







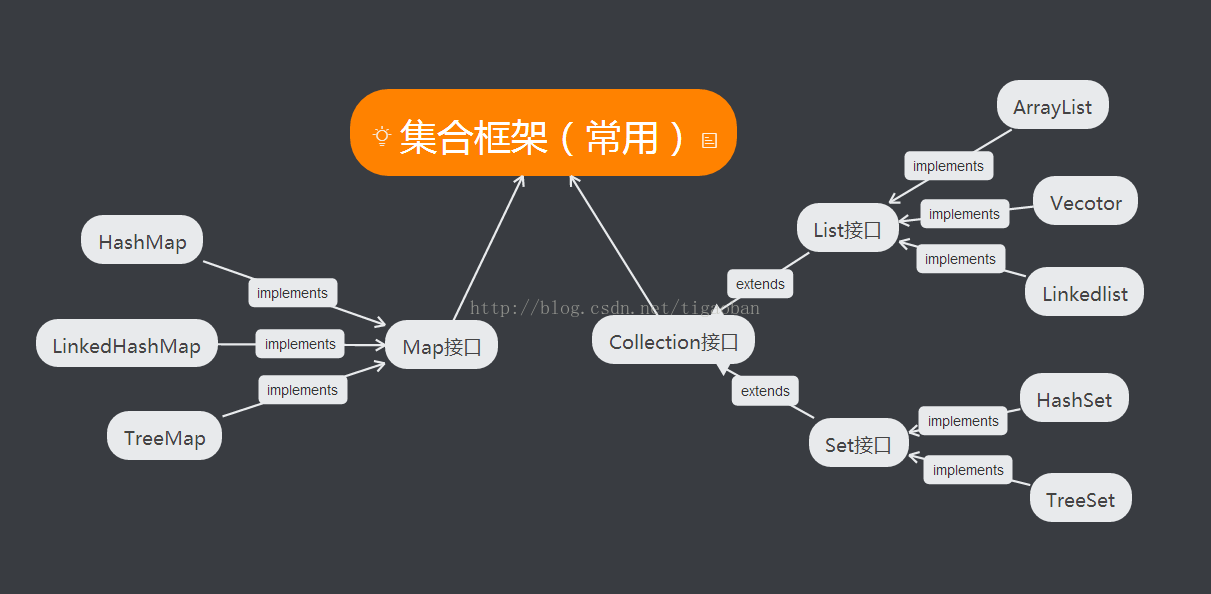
Collection接口
(1)定义:
Collection是层次结构中的根接口,在实际编程中用List和Set作为Collection的子类接口,通过他们的具体实现类来使用集合。但Collection的方法对其子接口和实现类都适用。
(2)方法:
A:添加功能
boolean add();添加一个元素
boolean addAll();添加多个元素
B:删除功能
void clear();移除所有元素
boolean remove();移除一个元素
boolean removeAll();移除一个集合的元素
C:判断功能
boolean contains();判断集合中是否包含指定元素
Boolean containsAll();判断集合中是否包含指定集合元素
Boolean isEmpty();判断集合是否为空
D:获取功能
Iterator<E>iterator();迭代器模式
E:长度功能
int size();元素的个数
数组中没有length()方法,字符串有length()方法,集合没有length()方法
F:交集
Boolean retainAll();如果有交集返回true否则false
G:把集合转数组(了解)
Object[]toArray();
(3)Collection集合的通用遍历方法:
把集合转成数组遍历,for循环
public class CollectionDemo {
public static void main(String[] args) {
Collection<String> c=new ArrayList<String>();
c.add("zhang");
c.add("jian");
c.add("hui");
//把集合转换成数组
Object[] objs= c.toArray();
//for循环遍历
for(int x=0;x<objs.length;x++){
System.out.println(objs[x]);
}
}
}
迭代器遍历
public class IteratorDemo {
public static void main(String[] args) {
//创建集合对象,泛型限制类型
Collection<String> c=new ArrayList<String>();
c.add("zhang");
c.add("jian");
c.add("hui");
//创建迭代器对象
Iterator<String> it=c.iterator();
//如果有元素可以迭代,则返回true
while(it.hasNext()) {
System.out.println(it.next());
}
//使用for循环改进,迭代器作为for循环的判断条件,提高效率
for(Iterator<String> it1=c.iterator();it1.hasNext();){
System.out.println(it1.next());
}
}
}增强for循环(适用于集合和数组的一种简便for循环)
格式:
for(元素的数据类型 变量名 : 数组或者Collection集合的对象) {
使用该变量即可,该变量其实就是数组或者集合中的元素。
}
上面的使用增强for改进:
for(String s:c){
System.out.println(s);
}总结:其实不管是while还是for其底层源码都是迭代器遍历的,但是在编码中经常会适用增强for循环。
(一)LIst接口
(1)特点:
- 有序的集合,指存储和取出是有序的而不是排序
- 元素可重复。
(2)特有功能:
A:添加
voidadd(int index, E element) 在列表的指定位置插入指定元素(可选操作)
B:删除
Object remove(int index) 移除列表中指定位置的元素(可选操作),将所有的后续元素向左移动(将其索引减1)。返回从列表中移除的元素。
C:获取
Object get(int index) 返回列表中指定位置的元素。
D:迭代器
ListIterator<E>listIterator() 返回列表中元素的列表迭代器(按适当顺序),是Iterator的子接口。
Listiterator特有方法:hasPrevious()和previous()实现逆向遍历列表
E:修改
Object set(int index, E element) 用指定元素替换列表中指定位置的元素(可选操作)。
(3)List特有遍历:
注意:在遍历的时候,使用什么方式遍历,就用什么添加元素,否则出现并发修改异常,因为迭代器是依赖集合而存在的,当遍历过程中添加元素后集合就改变了,而迭代器不知道,就会报错。
1. 迭代器遍历迭代器添加元素,元素添加到equals比较的元素后面。
2. 集合遍历集合添加元素(本例),元素添加到末尾。
public class ListIteratorDemo {
public static void main(String[] args) {
List<String> list=new ArrayList<String>();
list.add("hello");
list.add("world");
list.add("java");
//注意:容易出现并发修改异常的情况
for(int x=0;x<list.size();x++){
