






对于注意力机制,是近期大火的Transformer的关键,Transformer是GPT的最核心的架构。
很多人说:Transformer 架构极其简单,十分钟看完。确实,3 分钟就看完了,但是如果不能理解注意力机制,那一定会是一头雾水。
我一直也似懂非懂,最近看了一些资料,尝试再理解一下。
什么是注意力机制:(What)
人在阅读图书时,一般会有侧重点,原因是,我们基本上都有带着问题和喜好在读书。所以,并不会对所有文字都投入一样的关注度。可以说,人是天生知道如何关注重点的,很强!
举个例子,在下面一段文字和问题,如何根据问题,重点阅读,得到答案?
昨天,我在繁忙的一天结束后,决定去我最喜欢的咖啡店放松一下,我走进咖啡店,点了一杯拿铁,然后找了靠窗的一个位置坐下。我喝着咖啡,看到窗外的人们匆匆忙忙,感到非常惬意。然后,我从咖啡店出来,回到了家中。
问题:昨天我去了几次咖啡店?
首先:一定会找 "咖啡店”,于是,我们找到了,有3个提到咖啡店的地方。那答案是3吗,显然不是。
然后:我们进一步要理解与 和 去咖啡店相关的词语(动作),哪些能代表去了咖啡店,显然,“决定去” 并不是真的去,可以去掉一次。那答案是 2 次?好像也不对。
再进一步:走进和出来咖啡店 这2个信息有冗余,我们需要去掉一次,最终的答案是1。
这个在人看来,是非常显而易见的问题,对于计算机,其实是一个非常非常困难的问题。
我们来看看,对于计算机理解,难点在哪里?
首先:找出关键词还是比较容易的(当然,这里可能还会用到咖啡店的类似写法),难度在于理解语义(理解什么是去了咖啡店?),你可以假定我们有预训练,完成了相关的关联性的学习。比如:在咖啡店里 和 走进,出来,决定去 的一些关系。由于我们知道与去过咖啡店最关联的词是什么,所以,我们知道应该如何抓住重点(注意力)。那些中间的描述,我们可以不怎么关注。
所以,对于注意力机制,我们可以这样理解:
注意力机制就是帮助计算机模型在阅读文本时,能够很好地关注到关键的信息,忽略冗余的信息。那具体如何做到的呢?(后面再说)
再啰嗦一下,就是要完成两点:
1:找到问题的关键词。通过词语之间的关联概率。
2:理解语义,知道 去过咖啡店 和 想去,走出,离开的关系。
为什么需要注意力机制:(Why)
除了上面讲的引出注意力机制的原因,但实际优点并不明确,我们通过结果看原因,先看看还有什么问题通过注意力机制来得到了解决。
在传统的机器学习/深度学习中,有几个问题:
