







论文《GA-Net: Guided Aggregation Net for End-to-end Stereo Matching》的完整翻译,如有不当之处,敬请评论指出,蟹蟹!(时间:2019-06-11)
发表:CVPR2019
作者:Feihu Zhang1∗ Victor Prisacariu1 Ruigang Yang2 Philip H.S. Torr1
1 University of Oxford 2 Baidu Research, Baidu Inc.
代码:https://github.com/feihuzhang/GANet
摘要
在立体匹配任务中,匹配代价聚合在传统方法和深度神经网络模型中都起着至关重要的作用,以准确估计视差。我们提出了两种新的神经网络层,分别用于捕获局部和整个图像的成本依赖性。第一种是半全局聚合层,它是半全局匹配的可微近似;第二种是局部引导聚合层,它遵循传统的成本过滤策略来精炼细结构。
这两个层可用于代替广泛使用的3D卷积层,由于其具有立方计算/存储器复杂性,因此计算成本高并且消耗存储器。 在实验中,我们表明,具有双层引导聚合块的网络容易胜过具有19个3D卷积层的最先进的GC-Net。 我们还训练深度引导聚合网络(GA-Net),它比场景流数据集和KITTI基准测试中的最先进方法具有更好的准确性。代码将在https://github.com/feihuzhang/GANet上提供。
1.介绍
立体重建是计算机视觉,机器人和自动驾驶的主要研究课题。 其目的是通过计算立体图像对中的匹配像素之间的视差来估计3D几何。 由于各种现实问题,例如遮挡,大的无纹理区域(例如天空,墙壁等),反射表面(例如窗户),薄结构和重复纹理,这是具有挑战性的。
传统上,立体重建被分解为三个重要步骤:特征提取(用于匹配代价计算),匹配代价聚合和视差预测[9,21]。 基于特征的匹配通常是模糊的,由于遮挡,平滑,反射,噪声等,错误匹配的代价低于正确的匹配。因此,代价聚合是在具有挑战性的区域中获得准确的视差估计所需的关键步骤。
深度神经网络已被用于匹配例如[30,33]中的代价计算,以及(i)基于传统方法的代价聚合,例如成本过滤[10]和半全局匹配(SGM)[9]和(ii)通过单独步骤的视差计算。这种方法相对于传统的像素匹配显着改进,但仍然难以在无纹理,反射和遮挡区域中产生精确的视差。将匹配与视差估计联系起来的端到端方法在例如DispNet [15],直到GC-Net [13]才通过使用3D卷积将代价聚合纳入训练管道。 [3]最近的工作PSMNet,通过实施堆叠沙漏主干[17]进一步提高了准确性,并大大增加了3D卷积层的数量,以进行成本聚合。通过频繁下采样和上采样减少了使用3D卷积所产生的大内存和计算成本,但这导致视差图中的精度损失。
在这些方法中,传统的半全局匹配(SGM)[9]和代价过滤[10]都是强大而有效的代价聚合方法,已广泛应用于许多工业产品中。 但是,它们不是可区分的,不能以端到端的方式轻松训练。
在这项工作中,我们提出了两个新的代价聚合层,用于端到端立体重建,以取代3D卷积的使用。 我们的解决方案可显着提高准确性,同时降低内存和计算成本。
首先,我们引入了一个半全局引导聚合层(SGA),它实现了半全局匹配(SGM)的可微近似[9],并在整个图像上聚合不同方向的匹配代价。 这使得能够在遮挡区域或大的无纹理/反射区域中进行精确估计。
其次,我们引入局部引导聚合层(LGA)来处理薄结构和对象边缘,以便恢复由下采样和上采样层引起的细节损失。
