






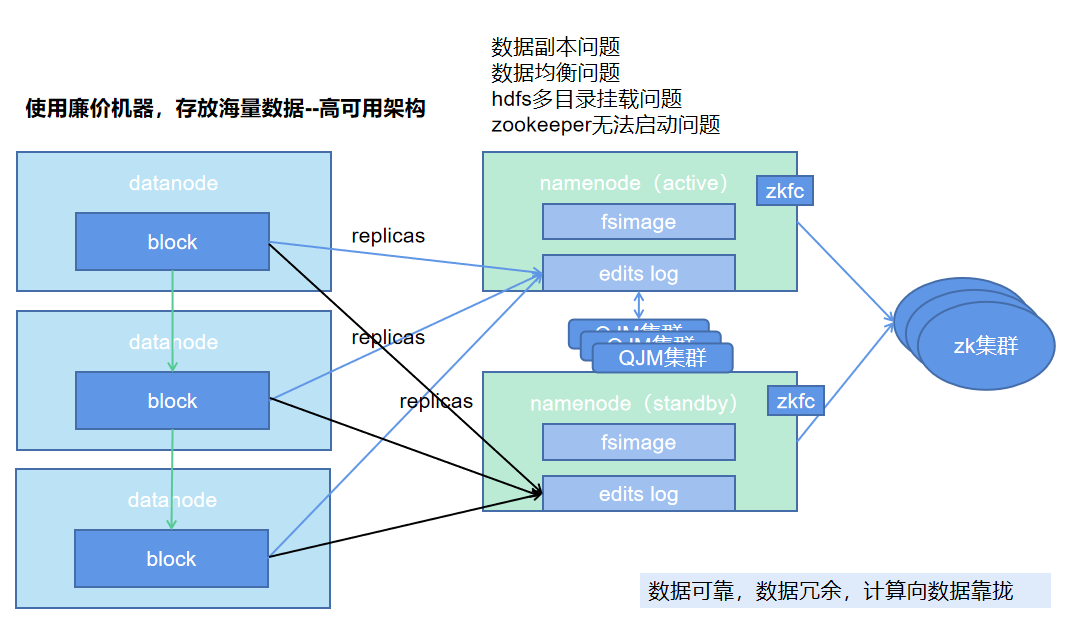
序言
海量的数据无论是存储还是计算,总是要保证其架构的高可用,数据仓库的构建是一个合的过程,而微服务又是一个分的过程,天下大势,分分合合。
不同的场景适合于不同的技术,不要在一个里面觉得这个技术就是银弹,可能也只是昙花一现。
hadoop相关问题
序:namenode高可用问题
namenode的高可用是由QJM和zkfc加zk集群来实现的,当宕机再启动的时候,会切换很快,但是如果直接宕机或者是hang机,当ssh无法登录上去的时候,就会导致切换不成功,一直为standby状态。。。需要登录上去,进行探测namenode进程是否存在,如果存在则杀死,这就是sshfence的实现,但是要在宕机的时候,也可以切换,必须修改为如下配置:
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
namenode不可用导致集群不可用:
#只读操作也不可以
hdfs dfs -ls hdfs://ns/user
21/03/02 04:21:21 INFO retry.RetryInvocationHandler: Exception while invoking getFileInfo of class ClientNamenodeProtocolTranslatorPB over KEL1/192.168.1.99:9000 after 1 fail over attempts. Trying to fail over after sleeping for 659ms.
