









一,准备工作
//获取随机的数组
func GetArry(count int) []int {
arr := make([]int, count)
rand.Seed(time.Now().UnixNano())
for i := 0; i < count; i++ {
arr[i] = rand.Intn(100)
}
return arr
}
//打印数组
func Print(arr []int) {
fmt.Println("打印:")
for _, k := range arr {
fmt.Println(k)
}
}
//交换位置
func swap(s []int, i, j int) {
s[i], s[j] = s[j], s[i]
}
//获取最大的元素
func GetArryMax(arr []int) int {
biger := 0
for _, v := range arr {
if v > biger {
biger = v
}
}
return biger
}
//获取数字位的值
func digit(num int, loc int) int {
return num % int(math.Pow10(loc)) / int(math.Pow10(loc-1))
}
二,快速排序
时间复杂度:
- 平均:O(nlog2n)
- 最坏: O(n2)
- 最好:O(nlog2n)
//快速排序
func quickSort(arr []int, start, end int) {
if start < end {
i, j := start, end
key := arr[(start+end)/2]
for i <= j {
for arr[i] < key {
i++
}
for arr[j] > key {
j--
}
if i <= j {
arr[i], arr[j] = arr[j], arr[i]
i++
j--
}
}
if start < j {
quickSort(arr, start, j)
}
if end > i {
quickSort(arr, i, end)
}
}
}
//测试
func Test_FastSort(t *testing.T) {
arr := GetArry(10)
Print(arr)
quickSort(arr, 0, len(arr)-1)
Print(arr)
}
通过一次排序将要排序的数据分成两部分。一部分要比另外一部分小,两个部分进行分别排序。核心是分治法。
三,堆排序
时间复杂度:
- 平均:O(nlog2n)
- 最坏: O(n2)
- 最好:O(nlog2n)

//堆排序
func HeapSort(arr []int) {
n := len(arr) - 1
for k := n / 2; k >= 1; k-- {
sink(arr, k, n)
}
for n > 1 {
swap(arr, 1, n)
n--
sink(arr, 1, n)
}
}
func sink(s []int, k, n int) {
for {
i := 2 * k
if i > n {
break
}
if i < n && s[i+1] > s[i] {
i++
}
if s[k] >= s[i] {
break
}
swap(s, k, i)
k = i
}
}