String s=list.get(x);
if("world".equals(s)){
list.add("javaee");
}
System.out.println(s);
}
}
}List三个实现类的特点:
ArrayList(常用)
底层数据结构是数组,查询快,增删慢。
线程不安全,效率高。
Vector(使用少)
底层数据结构是数组,查询快,增删慢。
线程安全,效率低。
LinkedList
底层数据结构是链表,查询慢,增删快。
线程不安全,效率高。
(二)Set接口
(1)特点:无序集合(指顺序而非排序),不包含重复元素(唯一)。无自己的特殊方法,同父类。
(2)HashSet类
底层数据结构是哈希表(是一个元素为链表的数组),哈希表底层依赖两个方法:hashCode()和equals()保证元素的唯一性。
学生类
public class Student {
private String name;
private int age;
无参构造
带参构造
get&set方法
@Override
/*快捷键生成hashCode和equals方法:Alt+Shift+s+h
判断过程:
1、先比较哈希值是否相同,在下面加入一个常量值,目的是防止不同的哈希值相加的结果相同但实际的值是不同的,比如:2+3=1+4,但2*2+3!=1*2+4,所以就是为了避免出现特殊情况。
2、如果哈希值不同,执行equals方法,true元素重复,false添加元素
*/
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Student other = (Student) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
}
测试类
import java.util.HashSet;
public class HashSetDemo {
public static void main(String[] args) {
HashSet<Student> hs=new HashSet<Student>();
Student s1=new Student("张建辉1",21);
Student s3=new Student("张建辉3",23);
Student s4=new Student("张建辉3",23);
Student s5=new Student("惠小妹",25);
Student s6=new Student("惠小妹",26);
hs.add(s1);
hs.add(s3);
hs.add(s4);
hs.add(s5);
hs.add(s6);
for(Student s:hs){
System.out.println(s.getName()+"------------"+s.getAge());
}
}
}
/*输出结果:
惠小妹------------25
张建辉3------------23
惠小妹------------26
张建辉1------------21
证明Set存储和输出的顺序是不一样的,相同的元素不能重复添加,不重写hashCode和equals方法会报错。*/(3)TreeSet类
底层数据结构是红黑树(是一个自平衡的二叉树)
a:自然排序(让元素所属的类实现Comparable接口)
学生类
public class Student implements Comparable<Student>{
private String name;
private int age;
无参构造
带参构造
get&set方法
@Override
public int compareTo(Student s) {
//首要条件,年龄从小到大
int num=this.age-s.age;
//次要条件姓名的长度
int num2=num==0?this.name.length()-s.name.length():num;
int num3=num== 0?this.name.compareTo(s.name):num2;//判断是否重复元素
return num3;
}
}
测试类
import java.util.TreeSet;
public class TreeSetDemo {
public static void main(String[] args) {
TreeSet<Student> ts=new TreeSet<Student>();
Student s1=new Student("张建",1);
Student s2=new Student("张",4);
Student s3=new Student("张建辉",2);
Student s4=new Student("张建辉1",2);
Student s5=new Student("张建辉22",2);
ts.add(s2);
ts.add(s1);
ts.add(s3);
ts.add(s4);
ts.add(s5);
for(Student s:ts){
System.out.println(s.getName()+"---"+s.getAge());
}
}
}
/*输出结果:
张建---1
张建辉---2
张建辉1---2
张建辉22---2
张---4
证明需要在Student类中给出排序的条件,没有则报错。自然排序如果集合中添加得是相同类型元素,如数字、字母可以不用给出排序条件,自动按顺序排,