org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.ipc.StandbyException): Operation category READ is not supported in state standby
at org.apache.hadoop.hdfs.server.namenode.ha.StandbyState.checkOperation(StandbyState.java:87)
at org.apache.hadoop.hdfs.server.namenode.NameNode$NameNodeHAContext.checkOperation(NameNode.java:1774)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkOperation(FSNamesystem.java:1313)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getFileInfo(FSNamesystem.java:3850)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.getFileInfo(NameNodeRpcServer.java:1011)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.getFileInfo(ClientNamenodeProtocolServerSideTranslatorPB.java:843)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:616)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:969)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2049)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2045)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1657)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2043)
##namenode log
2021-03-02 05:30:27,301 WARN org.apache.hadoop.hdfs.server.namenode.FSNamesystem: Get corrupt file blocks returned error: Operation category READ is not supported in state standby
2021-03-02 05:30:28,171 WARN org.apache.hadoop.hdfs.server.namenode.FSNamesystem: Get corrupt file blocks returned error: Operation category READ is not supported in state standby
##zkfc log
2021-03-02 06:14:13,573 WARN org.apache.hadoop.ha.HealthMonitor: Transport-level exception trying to monitor health of NameNode at KEL/192.168.1.10:9000: java.net.SocketTimeoutException: 45000 millis timeout while waiting for channel to be ready for read. ch : java.nio.channels.SocketChannel[connected local=/192.168.1.10:54563 remote=KEL/192.168.1.10:9000] Call From KEL/192.168.1.10 to KEL:9000 failed on socket timeout exception: java.net.SocketTimeoutException: 45000 millis timeout while waiting for channel to be ready for read. ch : java.nio.channels.SocketChannel[connected local=/192.168.1.10:54563 remote=KEL/192.168.1.10:9000]; For more details see: http://wiki.apache.org/hadoop/SocketTimeout
##两次切换的日志
2021-03-02 08:11:18,790 WARN org.apache.hadoop.ha.FailoverController: Unable to gracefully make NameNode at KEL/192.168.1.10:9000 standby (unable to connect)
org.apache.hadoop.net.ConnectTimeoutException: Call From KEL1/192.168.1.99 to KEL:9000 failed on socket timeout exception: org.apache.hadoop.net.ConnectTimeoutException: 20000 millis timeout while waiting for channel to be ready for connect. ch : java.nio.channels.SocketChannel[connection-pending remote=KEL/192.168.1.10:9000]; For more details see: http://wiki.apache.org/hadoop/SocketTimeout
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:792)
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:751)
at org.apache.hadoop.ipc.Client.call(Client.java:1479)
at org.apache.hadoop.ipc.Client.call(Client.java:1412)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:229)
at com.sun.proxy.$Proxy9.transitionToStandby(Unknown Source)
at org.apache.hadoop.ha.protocolPB.HAServiceProtocolClientSideTranslatorPB.transitionToStandby(HAServiceProtocolClientSideTranslatorPB.java:112)
at org.apache.hadoop.ha.FailoverController.tryGracefulFence(FailoverController.java:172)
at org.apache.hadoop.ha.ZKFailoverController.doFence(ZKFailoverController.java:514)
at org.apache.hadoop.ha.ZKFailoverController.fenceOldActive(ZKFailoverController.java:505)
at org.apache.hadoop.ha.ZKFailoverController.access$1100(ZKFailoverController.java:61)
at org.apache.hadoop.ha.ZKFailoverController$ElectorCallbacks.fenceOldActive(ZKFailoverController.java:892)
at org.apache.hadoop.ha.ActiveStandbyElector.fenceOldActive(ActiveStandbyElector.java:910)
at org.apache.hadoop.ha.ActiveStandbyElector.becomeActive(ActiveStandbyElector.java:809)
at org.apache.hadoop.ha.ActiveStandbyElector.processResult(ActiveStandbyElector.java:418)
at org.apache.zookeeper.ClientCnxn$EventThread.processEvent(ClientCnxn.java:599)
at org.apache.zookeeper.ClientCnxn$EventThread.run(ClientCnxn.java:498)
Caused by: org.apache.hadoop.net.ConnectTimeoutException: 20000 millis timeout while waiting for channel to be ready for connect. ch : java.nio.channels.SocketChannel[connection-pending remote=KEL/192.168.1.10:9000]
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:534)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:495)
at org.apache.hadoop.ipc.Client$Connection.setupConnection(Client.java:614)
at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:712)
at org.apache.hadoop.ipc.Client$Connection.access$2900(Client.java:375)
at org.apache.hadoop.ipc.Client.getConnection(Client.java:1528)
at org.apache.hadoop.ipc.Client.call(Client.java:1451)
... 14 more
2021-03-02 08:11:18,791 INFO org.apache.hadoop.ha.NodeFencer: ====== Beginning Service Fencing Process... ======
2021-03-02 08:11:18,791 INFO org.apache.hadoop.ha.NodeFencer: Trying method 1/2: org.apache.hadoop.ha.SshFenceByTcpPort(null)
2021-03-02 08:11:18,793 INFO org.apache.hadoop.ha.SshFenceByTcpPort: Connecting to KEL...