利用堆这种特殊的数据结构,完全的二叉树进行排序。大顶堆,小顶堆。
四,计数排序
时间复杂度:
- 平均:O(n+k)
- 最坏: O(n+k)
- 最好:O(n+k)
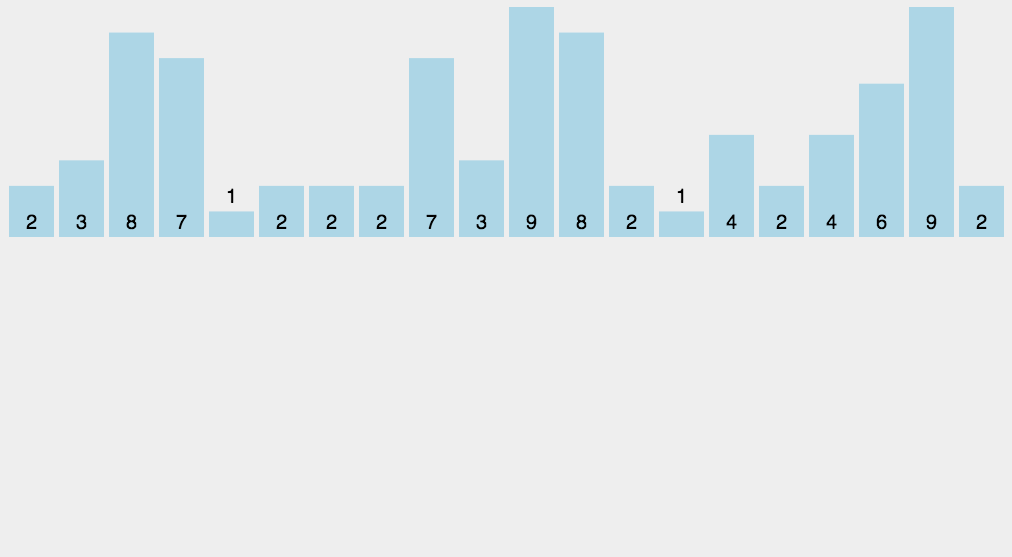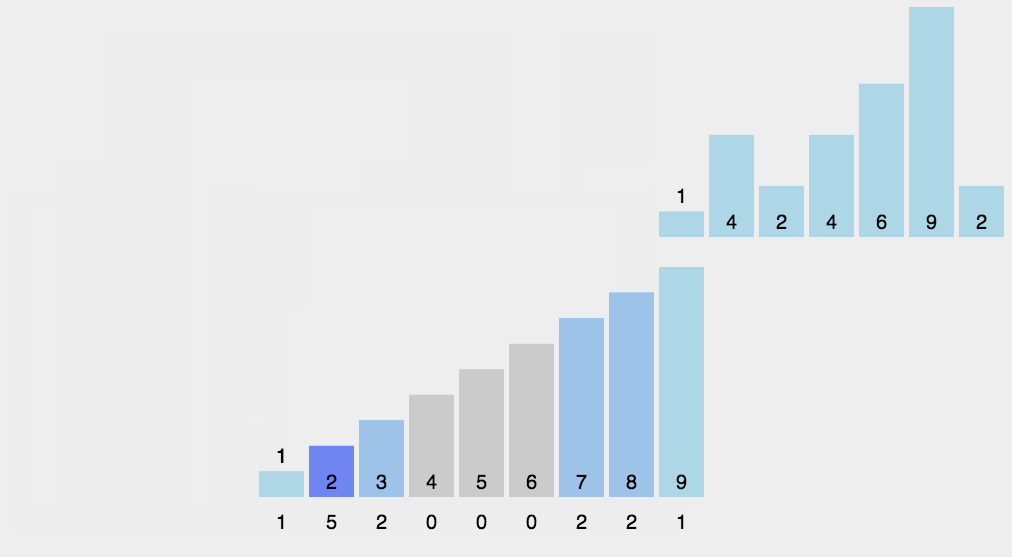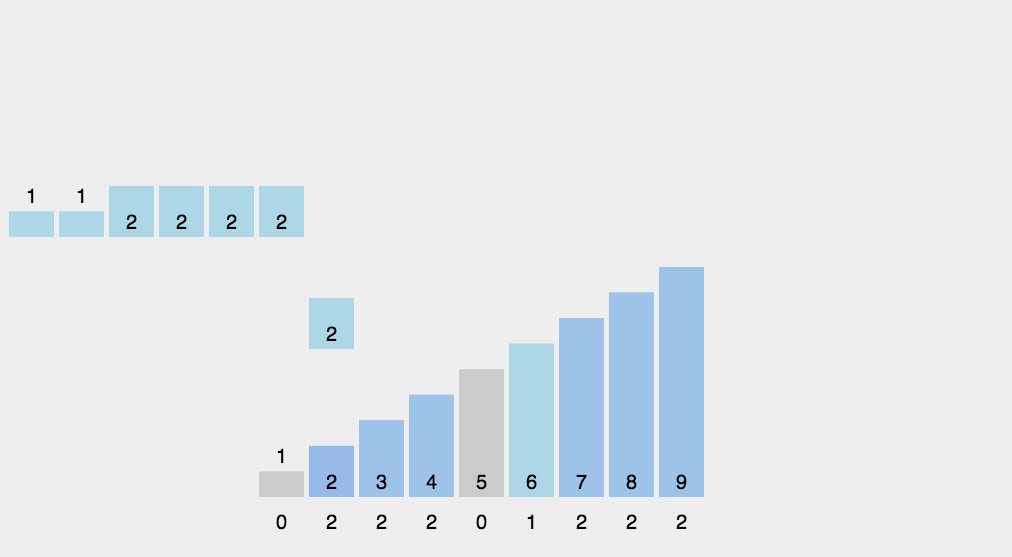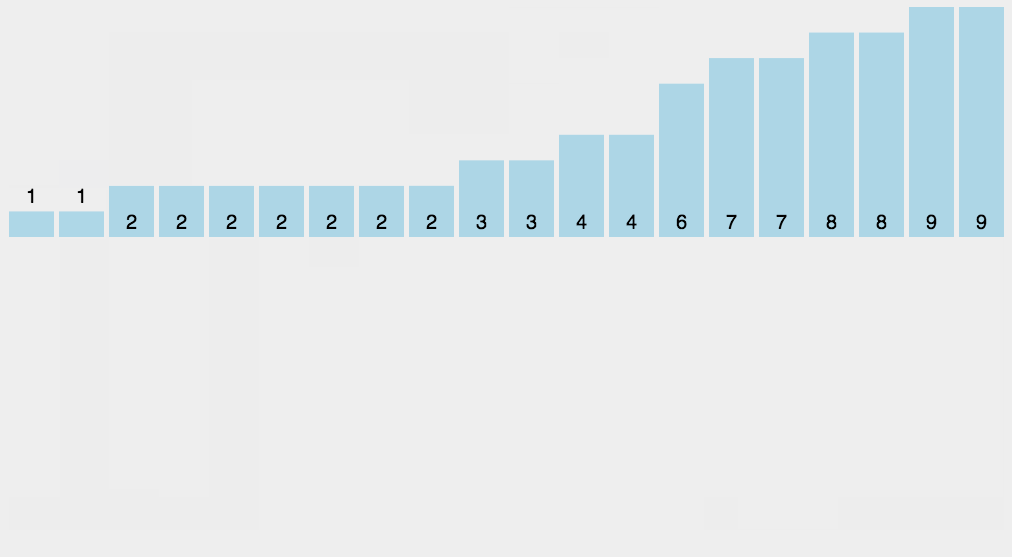
//计数排序
func CountingSort(arr []int) []int {
biger := GetArryMax(arr)
fmt.Println("zuida:", biger)
orderarr := make([]int, biger+1)
for _, v := range arr {
orderarr[v]++
}
var resarr []int
for i, v := range orderarr {
if v > 0 {
for j := 1; j <= v; j++ {
resarr = append(resarr, i)
}
}
}
return resarr
}
计数排序是一个稳定的排序算法。当输入的元素是 n 个 0到 k 之间的整数时,时间复杂度是O(n+k),空间复杂度也是O(n+k),其排序速度快于任何比较排序算法。当k不是很大并且序列比较集中时,计数排序是一个很有效的排序算法。
五,桶排序
时间复杂度:
- 平均:O(n+k)
- 最坏: O(n2)
- 最好:O(n)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WkesE7gq-1625304794524)(https://gimg2.baidu.com/image_search/src=http%3A%2F%2Fimg.kanzhun.com%2Fimages%2Fseo%2Fmianshiti%2F20191125%2F8c57857f177717f04d1255c32dbbec4e.gif&refer=http%3A%2F%2Fimg.kanzhun.com&app=2002&size=f9999,10000&q=a80&n=0&g=0n&fmt=jpeg?sec=1627895630&t=9153e406f528898ed2cc32a5b13b204e)]
//桶排序
func BucketSort(arr []int) []int {
num := len(arr)
max := GetArryMax(arr)
buckets := make([][]int, num)
index := 0
for i := 0; i < num; i++ {
index = arr[i] * (num - 1) / max
buckets[index] = append(buckets[index], arr[i])
}
tmpPos := 0
for i := 0; i < num; i++ {
bucketLen := len(buckets[i])
if bucketLen > 0 {
SortInBucket(buckets[i])
copy(arr[tmpPos:], buckets[i])
tmpPos += bucketLen
}
}
return arr
}