如图1所示,仅具有两个GA层和两个3D卷积层的代价聚合块容易胜过最先进的GC-Net [13],其具有十九个3D卷积层。 更重要的是,就FLOP(浮点运算)而言,一个GA层在3D卷积方面的计算复杂度仅为1/100。 这使我们能够构建一个实时GA-Net模型,与其他现有的实时算法相比,它可以实现更高的精度,并以15~20 fps的速度运行。

图1:性能插图。 (a)具有挑战性的输入图像。 (b)最先进的方法GC-Net [13]的结果,其具有19个用于匹配代价聚合的3D卷积层。 (c)GA-Net-2的结果,它仅使用两个提出的GA层和两个3D卷积层。 它将匹配信息聚合到大的无纹理区域,并且比GC Net快一个数量级。 (d)GT。
我们通过改进用于特征提取和匹配代价聚合的网络架构来进一步提高准确性。 完整的模型,我们称之为“GA-Net”,在场景流数据集[15]和KITTI基准[7,16]上实现了最先进的精度。
2.相关工作
基于特征的匹配代价通常是模糊的,因为由于遮挡,平滑,反射,噪声等错误匹配可以容易地比正确匹配代价更低。为了解决这个问题,已经开发了许多代价聚合方法来改进代价量和 实现更好的估计。 本节简要介绍了深度神经网络在立体重建中应用的相关工作,重点是现有的匹配代价聚合策略,并简要回顾了传统局部和半全局代价聚合的方法。
2.1. 用于立体匹配的深度神经网络
深度神经网络被用于计算[4,6,29,33]中的块相似度得分,传统的代价聚合和视差计算/细化方法[9,10]用于获得最终的视差图。 这些方法实现了最先进的精度,但是受传统匹配代价聚合步骤的限制,经常在遮挡区域,大的无纹理/反射区域和物体边缘周围产生错误的预测。 一些其他方法希望改善传统代价聚合的性能,例如, SGM-Nets [23]使用神经网络预测SGM [9]的惩罚参数,而Schonberger等人。 [22]学会了通过立体匹配中的优化来融合提议并且Yang等人。 建议使用最小生成树来汇总代价[28]。
最近,端到端深度神经网络模型已经变得流行。 梅耶等人。 创建了一个大的合成数据集来训练用于视差估计的端到端深度神经网络(例如DispNet)[15]。 庞等人。 [19]建立了一个两阶段卷积神经网络来首先估计然后改进视差图。 Tulyakov等人。 提出了用于实际应用的端到端深立体模型[26]。 GCNet [13]将特征提取,代价聚合和视差估计与单个端到端深度神经模型相结合,以在几个基准测试中获得最先进的精度。 PSMNet [3]使用金字塔特征提取和堆叠沙漏块[18],具有二十五个3D卷积层,以进一步提高准确性。
2.2. 代价聚合
传统的立体匹配算法[1,9,27]增加了一个额外的约束,通过惩罚相邻差异的变化来强制平滑。 这可以是局部的和(半)全局的,如下所述。
2.2.1 局部代价聚合
代价量C由每个候选视差值d的每个像素位置处的匹配代价形成。它的大小为H×W×Dmax(H:图像高度,W:图像宽度,Dmax:视差的最大值),并且可以针对每个候选视差d切成Dmax切片。有效的代价聚合方法是局部代价过滤框架[10,31],其中代价体积C(d)的每个切片由引导图像过滤器[8,25,31]独立地过滤。在视差d处对像素位置p =(x,y)的滤波是在相同切片C(d)中的所有邻域q∈Np的加权平均:
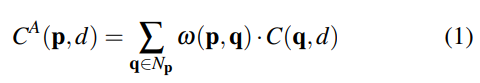
其中C(q,d)表示候选视差d的位置p处的匹配代价。C^A(p,d)表示聚合的匹配代价。可以使用不同的图像滤波器[8,25,31]来产生被引导的滤波器权重ω。由于这些方法仅汇总了局部区域Np的代价,因此它们可以快速运行并达到实时性能。