1:之前我们会使用循环神经网络 RNNs来完成自然语言理解,但它的问题是,输入序列太长时性能会下降,并且因为是顺序处理,会导致无法处理大规模的数据。(无法通过堆叠算力来达成大规模的训练)
2:为了能处理长文本,我们可能会使用更深的网络,但网络过深,会有梯度消失和爆炸的问题(你可以简单理解为乘法做多了,要不太驱近于0,要不趋近于1,如果值太相似,计算出的概率就没意义了)。如果使用LSTM(处理跨层连接),一样也有容量的限制。
3:据说在计算机视觉,跨模态任务,推荐系统领域也可以使用注意力机制(这个没做研究,不清楚原理)(你可以理解注意力机制本身是个套路,如果相关场景有这个需求,可能就能利用上)
还是可以举例:通过注意力机制,在图像处理时,可以将不重要信息去掉(只突出重要的内容)
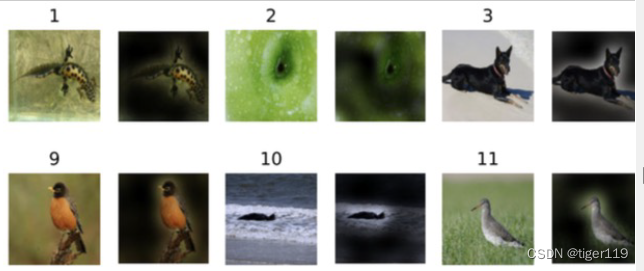
4:传统的神经网络实际上是黑盒模式(无法通过模型查看学习的结果),可视性不强,做出来不拿验证数据试,也不知道好坏。但注意力机制,因为会计算数据之间的关联概率,实际上通过关联性,可以观察到训练结果的好坏。比如:下图中机器翻译的关联结果(可视化的效果)(越亮表达相关性越高,可以通过实际的对应看到不同语种的交叉亮点,确定相应的效果咋样)

5:注意力机制的传统架构包含编码,解码。可以理解为训练时和推理时,我们可以在解码时使用编码时的序列和通过问题的上下文调整注意权重来有选择的完成解码(这个有点不好理解,往后面看吧)
引入注意力机制之后,GPT3.5/4.0都有大量的基准测试结果,确实获得了更好的效果(主要是在NLP领域)。
如何实现注意力机制:(How)
好,说了半天,那注意力机制如何实现。
说实话,我这么简单描述,肯定也不一定能说清楚,我只能尽量了。
我们先用注意力机制最早的应用场景:机器翻译来说明一下。
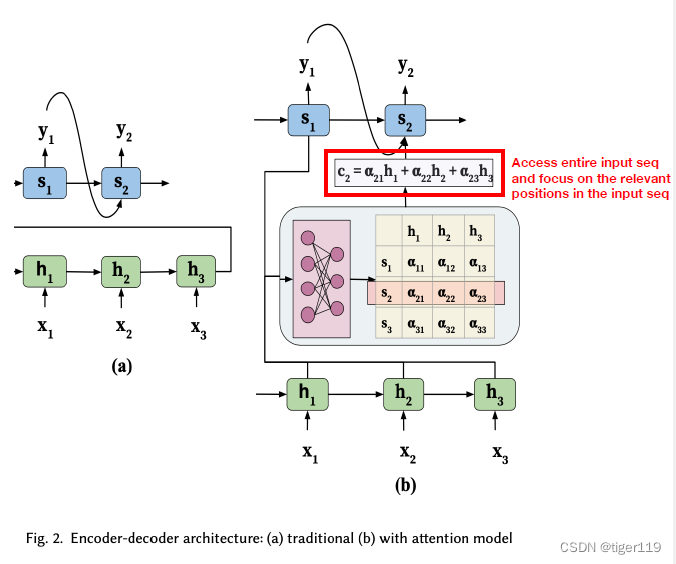
我们先看一下机器翻译使用的 Encoder-Decoder架构。

从上图可以看到,加入注意力机制后,提供了注意力网络,
如何理解这个注意力网络?实际上可以简单认为,注意力网络可以保证在编码器得到的单词的关联关系会全部传递给解码器。任意向量之间的关联关系都会被学习和记录。这样,保证不会丢失编码器得到的向晨间的关系。传统的方式,是将训练期的内容串在一起往后传,这是不智谱的,如果量大,一定会丢失。就是我们上面提到的传统RNNs的缺点。
