







序言
在使用大数据的时候,各种不同的数据都要将数据采集同步到数据仓库中,一个是属于业务系统的RDBMS系统,也就是各种关系型数据库,一个是hadoop生态的存储,中间用于传输的数据的工具可以使用sqoop,也就是sql to hadoop。
在数据进入数仓的ODS层的时候,使用sqoop,在进入hadoop之后,就可以使用其他的计算框架进行分析,例如hive,MR,spark等。
sqoop
1 sqoop所处的位置
sqoop是一个用于数据传输的工具,是连接RDBMS和数仓ODS的桥梁:
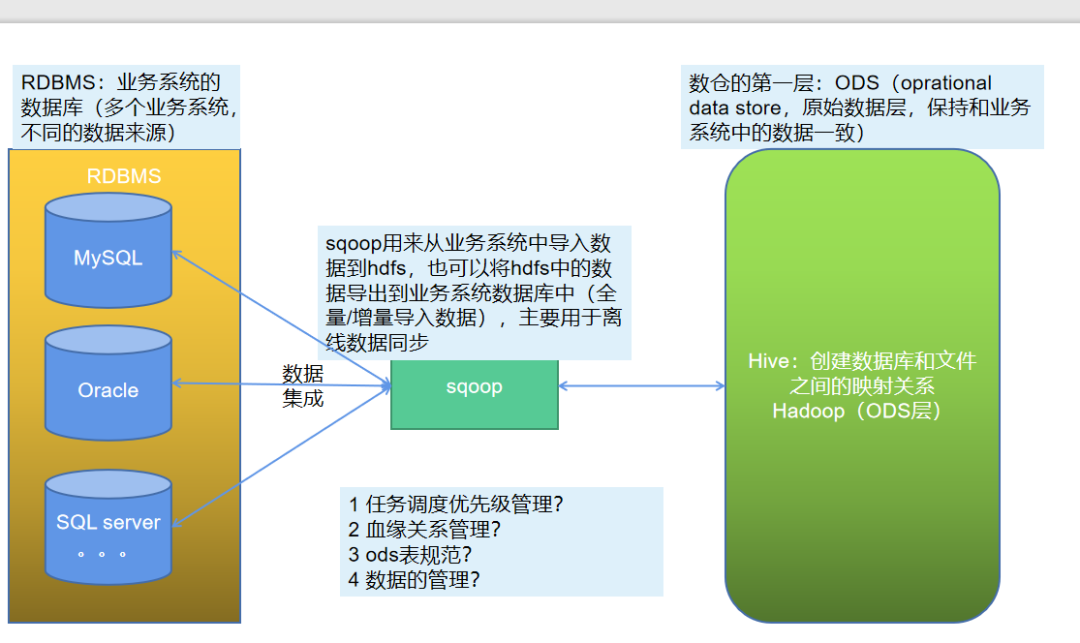
sqoop是将结构化数据同步到hdfs中,也可以是hive和hbase等,支持不同的数据库,只要将相关的连接数据库驱动放到安装sqoop的lib库中即可,从而能连接,进行数据的导入导出操作。
在进行使用sqoop的时候,考虑到任务数量的众多,需要从不同的业务系统中同步数据,而业务系统使用的数据库又是多种多样的,从数仓的建立来说,需要确定相关的指标,从而需要首先规划好哪些数据库,哪些数据需要同步,任务数量多,从而需要考虑任务的优先级管理,任务的优先级决定了指标的产出时间,可以划分核心指标,从而得到核心任务,也就是需要优先产出的任务,从而定义好相应的任务。
血缘关系,也就是sqoop数据导入任务才是第一步,后面还有数仓中的各种数据清洗,数据统计分析的任务,从而需要划分好任务依赖。
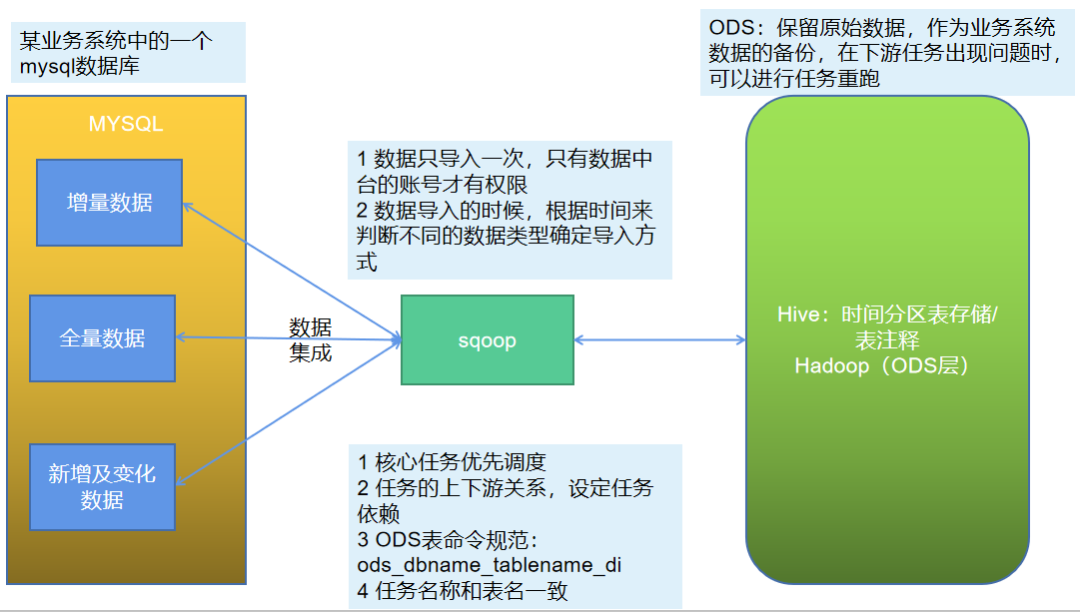
为了方便问题的排查,也就是对于sqoop的导入数据任务来说,每个导入使用一个导入job来实现。
ODS作为第一层,保持业务数据的一致性,基本不会对数据进行任何处理,直接保存在数仓中。从而表命名可以使用ods_databasename_tablename_di,ods表示表所在的层级,数据库名称表示数据的来源,而表名和业务系统一致,di表示每日增量day increase,全量的就不需要标注了,对于任务名称来说,也可以使用表名一致的方式,从而便于问题的排查,见名知意。
2 数据分类
在业务系统的表里面的数据,可以分为三类数据,一种是全量数据,这种表示同步的时候,只要全部同步就好,数据量比较少,而且变化的频率不高,像用户,地区这种维度表。
