








新智元编译
来源:blog.piekniewski
作者:Filip Piekniewski
编译:肖琴
【导读】Uber近日一篇论文引起许多讨论:该论文称发现卷积神经网络一个引人注目的“失败”,并提出解决方案CoordConv。论文称CoordConv解决了坐标变换问题,具有更好的泛化能力,训练速度提高150倍,参数比卷积少10-100倍。当然,这是在极大的计算力(100个GPU)的基础上进行的。这真的是重要的结果吗?计算机视觉领域专家Filip Piekniewski对此提出质疑。
(文/Filip Piekniewski)我读了很多深度学习论文,通常每周都会阅读几篇。我读过的论文可能已经有上千篇。我发现,机器学习或深度学习方面的论文普遍存在的问题是,它们通常处于科学和工程之间的某个无人区,我称之为“学术工程”(academic engineering)。我对其描述为:
以我个人的浅见而言,一篇科学论文应该传达一种有能力解释某事的idea。例如,一篇证明数学定理的论文,一篇提出某种物理现象模型的论文。或者,一篇科学论文可以是实验性的,实验的结果告诉我们一些关于现实的基本知识。尽管如此,科学论文的核心思想是对一些非平凡的普遍性(和预测力)或对现实本质的一些非平凡的观察的相对简洁的表述。
一篇工程论文应该介绍一种解决特定问题的方法。问题可能会因应用而异,有时它们可能非常无趣而具体,但对某个领域的人来说却是有用的。对于一篇工程论文来说,与科学论文不同的是:解决方案的普遍性可能不是最重要的。重要的是解决方案能够有效地实施,例如,给定可用的组件,能比其他解决方案更便宜或更节能,等等。工程论文的核心思想是应用,其余的仅仅是解决应用问题的想法的集合。
机器学习介于两者之间。机器学习领域既有一些明显的科学论文(例如提出反向传播backprop的论文),也有一些明显的工程论文的例子,例如描述一个非常特殊的实际问题的解决方案。但机器学习中大多数论文似乎都是工程的,只不过它们的工程是指在一个学术数据集上设计出一种综合的测量方法。为了显示出优势,一些特别的技巧被从没有人知道的地方提取出来(通常具有极其有限的普遍性),并且经过一些统计上不重要的测试后宣布该方法最优。
还有第四种论文,它确实提出一个idea。这个idea甚至可能是有用的,但它同时也是微不足道的。为了掩盖这种尴尬的事实,“学术工程”重炮再次上膛,使得论文整体上看起来令人印象深刻。
这就是Uber人工智能实验室(Uber AI labs)最近的一篇论文“"An Intriguing Failing of Convolutional Neural Networks and the CoordConv Solution”(卷积神经网络的问题及其解决方案CoordConv)的情况,我将在下面详细剖析这篇论文。
论文地址:https://arxiv.org/pdf/1807.03247.pdf
让我们直接看这篇论文的内容。我们甚至不需要阅读论文,只需看作者上传的一段视频就可以基本了解了:
这篇论文的核心论点是:卷积神经网络在需要定位的任务上表现不太好,在这些任务中,输出标签或多或少是输入实体坐标的直接函数,而不是该输入的任何其他属性。
卷积网络确实不能很好地解决这个问题,因为卷积神经网络的原始模型神经认知机(Neocognitron)的设计就是忽视位置的。接下来,作者提出了一个解决方案:在卷积层中添加坐标,作为附加的输入映射。
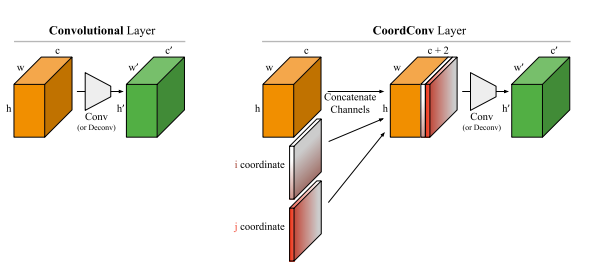
卷积层和添加坐标的CoordConv层
这听起来非常聪明,但作者实际上提出的是该领域任何一名从业者都认为是理所当然的东西——添加一个更适合解码所需输出的特征(feature)。任何在计算机视觉领域做实际工作的人都不会认为添加特征有什么非凡之处,尽管在深度学习圈的纯粹学术争论中这是一个激烈的话题,脱离实际应用的研究人员认为我们应该只使用学习的特征,因为这种方式更好。因此,深度学习的研究人员现在开始喜欢特性工程,虽然这也许不是坏事……
总之,他们添加了一个特性,即坐标的显式值。然后他们创建了一个简单的数据集(称之为Not-so-Clevr),以测试这一想法的性能。