那它为什么能保证通过注意力网络来传递呢?因为注意力网络的生成都是并行运算的(矩阵的),如果你的训练期的向量集很大,那你只要保证有足够的算力和存储,一定能将信息后传。先这么简单的理解了。
注意力综述:(这是非常重要的论文,看 attention is all you need 之前,可以先看这个)
重点论文:注意力综述
重要概念:上下文变量C:
见下图,对于推理期的 S1,S2 会根据 训练期获得的 h1,h2,h3 设定不同的注意力权重。这样,可以保证S1 或者 S2 可以使用自已的关注的重点。这句话其实很扯,实际上我们一定要能理解,训练的过程实际上就是一个不断迭代的过程,我们可以理解是在不断调整概率的过程。我们假定知道了答案,然后反向在调整权重。这样就好理解了,并不是指真正的推理期,所以,在GPT训练时,实际上并不同时使用Endoding和Decoding。
解码器/推理期 可以完整获取编码时的信息,而且自行决定关注的权重,来得到自已关注的重点内容。
A 对齐函数:把输入,输出,位置对齐的函数。函数有很多种,实际上我们只选用了一种。见后。

Softmax:进行归一化,做过AI的肯定理解这个了。归一化,获得合理的概率值,方便作为上下文的变量。
h:编码侧的关联信息。就是多头中的某一头的学习情况。
s:解码侧的输入。
A:要关注的重点,解码侧针对编码信息的关注度(权重)。
Vi:提供多种的学习结果(多头),例如:可能有文字的,录音的,视频的,多角度信息。
对于对齐函数,会有多种方案:

对于对齐函数,有相应的论文(很早期的一篇论文)
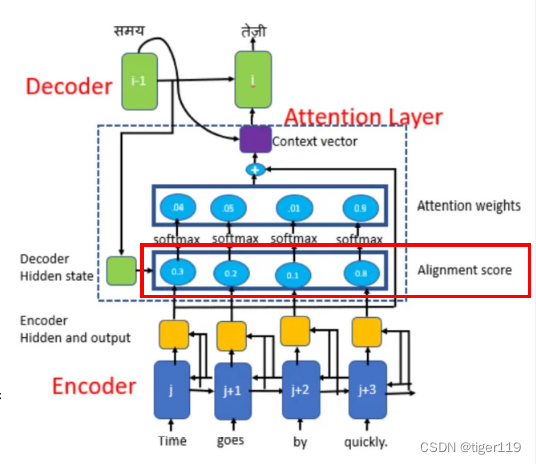
对齐函数,上图中我们可以理解为对齐分数,经过softMax变成注意力权重。
Transformer 使用注意力机制:
关键论文:Attension is all you need
关键技术点:
【神经网络架构】 : 非 编 / 解码结构,而是创造了 Transformer架构,但与之类似。
【注意力机制类型】:自注意力机制——Self-attension (不同的对齐函数)
【注意力模型技术】:具体的应用场景较多,比较熟知的是,机器翻译,知识问答,图像处理……
优势:
更好的效果(多头注意机制)
支持并行计算:可以并行运算,无依赖,训练效率更高,支持更大的模型。
看一下具体的变化:如下图
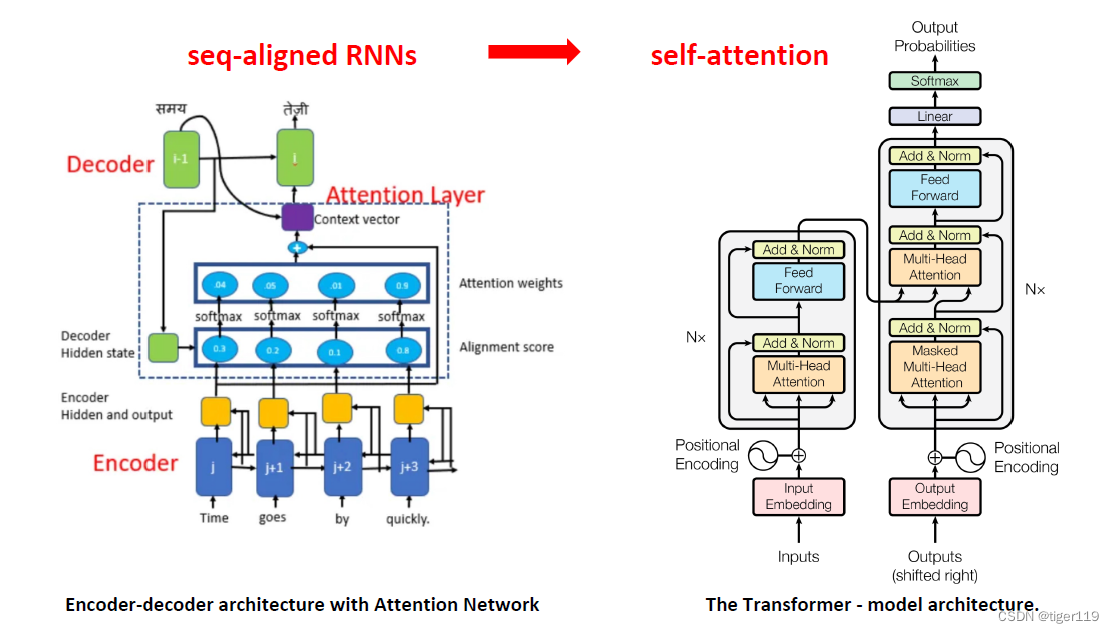
什么叫self-attension?
