







python包版本:
selenium==4.14.0
PyAutoGUI==0.9.54
pyppeteer==1.0.2PS:若瀏覽器驅動只啓動一個,高并發時會導致數據紊亂,調用瀏覽器時使用鎖可解決
1、HTML字符串用浏览器打开样式
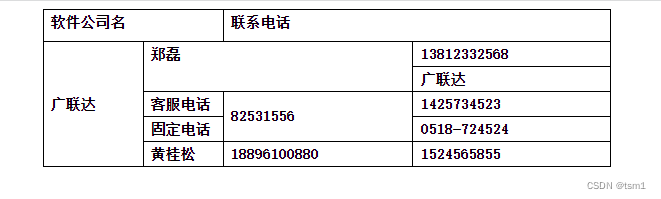
2、拆分单元格结果

3、思想:根据selenium获取每个td的坐标,如下:
![]()
3.1、高效代码替换:
# 这个速度太慢了
list_trs = []
for i, tr in enumerate(self.browser.find_elements(by=By.TAG_NAME, value='tr')):
if not tr.is_displayed(): continue
tds = [{"rect": td.rect, "content": td.text.strip()} for td in tr.find_elements(By.CSS_SELECTOR, 'th,td') if
td.is_displayed()]
if not tds: continue
list_trs.append(sorted(tds, key=lambda td: td['rect']['x'])) # 一个tr里,有些用td,有些用th
# 秒返回,增加对隐藏标签处理
list_trs = self.browser.execute_script('''
var trs = document.querySelectorAll('tr');
var dataByGroup = [];
trs.forEach(function(tr) {
// 检查行是否可见
if (window.getComputedStyle(tr).display !== 'none') {
var tds = tr.querySelectorAll('td, th');
var data = [];
tds.forEach(function(td) {
// 检查单元格是否可见
if (window.getComputedStyle(td).display !== 'none') {
var rect = td.getBoundingClientRect();
var tdData = {
'content': td.textContent.trim(),
'rect': {
'height': rect.height,
'width': rect.width,
'x': rect.left,
'y': rect.top,
}
};
data.push(tdData);
}
});
// 检查行中是否有可见单元格
if (data.length > 0) {
dataByGroup.push(data);
}
}
});
return dataByGroup;
''')
4、实现代码——2023.11.01更新
# -*-coding:utf-8 -*-
"""
# File : assemble_table.py
# Time :2023/10/25 15:01
# Author :tsm
# version :python 3.8
# Des :
"""
import time
import urllib
from copy import deepcopy
import pyautogui
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
class AssembleTable(object):
affect_x, affect_y = 2.0, 2.0 # x、y方向上允许的偏差,如第(0,0)和第(1,0)两个标签最右边的y坐标之间的差距允许在 0~affect_y 之内
def __init__(self, html, repeat_x=True, repeat_y=True):
self.html = html
self.repeat_x = repeat_x # 拆分单元格时,在x方向上是否复制被拆分单元格内容
self.repeat_y = repeat_y # 拆分单元格时,在y方向上是否复制被拆分单元格内容
self.browser = self.init_driver()
@staticmethod
def init_driver():
opts = Options()
driver_width, driver_height = pyautogui.size() # 通过pyautogui方法获得屏幕尺寸
opts.add_argument('--window-size=%s,%s' % (driver_width, driver_height)) # 设置浏览器窗口大小
opts.add_argument('--headless')
opts.add_argument('--no-sandbox')
return webdriver.Chrome(options=opts)
@staticmethod
def _x_tds(list_trs: list) -> list:
"""
计算表格的tr中,每个td的x坐标
@param list_trs:
@return:
"""
rect = list_trs[-1][-1]['rect']
return sorted(set([td['rect']['x'] for tr in list_trs for td in tr])) + [rect['x'] + rect['width']]
@staticmethod
def _y_tds(list_trs: list) -> list:
"""
计算表格的tr中,每个td的y坐标
每行取的都是y坐标的平均值,
@param list_trs:
@return:
"""
y_tds = sorted(set([sum([td['rect']['y'] for td in tr]) / len(tr) for tr in list_trs]))
return y_tds + [sum([y_tds[-1] + td['rect']['height'] for td in list_trs[-1]]) / len(list_trs[-1])]
@staticmethod
def find_x_scope(x, x_tds: dict):
"""
通过x坐标找出当前td所在范围
@param x:
@param x_tds:
"""
result = None
for k, (x1, x2) in x_tds.items():
if x >= x1 and x <= x2:
result = k
return result
@staticmethod
def update_rect(td: dict, xy=[None, None], wh=[None, None], content=None):
"""
更新当前td的x、y坐标为基准坐标
更新当前td的宽、高
@param td:
@param xy: tuple or list, 指定的x、y坐标, 为None则不处理
@param wh: tuple or list, 指定的宽、高, 为None则不处理
@param content:
"""
rect = td['rect']
x, y = xy
w, h = wh
if x is not None:
rect['x'] = x
if y is not None:
rect['y'] = y
if w is not None:
rect['width'] = w
if h is not None:
rect['height'] = h
if content is not None:
td['content'] = content
td['rect'] = rect
return td
def pre_trs(self, x_tds, y_tds, list_trs=[]):
"""
将传入的 list_trs 不存在的单元格用 None 暂时替代
