






 本文概述了卷积神经网络的基础,包括AlexNet、VGG-16和残差网络的结构特点。介绍了常用的数据集如MNIST、Fashion-MNIST、CIFAR-10、PASCALVOC、MSCOCO和ImageNet,以及深度学习的评价指标、YOLO网络和语义分割等内容。风格迁移和人脸识别也被提及作为应用示例。
本文概述了卷积神经网络的基础,包括AlexNet、VGG-16和残差网络的结构特点。介绍了常用的数据集如MNIST、Fashion-MNIST、CIFAR-10、PASCALVOC、MSCOCO和ImageNet,以及深度学习的评价指标、YOLO网络和语义分割等内容。风格迁移和人脸识别也被提及作为应用示例。
第5章 卷积神经网络基础
5.3 基本卷积神经网络
5.3.1 AlexNEt
网络结构
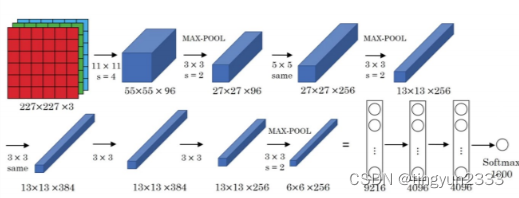
网络说明
网络说明 :
网络一共有8层可学习层——5层卷积层和3层全连接层
改进:
池化层均采用最大池化
选用ReLU作为非线性环节激活函数
网络规模扩大,参数数量接近6000万
出现“多个卷积层+一个池化层”的结构
普遍规律
随网络深入,宽、高衰减,通道数增加
左侧:连接数 右侧:参数

改进:输入样本
最简单、通用的图像数据变形的方式
从原始图像(256,256)中,随机的crop出一些图像(224,224)。【平移变换,crop】水平翻转图像。【反射变换,flip】给图像增加一些随机的光照。【光照、彩色变换,color jittering】
改进:激活函数
采用ReLU替代 Tan Sigmoid
用于卷积层与全连接层之后
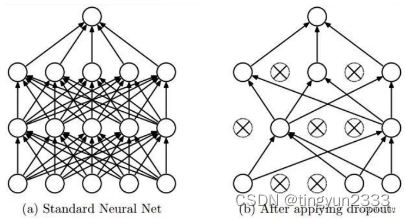
改进:Dropout
在每个全连接层后面使用一个 Dropout 层,以概率 p 随机关闭激活函数
改进:双GPU策略
AlexNet使用两块GTX580显卡进行训练,两块显卡只需要在特定的层进行通信
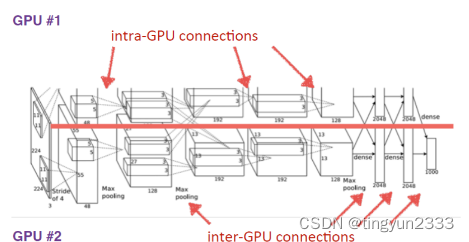
详细解释:以第一层conv1为例
relu1:max(0,𝑥),作为激活函数紧接在卷积层后面
norm1:局部响应归一化LRN
LRN层作用不大,在CNN中并不常用
pool1:采用max pooling
pooling核大小为3×3
stride为2,即pooling核的步长是2,即2倍降采样
此处的pool1层是有交叠的池化层,即pooling核在相邻位置有重叠
5.3.2 VGG-16
网络结构
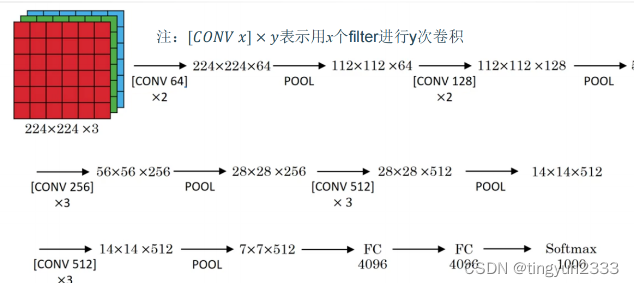
参数数量变化
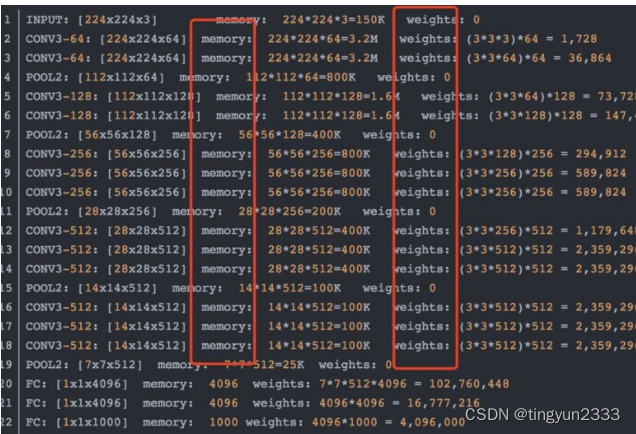
网络说明
改进
网络规模进一步增大,参数数量约为1.38亿
由于各卷积层、池化层的超参数基本相同,整体结构呈现出规整的特点。
普遍规律
随网络深入,高和宽衰减,通道数增多。
5.3.3 残差网络
非残差网络的缺陷
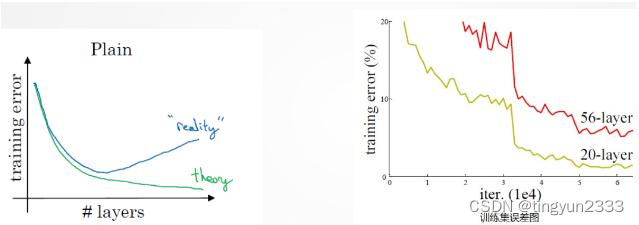
残差网络的优势
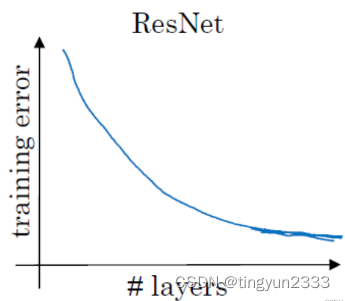
残差块
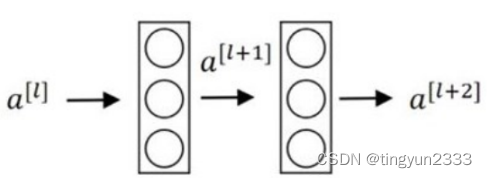
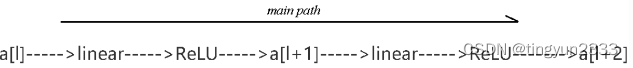
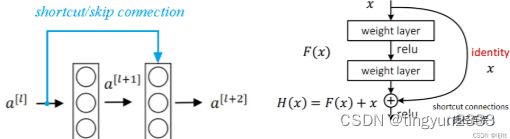



残差网络
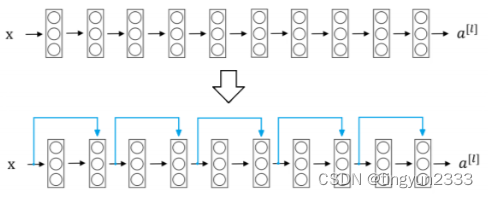
普通网络的基准模型受VGG网络的启发卷积层主要有3×3的过滤器,并遵循两个简单的设计规则:①对输出特征图的尺寸相同的各层,都有相同数量的过滤器; ②如果特征图的大小减半,那么过滤器的数量就增加一倍,以保证每一层的时间复杂度相同。ResNet模型比VGG网络更少的过滤器和更低的复杂性。ResNet具有34层的权重层,有36亿FLOPs,只是VGG-19(19.6亿FLOPs)的18%。
5.4 常用数据集
MNIST