1:提升输入的语句内部的语义关系,提升对语义的理解能力。
2:这样,可以通过填空(抽空)的方式来完成自训练(无需标注)。这个非常重要。解决了训练的问题。
3:理解语言,理解语义。这是获得基础LLM。很多工作就可以基于这个开展。

看看最核心的对齐函数:(使用了 Scaled Dot-Product Attention)
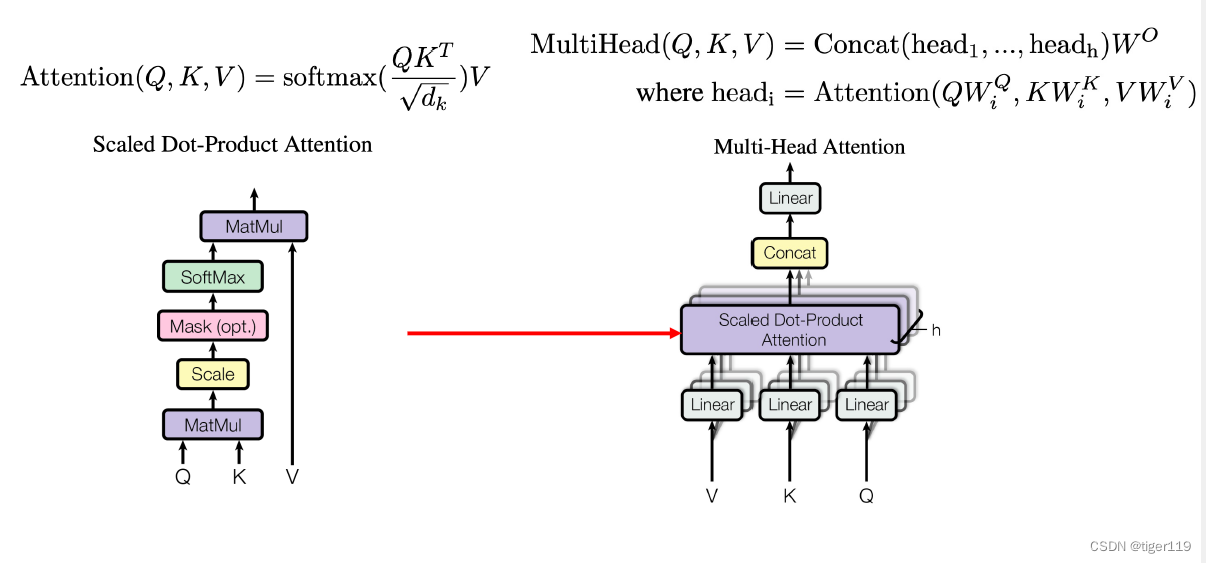
Q:查询信息,提问,输入
K:针对查询信息的其它信息的关键度
V:整个内容信息
Multi-Head:实际上就是多头注意力(类似,通过文字,语音,视频多角度的学习结果)
对于KQV的计算,实际可以去看它的矩阵运算过程,Q*K实际上是在计算训练文字内部的语义关系,是一个倒置的矩阵相乘。再和V进行运算,
下面是完整的架构图:
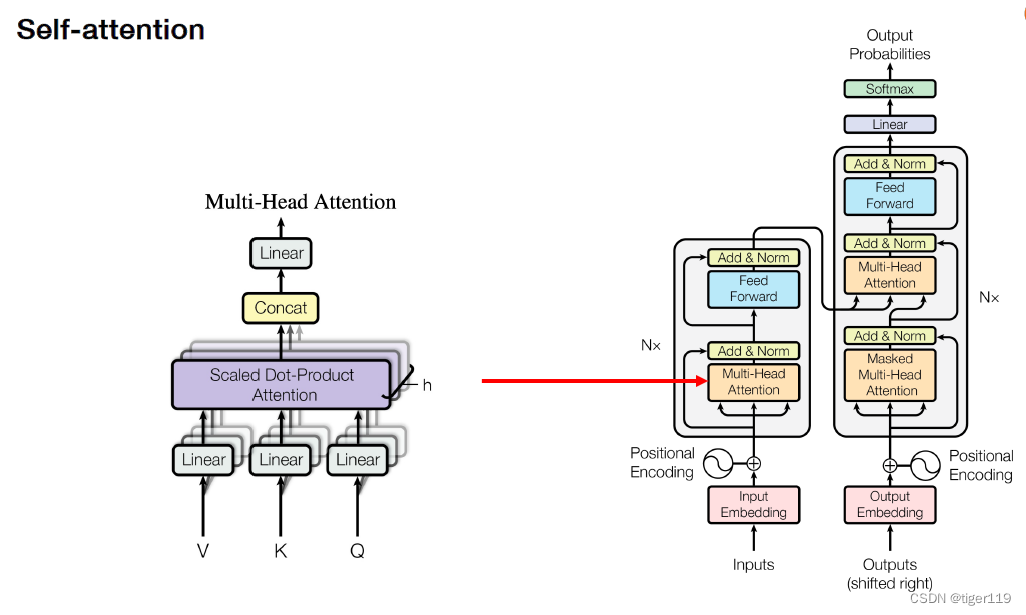
注意其中的几点:
* Positional 对位置进行编码,要区分每个单词(token)的位置,这是必须的,而且编码方式有些小的技巧,这里不详细解释了。
* Embedding的原理,就不详细讲了,非常重要,是一个关键技术。
* Masked 就是遮住后面的词来进行训练(QKV只到当前位置,之后的不给看),这是GPT和BERT可以做到无标注训练的原因。因为这样就可以学习到语义了,只需要大量输入网络上的文字就可以学习了。
