






可能很多人并没有关注Embedding技术,但实际上它是GPT非常重要的基础,准备的说,它是GPT模型中理解语言/语义的基础。
【解释什么是Embedding】
对于客观世界,人类通过各种文化产品来表达,比如:语言,艺术品,图书,手机,电脑等……
我们可以用语言表达,通过人的意识,比如问题,猜想,理论,反驳 来进一步表达。
对于脑科学家,一直在研究人的意识从何而来,但截止目前,并没有什么突破。人的大脑是怎么回事,我们并没有搞明白。但OpenAI的工程师说,他们现在就是在模仿人的意识的生成来进行AI的研发(一种说法)。
对于计算机,是如何记录或进一步理解客观世界呢?所有人都知道的答案,就是使用 0 和1了。
具体的来看一下:
灰度的图像:会使用0,1生成灰度的矩阵。

彩色的图像:将RGB拆出三个通道
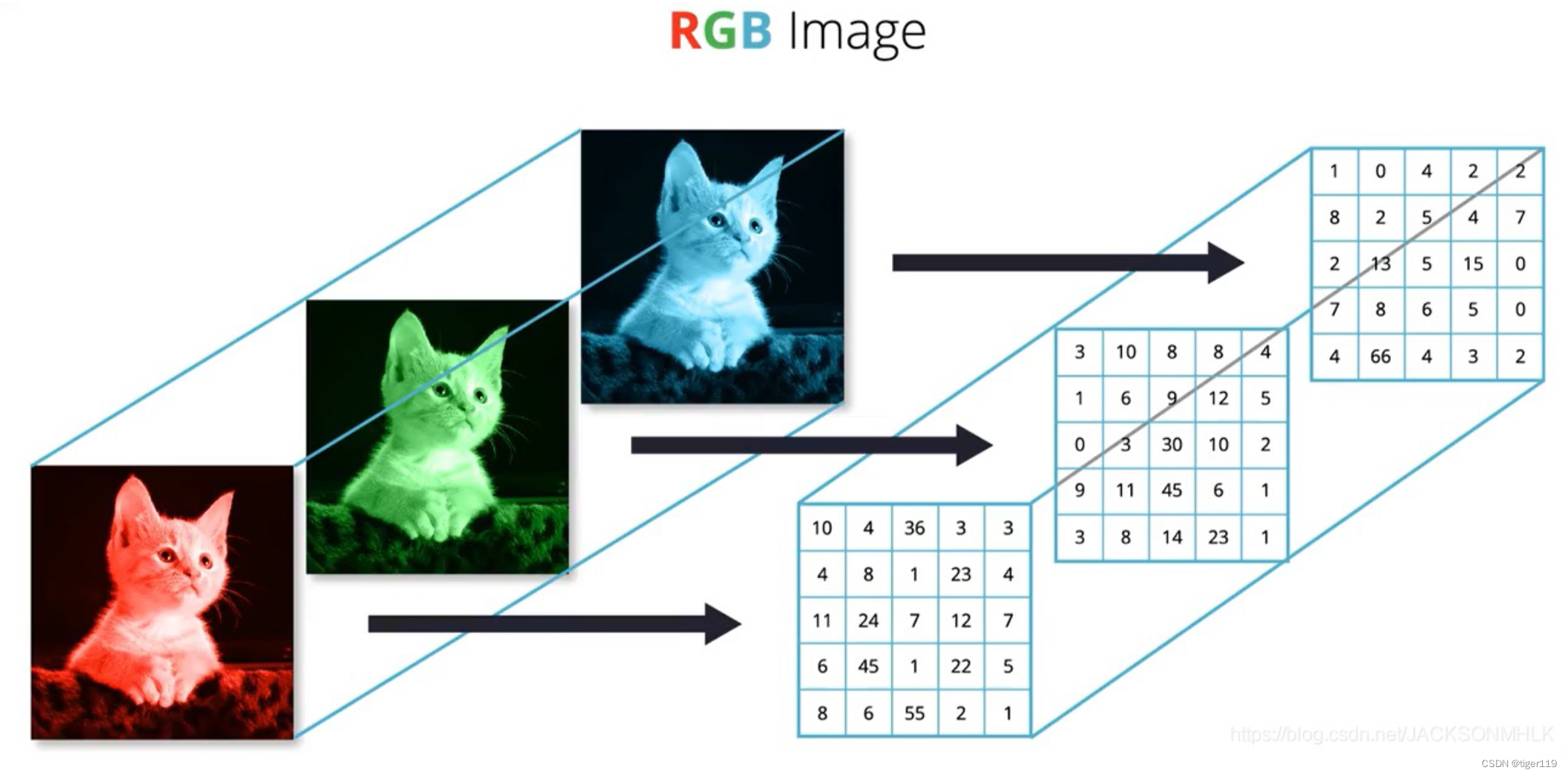
西文的表示:这个很简单,一一对应就好了。
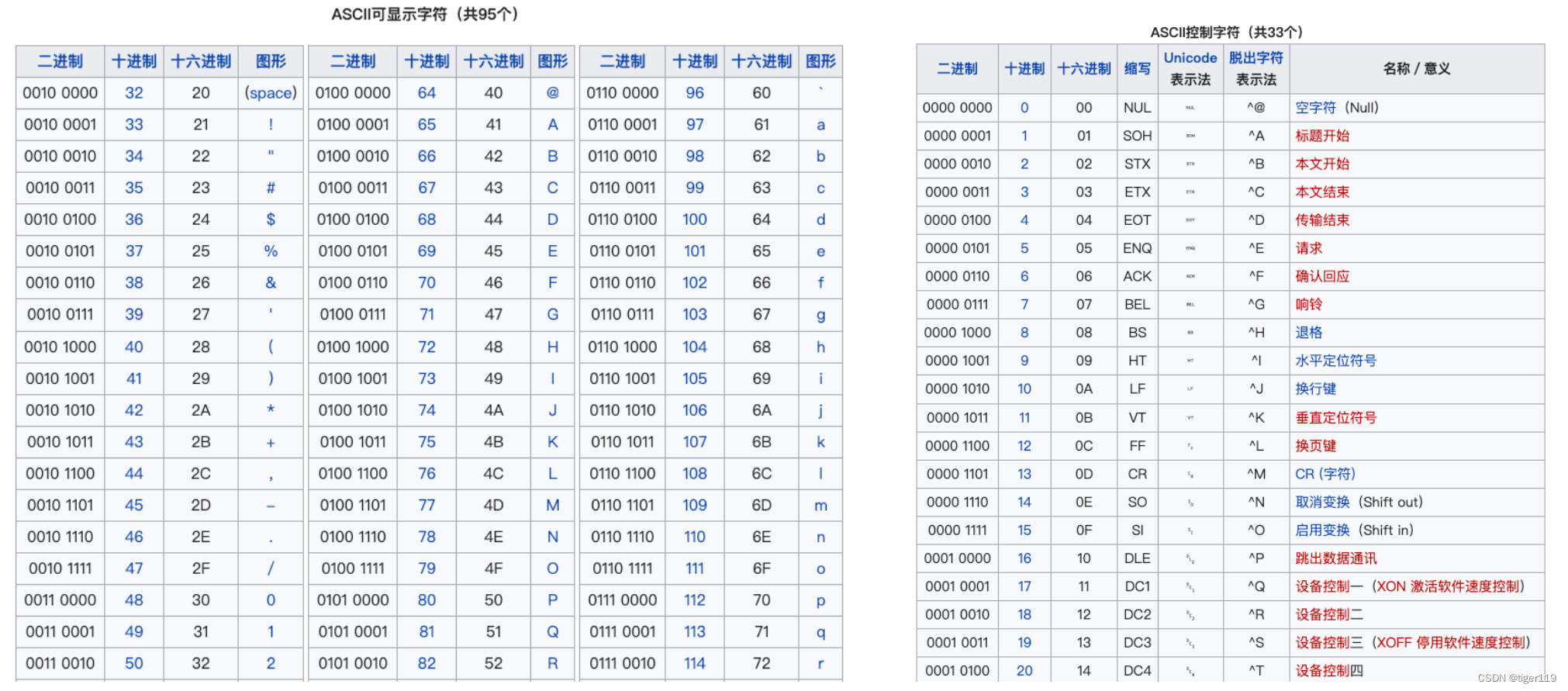
中文如何表示的呢?