2.2.2 半全局匹配
当执行(半)全局聚合时,匹配代价和平滑约束被公式化为一个能量函数E(D)[9],输入图像的视差图为D。立体匹配的问题现在可以表述为找到最小化能量E(D)的最佳视差图D *:
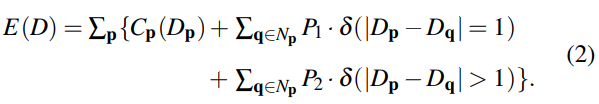
第一项ΣpCp(Dp)是视差图D的所有像素位置p处的匹配代价之和。如果在视差图D中具有小的视差不连续性(| Dp -Dq | = 1),则第二项是对于p附近的位置q的常数惩罚P1。对于所有较大的视差变化(| Dp -Dq |> 1),最后一项增加了较大的常数惩罚P2。
Hirschmuller建议从16个方向汇总1D的匹配代价,得到O(KN)时间复杂度的近似解,这就是众所周知的半全局匹配(SGM)[9]。视差d处的位置p的代价Cr ^ A(p,d)沿着方向r上的整个图像上的路径聚合,并且递归地定义为: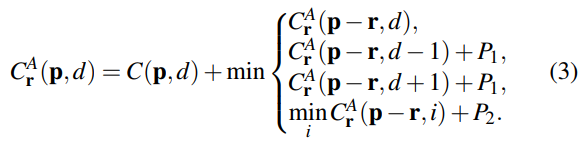
其中r是单位方向向量。 在MC-CNN中使用相同的聚合步骤[23,30],并且在[1,2,14]中采用类似的迭代步骤。
在下一节中,我们将详细介绍更高效的引导聚合(GA)策略,其中包括半全局聚合(SGA)层和局部引导聚合(LGA)层。 两个GA层都可以在端到端模型中通过反向传播来实现,以取代低效的3D卷积并获得更高的精度。
3. 引导聚合网络
在本节中,我们描述了我们提出的引导聚合网络(GA-Net),包括引导聚合(GA)层和改进的网络架构。
3.1 引导聚合层
最先进的端到端立体匹配神经网络[3,13]构建了4D匹配代价量(大小为H×W×Dmax×F,H:高度,W:宽度,Dmax :最大视差,F:特征尺寸)通过连接立体视图之间的特征,以不同的视差值计算。接下来通过代价聚合阶段对其进行细化,最后用于视差估计。 与这些方法不同,受半全局和局部匹配代价聚合方法的启发[9,10],我们提出了半全局引导聚合(SGA)和局部引导聚合(LGA)层,如下所述。
3.1.1 半全局聚合
传统的SGM [9]在不同的方向上迭代地聚合匹配代价(等式(3))。 在端到端可训练的深度神经网络模型中使用这种方法存在一些困难。
首先,SGM有许多用户定义的参数(P1,P2),这些参数不易调整。 所有这些参数在神经网络训练期间成为不稳定因素。 其次,SGM中的代价聚合和惩罚对于所有像素,区域和图像是固定的,而不适应不同的条件。 第三,硬最小选择导致深度估计中的许多前平行表面。
我们设计了一个支持反向传播的新的半全局代价聚合步骤。 这比传统的SGM更有效,并且可以在深度神经网络模型中重复使用以提高代价聚合效果。 建议的聚合步骤是:
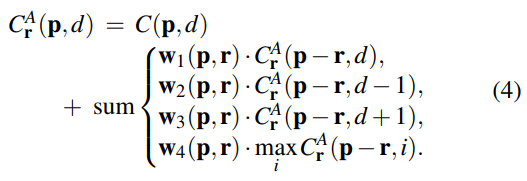
这与SGM有三种不同。 首先,我们使用户定义的参数可学习,并将它们添加为匹配代价项的惩罚系数/权重。因此,对于不同的情况,这些权重在不同位置是自适应的并且更灵活。我们用加权和替换等式 (3) 中的第一个/外部最小选择,没有任何精度损失。这种变化在[24]中被证明是有效的,其中使用具有步幅的卷积来代替最大池化层以获得所有卷积网络而不损失准确性。第三,内部/第二最小选择被改变为最大值。这是因为我们模型中的学习目标是最大化 gt 深度的概率,而不是最小化匹配代价。由于方程(4)中的最大Cr ^ A(p-r,i)可以由Cr ^ A(p,d)共享d个不同的位置,这里,我们不使用另一个加权求和来替换它以便减少 计算复杂性。