2021-03-02 08:11:18,793 INFO org.apache.hadoop.ha.SshFenceByTcpPort.jsch: Connecting to KEL port 22
2021-03-02 08:11:48,818 WARN org.apache.hadoop.ha.SshFenceByTcpPort: Unable to connect to KEL as user root
com.jcraft.jsch.JSchException: timeout: socket is not established
at com.jcraft.jsch.Util.createSocket(Util.java:386)
at com.jcraft.jsch.Session.connect(Session.java:182)
at org.apache.hadoop.ha.SshFenceByTcpPort.tryFence(SshFenceByTcpPort.java:100)
at org.apache.hadoop.ha.NodeFencer.fence(NodeFencer.java:97)
at org.apache.hadoop.ha.ZKFailoverController.doFence(ZKFailoverController.java:532)
at org.apache.hadoop.ha.ZKFailoverController.fenceOldActive(ZKFailoverController.java:505)
at org.apache.hadoop.ha.ZKFailoverController.access$1100(ZKFailoverController.java:61)
at org.apache.hadoop.ha.ZKFailoverController$ElectorCallbacks.fenceOldActive(ZKFailoverController.java:892)
at org.apache.hadoop.ha.ActiveStandbyElector.fenceOldActive(ActiveStandbyElector.java:910)
at org.apache.hadoop.ha.ActiveStandbyElector.becomeActive(ActiveStandbyElector.java:809)
at org.apache.hadoop.ha.ActiveStandbyElector.processResult(ActiveStandbyElector.java:418)
at org.apache.zookeeper.ClientCnxn$EventThread.processEvent(ClientCnxn.java:599)
at org.apache.zookeeper.ClientCnxn$EventThread.run(ClientCnxn.java:498)
2021-03-02 08:11:48,820 WARN org.apache.hadoop.ha.NodeFencer: Fencing method org.apache.hadoop.ha.SshFenceByTcpPort(null) was unsuccessful.
2021-03-02 08:11:48,820 INFO org.apache.hadoop.ha.NodeFencer: Trying method 2/2: org.apache.hadoop.ha.ShellCommandFencer(/bin/true)
2021-03-02 08:11:48,852 INFO org.apache.hadoop.ha.ShellCommandFencer: Launched fencing command '/bin/true' with pid 5931
2021-03-02 08:11:48,856 INFO org.apache.hadoop.ha.NodeFencer: ====== Fencing successful by method org.apache.hadoop.ha.ShellCommandFencer(/bin/true) ======
2021-03-02 08:11:48,856 INFO org.apache.hadoop.ha.ActiveStandbyElector: Writing znode /hadoop-ha/ns/ActiveBreadCrumb to indicate that the local node is the most recent active...
2021-03-02 08:11:48,863 INFO org.apache.hadoop.ha.ZKFailoverController: Trying to make NameNode at KEL1/192.168.1.99:9000 active...
2021-03-02 08:11:49,387 INFO org.apache.hadoop.ha.ZKFailoverController: Successfully transitioned NameNode at KEL1/192.168.1.99:9000 to active state
1 数据副本问题
在查看namenode的日志时,出现数据块管理报错,没有足够的副本来存放数据,不停的WARN:
2021-03-02 04:35:38,652 WARN org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicy: Failed to place enough replicas, still in need of 1 to reach 3 (unavailableStorages=[], storagePolicy=BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]}, newBlock=false) For more information, please enable DEBUG log level on org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicy
2021-03-02 04:35:38,653 WARN org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicy: Failed to place enough replicas, still in need of 1 to reach 3 (unavailableStorages=[DISK], storagePolicy=BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]}, newBlock=false) For more information, please enable DEBUG log level on org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicy
看报错的信息,大致的意思就是本来设置了一个block为三个副本,但是还差一个才能到达三个副本。
这种情况出现的原因有很多,毕竟hadoop是运行在廉价的物理机之上,那么无论是服务器节点还是硬盘都随时可能出现故障,出现坏盘或者坏机器,从而导致数据副本不足。
hdfs为了保证数据的可靠性,会将一个文件切分成一个个的block,一个block默认大小为124M,然后将block分布在不同的datanode节点之上,当有节点出现问题的时候,会自动的进行复制迁移到正常的节点上。
偶尔也需要进行手动的迁移,也就是本来是三副本现在不足,那么就先设置为2副本,然后再设置为3副本,从而手动触发数据迁移复制。
[root@KEL logs]# hdfs fsck /
Connecting to namenode via http://KEL1:50070/fsck?ugi=root&path=%2F
FSCK started by root (auth:SIMPLE) from /192.168.1.10 for path / at Wed Mar 03 13:03:26 CST 2021
....................................................................................................