Unicode, UTF-8(包含全世界的所有语言进行表达)(可变长度,1-4个字节,按需扩展)
但这些只表达了单个元素的存储,并没有有语义,没有理解。
在机器学习中,为了学习这些,我们进一步采用了 One-hot 编码,你可以理解按单词来进行记录。比如:OpenAI ,利用了 10万个编码。
那如何表达单词之间的关系呢?和其它一样,也是使用特征维度,比如gpt-4的embedding-data2采用了1536维的向量。也就是说,每个单词和其它单词,可以在1536个维度上进行比较。
这就是我们所说的语言模型了:
为了表达词语的语义,我们必须能计算和存储词与词之间的关联关系,也就是需要有一个多维的向量空间来理解语义。而这个多维的向量空间与每个词都有对应关系。我们认为单词映射到这个高维空间就是词嵌入(Embedding),通过这个高维空间可以捕捉到词的语义信息。
不知道绕了这么大一圈,有没有说清楚词嵌入是个什么概念,可能是中文翻译的原因,感觉这个嵌入的说法并不准确。
在进一步介绍Embedding之前,我们不得不说一下表示学习。
什么是表示学习?
我们通过算法,通过机器学习,从原始数据中学习到表示形式和特征,最终可理解数据的含义,学会一些知识。这叫做表示学习。
嵌入,然后通过降维,保留高维空间的含义,它是表示学习的重要表达方式。
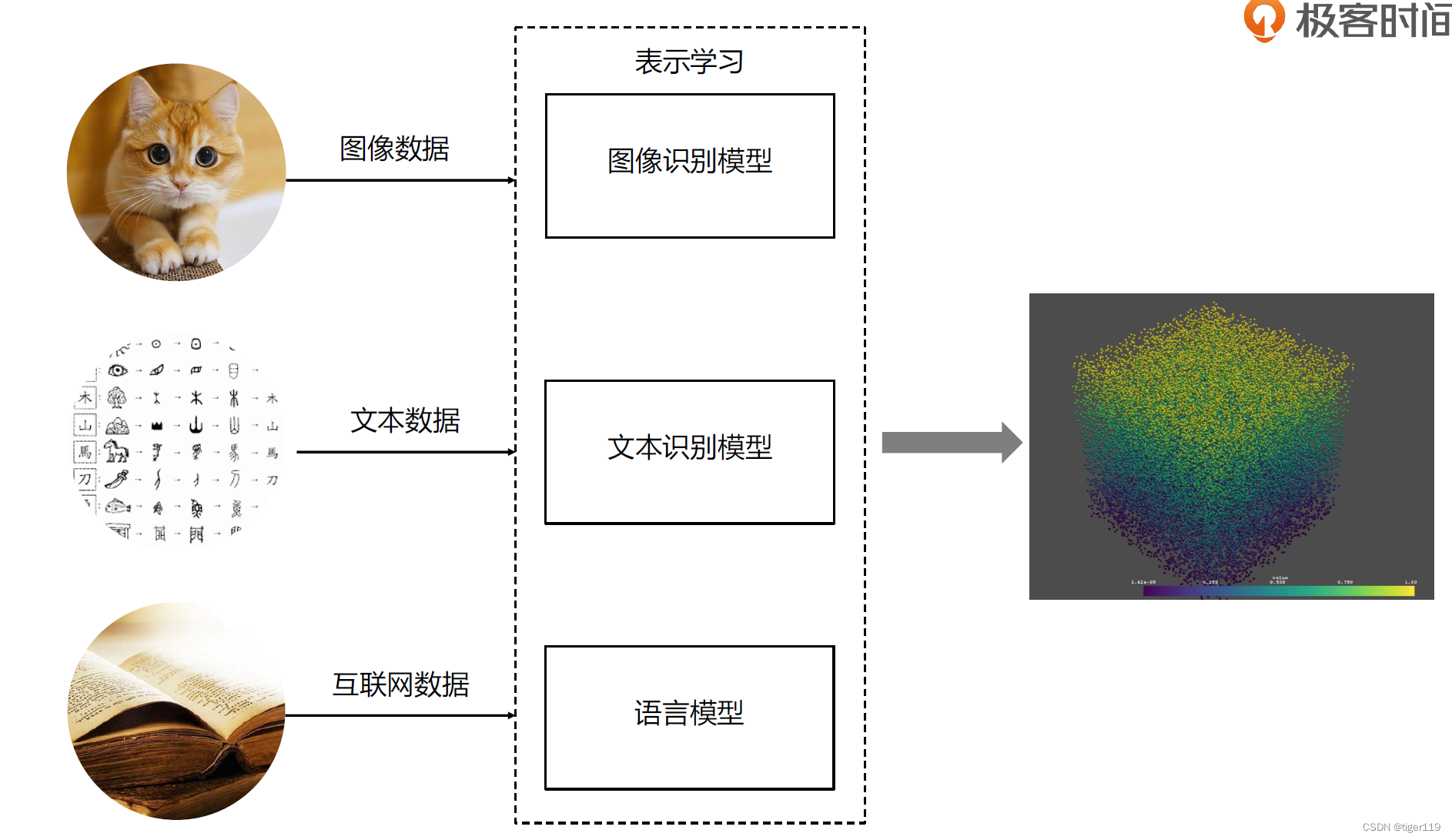
在表示学习的表达时,为了人可以看懂,需要通过Embeding 进行降维,变成人可以理解的信息。
我们拿大语言模型为例 ,为了表达语义,会使用嵌入将学习的特征存储起来。因为这些存储值都是实数,它们之间实际上是可以进行运算的。而运算的关系,会表达出语义(后面会举例)