对于方程(3)和方程(4),Cr ^ A(p,d)的值沿路径增加,这可能导致非常大的值。 我们将权重标准化以避免这样的问题。 这导致了我们新的半全局聚合:

C(p,d)被称为代价体积(尺寸为H×W×Dmax×F)。与传统的SGM [9]相同,可以针对每个候选视差d将代价量切成第三维的Dmax切片,并且这些切片中的每一个重复等式1的聚合操作。 (5)使用共享权重矩阵(w0 … 4)。所有权重w0 … 4都可以通过引导子网络实现(如图2所示)。与在16个方向上聚合的原始SGM不同,为了提高效率,所提出的聚合在整个图像上沿着每行或每列的四个方向(左,右,上和下)完成,即r∈{ (0,1),(0,-1),(1,0)( - 1,0)}。

图2:(a)架构概述。 左图像和右图像被馈送到权重共享特征提取管道。 它由堆叠的沙漏CNN组成,并通过连接连接。 然后,使用所提取的左图像特征和右图像特征来形成4D代价量,将其馈送到代价聚合块中以进行正则化,细化和视差回归。 引导子网络(绿色)生成引导代价聚合(SGA和LGA)的权重矩阵。 (b)SGA层半全局地汇总四个方向的代价量。 (c)在视差回归之前使用LGA层并多次局部细化4D代价量。
通过选择四个方向之间的最大值来获得最终的聚合输出C ^ A(p):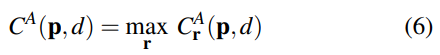
最后一次最大选择仅从一个方向保留最佳消息。 这保证了聚合效果不会被其他方向模糊。 SGA层中w和C(p,d)的反向传播可以与方程(5)相反地进行(细节可在附录A中获得)。 我们的SGA层可以在神经网络模型中重复几次,以获得更好的代价聚合效果(如图2所示)。
3.1.2 局部聚合
我们现在介绍局部引导聚合(LGA)层,旨在细化薄结构和对象边缘。 下采样和上采样广泛用于立体匹配模型,其模糊薄结构和物体边缘。 LGA层学习了几个引导过滤器,以优化匹配代价并帮助恢复薄结构信息。 局部聚合遵循代价过滤器定义[10](等式(1)),可以写成:
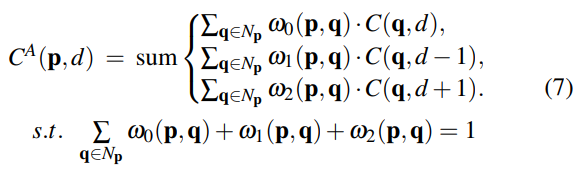
代价量的不同切片(总共Dmax个切片)在LGA中共享相同的过滤/聚合权重。 这与本文中的原始代价过滤框架[10]和SGA(公式(5))相同。然而,与使用K×K滤波器内核来过滤K×K局部/邻近区域Np中的代价体积的传统代价滤波器[10]不同,所提出的LGA层具有三个K×K滤波器(ω0,ω1和 ω2)在每个像素位置p处分别为视差d,d-1和d + 1。即,对于每个像素位置p,它在K×K局部区域中与K×K×3权重矩阵聚合。 权重矩阵的设置也类似于[11],但是,在[10]中设计的聚合期间共享权重和过滤器。
3.1.3 有效实现
我们使用几个2D卷积层来构建快速引导子网络(如图2所示)。 实现类似于[32]。 它使用参考图像作为输入并输出聚合权重w(公式(5))。对于尺寸为H×W×D×F(H:高度,W:宽度,D:最大视差,F:特征尺寸)的4D代价体积C,引导子网络的输出被分割,重新整形并归一化为四 个使用等式(5)的四个方向聚合的H×W×K×F(K = 5)权重矩阵。 注意,对应于切片d的不同视差的聚合共享相同的聚合权重。 类似地,LGA层需要学习H×W×3K^2×F(K = 5)权重矩阵并使用等式(7)进行聚合。
即使SGA层涉及跨宽度或高度的迭代聚合,由于不同特征通道或行/列中的元素之间的独立性,可以并行计算前向和后向。 例如,当在左方向聚合时,不同通道或行中的元素是独立的并且可以同时计算。 LGA层的元素也可以通过简单地将其分解为逐元素的矩阵乘法和求和来并行计算。 为了增加LGA层的感受野,我们用相同的权重矩阵重复计算等式(7)两次,这与[5]类似。