....................................................................................................
.....................................
/tmp/hadoop-yarn/staging/root/.staging/job_1614266885310_0001/job.jar: Under replicated BP-184102405-192.168.1.10-1612873956948:blk_1073742395_1571. Target Replicas is 10 but found 2 replica(s).
.
/tmp/hadoop-yarn/staging/root/.staging/job_1614266885310_0001/job.split: Under replicated BP-184102405-192.168.1.10-1612873956948:blk_1073742396_1572. Target Replicas is 10 but found 3 replica(s).
.....
/tmp/hadoop-yarn/staging/root/.staging/job_1614529282649_0001/job.jar: Under replicated BP-184102405-192.168.1.10-1612873956948:blk_1073747250_6426. Target Replicas is 10 but found 3 replica(s).
.
/tmp/hadoop-yarn/staging/root/.staging/job_1614529282649_0001/job.split: Under replicated BP-184102405-192.168.1.10-1612873956948:blk_1073747251_6427. Target Replicas is 10 but found 3 replica(s).
...
/tmp/hadoop-yarn/staging/root/.staging/job_1614648088274_0001/job.jar: Under replicated BP-184102405-192.168.1.10-1612873956948:blk_1073747449_6625. Target Replicas is 10 but found 3 replica(s).
.
/tmp/hadoop-yarn/staging/root/.staging/job_1614648088274_0001/job.split: Under replicated BP-184102405-192.168.1.10-1612873956948:blk_1073747450_6626. Target Replicas is 10 but found 3 replica(s).
....................................................
....................................................................................................
....................................................................................................
....................................................................................................
..........................Status: HEALTHY
Total size: 577584452 B
Total dirs: 300
Total files: 626
Total symlinks: 0
Total blocks (validated): 521 (avg. block size 1108607 B)
Minimally replicated blocks: 521 (100.0 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 6 (1.1516315 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 3
Average block replication: 2.9980807
Corrupt blocks: 0
Missing replicas: 43 (2.6791277 %)
Number of data-nodes: 3
Number of racks: 1
FSCK ended at Wed Mar 03 13:03:26 CST 2021 in 70 milliseconds
The filesystem under path '/' is HEALTHY
可以使用hdfs fsck来进行文件的检查,会检查所有的副本数是否满足,如上所示,有几个文件的副本数不足,产生的原因是运行任务的过程中出现了报错,而没有将相关的数据进行清理。
#手动设置所有文件的副本数为3
[root@KEL module]hdfs dfs -setrep -w 3 -R /
发现用了很久时间都没有进行设置。
Waiting for /tmp/hadoop-yarn/staging/history/done/2021/03/02/000000/job_1614665577456_0002_conf.xml ... done
Waiting for /tmp/hadoop-yarn/staging/root/.staging/job_1614266885310_0001/job.jar
在tmp目录很久也未设置成功,从而直接将此文件删除:
[root@KEL module]# hdfs dfs -rm -r /tmp/hadoop-yarn/staging/
21/03/03 21:51:42 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes.
Deleted /tmp/hadoop-yarn/staging
#删除临时文件之后,再次进行检查
[root@KEL module]# hdfs fsck /
Connecting to namenode via http://KEL1:50070/fsck?ugi=root&path=%2F
FSCK started by root (auth:SIMPLE) from /192.168.1.10 for path / at Wed Mar 03 13:41:53 CST 2021
....................................................................................................
