







今天在调试 Intel Edison 上搜索 Wi-Fi 功能时,遇到一个问题,当搜索到的 Wi-Fi 名称带有中文时,代码中获取到的字符串是十六进制字节码的形式,如 \x91\xb8 这样的。但当我进入断点查看时,看到的结果是像这样: \\xe5\\xb0\\x8f\\xe7\\xb1\\xb3\\xe6\\x89\\x8b\\xe6\\x9c\\xba。很明显这是 \ 字符被转义了。我尝试直接通过 decode 方法转换编码,但是不行;直接 print 出来倒是可以得到正常的十六进制字节码的形式,但这不是我想要的;然后又尝试使用 replace 方法替换掉 \\,事实证明这个思路就是错误的,所有尝试方法的结果如图:
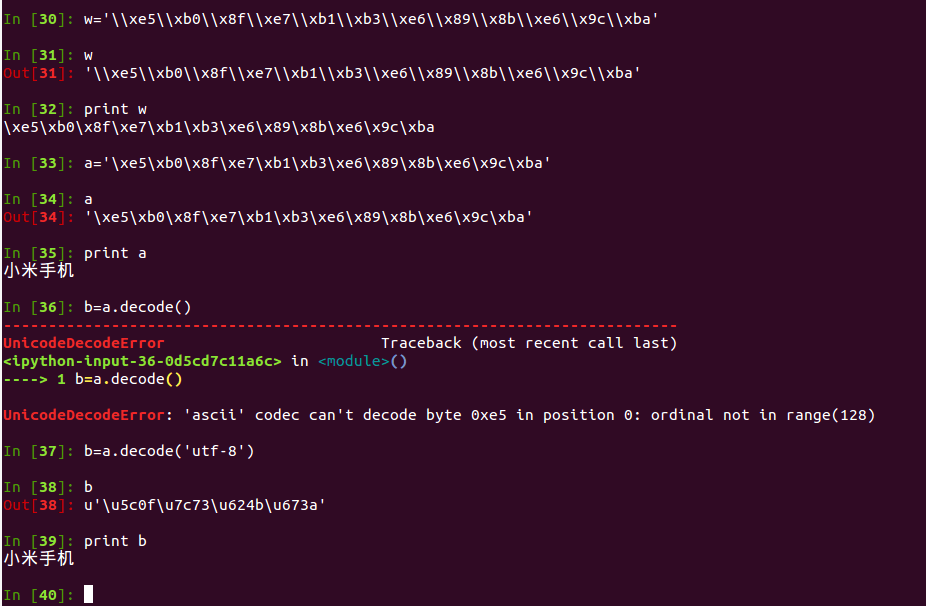
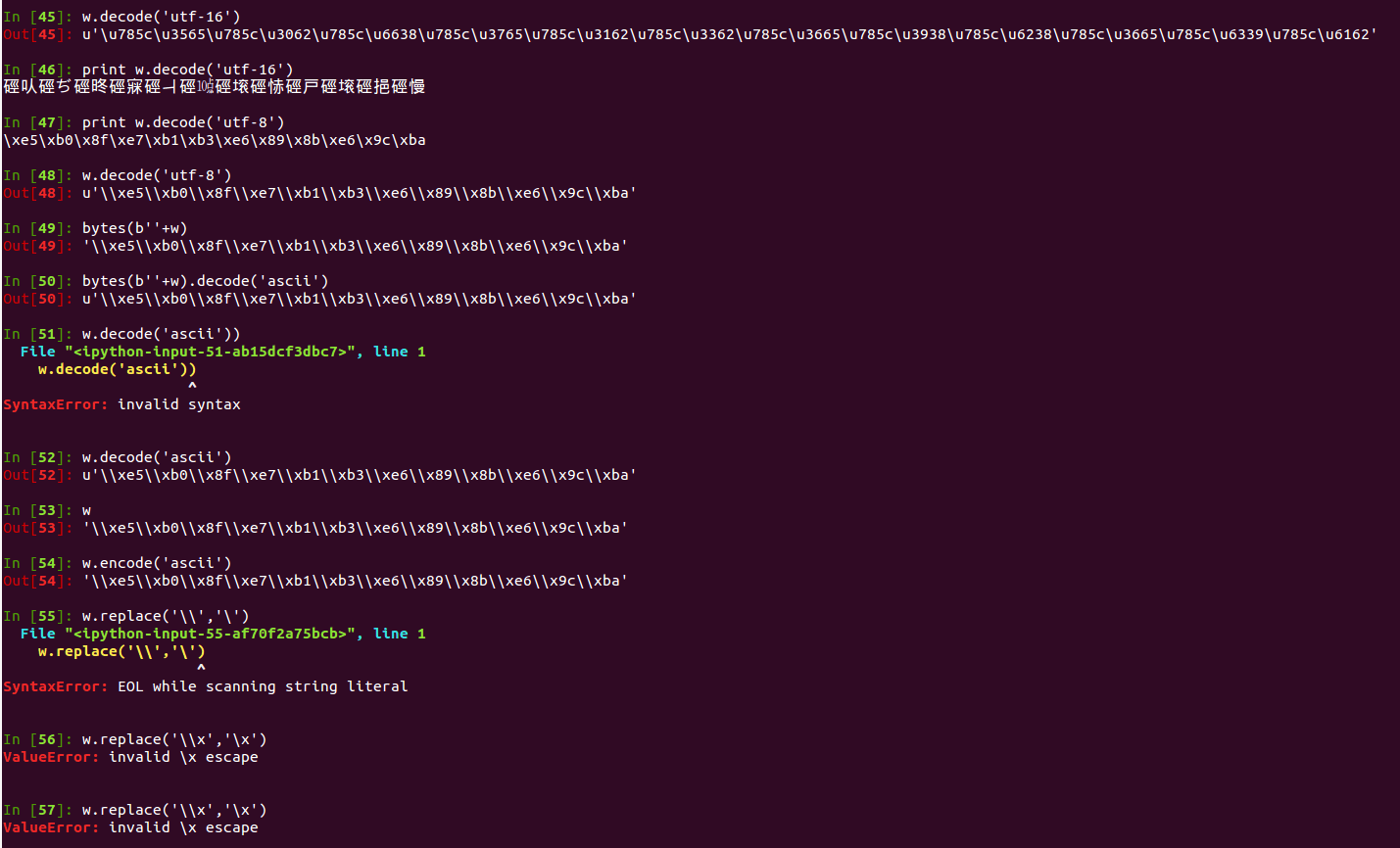
困惑了很久,最终求教于高手,高手点拨后,问题得以解决,原来是可以直接使用 decode 方法的,只是传入的编码参数需要指定为 string-escape,才能正常转码,如图:
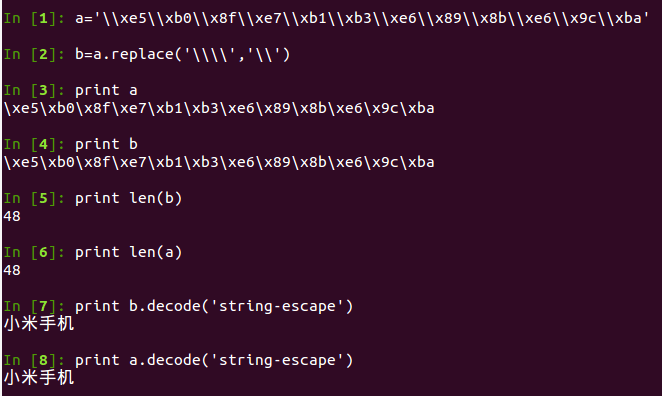
解决问题之后,经过总结,发现我在这次调试过程中暴露了三大问题:
- 不应该直接将
\\xe5\\xb0\\x8f\\xe7\\xb1\\xb3\\xe6\\x89\\x8b\\xe6\\x9c\\xba复制到交互环境里测试,因为此时复制进去的内容,不是,或者说不能确保是内存中的正确形式。要调试这样的编码问题,一般来说应该将内容保存进一个文本文件,写最小应用进行调试。 - 基础知识不足,看的书太少,没有真正理解数据在计算机中的表示形式,导致闷头乱撞,浪费时间。
- 思考问题时局限性太大,思路放不开,钻进牛角尖出不来。在事实证明当前道路走不通的情况下应该及时转变思考方向,避免浪费时间。
最终深刻体会了一个已经看过很多遍的道理:不懂不可怕,可怕的是压根不知道。
多看书,多学习,多思考,多总结。















 446
446











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