3.2 网络架构
如图2所示,GA-Net由四部分组成:特征提取块,4D代价量的代价聚合,产生代价聚合权重的指导子网络和视差回归。对于特征提取,我们使用堆叠沙漏网络,通过不同层之间的连接密集连接。左视图和右视图共享特征提取块。然后,使用用于左图像和右图像的提取的特征来形成4D代价量。几个SGA层用于代价聚合,并且LGA层可以在视差回归的softmax层之前和之后实现。它改进了薄结构并补偿了由代价量下采样引起的精度损失。权重矩阵(在等式(5)和等式(7)中)由额外的引导子网络生成,该子网络使用参考视图(例如左图像)作为输入。引导子网络由几个快速2D卷积层组成,输出被重新整形并归一化为这些GA层所需的权重矩阵。
3.3 损失函数
我们采用平滑的L1损失函数来训练我们的模型。 与L2损失相比,平滑L1在视差不连续处是鲁棒的并且对异常值或噪声具有低灵敏度。 训练模型的损失函数定义为:
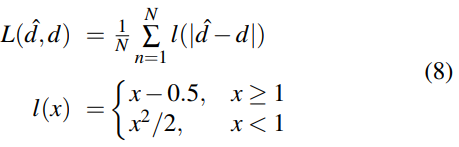
其中,| d*- d | 测量视差预测的绝对误差,N是具有训练 gt 的有效像素的数量。
对于视差估计,我们采用[13]中提出的视差回归:
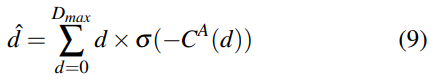
视差预测d是通过其概率加权的每个视差候选者的总和。 通过softmax操作σ(·)在代价聚合之后计算每个视差d的概率。 显示视差回归比基于分类的方法更鲁棒并且可以生成亚像素精度。
4. 实验
在本节中,我们使用Scene Flow [15]和KITTI [7,16]数据集评估具有不同设置的GA-Nets。 我们使用pytorch或caffe [12]实现我们的架构(仅用于实时模型的实现)。 所有模型都使用Adam进行优化(β1= 0.9,β2= 0.999)。 我们使用来自输入图像的240×576随机裁剪在八个GPU上以16的批量训练。 视差的最大值设置为192.在训练之前,我们通过减去它们的平均值并除以它们的标准偏差来标准化图像的每个通道。 我们在场景流数据集上训练模型10个周期,学习率恒定为0.001。 对于KITTI数据集,我们将对场景流数据集上预训练的模型进行微调,以进一步调整640个周期。 微调的学习率从前300个周期的0.001开始到剩余的周期减少到0.0001。
4.1 消融研究
我们使用不同的设置评估GA-Nets的性能,包括不同的体系结构和不同的GA层数(0-4)。 如表1中所列,引导聚合模型明显优于仅具有用于代价聚合的3D卷积层的基线设置。 用于特征提取和代价聚合的新架构在KITTI数据集上提高了0.14%,在场景流数据集上提高了0.9%。 最后,具有三个SGA层和一个LGA层的GA-Net的最佳设置在KITTI 2015验证集上获得了2.71%的最佳3像素阈值错误率。 它还在场景流测试装置上实现了0.84像素的最佳平均EPE和9.9%的最佳1像素阈值误差率。

表1:具有不同设置的GA-Nets的评估。 平均端点误差(EPE)和阈值误差率用于评估。
4.2 引导聚合的效果
在本节中,我们将引导聚合策略与其他匹配代价聚合方法进行比较。 我们还通过观察不同模型输出的post-softmax概率来分析GA层的影响。