....................................................................................................
....................................................................................................
..............................................................................Status: HEALTHY
Total size: 533172477 B
Total dirs: 268
Total files: 378
Total symlinks: 0
Total blocks (validated): 274 (avg. block size 1945884 B)
Minimally replicated blocks: 274 (100.0 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 0 (0.0 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 3
Average block replication: 3.0
Corrupt blocks: 0
Missing replicas: 0 (0.0 %)
Number of data-nodes: 3
Number of racks: 1
FSCK ended at Wed Mar 03 13:41:53 CST 2021 in 76 milliseconds
The filesystem under path '/' is HEALTHY
在进行查看job history文件的时候,出现错误(historyserver日志):
2021-03-03 21:56:50,962 ERROR org.apache.hadoop.mapreduce.v2.hs.JobHistory: Error while scanning intermediate done dir
java.io.FileNotFoundException: File /tmp/hadoop-yarn/staging/history/done_intermediate does not exist.
at org.apache.hadoop.fs.Hdfs$DirListingIterator.<init>(Hdfs.java:211)
at org.apache.hadoop.fs.Hdfs$DirListingIterator.<init>(Hdfs.java:195)
at org.apache.hadoop.fs.Hdfs$2.<init>(Hdfs.java:177)
at org.apache.hadoop.fs.Hdfs.listStatusIterator(Hdfs.java:177)
at org.apache.hadoop.fs.FileContext$22.next(FileContext.java:1494)
at org.apache.hadoop.fs.FileContext$22.next(FileContext.java:1489)
at org.apache.hadoop.fs.FSLinkResolver.resolve(FSLinkResolver.java:90)
at org.apache.hadoop.fs.FileContext.listStatus(FileContext.java:1489)
at org.apache.hadoop.mapreduce.v2.jobhistory.JobHistoryUtils.listFilteredStatus(JobHistoryUtils.java:505)
at org.apache.hadoop.mapreduce.v2.jobhistory.JobHistoryUtils.localGlobber(JobHistoryUtils.java:452)
at org.apache.hadoop.mapreduce.v2.jobhistory.JobHistoryUtils.localGlobber(JobHistoryUtils.java:444)
at org.apache.hadoop.mapreduce.v2.jobhistory.JobHistoryUtils.localGlobber(JobHistoryUtils.java:439)
at org.apache.hadoop.mapreduce.v2.hs.HistoryFileManager.scanIntermediateDirectory(HistoryFileManager.java:795)
at org.apache.hadoop.mapreduce.v2.hs.JobHistory$MoveIntermediateToDoneRunnable.run(JobHistory.java:189)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:308)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:294)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
页面出现500报错。。。开启了mapreduce的日志聚合之后,默认会将日志存放在这个tmp路径之中。(当不能触发自动迁移的时候,就应该主动去手动触发迁移。)
hdfs-site.xml配置文件中,参数dfs.replication设置副本数量,默认为3.
2 hdfs多目录挂载
这种情况一般发生在刚上线的时候,或者是服务器的盘坏了需要重新加一块盘的时候。
#对磁盘进行分区
[root@KEL ~]# fdisk /dev/sdb
Welcome to fdisk (util-linux 2.23.2).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
Device does not contain a recognized partition table
Building a new DOS disklabel with disk identifier 0x4670e170.
Command (m for help): n
Partition type:
p primary (0 primary, 0 extended, 4 free)
e extended
Select (default p): p
Partition number (1-4, default 1):
First sector (2048-20971519, default 2048):
Using default value 2048
Last sector, +sectors or +size{K,M,G} (2048-20971519, default 20971519):
Using default value 20971519
Partition 1 of type Linux and of size 10 GiB is set
Command (m for help): w
The partition table has been altered!