Embedding的作用
其实讲了它的定义,它的作用就显而易见了。
看下图的输出,通过数据降维,可以通过颜色,位置就可表达学习的结果。
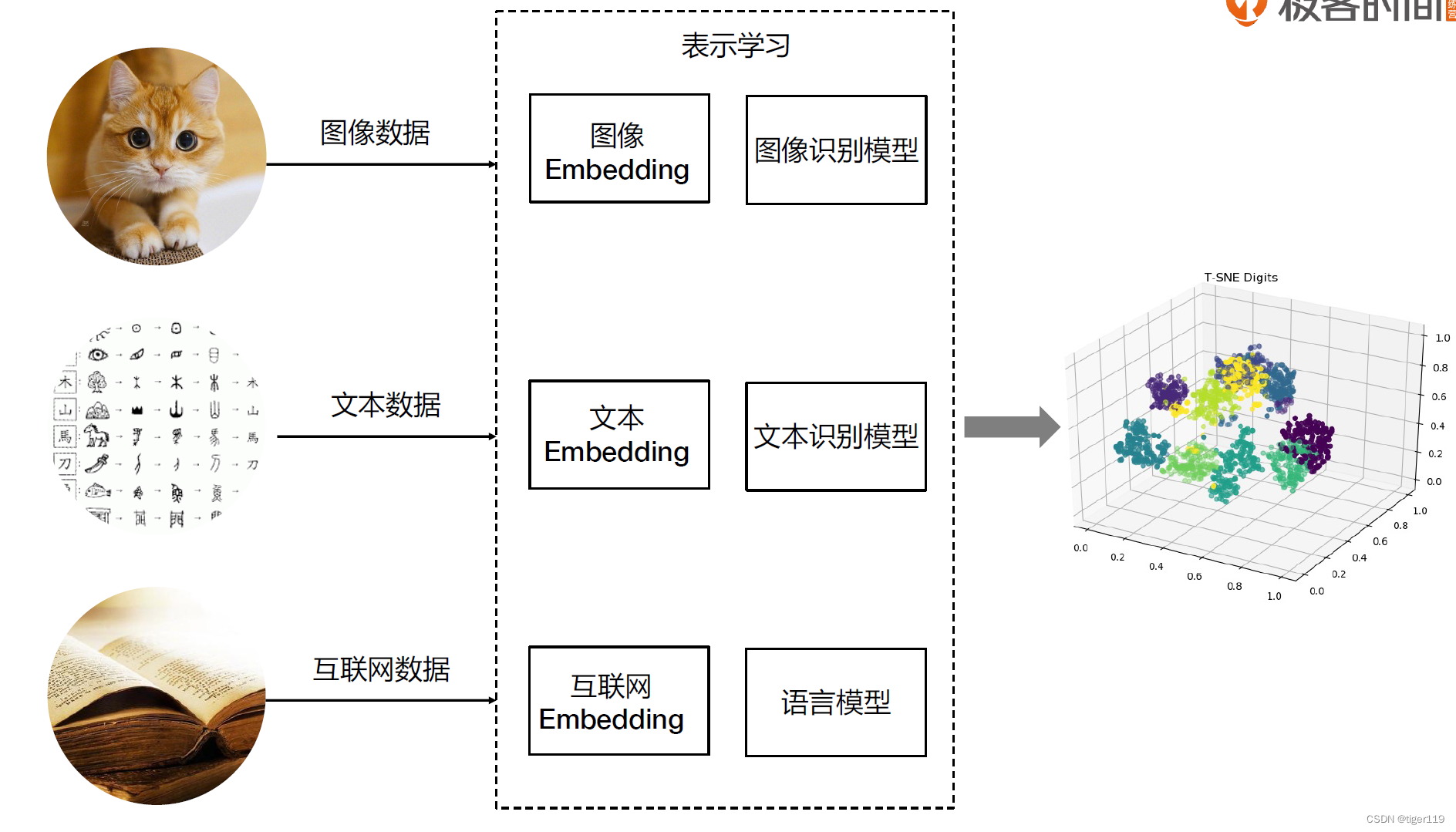
比如:我们认为图中在三维坐标离得近的,一定有相似的语义。而颜色可能是我们想比较的另外一个特征,我们通过颜色与位置的比较,可以得出一些结论。
再看这个,可以得出向量运算得到如下的关系,是不是有一定的道理。提取出了语义。
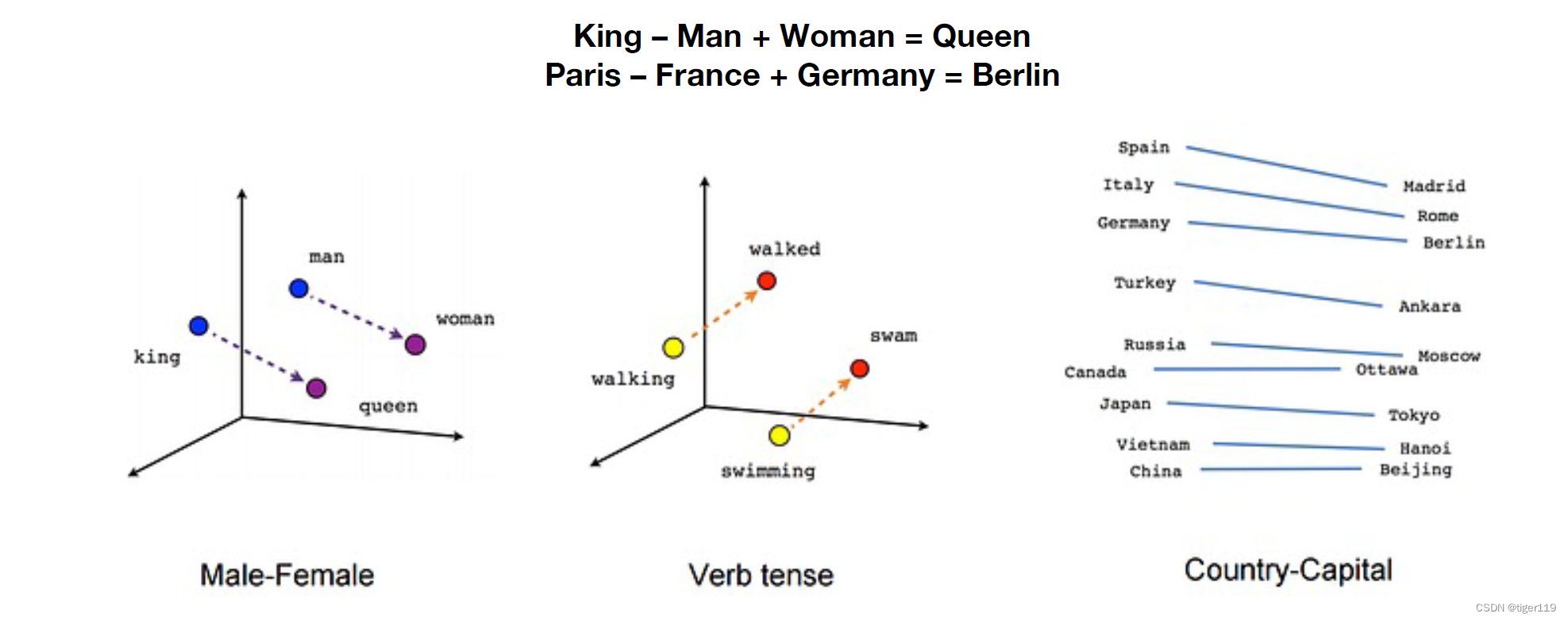
我们认为 King 和 Queern的差距 雷同于 Man 和 Woman的差距,这显然是符合语义的。
背后的原理是什么?
