









懒虫锅~~~!!!!
原始数据:
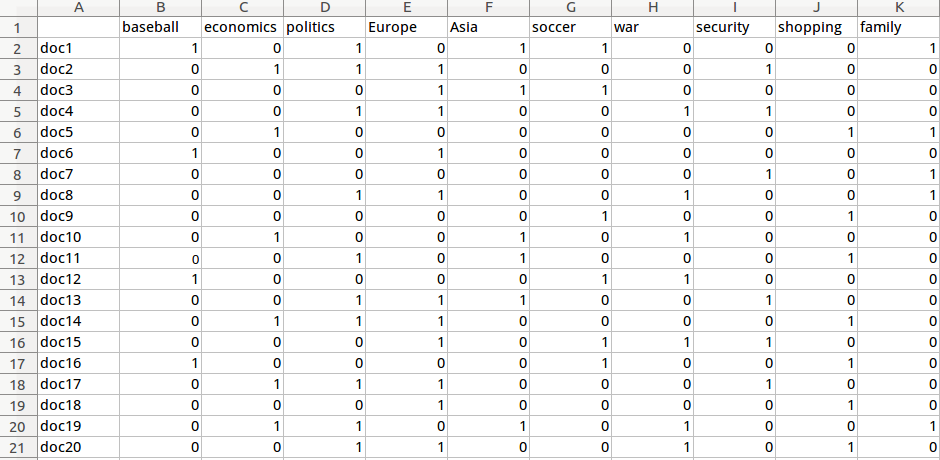
以及用户目前对doc的数据
#coding:utf-8
import csv
import operator
import math
csvfile=file("data1.csv",'rU')
reader=csv.reader(csvfile,dialect='excel')
doc={}
item=[]
for line in reader:
if reader.line_num==1:
for i in range(len(line)):
item.append(line[i])
else:
for i in range(len(item)):
if i==0:
doc.setdefault(line[0],{})
else:
doc[line[0]].setdefault(item[i],line[i])
csvfile.close()
csvfile=file('userdata.csv','rU')
reader=csv.reader(csvfile,dialect='excel')
User_Current={}
user=[]
for line in reader:
if reader.line_num==1:
for i in range(len(line)):
user.append(line[i])
else:
for i in range(len(line)):
if i>0:
User_Current.setdefault(user[i],{})
if line[i]=='':
line[i]="0"
User_Current[user[i]].setdefault(line[0],line[i])
#计算每个attibute的值DF
def calDF(doc):
result={}
for it in item:
if it != "":
result.setdefault(it,{})
s=0
for d in doc:
s=s+int(doc[d][it])
result[it]=s
return result
df=calDF(doc)
#计算每个doc有几个attribute
def numattr(doc):
result={}
for d in doc:
s=0
for i in doc[d]:
s=s+int(doc[d][i])
result.setdefault(d,s)
return result
totalcount=numattr(doc)
#计算userprofile
def UserProfiles(User_Current,doc):
result={}
for person in User_Current:
result.setdefault(person,{})
for i in item:
if i!="":
s=0.0
for d in User_Current[person]:
#这行缩进有点问题,第一个part和后两个part的userprofile计算不同
s=s+1.0/math.sqrt(int(totalcount[d]))*float(doc[d][i])*float(User_Current[person][d])
result[person].setdefault(i,s)
return result
userprofile=UserProfiles(User_Current,doc)
#计算dotproduct
def dotProduct(person,userprofile,doc):
result={}
for d in doc:
s=0
for i in doc[d]:
s=s+int(doc[d][i])*float(userprofile[person][i])
result.setdefault(d,s*1.0/math.sqrt(int(totalcount[d])))
return result
dotproducts=dotProduct('User 1',userprofile,doc)
#计算IDF下的dotproduct=profile*doc_vector*IDF
def IDF(person,userprofile,doc):
result={}
for d in doc:
s=0.0
for i in doc[d]:
s=s+int(doc[d][i])*float(userprofile[person][i])*1.0/int(df[i])
result.setdefault(d,s*1.0/math.sqrt(int(totalcount[d])))
return result
Idf=IDF('User 2',userprofile,doc)
def topn_dotProduct(dotproducts,n=5):
sorted_x=sorted(dotproducts.iteritems(),key=operator.itemgetter(1),reverse=True)
for i in range(n):
print sorted_x[i]
topn_dotProduct(Idf,20)问题一:
def UserProfiles(User_Current,doc):
result={}
for person in User_Current:
result.setdefault(person,{})
for i in item:
if i!="":
s=0.0
for d in User_Current[person]:
s=s+float(doc[d][i])*float(User_Current[person][d])
result[person].setdefault(i,s)
return result
userprofile=UserProfiles(User_Current,doc)
def dotProduct(person,userprofile,doc):
result={}