#进行检查分区结果
[root@KEL ~]# fdisk -l
Disk /dev/sdb: 10.7 GB, 10737418240 bytes, 20971520 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0x4670e170
Device Boot Start End Blocks Id System
/dev/sdb1 2048 20971519 10484736 83 Linux
再进行格式化磁盘:
[root@KEL data2]# mkfs.ext3 /dev/sdb1
mke2fs 1.42.9 (28-Dec-2013)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
655360 inodes, 2621184 blocks
131059 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=2684354560
80 block groups
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632
Allocating group tables: done
Writing inode tables: done
Creating journal (32768 blocks): done
Writing superblocks and filesystem accounting information: done
#创建挂载目录
[root@KEL hadoop-2.7.2]# mkdir data2
#添加开启启动文件
[root@KEL data2]# cat /etc/fstab
#
# /etc/fstab
# Created by anaconda on Sat Feb 6 18:18:57 2021
#
# Accessible filesystems, by reference, are maintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
/dev/mapper/rhel-root / xfs defaults 0 0
UUID=a6f53869-d27b-4a99-94b5-4ec61040d008 /boot xfs defaults 0 0
/dev/mapper/rhel-swap swap swap defaults 0 0
/dev/sdb1 /opt/module/hadoop-2.7.2/data2 ext3 defaults 0 0
#测试挂载
[root@KEL data2]# mount -a
#修改hdfs配置文件
[root@KEL hadoop]# vim hdfs-site.xml
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data,file:///opt/module/hadoop-2.7.2/data2</value>
</property>
#启动本机上的相关进程
[root@KEL hadoop]# start-dfs.sh
#检查文件结果(主要查看版本号是否一致)
[root@KEL current]# pwd
/opt/module/hadoop-2.7.2/data2/current
[root@KEL current]# cat VERSION
#Wed Mar 03 17:07:06 CST 2021
storageID=DS-72c239ca-daff-4655-b95a-4e5a50bd28a8
clusterID=CID-073cc3af-78f6-4716-993b-92a0b398291a
cTime=0
datanodeUuid=1c4ffb79-0fae-42a1-af32-65fecc962cda
storageType=DATA_NODE
layoutVersion=-56
[root@KEL current]# cd -
/opt/module/hadoop-2.7.2/data/tmp/dfs/data/current
[root@KEL current]# cat VERSION
#Wed Mar 03 17:07:06 CST 2021
storageID=DS-ff23d5a7-fe98-404b-a5b9-5d449e3b31d2
clusterID=CID-073cc3af-78f6-4716-993b-92a0b398291a
cTime=0
datanodeUuid=1c4ffb79-0fae-42a1-af32-65fecc962cda
storageType=DATA_NODE
layoutVersion=-56
[root@KEL current]# pwd
/opt/module/hadoop-2.7.2/data/tmp/dfs/data/current
#查看空间是否增大
[root@KEL hadoop]# hdfs dfsadmin -report
-------------------------------------------------
Live datanodes (3):
Name: 192.168.1.10:50010 (KEL)
Hostname: KEL
Decommission Status : Normal
Configured Capacity: 29180092416 (27.18 GB)
DFS Used: 788815872 (752.27 MB)
Non DFS Used: 3924152320 (3.65 GB)
DFS Remaining: 24467124224 (22.79 GB)
DFS Used%: 2.70%
DFS Remaining%: 83.85%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Wed Mar 03 09:12:20 CST 2021
WEB页面查看增大的空间:

3 数据不均衡
在集群中新加入一台机器之后,那么就会造成数据不均衡,新上线的机器的负载低,存储的数据量也少,从而要对数据进行一个balance操作。
#启动一个balancer操作,threshold表示每个datanode上数据量差别为1%
[root@KEL sbin]# ./start-balancer.sh -threshold 1
starting balancer, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-balancer-KEL.out
[root@KEL sbin]# vim ../logs/hadoop-root-balancer-KEL.log
[root@KEL sbin]# jps
10121 Balancer
2021-03-03 17:47:38,546 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /default-rack/192.168.1.199:50010
2021-03-03 17:47:38,546 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /default-rack/192.168.1.99:50010
2021-03-03 17:47:38,546 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /default-rack/192.168.1.10:50010
2021-03-03 17:47:38,547 INFO org.apache.hadoop.hdfs.server.balancer.Balancer: 1 over-utilized: [192.168.1.199:50010:DISK]
2021-03-03 17:47:38,547 INFO org.apache.hadoop.hdfs.server.balancer.Balancer: 0 underutilized: []
2021-03-03 17:47:38,547 INFO org.apache.hadoop.hdfs.server.balancer.Balancer: Need to move 7.59 MB to make the cluster balanced.
