渲染图像作为监督信号导致的细节丢失问题。
D3D-DiT:设计了一种新型的图像条件3D扩散变换器,能够将像素级和语义级图像信息融入每个扩散块中,从而生成与条件图像高度一致的3D形状。
半连续表面采样策略:通过结合连续和离散的监督方式,解决了在物体表面附近由于突然的梯度变化导致的优化困难问题,提高了3D形状的重建精度。 - 该篇文章给我们的启发
5.1 启发
3D生成模型的设计思路:文章展示了如何通过显式潜在表示和直接监督策略来提高3D生成的质量和效率,为未来3D生成模型的设计提供了新的思路。
多模态融合方法:通过在扩散模型中引入像素级和语义级图像信息,文章为多模态融合在3D生成中的应用提供了范例,启发我们在其他生成任务中探索类似的融合策略。
高效3D表示的应用:三平面表示在3D生成中的成功应用,展示了其在处理复杂几何结构方面的优势,为其他3D任务(如重建和编辑)提供了参考。
潜在空间的优化策略:半连续表面采样策略的提出,为处理3D生成中的优化难题提供了新的方法,尤其是在处理复杂几何结构时,这种策略可以有效提高模型的稳定性和精度。
数学公式
1. 半连续占用公式
文章中提出了一个半连续占用公式,用于在训练过程中平滑地处理靠近物体表面的点的占用值:
o
(
x
)
=
{
1
,
if sdf
(
x
)
<
−
s
0.5
−
0.5
⋅
sdf
(
x
)
s
,
if
−
s
≤
sdf
(
x
)
≤
s
0
,
if sdf
(
x
)
>
s
o(x)=\begin{cases}1,&\text{if }\text{sdf}(x)<-s\\0.5-0.5\cdot\frac{\text{sdf}(x)}{s},&\text{if }-s\leq\text{sdf}(x)\leq s\\0,&\text{if }\text{sdf}(x)>s\end{cases}
o(x)=⎩
⎨
⎧1,0.5−0.5⋅ssdf(x),0,if sdf(x)<−sif −s≤sdf(x)≤sif sdf(x)>s
其中,
sdf
(
x
)
\text{sdf}(x)
sdf(x) 表示点
x
x
x 的有符号距离函数值,
s
s
s 是一个阈值,用于控制连续和离散占用值之间的过渡范围。
2. D3D-VAE的优化目标
D3D-VAE的优化目标是通过最小化以下损失函数来实现的:
L
D3D-VAE
=
L
BCE
+
λ
KL
L
KL
L_{\text{D3D-VAE}}=L_{\text{BCE}}+\lambda_{\text{KL}}L_{\text{KL}}
LD3D-VAE=LBCE+λKLLKL
其中,
L
BCE
L_{\text{BCE}}
LBCE 是二元交叉熵损失,用于监督预测的半连续占用值;
L
KL
L_{\text{KL}}
LKL 是KL散度损失,用于防止潜在空间中的过度方差;
λ
KL
\lambda_{\text{KL}}
λKL 是KL损失的权重。
3. D3D-DiT的训练目标
D3D-DiT的训练目标是预测噪声
ϵ
\epsilon
ϵ,使得在时间步
t
t
t 的噪声潜在表示
z
t
z_t
zt 能够接近真实潜在表示:
z
t
=
1
−
β
t
z
t
−
1
+
β
t
ϵ
z_t=\sqrt{1-\beta_t}z_{t-1}+\sqrt{\beta_t}\epsilon
zt=1−βtzt−1+βtϵ
其中,
β
t
\beta_t
βt 是扩散过程中的噪声系数,
ϵ
\epsilon
ϵ 是标准正态分布的噪声。
4. AdaLN-Single参数预测
在D3D-DiT中,使用AdaLN-Single来预测全局的平移和缩放参数:
P
=
[
γ
1
,
β
1
,
α
1
,
γ
2
,
β
2
,
α
2
]
P=[\gamma_1,\beta_1,\alpha_1,\gamma_2,\beta_2,\alpha_2]
P=[γ1,β1,α1,γ2,β2,α2]
这些参数通过时间嵌入预测得到,并在每个扩散块中进行调整,以增强语义特征的表达能力。
5. 分类器自由引导
在训练过程中,为了提高条件生成的质量,使用了分类器自由引导(classifier-free guidance)。具体来说,以一定概率(如10%)随机将条件输入 c p c_p cp 和 c s c_s cs 置为零,从而在推理时能够利用分类器自由引导来提升生成质量。
以下是文章中所有图例和表例的中文翻译,按照文章中的顺序排列:
图1:Direct3D框架示意图
原文:Direct3D is a novel image-to-3D generation method that directly trains on larger-scale 3D datasets and performs state-of-the-art generation quality and generalizability. We achieve this by designing a novel 3D latent diffusion transformer model, which takes an image as the condition prompt and generates high-quality 3D shapes that highly consistent with the conditional images.