for d in doc:
s=0
for i in doc[d]:
s=s+int(doc[d][i])*float(userprofile[person][i])
result.setdefault(d,s)
return result
dotproducts=dotProduct('User 1',userprofile,doc)
def topn_dotProduct(dotproducts,n=5):
sorted_x=sorted(dotproducts.iteritems(),key=operator.itemgetter(1),reverse=True)
for i in range(n):
print sorted_x[i]
topn_dotProduct(dotproducts,20)问题二:
def UserProfiles(User_Current,doc):
result={}
for person in User_Current:
result.setdefault(person,{})
for i in item:
if i!="":
s=0.0
for d in User_Current[person]:
s=s+1.0/math.sqrt(int(totalcount[d]))*float(doc[d][i])*float(User_Current[person][d])
result[person].setdefault(i,s)
return result
userprofile=UserProfiles(User_Current,doc)
def dotProduct(person,userprofile,doc):
result={}
for d in doc:
s=0
for i in doc[d]:
s=s+int(doc[d][i])*float(userprofile[person][i])
result.setdefault(d,s*1.0/math.sqrt(int(totalcount[d])))
return result
dotproducts=dotProduct('User 1',userprofile,doc)
def topn_dotProduct(dotproducts,n=5):
sorted_x=sorted(dotproducts.iteritems(),key=operator.itemgetter(1),reverse=True)
for i in range(n):
print sorted_x[i]
topn_dotProduct(dotproducts,20)~~~~
遇到的一些问题
直接将表格存为.csv文件,运行python时候会报错
_csv.Error: line contains NULL byte
保存形式应该是另存为.csv
python字典排序问题
#-*- encoding=utf-8 -*-
import operator
#按字典值排序(默认为升序)
x = {1:2, 3:4, 4:3, 2:1, 0:0}
sorted_x = sorted(x.iteritems(), key=operator.itemgetter(1))
print sorted_x
#[(0, 0), (2, 1), (1, 2), (4, 3), (3, 4)]
#如果要降序排序,可以指定reverse=True
sorted_x = sorted(x.iteritems(), key=operator.itemgetter(1), reverse=True)
print sorted_x
#[(3, 4), (4, 3), (1, 2), (2, 1), (0, 0)]
#或者直接使用list的reverse方法将sorted_x顺序反转
#sorted_x.reverse()
#取代方法是,用lambda表达式
sorted_x = sorted(x.iteritems(), key=lambda x : x[1])
print sorted_x
#[(0, 0), (2, 1), (1, 2), (4, 3), (3, 4)]
sorted_x = sorted(x.iteritems(), key=lambda x : x[1], reverse=True)
print sorted_x
#[(3, 4), (4, 3), (1, 2), (2, 1), (0, 0)]
#包含字典dict的列表list的排序方法与dict的排序类似,如下:
x = [{'name':'Homer', 'age':39}, {'name':'Bart', 'age':10}]
sorted_x = sorted(x, key=operator.itemgetter('name'))
print sorted_x
#[{'age': 10, 'name': 'Bart'}, {'age': 39, 'name': 'Homer'}]
sorted_x = sorted(x, key=operator.itemgetter('name'), reverse=True)
print sorted_x
#[{'age': 39, 'name': 'Homer'}, {'age': 10, 'name': 'Bart'}]
sorted_x = sorted(x, key=lambda x : x['name'])
print sorted_x
#[{'age': 10, 'name': 'Bart'}, {'age': 39, 'name': 'Homer'}]
sorted_x = sorted(x, key=lambda x : x['name'], reverse=True)
print sorted_x
#[{'age': 39, 'name': 'Homer'}, {'age': 10, 'name': 'Bart'}] 














 1322
1322

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