MNIST数据集主要由一些手写数字的图片和相应的标签组成,图片一共有 10 类分别对应从0~9
原始的MNIST数据库一共包含下面 4 个文件
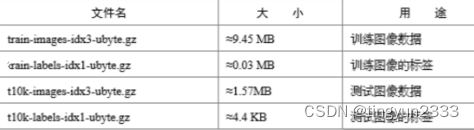
MNIST数据集是由0〜9手写数字图片和数字标签所组成的,由60000个训练样本和10000个测试样本组成,每个样本都是一张28 * 28像素的灰度手写数字图片。

Fashion-MNIST数据集
FashionMNIST是一个替代MNIST手写数字集的图像数据集。它是由 Zalando旗下的研究部门提供,涵盖了来自 10 种类别的共 7 万个不同商品的正面图片。
FashionMNIST 的大小、格式和训练集/测试集划分与原始的MNIST 完全一致。60000/10000 的训练测试数据划分,28x28的灰度图片。你可以直接用它来测试你的机器学习和深度学习算法性能,且不需要改动任何的代码。
以下是数据集中的类,以及来自每个类的10个随机图像:

CIFAR-10数据集
CIFAR-10数据集由10个类的60000个32x32彩色图像组成,每个类有6000个图像。有50000个训练图像和10000个测试图像
数据集分为五个训练批次和一个测试批次,每个批次有10000个图像。测试批次包含来自每个类别的恰好1000个随机选择的图像
以下是数据集中的类,以及来自每个类的10个随机图像:

PASCAL VOC数据集
PASCAL的全称是Pattern Analysis, Statistical Modelling and Computational Learning
VOC的全称是Visual Object Classes
目标分类(识别)、检测、分割最常用的数据集之一
第一届PASCAL VOC举办于2005年,2012年终止。常用的是PASCAL 2012
一共分成20类:
person
bird, cat, cow, dog, horse, sheep
aeroplane, bicycle, boat, bus, car, motorbike, train
bottle, chair, dining table, potted plant, sofa, tv/monitorVTL
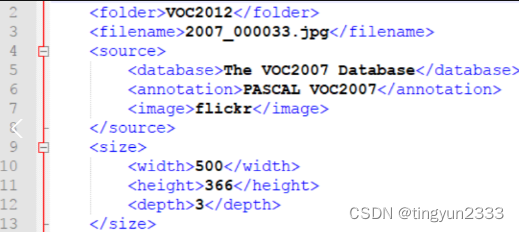
标注格式: 里面是图像对应的XML标注信息描述,每张图像有一个与之对应同名的描述XML文件,XML前面部分声明图像数据来源,大小等元信息,举例如下:
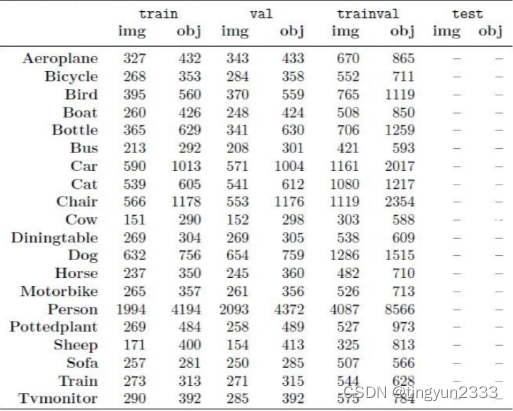
Pascal VOC2012 Main中统计的训练、验证、验证与训练、测试图像:
20类图像实例:

MS COCO数据集
PASCAL的全称是Microsoft Common Objects in Context,起源于微软于2014年出资标注的Microsoft COCO数据集
数据集以scene understanding为目标,主要从复杂的日常场景中截取
包含目标分类(识别)、检测、分割、语义标注等数据集
ImageNet竞赛停办后,COCO竞赛就成为是当前目标识别、检测等领域的一个最权威、最重要的标杆
官网:http://cocodataset.orgVTL
提供的标注类别有80 类,有超过33 万张图片,其中20 万张有标注,整个数据集中个体的数目超过150 万个。
人:1类
交通工具:8类,自行车,汽车等
公路常见:5类,信号灯,停车标志等
动物:10类,猫狗等
携带物品:5类,背包,雨伞等
运动器材:10类,飞盘,滑雪板,网球拍等。
厨房餐具:7类,瓶子,勺子等
水果及食品:10类
家庭用品:7类,椅子、床,电视等
家庭常见物品:17类,笔记本,鼠标,遥控器等VTL
MS COCO数据集示例

ImageNet数据集
始于2009年,李飞飞与Google的合作:“ImageNet: A Large-Scale Hierarchical Image Database”
总图像数据:14,197,122
总类别数:21841
带有标记框的图像数:1,034,908VTL
ISLVRC 2012子数据集