* FFN 前馈网络,标准的神经网络。max(0,xW1 + b1)W2 + b2这应该是一个经验的神经网络(原理不清楚了),这个还是必须的,但不明白为什么是这个公式。
如果要和Encode/Decode对比,大概是相同的。其实也是类似的架构,重要区别是没有使用RNN。(这很重要,没有顺序化执行了)
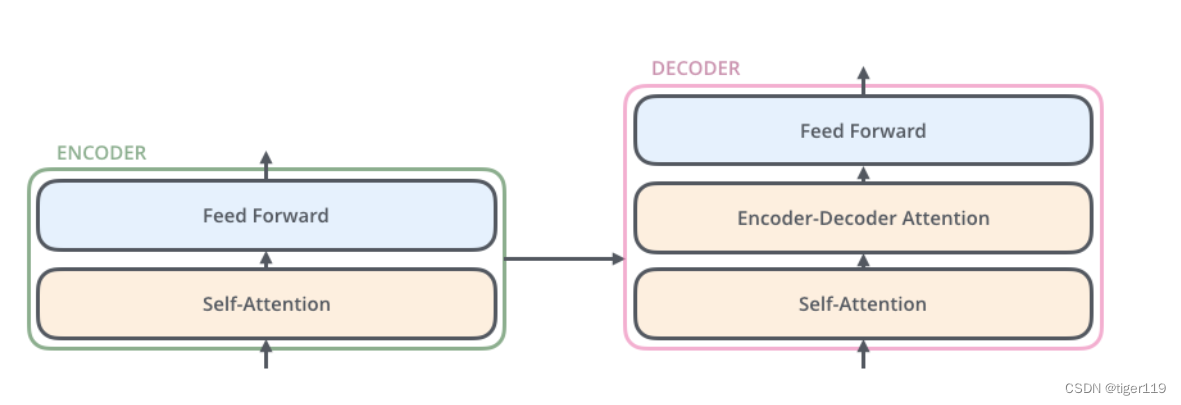
Transformer的重大变革:
Transformer在进行词语相似度比较时,使用了余弦相似度,而相似度的比较变成了矩阵相乘的运算(这个可以做数学推导)。而矩阵相乘是可以并行完成的,因此,没有了RNN的Transformer可以通过大规模的并行算力,来训练超大规模的模型。对于自然语言,OpenAI采用的是10万个token编码,要计算它们之间的关系,这是一个恐怖的量级,但因为将运算变成并行,成为可扩展的算法,就有了所谓的暴力出奇迹的可能。
训练生成基础模型,然后通过Fine-tune(Adaptiive)轻量适配可以解决行业问题。这其实是通用模型产生的基础。就象人一样,在大学毕业前,学习的都是通用的基本技能。进入社会,再进行微调,掌握行业能力。这种学习曲线和人是一样一样的了。