下面这张图,可以很是确的表达出Embedding技术在LLM中的重要性。
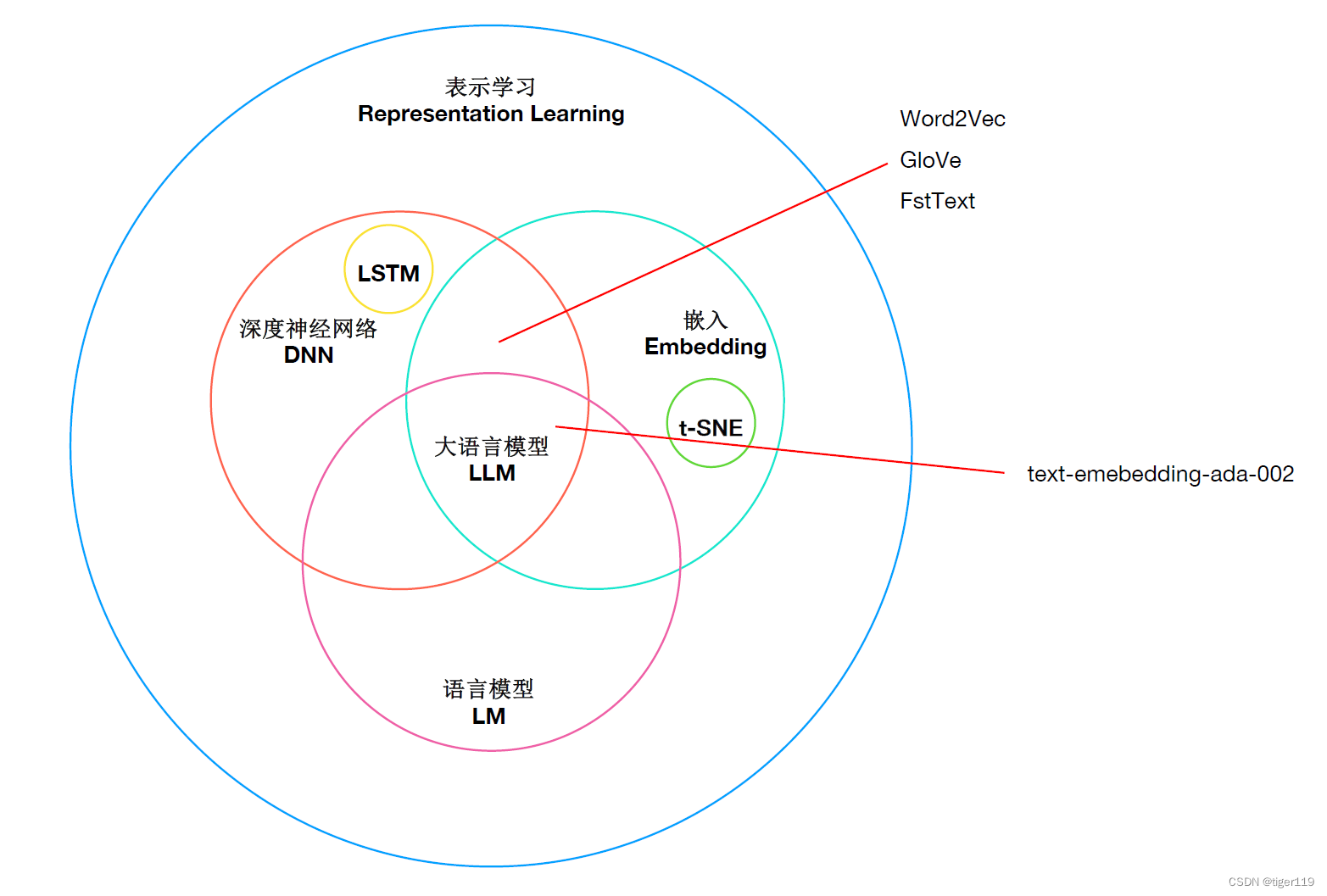
它的原理也很简单,就是一个提取文字特征的一种方式。而它们的语义的相似性,实际上也是我们通过现实世界中的一些存在的文本训练出来的(因为训练的过程会根据词之间的出现频率来进行推导,最终得到相互间的多维空间的关系值)
所以,可能训练出来的结果会存在偏见,但这种偏见一定是你给的语料里面存在的。
而因为我们对于训料语义的一视同仁,也可能在某些领域,得出的语义并不是真实的,只能说是大多数人的理解。(真理有时会掌握在少数人手里),碰到这种情况,就只能通过后期的微调来改善了。
如何使用Embedding
那我们可以直接使用它吗?其实OpenAI的API里面,对这个模型也可以付费使用的。
我们目前可用到的模型是:
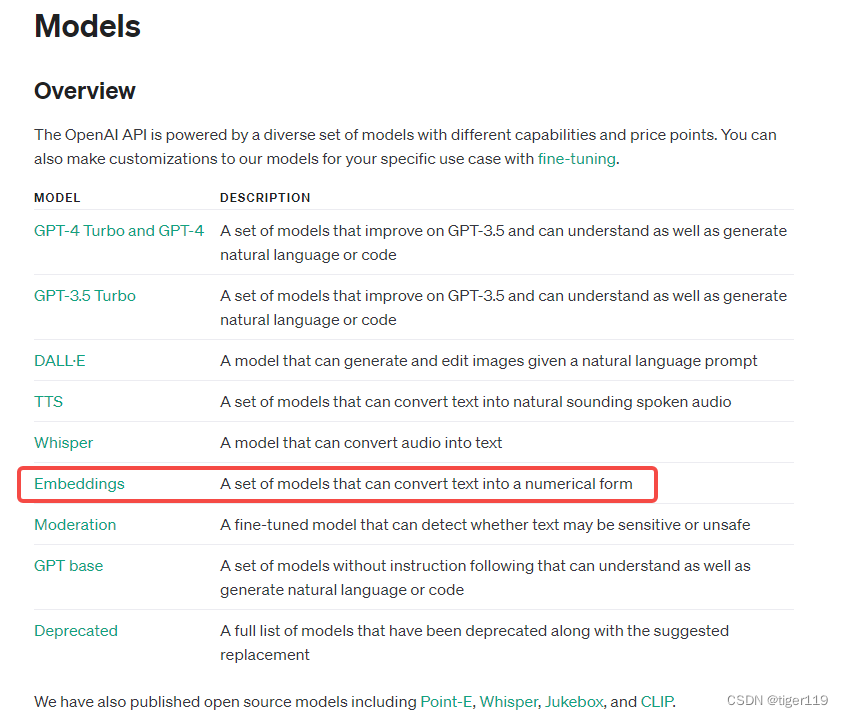

注意这里的1536维度,说明单词可以在1536维的空间中比较它们的相似度,这个其实很难用人的思维来理解了(为什么是1536,这应该是大量训练得出的经验值 ,实际上最新的版本已经扩展到3072维,不知道这种维度会带来什么惊喜)
如果我们单独使用,可以完成 文本的搜索,评论聚类等功能:
下面有三个例子来说明使用方法:
数据:对于羡食平台的评论,我们将评论的标题 和评论的主体内容放到一起来分析。
对于评论的评分做为一个相关因素来考察。
下面给了三个例子。
# 设置调用的API
embedding_model = "text-embedding-ada-002"
embedding_encoding = "cl100k_base"
from openai import OpenAI
client = OpenAI()
# 调用embedding,获得1536维的向量
def embedding_text(text, model="text-embedding-ada-002"):
res = client.embeddings.create(input=text, model=model)
return res.data[0].embedding
df["embedding"] = df.combined.apply(embedding_text)
# 示例一:评分和评论的相似度关系图
# 可以使用 t-SNE对结果进行降维显示,下面降为2维
# 可以得到 聚类后的图,查看效果
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
from sklearn.manifold import TSNE
matrix = np.vstack(df_embedded['embedding_vec'].values)
tsne = TSNE(n_components=2, perplexity=15, random_state=42, init='random', learning_rate=200)
vis_dims = tsne.fit_transform(matrix)