训练集:1,281,167张图片+标签
类别数:1,000
验证集:50,000张图片+标签
测试集:100,000张图片VTL
5.5 总结
经典网络:以“一个或多个卷积层+一个池化层“作为一个基本单元进行堆叠,在网络尾部使用全连接层,最后以Softmax为分类器,输出结果。
残差网络:在普通网络的基础上,将浅层的激活项通过支路直接传向深层,克服深层神经网络中梯度消失的问题,为训练极深的神经网络提供便利。
数据集:常见的数据集包括VOC和COCO;ImageNet较大
第6章 深度学习视觉应用
6.1 评价指标
算法评估相关概念:
TP: 被正确地划分为正例的个数,即实际为正例且被分类器划分为正例的实例数
FP: 被错误地划分为正例的个数,即实际为负例但被分类器划分为正例的实例数
FN:被错误地划分为负例的个数,即实际为正例但被分类器划分为负例的实例数
TN: 被正确地划分为负例的个数,即实际为负例且被分类器划分为负例的实例数
P(精确率): TP/(TP+FP)
R(召回率): TP/(TP+FN)。召回率越高,准确度越低
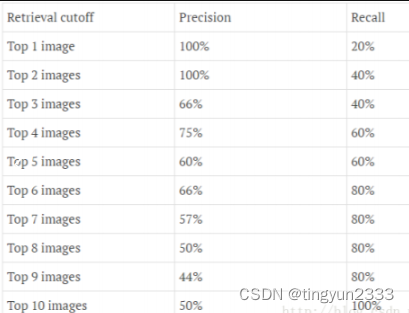
P-R曲线
P-R的关系曲线图,表示了召回率和准确率之间的关系
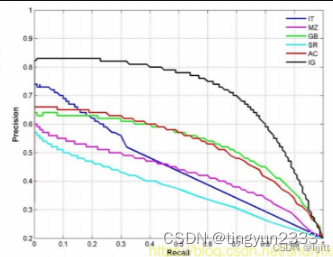
精度(准确率)越高,召回率越低
示例: 假设一个测试集,其中图片只由大雁和飞机两种图片组成

True positives : 飞机的图片被正确的识别成了飞机。
False positives: 大雁的图片被错误地识别成了飞机。
False negatives: 飞机的图片没有被识别出来,系统错误地认为它们是大雁。
True negatives: 大雁的图片没有被识别出来,系统正确地认为它们是大雁
假设使用CNN得到飞机分类结果如下:
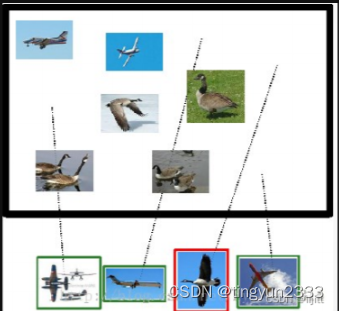
分类为飞机(正样本)的四张照片中:
True positives : 有三个,画绿色框的飞机。
False positives: 有一个,画红色框的大雁。
分类为大雁(负样本)的四张照片中:
True negatives : 有四个,这四个大雁的图片,系统正确地没有把它们识别成飞机。
False negatives: 有两个,两个飞机没有被识别出来,系统错误地认为它们是大雁。
置信度与准确率
调整阈值可改变准确率或召回值
在刚才例子中,对应某阈值,前四个样本(左侧)被分类为飞机改变阈值会改变划分,进一步影响准确率或召回值
可以通过改变阈值(也可以看作上下移动蓝色的虚线),来选择让系统识别能出多少个图片,当然阈值的变化会导致Precision与Recall值发生变化。比如,把蓝色虚线放到第一张图片下面,也就是说让系统只识别出最上面的那张飞机图片,那么Precision的值就是100%,而Recall的值则是20%。如果把蓝色虚线放到第二张图片下面,也就是说让系统只识别出最上面的前两张图片,那么Precision的值还是100%,而Recall的值则增长到是40%。
不同阈值条件下,Precision与Recall的变化情况
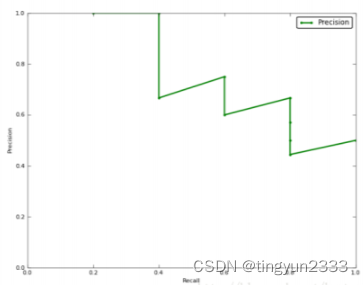
P-R曲线
AP计算
mAP:均值平均准确率
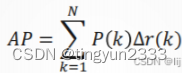
其中𝑁代表测试集中所有图片的个数,𝑃(𝑘)表示在能识别出𝑘个图片的时候Precision的值,而 Δ𝑟(𝑘)则表示识别图片个数从𝑘 − 1变化到𝑘时(通过调整阈值)Recall值的变化情况。
在这一例子中,AP的值
= (1 ∗ (0.2 − 0)) + (1 ∗ (0.4 − 0.2)) + (0.66 ∗ (0.4 − 0.4)) + (0.75 ∗ (0.6− 0.4)) + (0.6 ∗ (0.6 − 0.6)) + (0.66 ∗ (0.8 − 0.6)) + (0.57 ∗ (0.8 − 0.8))+ (0.5 ∗ (0.8 − 0.8)) + (0.44 ∗ (0.8 − 0.8)) + (0.5 ∗ (1 − 0.8)) = 0.782.