但是自定义对象必须给出如何排序的条件 */b:比较器排序(让集合构造方法接收Comparator的实现类对象)
/*
省略学生类,学生类中包括get set方法
*/
import java.util.TreeSet;
public class TreeSetDemo2 {
public static void main(String[] args) {
//Comparator是一个接口,需要的是一个接口的实现类的对象,采用匿名内部类。
TreeSet<Student> ts=new TreeSet<Student>(new Comparator<Student>(){
@Override
public int compare(Student s1, Student s2) {
//主要条件根据名字长度
int num=s1.getName().length()-s.getName().length();
//比较元素是否相同
int num2=num==0?s1.getName().compareTo(s2.getName()):num;
//次要条件年龄排序
int num3=num2==0?s1.getAge()-s2.getAge():num2;
return num3;
}
});
Student s1=new Student2("z",1);
Student s2=new Student2("zh",2);
Student s3=new Student2("zha",3);
Student s4=new Student2("zha",4);
Student s5=new Student2("zha",4);
ts.add(s1);
ts.add(s2);
ts.add(s4);
ts.add(s3);
ts.add(s5);
for(Student s:ts){
System.out.println(s.getName()+"---"+s.getAge());
}
}
}
/*输出结果:
z---1
zh---2
zha---3
zha---4
证明TreeSet集合内部元素的唯一性,以及排序方式。*/Map接口
(1)理解:
将键映射到值的对象。一个映射不能包含重复的键;每个键最多只能映射到一个值。键相当于Set集合,值相当于list集合,数组中有二维数组,集合中没有二维集合,但是Map集合却有点二维的感觉。
(2)Map和Collection的区别?
A:Map 存储的是键值对形式的元素,键唯一,值可以重复。(学号和姓名的关系)
B:Collection 存储的是单独出现的元素,子接口Set元素唯一,子接口List元素可重复。
C:Map是双列的,Collocation是单列的,
(3)Map接口的方法
A:添加功能
V put(k key,v value);添加元素
如果键是第一次存储,就直接存储键值对,返回null
如果键不是第一次存储,就用值把以前的值替换掉,返回以前的值。
B:删除功能
void clear();移除所有键值对
V remove(Object key);根据键删除键值对元素,并把值返回
C:判断功能
boolean containsKey(Object key); 判断集合是否包含指定键
boolean containsValue(Object value);判断集合是否包含指定值
D:获取功能
set<Map.Entry<K,V>>entrySet();返回此映射中包含的映射关系的Set视图。
Set<K> keySet();获取集合中所有键的集合
V get(Object key);根据键获取值
Collocation<V>value();获取集合中所有值的集合
E:长度功能
int size();返回集合中键值对的对数
(4)Map集合的遍历
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class MapDemo2 {
public static void main(String[] args) {
//定义map集合
Map<String,String> map=new HashMap<String,String>();
map.put("小明", "小玲 ");
map.put("小明", "小玲");
//方法1:
//获取所有的键的集合
Set<String> set=map.keySet();
for(String key:set){
String value=map.get(key);
System.out.println(key+"\t"+value);
}
//方法2:
//个人理解:将键值对包装为一个对象给出索引值,Set是一个索引值的集合
Set<Map.Entry<String,String>>set=map.entrySet();
//个人理解:遍历每一个索引,得到对象,对象调用getkey()和getvalue方法得到每一个键和值
for(Map.Entry<String,String> me:set){
System.out.println(me.getKey()+"\t"+me.getValue());
}
}
}(一)HashMap类
特点同HashSet
(二)LinkedHashMap类
特点同LinkedSet
(三)TreeMap类
特点同TreeSet















 365
365

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