翻译:Direct3D是一种新颖的图像到3D生成方法,它直接在大规模3D数据集上进行训练,并实现了顶尖的生成质量和泛化能力。我们通过设计一种新颖的3D潜在扩散变换器模型来实现这一点,该模型以图像作为条件提示,并生成与条件图像高度一致的高质量3D形状。
图2:Direct3D框架
原文:The framework of our Direct3D. (a) We utilize transformer to encode point cloud sampled from 3D model, along with a set of learnable tokens, into an explicit triplane latent space. Subsequently, a CNN-based decoder is employed to upsample these latent representations into high-resolution triplane feature maps. The occupancy values of queried points can be decoded through a geometric mapping network. (b) Then we train the image conditioned latent diffusion transformer in the 3D latent space obtained by VAE. Pixel-level information and semantic-level information from images are extracted using DINO-v2 and CLIP, respectively, and then injected into each DiT block.
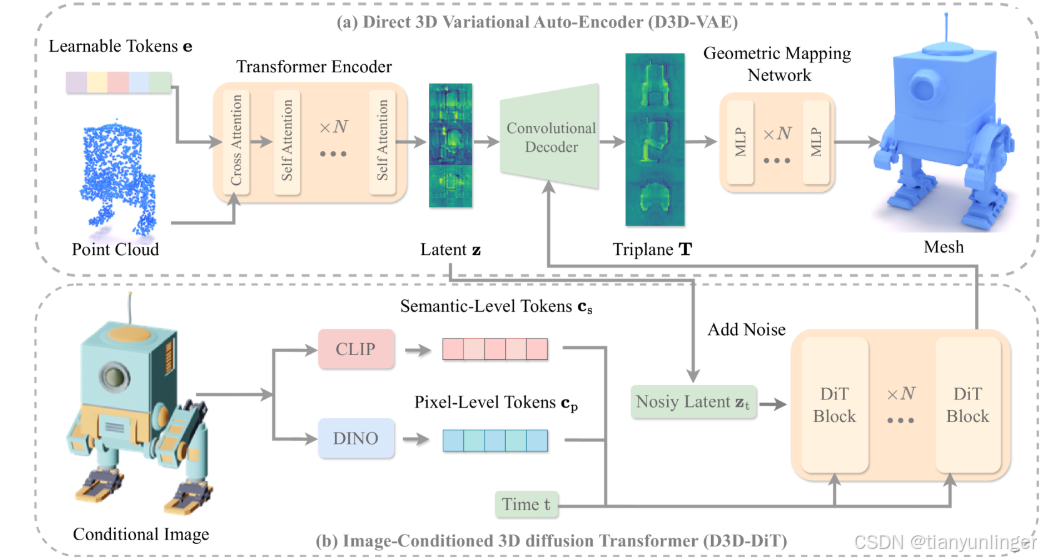
翻译:我们的Direct3D框架。(a) 我们利用变换器将从3D模型采样的点云以及一组可学习的标记编码到显式的三平面潜在空间中。随后,采用基于CNN的解码器将这些潜在表示上采样为高分辨率的三平面特征图。通过几何映射网络可以解码查询点的占用值。(b) 然后我们在通过VAE获得的3D潜在空间中训练图像条件的潜在扩散变换器。使用DINO-v2和CLIP分别提取图像的像素级信息和语义级信息,然后将它们注入到每个DiT块中。

图3:3D潜在扩散变换器架构
原文:The architecture of our 3D latent diffusion transformer. We employ the pre-trained DINO-v2 and CLIP vision model to extract tokens from conditional images respectively, then incorporate the pixel-level and semantic-level information into each DiT block.