= (1 ∗ 0.2) + (1 ∗ 0.2) + (0.66 ∗ 0) + (0.75 ∗ 0.2) + (0.6 ∗ 0) + (0.66∗ 0.2) + (0.57 ∗ 0) + (0.5 ∗ 0) + (0.44 ∗ 0) + (0.5 ∗ 0.2) = 0.782.
通过计算可以看到,那些Recall值没有变化的地方(红色数值),对增加Average Precision值没有贡献。
每一个类别均可确定对应的AP。
多类的检测中,取每个类AP的平均值,即为mAP。
6.2 YOLO网络
6.2.1 YOLO网络结构
网络结构包含24个卷积层和2个全连接层;其中前20个卷积层用来做预训练,后面4个是随机初始化的卷积层,和2个全连接层。
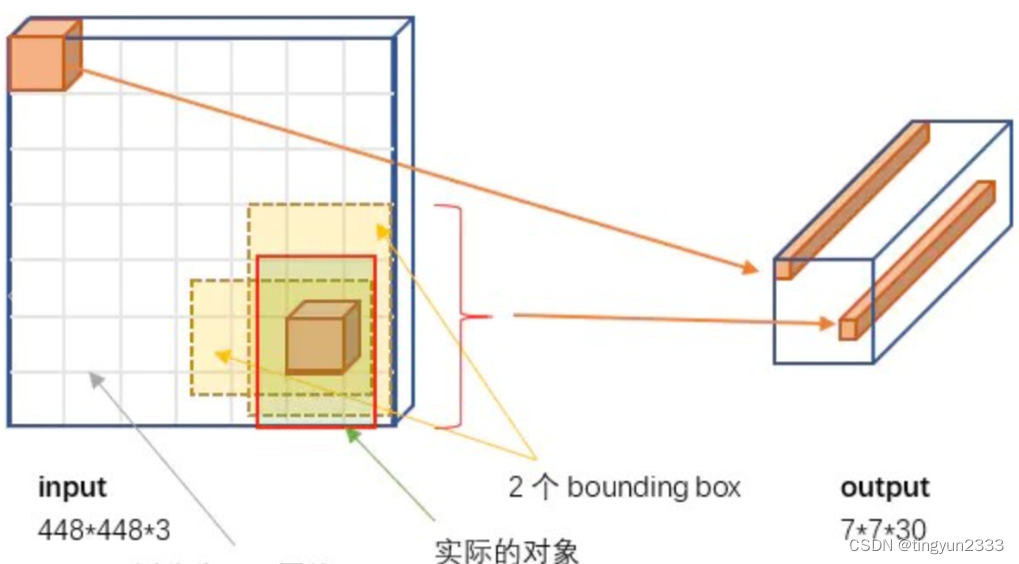
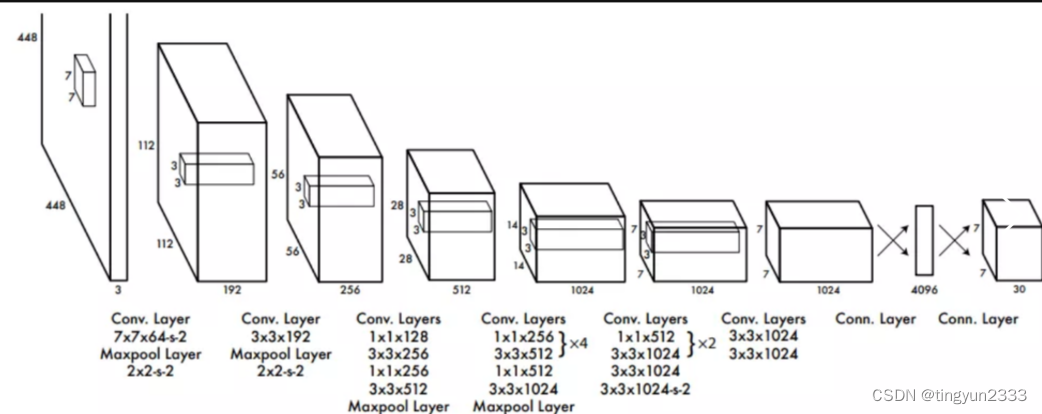
6.2.2 YOLO网络输入及输出
网络输入:
YOLO v1在PASCAL VOC数据集上进行的训练,因此输入图片为448 × 448 × 3。实际中如为其它尺寸,需要resize或切割成要求尺寸。
将图片分割为 𝑆 2个grid(𝑆 = 7),每个grid cell的大小都是相等的;每个格子都可以检测是否包含目标;YOLO v1中,每个格子只能检测一种物体(但可以不同大小)

网络输出:
输出是一个7 × 7 × 30的张量。对应7 × 7个cell ,每个cell对应2个包围框(bounding box, bb),预测不同大小和宽高比,对应检测不同目标。每个bb有5个分量, 分别是物体的中心位置(𝑥, 𝑦)和它的高(ℎ) 和宽 (𝑤) ,以及这次预测的置信度。
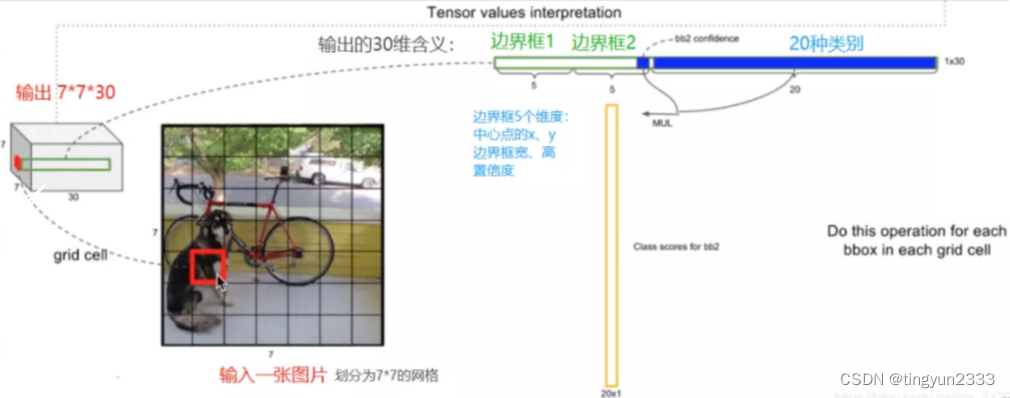
6.2.3 YOLO处理细节
6.2.3.1 YOLO包围框
有S×S个框,每个框的bb个数为𝐵,分类器可以识别出𝐶种不同的物体, 那么所有整个ground truth的长度为𝑆 × 𝑆 × (𝐵 × 5 + 𝐶) YOLO v1中,这个数量是30 ;YOLO v2和以后版本使用了自聚类的anchor box为bb, v2版本为𝐵 = 5, v3中𝐵 =9
6.2.3.2 归一化
四个关于位置的值,分别是 𝑥, 𝑦, ℎ 和 𝑤 ,均为整数,实际预测中收敛慢因此,需要对数据进行归一化,在0-1之间。
6.2.3.3 置信度
置信度计算公式:
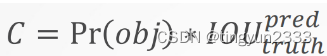
Pr(𝑜𝑏𝑗)是一个grid有物体的概率
IOU是预测的bb和真实的物体位置的交并比。
6.2.3.4 训练数据及网络输出
Pr𝑜𝑏𝑗 的ground truth :三个目标中点对应格子为 1 ,其它为 0

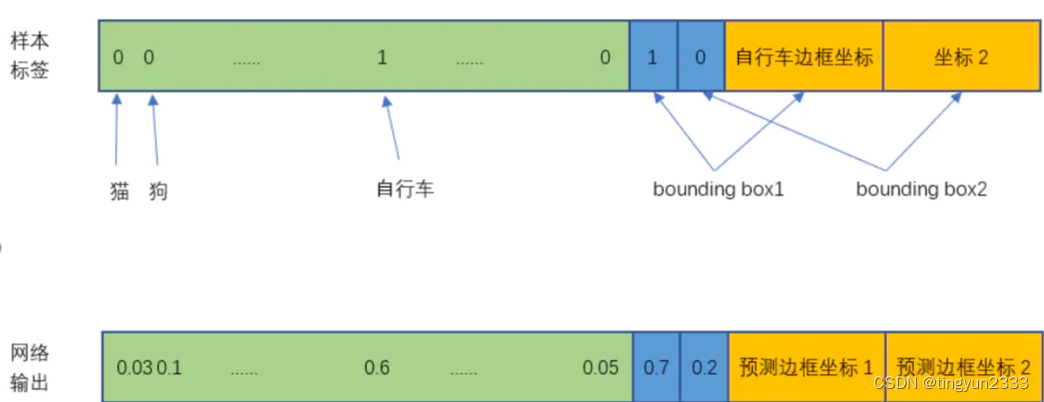
6.2.4 损失函数
YOLO损失函数一共五项


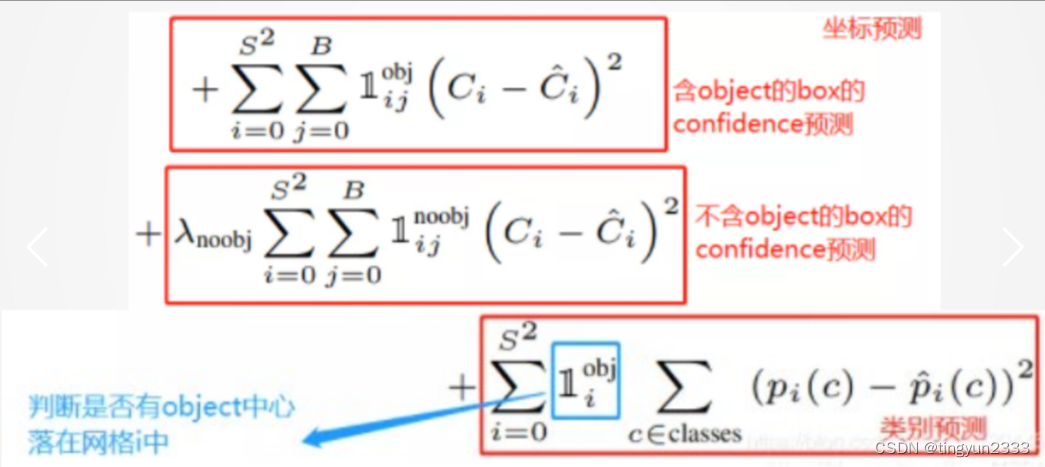