[[{'rect': {'x': 676, 'y': 40, 'width': 165, 'height': 50}, 'content': '广联达'}, # x_1, 横向第1个单元格
{'rect': {'x': 841, 'y': 40, 'width': 128, 'height': 25}, 'content': '郑磊'}, # x_2
{'rect': {'x': 969, 'y': 40, 'width': 274, 'height': 25}, 'content': '13812332568'}], # x_3
[{'rect': {'x': 841, 'y': 65, 'width': 128, 'height': 25}, 'content': '刘书丹'}, # x_2
{'rect': {'x': 969, 'y': 65, 'width': 274, 'height': 25}, 'content': '18651253807'}]] # x_3
python解析HTML有个特点:上术列表中”广联达“实际纵向跨过了第1行和第2行,即 index_tr=1 和 index_tr=2
@param x_tds: td在x方向上的x坐标集合
@param y_tds: td在y方向上的y坐标集合
@param list_trs:
"""
_x_tds = deepcopy(x_tds)
x_tds = dict([_x, [_x - self.affect_x, _x + self.affect_x]] for _x in x_tds[:-1])
trs_result = []
for i_tr, list_tds in enumerate(list_trs):
y = y_tds[i_tr]
h = y_tds[i_tr + 1] - y
tds_result = dict([[k, None] for k in x_tds])
for j_td, td in enumerate(list_tds): # 此处的list_tds长度与原始的td数量一致
k = self.find_x_scope(x=td['rect']['x'], x_tds=x_tds)
if k is None: raise Exception("数据有问题")
# 当前td的宽度远大于下一x坐标与当前x坐标的差值时,不更新w
w1, h1 = td['rect']['width'], td['rect']["height"]
w2 = _x_tds[j_td + 1] - k
w = w1 if w2 + self.affect_x < w1 else w2
h = h if h1 <= h or (h1 > h and h1 - self.affect_y <= h) else h1
tds_result[k] = self.update_rect(td=td, xy=[k, y], wh=[w, h])
trs_result.append(list(tds_result.values()))
return trs_result
def process_xy(self, x_tds, list_trs=[]):
"""
拆分在x方向合并的单元格,利用y坐标
@param x_tds: td在x方向上的x坐标集合
@param list_trs:
"""
max_tds = len(x_tds) - 1
trs_result = []
for i_tr, list_tds in enumerate(list_trs):
if None not in list_tds and len(list_tds) >= max_tds:
trs_result.append(list_tds)
continue
for j_x in range(1, len(list_tds), 1):
td_pre = list_tds[j_x - 1]
td_cur = list_tds[j_x]
if td_cur is not None or td_pre is None: continue
x1 = td_pre['rect']['x']
x2 = x1 + td_pre['rect']['width']
if x2 > x_tds[j_x] + self.affect_x if self.affect_x > 0 else 1.0:
list_tds[j_x - 1] = self.update_rect(td=deepcopy(td_pre), wh=[x_tds[j_x] - x1, None])
list_tds[j_x] = self.update_rect(td=deepcopy(td_pre),
xy=[x_tds[j_x], None],
wh=[x2 - x_tds[j_x], None],
content=None if self.repeat_x else "")
trs_result.append(list_tds)
return trs_result
def process_yx(self, x_tds, y_tds, list_trs=[]) -> list:
"""
拆分在y方向合并的单元格,利用x坐标
ps: 必须保证第一行的td数量等于最大td数
@param x_tds: td在x方向上的x坐标集合
@param y_tds: td在y方向上的y坐标集合
@param list_trs:
"""
max_tds = len(x_tds) - 1
trs_result = []
for i_tr, list_tds in enumerate(list_trs):
if None not in list_tds and len(list_tds) >= max_tds:
trs_result.append(list_tds)
continue
y_base = y_tds[i_tr] # 当前行左上角y坐标
tds_result = dict([[x, None] for x in x_tds[:-1]])
for j_x, td in enumerate(list_tds):
if td is not None:
tds_result[x_tds[j_x]] = td
continue
# 判断上一行同位置td是否纵向跨单元格
pre_line_td = trs_result[i_tr - 1][j_x] # 上一行同位置的td
rect = pre_line_td['rect']
h1 = rect['height']
y1 = rect['y'] + h1 # 上一行同位置td左下角y坐标
if y1 <= y_base or (y1 > y_base and y1 - self.affect_y <= y_base):
pre_line_td = {"rect": {"height": y_tds[i_tr + 1] - y_base, # 当前行td的高度
"width": rect['width'],
"x": rect['x'],
"y": y_base},
"content": ""}
tds_result[x_tds[j_x]] = self.update_rect(td=deepcopy(pre_line_td),
xy=[None, y_base],
wh=[None, h1 - y_base + y_tds[i_tr - 1]],
content=None if self.repeat_y else "")
trs_result.append(list(tds_result.values()))
return trs_result
def assemble(self):
# 通过html字符串打开 方式一 慢
# data_uri = "data:text/html;charset=utf-8," + urllib.parse.quote(self.html)
# self.browser.get(data_uri)
# 通过html字符串打开 方式二 快
self.browser.execute_script("document.open(); document.write(arguments[0]); document.close();", self.html)