colors = ["red", "darkorange", "gold", "turquoise", "darkgreen"]
x = [x for x,y in vis_dims]
y = [y for x,y in vis_dims]
color_indices = df_embedded.Score.values - 1
colormap = matplotlib.colors.ListedColormap(colors)
plt.scatter(x, y, c=color_indices, cmap=colormap, alpha=0.3)
plt.title("Amazon ratings visualized in language using t-SNE")
plt.show()
# 示例二:评论的聚类 与评论的文本相似度的关系
import numpy as np
from sklearn.cluster import KMeans
n_clusters = 4
kmeans = KMeans(n_clusters = n_clusters, init='k-means++', random_state=42, n_init=10)
kmeans.fit(matrix)
df_embedded['Cluster'] = kmeans.labels_
colors = ["red", "green", "blue", "purple"]
tsne_model = TSNE(n_components=2, random_state=42)
vis_data = tsne_model.fit_transform(matrix)
x = vis_data[:, 0]
y = vis_data[:, 1]
color_indices = df_embedded['Cluster'].values
colormap = matplotlib.colors.ListedColormap(colors)
plt.scatter(x, y, c=color_indices, cmap=colormap)
plt.title("Clustering visualized in 2D using t-SNE")
plt.show()
# 示例三:文本检索,输入关键字,查找相似的评论
# cosine_similarity 函数计算两个嵌入向量之间的余弦相似度。
def cosine_similarity(a, b):
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
# 定义一个名为 search_reviews 的函数,
def search_reviews(df, product_description, n=3, pprint=True):
product_embedding = embedding_text(product_description)
df["similarity"] = df.embedding_vec.apply(lambda x: cosine_similarity(x, product_embedding))