首先,我们提出的GA-Nets与GC-Net(具有19个3D卷积)和PSMNet(具有25个3D卷积)中的代价聚合架构进行比较。 我们修改了上面提出的特征提取架构。 如表2所示,GA-Nets具有较少的参数,以更快的速度运行并获得更好的准确性。 例如,只有两个GA层和两个3D卷积,我们的GA-Net-2的平均EPE优于GC-Net 0.29像素。 此外,具有三个GA层和七个3D卷积的GA-Net-7优于目前最好的PSMNet [3],其具有二十五个3D卷积层。

表2:不同代价聚合方法的比较。 平均端点误差(EPE)和1像素阈值误差率用于场景流数据集的评估。
我们还通过与没有GA步骤的相同架构进行比较来研究GA层的影响。 这些基线模型“GA Nets *”具有相同的网络架构和所有其他设置,除了没有实现GA层。 如图3所示,对于所有这些模型,GA层显着提高了模型的准确度(平均EPE为0.5-1.0像素)。 例如,与使用11个3D卷积的GA-Net *-11(1.54)相比,具有两个3D卷积和两个GA层的GA Net2产生较低的EPE(1.51)。 这意味着两个GA层比九个3D卷积层更有效。

图3:引导聚合效果的图示。 将GANets与没有GA层的相同架构进行比较。 使用平均EPE对场景流数据集进行评估。
最后,为了观察和分析GA层的影响,在图4中,我们绘制了关于候选视差范围的post-softmax概率。 这些概率直接用于使用等式1的视差估计。 (9)并且可以反映代价聚合策略的有效性。 数据样本全部选自一些具有挑战性的区域,例如大的无纹理区域(天空),反射区域(汽车的窗口)和物体边缘周围的像素。 比较了三种不同的模型。 第一个模型(图4的第一行)仅具有3D卷积(没有任何GA层),第二个模型(图4的第二行)具有SGA层,而最后一个模型(图4的最后一行)具有两个 SGA层和LGA层。

图4:关于视差值的post-softmax概率分布。 红线说明了GT的视差。 样本选自三个具有挑战性的区域:(a)大平滑区域(天空),(b)来自一个车窗的反射区域和(c)物体边缘周围的一个区域。 第一行显示没有GA层的概率分布。 第二行显示半全局聚合(SGA)层的效果,最后一行显示具有一个额外局部引导聚合(LGA)层的细化概率。
如图4(a)所示,对于大的无纹理区域,会有很多噪声,因为在这些区域中没有任何明显的特征用于正确匹配。 SGA层通过聚合周围的匹配信息成功地抑制概率中的这些噪声。 LGA层进一步将概率峰值集中在GT值上。它可以优化匹配结果。类似地,在反射区域的样本中(图4(b)),SGA和LGA层纠正了错误的匹配并将峰值集中在正确的视差值上。对于物体边缘周围的样本(图4(c)),概率分布中通常有两个峰值分别受背景和前景的影响。 SGA和LGA使用空间聚合以及适当的最大选择来减少来自背景的错误匹配信息的聚合,并因此抑制出现在背景的视差值处的错误概率峰值。
4.3 与SGM和3D Convolutions的比较
SGA层是SGM的可微近似[9]。 但是,与具有手工制作功能的原始SGM和具有CNN功能的MC-CNN [30]相比,它产生了更好的结果(如表5所示)。 这是因为1)SGA没有任何用户定义的参数,这些参数都是以端到端的方式学习的。 2)SGA的聚合由权重矩阵完全引导和控制。 指导子网络学习有效的几何和上下文知识,以控制代价聚合的方向,范围和优势。
此外,与原始SGM相比,避免了大的无纹理区域中的大多数平行近似。 (例子如图5所示。)这可能受益于:1)在方程(5)中使用软加权和(而不是方程(3)中的硬最小/最大选择); 2)方程(9)的回归损失有助于实现亚像素精度。
