







2025年(第13届)“泰迪杯”数据挖掘挑战赛将于3月1日开放报名。“泰迪杯”数据挖掘挑战赛始创于2013年,迄今已经连续举办了13年。累计参赛高校千余所,累计参赛人数逾10万人,全国各省份均有参加。大赛的开展始终秉持推动校企合作,产教融合的理念,为高校师生及相关企业搭建交流合作的桥梁。
2024年4月15日召开的第61届中国高等教育博览会上,全国高校计算机教育研究会、教师教学发展研究国家级虚拟教研室和研究报告专家工作组共同发布了《全国普通高校大学生计算机类竞赛研究报告》(下简称《研究报告》),“泰迪杯”数据挖掘挑战赛依旧位列其中。

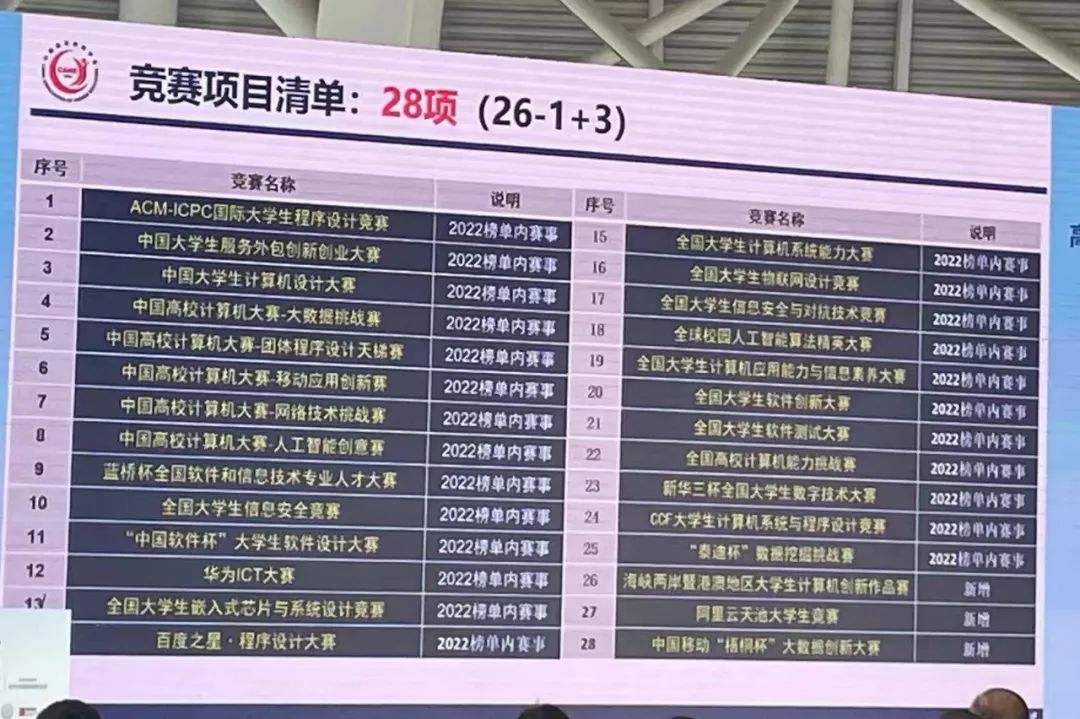
自2022年起,“泰迪杯”数据挖掘挑战赛便在《全国普通高校大学生计算机类竞赛指数》中占有一席之地,赛题设计紧密结合实际,主要是来源于企业、管理机构和科研院所等的实际问题,有较大的灵活性供参赛者发挥其创造能力。
“泰迪杯”数据挖掘挑战赛的举办旨在促进参赛者的技术技能、创新思维、实践能力培养,激励参赛者学习数据挖掘的积极性,提高参赛者的分析、解决实际问题的综合能力;推动数据挖掘技术在高校的推广和应用的同时,也助力高校培养出更多的创新型、复合型、应用型人才。
竞赛组织
主办单位:
广东泰迪智能科技股份有限公司
泰迪杯数据挖掘挑战赛组织委员会
协办单位:
重庆市工业与应用数学学会
广东省工业与应用数学学会
广西数学学会
河北省工业与应用数学学会
湖北省工业与应用数学学会
江苏省运筹学会
四川省现场统计学会
浙江省应用数学研究会
河南省运筹学会
支持单位:
人民邮电出版社
网宿科技股份有限公司
北京泰迪云智信息技术研究院
25年竞赛时间安排:
报名起讫时间:2025年3月1日—4月11日
开题时间:2025年3月1日 10:00:00(公布赛题和示例数据)
竞赛时间:2025年4月12日—4月25日(4月11日9:00:00 公布全部数据)
提交选题截止时间:2025年4月17日(16:00之前)
提交作品截止时间:2025年4月26日(16:00之前)
提交测试结果时间(公布测试数据,提交测试结果):2025年4月26日9:00—21:00
视频答辩时间:2025年5月30日或31日(具体时间后续单独通知)
成绩公示时间:2025年6月3—5日
成绩公布时间:2025年6月6日
颁奖及赛题讲解时间:2025年7月(具体时间待定)
竞赛奖励
-
特等奖并获泰迪杯:3队,每队20000元奖金(需扣除个人所得税)。
-
特等奖:3队,每队10000元奖金(需扣除个人所得税)。
-
网宿创新奖:3队,每队2000元奖金(需扣除个人所得税)。
-
一等奖:不超过2%。
-
二等奖:约5%。
-
三等奖:约10%。
*各省根据实际情况可设置省级奖项,分别设置一等奖、二等奖、三等奖,由各省级学会联合广东泰迪智能科技股份有限公司颁发获奖证书。
竞赛说明
-
挑战赛设赛题三道,参赛者任选其中一道参赛即可。
-
在校的研究生、本科生、专科生都可以“队”为单位参赛,每队不超过3人(须属于同一所学校),专业不限,并将使用相同的题目。每队可设一名指导教师,从事赛前辅导和参赛的组织工作。
-
研究生组、本科组与专科组分开三个组别评奖,以队伍内学历层次最高队员认定组别。
-
挑战赛收取报名费200元/队,同时接受社会各界的资助,由广东泰迪智能科技股份有限公司处理收费,并在报名结束后处理开具发票(电子发票)和支付奖金等事宜。
-
广东泰迪智能科技股份有限公司提供包括网站、赛前指导、技术讨论群等相关资源。挑战赛不限制参赛工具及平台的使用,参赛者可以使用如Python、R语言、MATLAB等任意一门编程语言或市面上主流数据科学相关工具。

















 839
839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