func SortInBucket(arr []int) {
length := len(arr)
if length <= 1 {
return
}
for i := 1; i < length; i++ {
backup := arr[i]
j := i - 1
for j >= 0 && backup < arr[j] {
arr[j+1] = arr[j]
j--
}
arr[j+1] = backup
}
}
桶排序是计数排序的升级版。解决了如果数据值范围过大造成的桶数量多的问题,进行函数映射处理缩小桶数量。但也增加了桶内排序的过程。
六,基数排序
时间复杂度:
- 平均:O(n*k)
- 最坏: O(n*k)
- 最好:O(n*k)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-i3kmFFWW-1625304794525)(https://gimg2.baidu.com/image_search/src=http%3A%2F%2Fupload-images.jianshu.io%2Fupload_images%2F7492974-c980be774a0cc76d.gif&refer=http%3A%2F%2Fupload-images.jianshu.io&app=2002&size=f9999,10000&q=a80&n=0&g=0n&fmt=jpeg?sec=1627895837&t=0c184d3053683c556a256d8824edacd7)]
//基数排序
func RadixSort(arr []int) {
maxValLen := 0
for i := 0; i < len(arr); i++ {
n := len(strconv.Itoa(arr[i]))
if n > maxValLen {
maxValLen = n
}
}
for loc := 1; loc <= maxValLen; loc++ {
Sort(arr, loc)
}
}
func Sort(arr []int, loc int) {
bucket := make([][]int, 10)
for i := 0; i < len(arr); i++ {
ji := digit(arr[i], loc)
if bucket[ji] == nil {
bucket[ji] = make([]int, 0)
}
bucket[ji] = append(bucket[ji], arr[i])
}
idx := 0
for i := 0; i <= 9; i++ {
for j := 0; j < len(bucket[i]); j++ {
arr[idx] = bucket[i][j]
idx++
}
}
}
基数排序的性能要比桶排序略微差一点。基于分别排序,分别收集,是稳定的。
七,总结
重新梳理排序算法的目的,就是加深印象。用golang进行实现也锻炼了逻辑思维能力。拓宽了视野,遇到排序问题不在只会一个冒泡,快排也可以考虑一下的哈。根据不同排序算法的不同特点可以在不同的场景使用,如果数据值范围不大,可以用计数排序,如果数据范围大,可以使用桶排序。















 278
278











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