现在的学习,是在学习语言而不是一个具体的任务。可以生成LLM!
GPT 和 BIRT
使用Transformer的除了GPT,其实还有BIRT。这里也提一下。

通过BIRT,实际上可以看到类似GPT的突破:
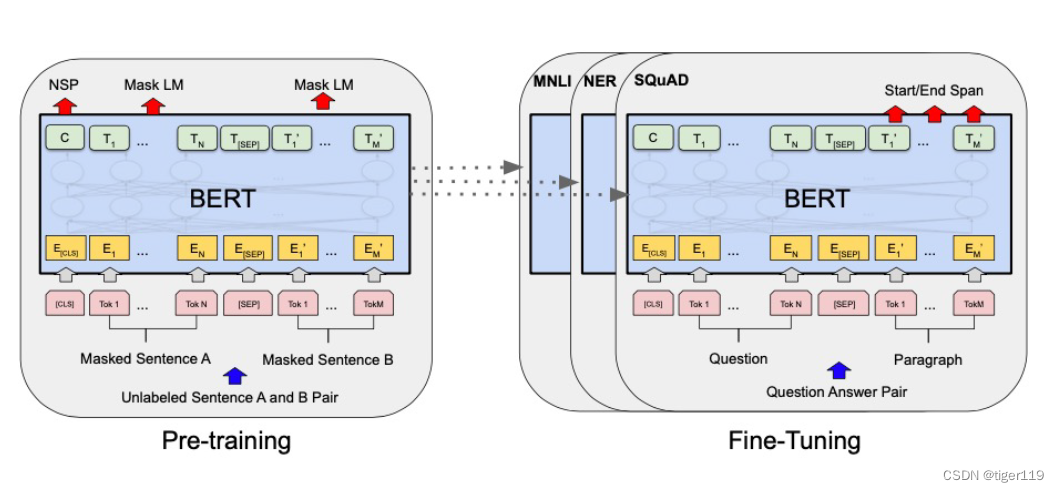
BIRT最大的特点:双向理解,但它还用了RNNs,LSTM,所以,它做不到大规模。
但可以重点关注它的几个点:
Mask方式形成训练的过程。15%的词进行mask。Mask LM。这个GPT是类似的处理。
句子之间的关系,可以加一些小的标签:如:: 是否下一句话? 是否同意是下一句话?
今天就写这么多了。
大概想表达的就是注意力机制解决了2大问题:
1:可以通过无标注的数据,训练得到理解语义的LLM。这非常强,这就可以解决人类的最强的自然语言的理解能力。不管你做什么工作,一定要先要能听懂人话。
2:运算机理变成可并行运算,这样,可以通过提升算力来得到大规模的基础模型。然后再通过行业的标注数据fine-tune形成行业模型。这是合理的路径。















 1709
1709

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