6.2.5 训练与NMS(非极大值抑制)
6.2.5.1 NMS算法要点
首先丢弃概率小于预定IOU阈值(例如0.5)的所有边界框;
对于剩余的边界框:选择具有最高概率的边界框并将其作为输出预测;
计算 “作为输出预测的边界框”,与其他边界框的相关联IoU 值;舍去IoU大于阈值的边界框;其实就是舍弃与“作为输出预 测的边界框” 很相近的框框。
重复步骤2,直到所有边界框都被视为输出预测或被舍弃
6.2.5.2 数据集训练
YOLO先使用ImageNet数据集对前20层卷积网络进行预训练,然后使用完整的网络,在PASCAL VOC数据集上进行对象识别和定位的训练和预测
训练中采用了drop out和数据增强来防止过拟合。
YOLO的最后一层采用线性激活函数(因为要回归bb位置),其它层都是采用Leaky ReLU激活函数:
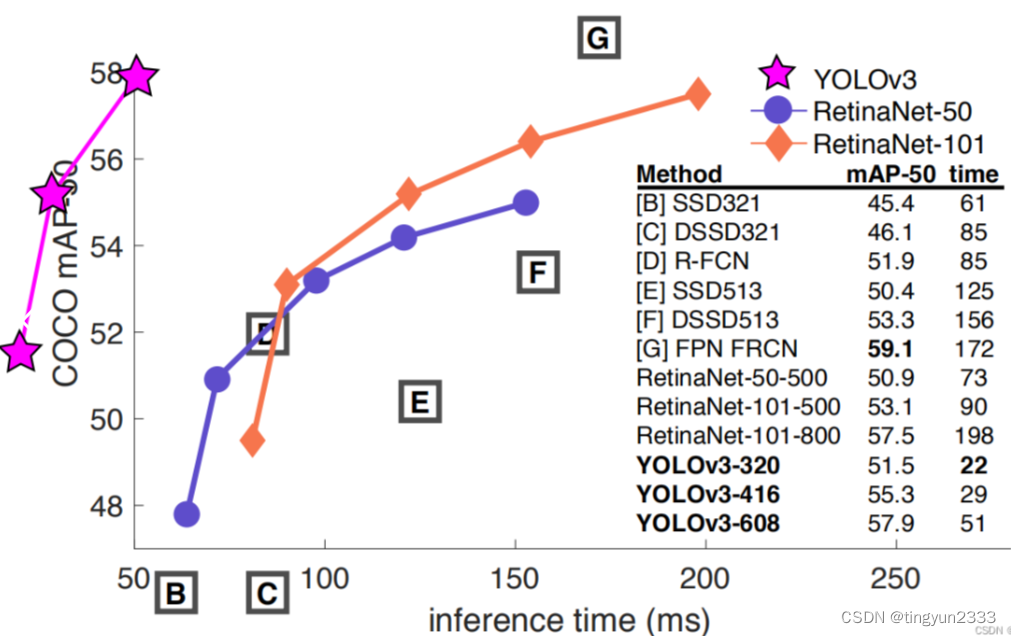
YOLO V3模型效果
6.3. 语义分割与FCN
6.3.1 语义分割定义及算法发展历史
语义分割:找到同一画面中的不同类型目标区域
基本思想:对图中每一个像素进行分类,得到对应标签
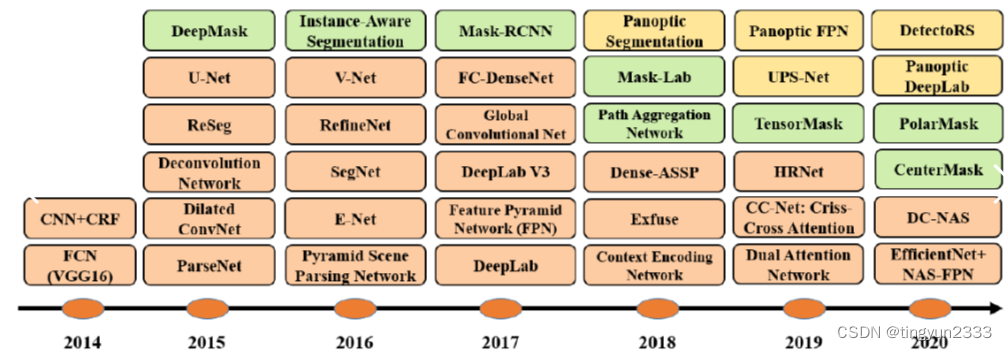
语义分割发展历史
6.3.2 反卷积与反池化
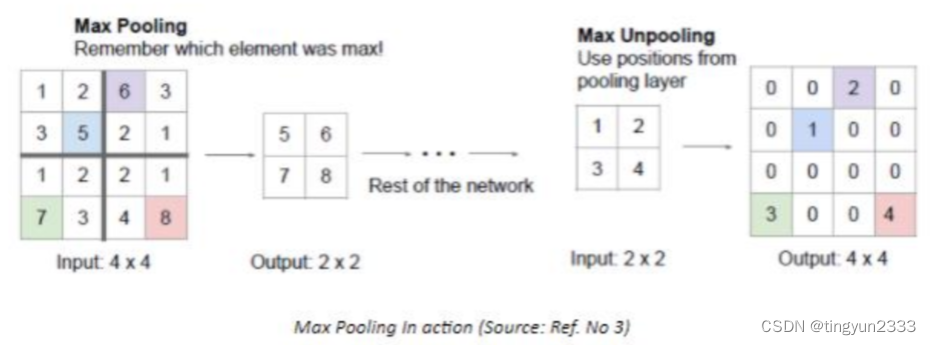
反卷积
反池化(上池化)
6.3.3 FCN具体实现
卷积部分:
FCN中第6、7、8层都是通过 1 × 1 卷积得到的,第6层的输出是 4096 × 7 × 7 ,第7层的输出是 4096 × 7 × 7 ,第8层的输出是 1000 × 7 × 7 ,即1000个大小是 7 × 7 的特征图(称为heatmap)
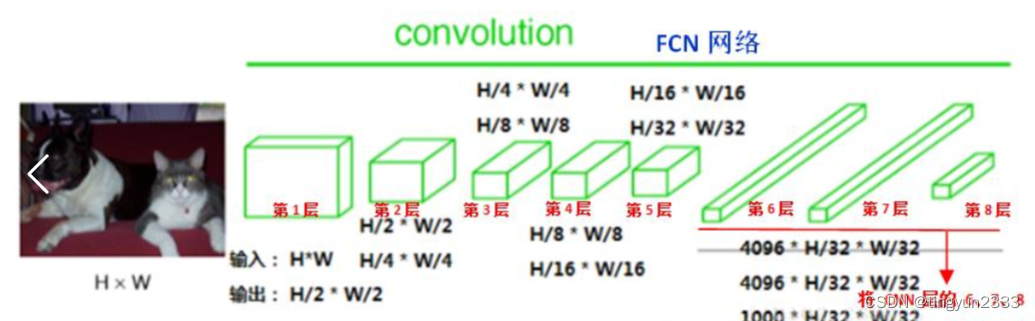
反卷积部分:
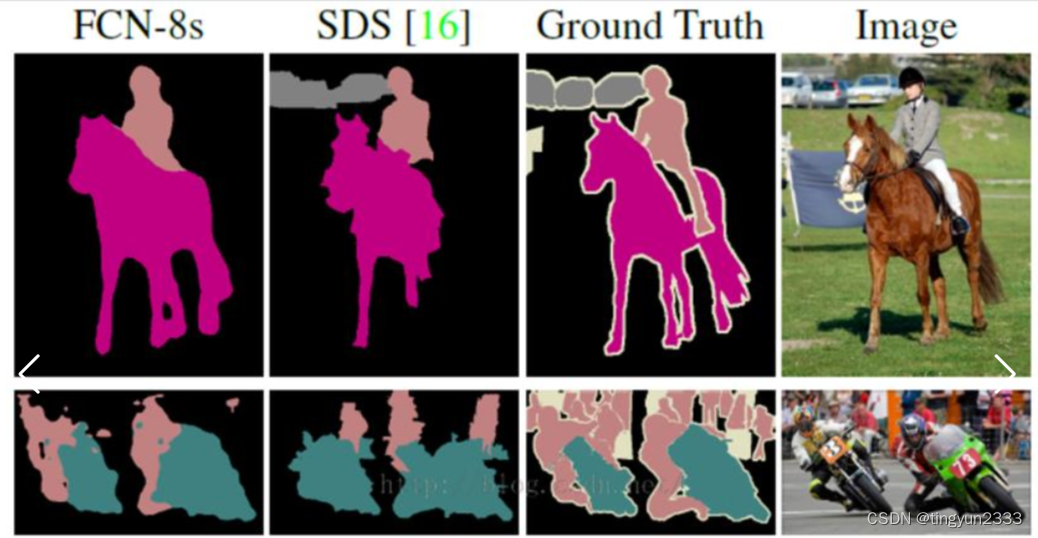
6.3.4 FCN训练结果
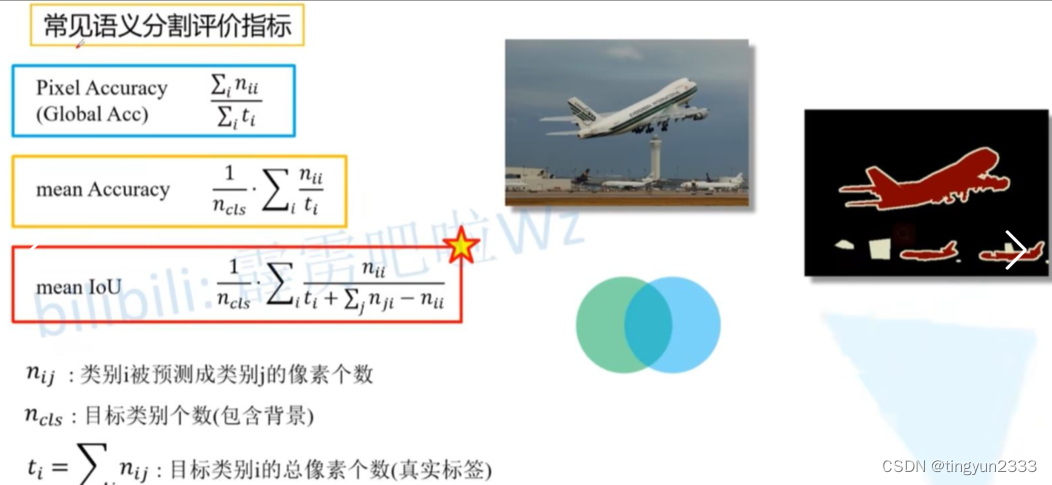
6.3.5 FCN评价指标与标注工具
评价指标
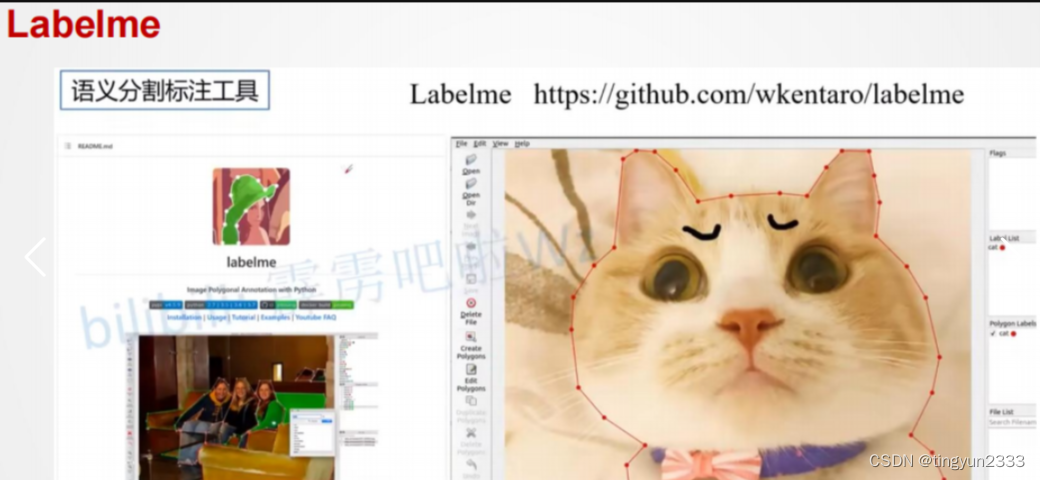
常见标注工具
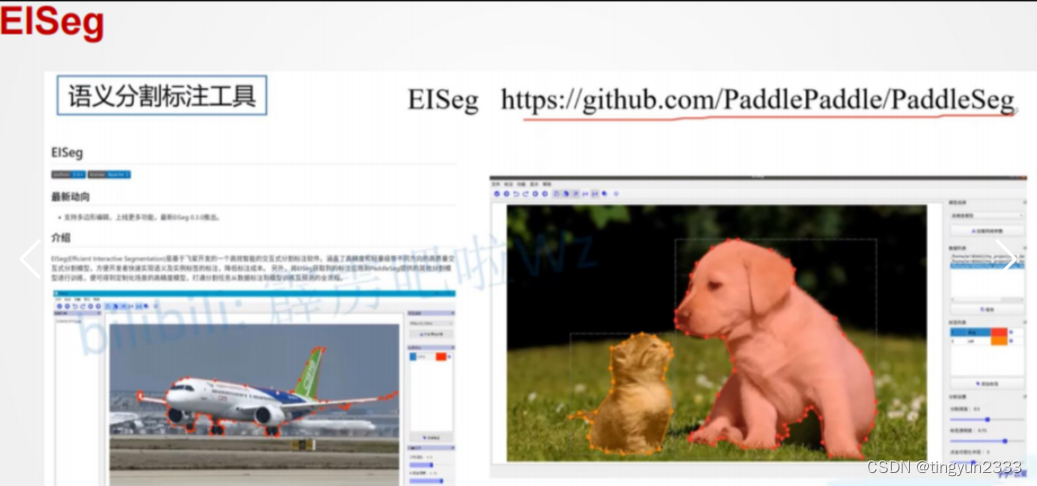
6.4 风格迁移
定义:如果你是一位摄影爱好者,也许接触过滤镜。它能改变照片的颜色样式,从而使风景照更加锐利或者令人像更加美白。但一个滤镜通常只能改变照片的某个方面。如果要照片达到理想中的样式,经常需要尝试大量不同的组合, 其复杂程度不亚于模型调参。 在本节中,我们将介绍如何使用卷积神经网络自动将某图像中的样式应用在 另一图像之上,即风格迁移。 这里我们需要两张输入图像,一张是内容图像,另一张是样式图像,我们将使用神经网络修改内容图像使其在样式上接近样式图像。

6.4.1 方法
首先,我们初始化合成图像,例如将其初始化成内容图像。该合成图像是样式迁移过程中唯一需要更新的变量,即样式迁移所需迭代的模型参数。
