







Spark的介绍
Hadoop与Strom
Hadoop:
- MapReduce:为海量数据提供了计算,但只有Map和Reduce操作,操作不灵活。
- HDFS(分布式文件系统):为海量的数据提供了存储。(把全部计算机的存储能力合在一起,数据通过网络在节点之间传输)。
Strom:一个分布式的、容错的实时计算系统。
大数据处理
- 复杂的批量数据处理(batch data processing)
- 基于历史数据的交互式查询(interactive query)
- 基于实时数据流的数据处理(streaming data processing)
Spark特点与应用场景
Spark是通用的并行化计算框架,基于MapReduce实现分布式计算,其中间结果可以保存在内存中,从而不再需要读写HDFS。
特点:
- 简单方便,使用scala语言。(与RDD很好结合)
- 计算速度快,中间结果缓存在内存中。
- 高错误容忍。
- 操作丰富。
- 广播,每个节点可以保留一份小数据集。
核心:RDD(Resilient Distributed Datasets弹性分布式数据集)
应用场景:
- 迭代式算法:迭代式机器学习、图算法,包括PageRank、K-means聚类和逻辑回归(logistic regression)。
- 交互式数据挖掘工具:用户在同一数据子集上运行多个Adhoc查询。
框架

RDD
RDD是一种只读的、分区的记录集合。Spark借助RDD实现对类存的管理。
操作:
- 转换(transformation):生成新的RDD。(map/filter/groupBy/join)
- 动作(action):将RDD上的某项操作的结果返回给程序,不产生RDD。(count/reduce/collect/save)
分区:对RDD分区,保存在多个节点上,实现分布式计算。
持久化:RDD缓存。(在内存中或者溢出到磁盘)(容错&加速)
血统(lineage):RDD有足够信息关于它是如何从其他RDD产生而来的。(容错)
对象:

依赖
转换操作产生新的RDD

窄依赖:父RDD只有一个子分区。
宽依赖:每个子RDD依赖所有父RDD分区。
懒惰计算
懒惰计算(lazy evaluation):Spark在遇到 Transformations操作时只会记录需要这样的操作,并不会去执行,需要等到有Actions操作的时候才会真正启动计算过程进行计算。(不像python和matlab马上执行)。
一个系统知道全部RDD的计算路径的时候,它才拥有最大的优化空间。
DAG
优化任意操作算子图

Spark会尽可能地管道化,并基于是否要重新组织数据来划分阶段(stage)。
窄依赖:多个RDD合并成一个,在一个节点进行,不用生成中间RDD结果。(管道化)
宽依赖:没啥优化。
调度过程


容错
- Checkpoint:数据备份,检测数据完整性。比较占用空间,数据复制需要消耗时间。(hadoop只有这个)
- loggingthe updates:依靠lineage chains,记录每个RDD产生方法,根据存储信息重构数据集合,其他节点帮组重构。节省空间,如果血缘关系复杂,可能导致全部节点重新计算。
Spark的安装教程
安装JDK与Scala
- 下载JDK:sudo apt-get install openjdk-7-jre-headless。
- 下载Scala: http://www.scala-lang.org/。
- 解压缩:tar –zxvf scala-2.10.6.tgz。
- 进入sudo vim /etc/profile在下面添加路径:
SCALA_HOME=
/home/scala/scala-2.10.6
(解压后的包所在的路径)
PATH=
$PATH
:
${
SCALA_HOME}/bin
- 使修改生效source /etc/profile。
- 在命令行输入scala测试。
安装Spark

- 解压缩: tar –zxvf spark-1.5.1-bin-hadoop2.6.tgz
- 进入sudo vim /etc/profile在下面添加路径:
SPARK_HOME=
/home/spark/spark-lectures/spark
-
1.5
.
1
-bin-hadoop2.
6
(解压后的包所在的路径)
PATH=
$PATH
:
${
SPARK_HOME}/bin
配置spark
- 配置 Spark
- 1
- 2
- 3
在spark-env.sh末尾添加以下内容(这是我的配置,你可以自行修改):
- 1
- 2
- 3
- 4
- 5
- 6
- 7
注:在设置Worker进程的CPU个数和内存大小,要注意机器的实际硬件条件,如果配置的超过当前Worker节点的硬件条件,Worker进程会启动失败。
vi slaves在slaves文件下填上slave主机名:
- 1
- 2
将配置好的spark-1.3.0文件夹分发给所有slaves吧
- 1
启动Spark
- 1
验证 Spark 是否安装成功
用jps检查,在 master 上应该有以下几个进
- 1
- 2
- 3
- 4
- 5
- 6
slave 上应该有以下几个进程:
- 1
- 2
- 3
- 4
- 5
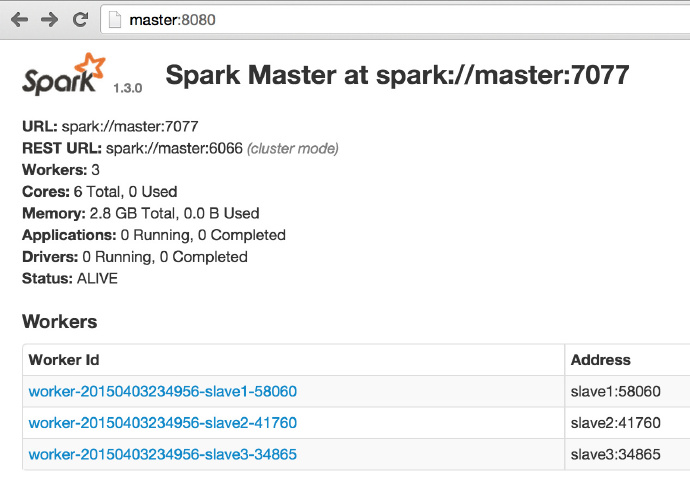
进入Spark的Web管理页面: http://master:8080
参考
http://blog.csdn.net/dengpei187/article/details/52280760
http://blog.csdn.net/lin360580306/article/details/51233397















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