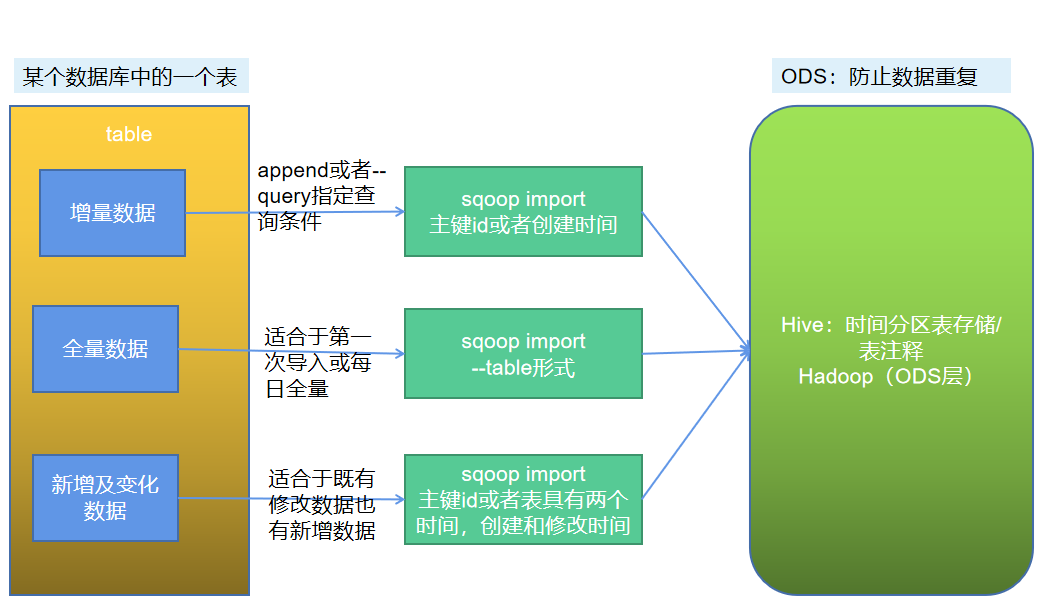
对于增量数据,也就是这个表里面的数据只会存在insert操作,而不会存在update操作,像交易表,这种只会新增记录,基本不会涉及修改。
对于新增及变化的数据,这种一般就是订单表,不但每天都会有新增的数据,而且会存在修改的动作,也就是修改订单的状态,从而每天都会发生变化。
3 sqoop使用
sqoop的安装很简单,只要下载之后,修改一下简单的配置就可以使用,但是由于sqoop需要使用hadoop的map任务,从而需要提前安装好hadoop,在这个基础上安装sqoop(注意将连接数据库的驱动放到sqoop的lib目录中)。
[root@KEL1 conf]# cat sqoop-env.sh
# Set Hadoop-specific environment variables here.
#Set path to where bin/hadoop is available
export HADOOP_COMMON_HOME=/opt/module/hadoop-2.7.2
#Set path to where hadoop-*-core.jar is available
export HADOOP_MAPRED_HOME=/opt/module/hadoop-2.7.2
#set the path to where bin/hbase is available
#export HBASE_HOME=
#Set the path to where bin/hive is available
export HIVE_HOME=/opt/module/apache-hive-1.2.2
#Set the path for where zookeper config dir is
#export ZOOCFGDIR=
[root@KEL1 conf]# which hadoop
/opt/module/hadoop-2.7.2/bin/hadoop
全量导入(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 333
333











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









