






7 循环神经网络与NLP
7.1 数据处理基础
7.1.1 特征编码
使用199维特征向量表达一个人的特征

7.2 文本处理
7.2.1 文本切分

7.2.2 统计词频
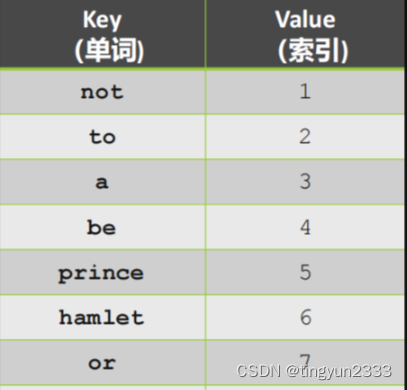
创建一个字典( 实际中经常使用 Hash 表 ) 进行词频统计(初始字典为空)

将词频索引化如果词汇太多,则只保留排序在前的k个单词 (如取𝑘 = 10000)
将每一个词映射到索引号上
7.3 文本预处理
一篇文章可以被简单地看作一串单词序列,甚至是一串字符序列。 我们将解析文本的常见预处理步骤。 这些步骤通常包括:
将文本作为字符串加载到内存中
将字符串切分为词元(如单词和字符)
建立一个字典,将拆分的词元映射到数字索引
将文本转换为数字索引序列,方便模型操作
读取数据集
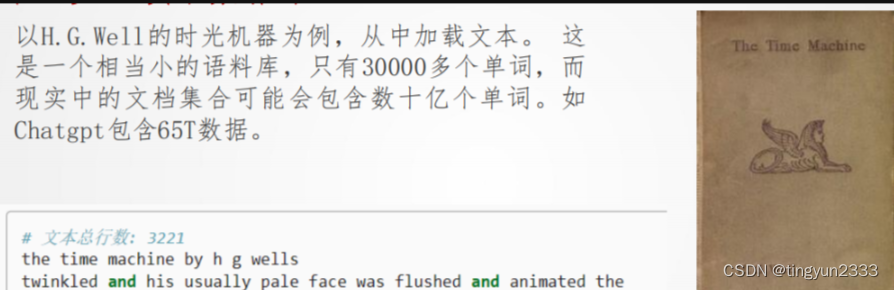
词汇切分
构建词索引表
打印前几个高频词及索引
[('<unk>', 0), ('the', 1), ('i', 2), ('and', 3), ('of', 4),
('a', 5), ('to', 6), ('was', 7), ('in', 8), ('that', 9)]
将每一条文本行转换成一个数字索引列表
文本: ['the', 'time', 'machine', 'by', 'h', 'g', 'wells']
索引: [1, 19, 50, 40, 2183, 2184, 400]
文 本 : ['twinkled', 'and', 'his', 'usually', 'pale', 'face',
'was', 'flushed', 'and', 'animated', 'the']
索引: [2186, 3, 25, 1044, 362, 113, 7, 1421, 3, 1045, 1]
7.4 文本嵌入
词嵌入(word embedding)
将独热向量映射为低维向量
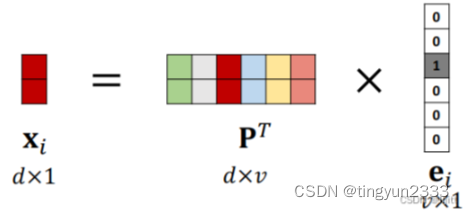
原始向量:𝑣维;映射后:𝑑维,𝑑 ≪ 𝑣;
映射矩阵: 𝑑 × 𝑣 , 根据训练数据学习得到
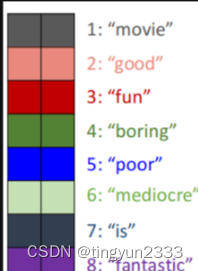
理解映射参数矩阵
7.5 RNN模型
7.5.1 RNN模型

7.5.2 RNN示例
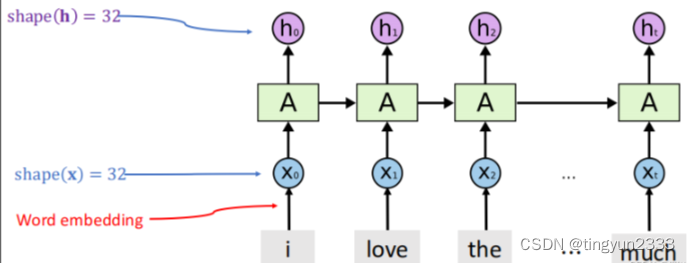
结果评价
• 训练精度: 89.2%
• 验证精度: 84.3%
• 测试精度: 84.4%
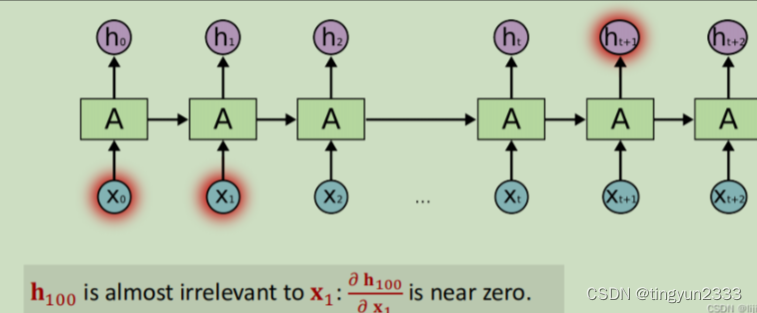
7.5.3 RNN问题
随着输入的增加,会产生“遗忘”问题
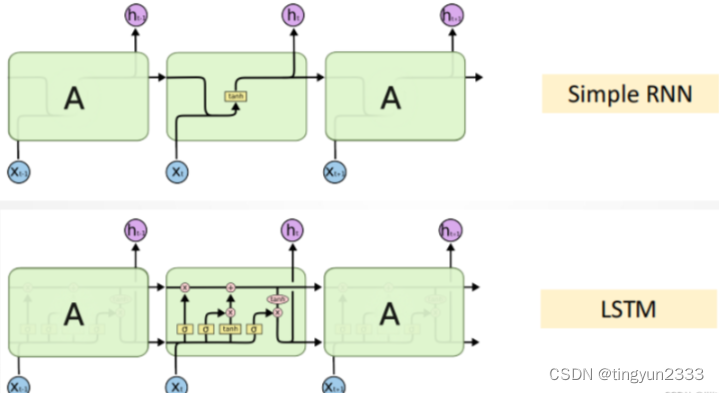
7.6 LSTM模型
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