然后,我们选择一个预训练的卷积神经网络来抽取图像的特征,其中的模型参数在训练中无须更新。深度卷积神经网络凭借多个层逐级抽取图像的特征。我们可以选择其中某些层的输出作为内容特征或样式特征。
6.4.2 损失函数
内容损失(content loss)使合成图像与内容图像在内容特征上接近
样式损失(style loss)令合成图像与样式图像在样式特征上接近
总变差损失(total variation loss)则有助于减少合成图像中的噪点。 最后,当模型训练结束时,我们输出样式迁移的模型参数,即得到最终的合成图像
内容代价函数:
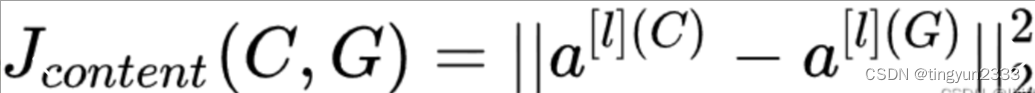
风格代价函数
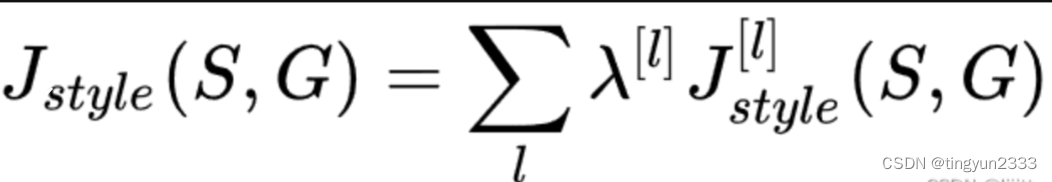
总体风格代价函数
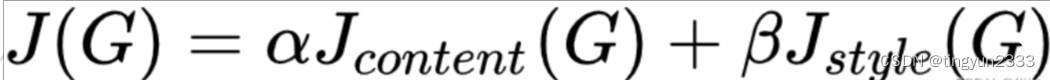
6.4.3 小结
样式迁移常用的损失函数由3部分组成:内容损失使合成图像与内容图像在内容特征上接近,样式损失令合成图像与样式图像在样式特征上接近,而总变差损失则有助于减少合成图像中的噪点。
可以通过预训练的卷积神经网络来抽取图像的特征,并通过最小化损失函数来不断更新合成图像。
用格拉姆矩阵表达样式层输出的样式。
6.5人脸识别

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