我们的SGA层也比3D卷积层更有效。 这是因为3D卷积层只能在受内核大小限制的局部区域中聚合。 因此,为了获得良好的结果,一系列3D卷积以及编码器和解码器架构是必不可少的。 作为比较,我们的SGA层在单个层中进行半全局聚合,这更有效。 SGA的另一个优点是聚合的方向,范围和强度完全由可变权重根据不同位置的不同几何和上下文信息引导。 例如,SGA在遮挡和大平滑区域中表现完全不同。 但是,3D卷积层具有固定的权重,并且总是对整个图像中的所有位置执行相同的操作。
4.4 复杂性和实时模型
一个3D卷积层的计算复杂度为O(K ^ 3CN),其中N是输出blob的元素编号。 K是卷积核的大小,C是输入blob的通道号。 作为比较,SGA的复杂度是O(4KN)或O(8KN),用于四方向或八方向聚合。 在GC-Net [13]和PSMNet [3]中,K = 3,C = 32,64或128,在我们的GA-Nets中,K用作5(对于SGA层)。 因此,所提出的SGA步骤的浮点运算(FLOP)方面的计算复杂度小于一个3D卷积层的1/100。
SGA层比3D卷积更快,更有效。 这使我们能够建立一个准确的实时模型。 我们实现了GA-Net-1的一个caffe [12]版本(只有一个3D卷积层,没有LGA层)。 通过对代价量使用4×下采样和上采样,进一步简化了模型。 对于TESLA P40 GPU上的300×1000图像,实时模型可以以15〜20 fps的速度运行。 我们还将结果的准确性与最先进的实时模型进行了比较。 如表3所示,实时GA-Net远远优于其他现有的实时立体匹配模型。
4.5 对基准的评估
对于基准评估,我们使用GA-Net-15进行评估的完整设置。 我们将GA-Net与场景流数据集和KITTI基准测试中最先进的深度神经网络模型进行比较。
4.5.1 场景流数据集
场景流合成数据集[15]包含35,454次训练和4,370次测试图像。 我们使用“最终”集进行训练和测试。 通过评估测试集上的平均端点误差(EPE)和1像素阈值误差率,将GA-Nets与其他最先进的DNN模型进行比较。 结果显示在表2中。我们发现我们的GA-Net在两个评估指标上都优于现有技术,具有值得注意的优势(错误率提高2.2%,EPE提高0.25像素) 目前最好的PSMNet [3]。)。
4.5.2 KITTI2012 和 KITTI2015 数据集
在对Scene Flow数据集进行训练后,我们使用GA-Net15分别对KITTI 2015和KITTI 2012数据集进行微调。 然后在测试集上评估模型。 根据在线排行榜,如表4和表5所示,我们的GA-Net具有较少的低效3D卷积,但实现了更高的准确性。 它在所有评估指标中都超过了目前最好的PSMNet。 示例在图6中示出.GA-Nets可以有效地将正确的匹配信息聚合到具有挑战性的大的无纹理或反射区域中以获得精确的估计。 它还可以很好地保持对象结构。

5. 结论
在本文中,我们开发了更有效和更有效的引导匹配代价聚合(GA)策略,包括用于端到端立体匹配的半全局聚合(SGA)和局部引导聚合(LGA)层。 GA层显着提高了挑战区域中的视差估计的准确性,例如遮挡,大的无纹理/反射区域和薄结构。 GA层可用于替代计算代价高昂的3D卷积并获得更高的准确度。
附录
A. SGA的反向传播



B. 结构细节
表6列出了GA-Net-15的细节,用于实验以在场景流数据集[15]和KITTI基准[7,16]上产生最先进的精度。 它有三个SGA层,两个LGA层和十五个3D卷积层,用于代价聚合。















 5053
5053











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