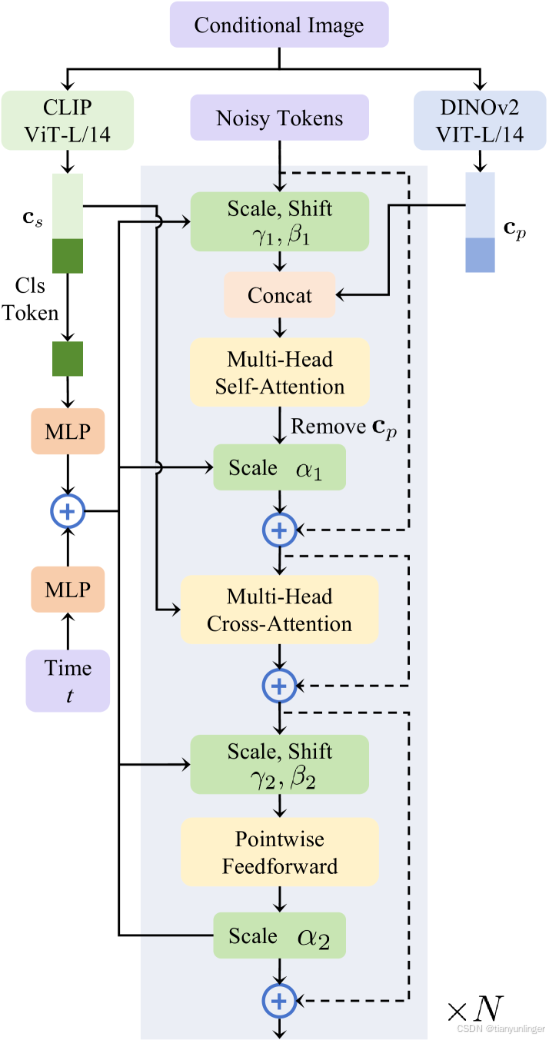
翻译:我们的3D潜在扩散变换器架构。我们使用预训练的DINO-v2和CLIP视觉模型分别从条件图像中提取标记,然后将像素级和语义级信息整合到每个DiT块中。
图4:与不同基线方法的定性比较
原文:Qualitative comparisons with different baseline methods on GSO dataset.
翻译:在GSO数据集上与不同基线方法的定性比较。
图5:从文本生成的网格的定性比较
原文:Qualitative comparisons of the meshes generated from text. We employ text-to-image diffusion model to produce highly detailed images as the inputs of each method.
翻译:从文本生成的网格的定性比较。我们使用文本到图像的扩散模型生成高度详细的图像作为每种方法的输入。
图6:纹理化网格的可视化
原文:Visualizations of the textured meshes. We employ SyncMVD to generate texture for the meshes produced by our Direct3D.
翻译:纹理化网格的可视化。我们使用SyncMVD为我们的Direct3D生成的网格生成纹理。
表1:用户研究结果
原文:User study on the quality of meshes. The higher the score, ranging from 1 to 5, the better.
翻译:关于网格质量的用户研究。分数越高(范围从1到5),表示质量越好。
图7:半连续表面采样策略的消融研究
原文:Ablation study for the semi-continuous surface sampling strategy.
翻译:半连续表面采样策略的消融研究。
图8:不同网络架构的扩散模型的定性比较
原文:Qualitative comparisons of diffusion models with different network architectures.
翻译:不同网络架构的扩散模型的定性比较。
图9:更多可视化结果
原文:More Visualizations.
翻译:更多可视化结果。
这些图例和表例的翻译涵盖了文章中所有重要的图表内容,帮助更好地理解文章的研究方法、实验结果和关键结论。
在文章中确实提到了实验环境和显卡需求的相关信息。以下是具体的内容:
实验环境和显卡需求
文章中提到的实验环境和显卡需求主要集中在两个部分:D3D-VAE 和 D3D-DiT 的训练和推理过程。
- D3D-VAE
训练环境:
使用 NVIDIA A100 (80G) 显卡进行训练。
训练步骤:100,000步(100K steps)。
优化器:AdamW,学习率设置为 1e-4。
损失函数:二元交叉熵损失(BCE)和KL散度损失,其中KL损失的权重为 1e-6。 - D3D-DiT
训练环境:
使用 NVIDIA A100 (80G) 显卡进行训练。
训练步骤:800,000步(800K steps)。
优化器:AdamW,学习率设置为 1e-4。
扩散模型配置:采用 DiT-XL/2 架构,包含28层DiT块,每层包含16个注意力头,每个头的维度为72。
推理过程:使用 DDIM 算法进行去噪,设置50步,指导尺度(guidance scale)为7.5。
总结
文章中明确指出,D3D-VAE和D3D-DiT的训练和推理过程都需要高性能的显卡支持,具体使用了 NVIDIA A100 (80G) 显卡。这种显卡具有较大的显存容量(80GB),能够支持大规模的3D数据处理和复杂的模型训练。此外,文章还提到了训练和推理过程中的一些关键参数设置,如优化器、学习率、训练步数等,这些信息对于复现和进一步研究具有重要参考价值。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