results = (
df.sort_values("similarity", ascending=False)
.head(n)
.combined.str.replace("Title: ", "")
.str.replace("; Content:", ": ")
)
if pprint:
for r in results:
print(r[:200])
print()
return results
res = search_reviews(df_embedded, 'delicious beans', n=3)
例子一的输出:
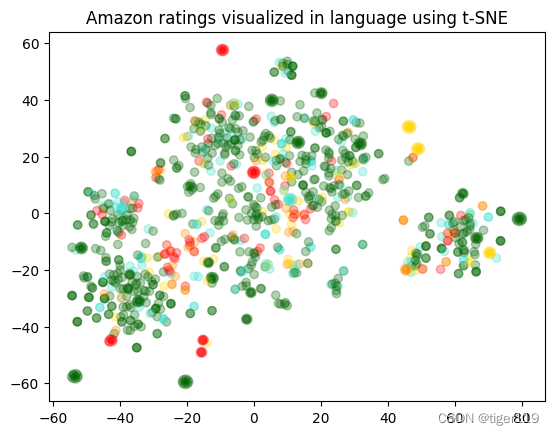
上图可以看出,评论分成了几大块,分别有正面,负面,狗粮相关评论(通过实际数据可以看出,这个分类没有问题)。
但是,评分与评论的关系好像并不明显?
其实这也很好解释:因为网络评价就是这样,高分有可能是个负面评论,正面评论可能是个高分,没有直接相关性。下面例子进一步说明。
例子二:
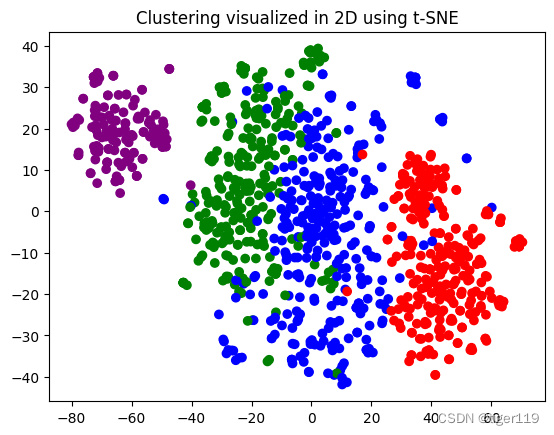
我们通过聚类,用聚类的值替代评分,发现了KMeans的聚类 和 评论相似度的计算是一致的,仔细查看四个色块的评论,确实是四种不同的评论。分别是:两个正面,一个狗粮评论,一个负面评论)
例子三的输出:
Good Buy: I liked the beans. They were vacuum sealed, plump and moist. Would recommend them for any use. I personally split and stuck them in some vodka to make vanilla extract. Yum!
Jamaican Blue beans: Excellent coffee bean for roasting. Our family just purchased another 5 pounds for more roasting. Plenty of flavor and mild on acidity when roasted to a dark brown bean and befor
Delicious!: I enjoy this white beans seasoning, it gives a rich flavor to the beans I just love it, my mother in law didn't know about this Zatarain's brand and now she is traying different seasoning
可以看出,搜索的效果非常不错,
对了,RAG的向量知识库的检索,背后的技术原理应该就是使用Embedding来完成的。
好了,差不多就这些内容了,Embedding技术了解这么多就足够了。















 1615
1615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