Not-so-Clevr数据集
那么他们的实验是否聪明呢?让我们看看。

论文中使用的Toy tasks
任务之一是基于坐标生成一个one-hot图像,或者基于一个one-hot图像生成坐标。实验表明,将坐标添加到卷积网络确实可以显著提高性能。
不过如果他们不是直接跳到TensorFlow,也许这就不那么令人震惊了,他们会发现,可以明确地构建一个神经网络来解决从one-hot到坐标的关联问题,而无需任何训练。对于这个任务,我会使用三个操作:卷积、非线性激活、以及求和。幸运的是,这些都是卷积神经网络的基本组成部分:

注意:one hot像素位图到坐标翻译!一个卷积层,一个非线性激活,一个求和,最后一个减法。就是这样。无需学习,只有大约50行python代码(带注释)……对于这个任务,给定坐标特征是微不足道的。毫无疑问,这是可行的。到目前为止,我们所用的知识还没有超出一个刚上完ML 101课程的学生所能解决的。所以,他们不得不使用重型火炮:GAN。
好吧,让我们用GAN试试这个合成生成任务,一个带有坐标特征,一个没有。好了,现在让我们继续看论文……
他们在附录的表格中给出了结果:
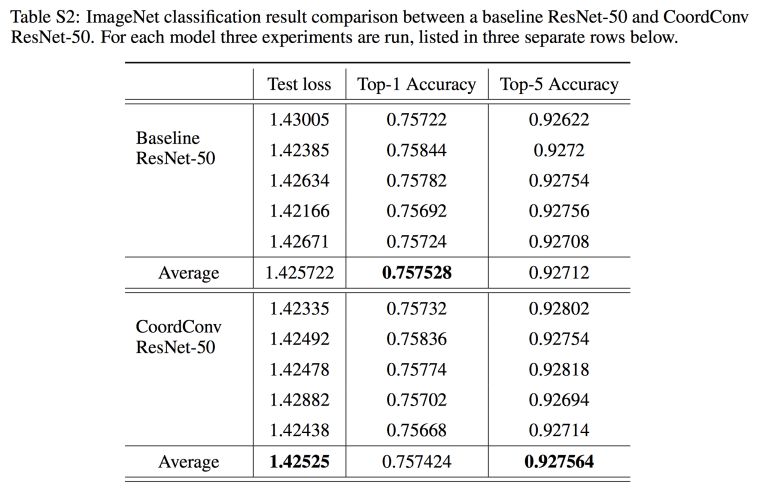
他们在ImageNet上尝试了这个坐标特征,将它添加到ResNet-50网络的第一层。我认为不会有太大的差别,因为ImageNet中的类别读取不是位置的函数(如果存在这样的偏差,那么在训练期间的数据增强应该完全删除它)。所以他们用100个GPU来训练网络(100个GPU!天啊!)。然而,到小数点后第4位,结果才显示出一点差异。Facebook、谷歌的人可能会用10000个GPU来复现这个结果吧。这些GPU能不能用来做些更重要的事情?
这确实是一篇吸引人的论文。它揭露了当前深度学习研究的浅薄之处,这些研究被荒谬的计算量所掩盖了。为什么Uber AI 实验室要做这个研究?有什么意义?我的意思是,如果这些是某个大学的某些学生做的,他们想做出点什么投给会议,那么无可厚非。但Uber AI?我以为这些人应该致力于打造自动驾驶汽车,不是吗?不过,比这篇论文更有趣的是哪些对这个结果的无足轻重无知,而去赞美它的追随者。请阅读原始博客(https://eng.uber.com/coordconv)的评论,或者Twitter上的评论,赞美者甚至包括一些著名的DL研究人员。他们显然花了很多时间盯着GPU上的进度条,才意识到他们在称赞一些显而易见的东西,这些显而易见的东西可以用几行python代码手工构建。
编译来源:
https://blog.piekniewski.info/2018/07/14/autopsy-dl-paper/


点击下方“阅读原文”了解云创大数据诚征公安行业总代理事宜 ↓↓↓















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