2021-03-03 17:47:38,547 INFO org.apache.hadoop.hdfs.server.balancer.Balancer: Decided to move 27.38 MB bytes from 192.168.1.199:50010:DISK to 192.168.1.99:50010:DISK
2021-03-03 17:47:38,547 INFO org.apache.hadoop.hdfs.server.balancer.Balancer: Decided to move 151.40 MB bytes from 192.168.1.199:50010:DISK to 192.168.1.10:50010:DISK
2021-03-03 17:47:38,547 INFO org.apache.hadoop.hdfs.server.balancer.Balancer: Will move 178.78 MB in this iteration
2021-03-03 17:47:47,568 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /default-rack/192.168.1.10:50010
2021-03-03 17:47:47,569 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /default-rack/192.168.1.99:50010
2021-03-03 17:47:47,569 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /default-rack/192.168.1.199:50010
在页面上查看均衡结果:

在大致平衡完成之后,需要手动进行关闭,否则大量的数据迁移会导致运行中的任务性能的降低。
[root@KEL sbin]# ./stop-balancer.sh
4 强制关机导致zookeeper无法启动
强制关机的时候,导致启动脚本中还能检测pid,从而误认为进程还存在,从而不启动。
#status说未启动
[root@KEL2 zkdata]# /opt/module/zookeeper-3.4.12/bin/zkServer.sh status /opt/module/zookeeper-3.4.12/zkdata/zoo.cfg
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.4.12/zkdata/zoo.cfg
Error contacting service. It is probably not running.
#start的时候,检测到pid文件,认为已经在运行
[root@KEL2 zkdata]# /opt/module/zookeeper-3.4.12/bin/zkServer.sh start /opt/module/zookeeper-3.4.12/zkdata/zoo.cfg
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.4.12/zkdata/zoo.cfg
Starting zookeeper ... already running as process 2260.
两种方式解决:
#找到pid文件,然后将文件删除,再次启动即可。
[root@KEL2 zkdata]# grep data zoo.cfg
dataDir=/opt/module/zookeeper-3.4.12/zkdata
[root@KEL2 zkdata]# ls -l
total 16
-rw-r--r-- 1 root root 2 Feb 9 18:31 myid
drwxr-xr-x 2 root root 4096 Feb 17 19:38 version-2
-rw-r--r-- 1 root root 170 Feb 9 18:38 zoo.cfg
-rw-r--r-- 1 root root 4 Feb 16 18:36 zookeeper_server.pid
[root@KEL2 zkdata]# cat zookeeper_server.pid
2260[root@KEL2 zkdata]# rm -rf zookeeper_server.pid
[root@KEL2 zkdata]# /opt/module/zookeeper-3.4.12/bin/zkServer.sh start /opt/module/zookeeper-3.4.12/zkdata/zoo.cfg
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.4.12/zkdata/zoo.cfg
Starting zookeeper ... STARTED
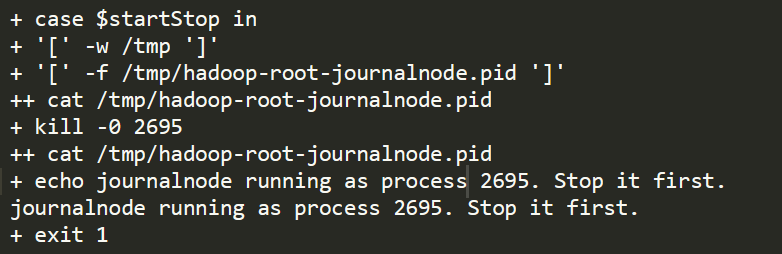
或者是先停止,然后再启动也行。
除了zk启动会碰到这种问题,对于haddoop其他进程也可能碰到此类问题,都可以先停止,然后再启动。
在检测的时候,使用kill -0 去检测进程,返回0表示已经启动,返回其他则表示未启动。














 232
232











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