list_trs = []
for i, tr in enumerate(self.browser.find_elements(by=By.TAG_NAME, value='tr')):
tds = []
for td in tr.find_elements(by=By.TAG_NAME, value='td'):
tds.append({"rect": td.rect, "content": td.text.strip()})
list_trs.append(tds)
# print(list_trs)
x_tds, y_tds = self._x_tds(list_trs=list_trs), self._y_tds(list_trs=list_trs)
list_trs = self.pre_trs(x_tds=x_tds, y_tds=y_tds, list_trs=list_trs)
xy = self.process_xy(x_tds=x_tds, list_trs=list_trs)
yx = self.process_yx(x_tds=x_tds, y_tds=y_tds, list_trs=xy)
for i, tr in enumerate(yx):
tr = [str(i)] + [td['content'] if td is not None else "" for td in tr]
print(" --|-- ".join(tr))
if __name__ == '__main__':
with open(r'C:/Users/Administrator/Desktop/9.html', 'r', encoding="utf-8") as f:
html = f.read()
obj = AssembleTable(html=html, repeat_x=True, repeat_y=True)
obj.assemble()
obj.browser.quit()
5、更轻量级的获取坐标方式
# -*-coding:utf-8 -*-
"""
# File : testM.py
# Time :2023/8/11 11:04
# Author :tsm
# version :python 3.8
# Des :
"""
import asyncio
import pyautogui
from pyppeteer import launch
driver_width, driver_height = pyautogui.size()
async def get_element_position(browser, html_content, tag_selector):
page = await browser.newPage()
await page.setContent(html_content)
elements = await page.querySelectorAll(tag_selector)
if not elements:
await page.close()
raise ValueError(f"No element found for selector: {tag_selector}")
# boundingBox = await elements[0].boundingBox()
boundingBox = [(await ele.boundingBox(), str(await page.evaluate('(element) => element.textContent', ele)).strip()) for ele in elements]
map_tds = []
for i, ele in enumerate(elements):
map_tds.append({"rect": await ele.boundingBox(), "index_tr": i, "content": str(await page.evaluate('(element) => element.textContent', ele)).strip()})
await page.close()
return map_tds # {'x': ..., 'y': ..., 'width': ..., 'height': ...}
async def main():
browser = await launch(headless=True, defaultViewport={'width': driver_width, 'height': driver_height})
element_position = await get_element_position(browser, html_content, 'td')
# 在此处使用或打印 element_position
# print(element_position)
for res in element_position:
print(res)
await browser.close()
if __name__ == '__main__':
with open(r'C:/Users/Administrator/Desktop/2.html', 'r', encoding="utf-8") as f:
html_content = f.read()
# 调用 main 函数
asyncio.get_event_loop().run_until_complete(main())6、另外一种更准确拆分思路:
让我快活一下我就告诉你
ps:很少看博客,随缘回复,确实有另外一种方式,是我在测试是否有bug的时候发现的,提示一下利用css属性
7、处理嵌套表格
# -*-coding:utf-8 -*-
"""
# File : assemble_table.py
# Time :2023/10/25 15:01
# Author :tsm
# version :python 3.8
# Des :
"""
import re
import urllib
import pyautogui
import numpy as np
from copy import deepcopy
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
class AssembleTable(object):
affect_x, affect_y = 2.0, 2.0 # x、y方向上允许的偏差,如第(0,0)和第(1,0)两个标签最右边的y坐标之间的差距允许在 0~affect_y 之内
placeholder = 'NaN' # 单元格为空时用此代替
def __init__(self, html, repeat_x=True, repeat_y=True):
self.html = html
self.repeat_x = repeat_x # 拆分单元格时,在x方向上是否复制被拆分单元格内容
self.repeat_y = repeat_y # 拆分单元格时,在y方向上是否复制被拆分单元格内容
self.browser = self.init_driver()
@staticmethod
def init_driver():
opts = Options()
driver_width, driver_height = pyautogui.size() # 通过pyautogui方法获得屏幕尺寸
opts.add_argument('--window-size=%s,%s' % (driver_width, driver_height)) # 设置浏览器窗口大小
opts.add_argument('--headless')
opts.add_argument('--no-sandbox')
return webdriver.Chrome(options=opts)
@staticmethod
def _x_tds(list_trs: list) -> list:
"""
计算表格的tr中,每个td的x坐标
@param list_trs:
@return:
"""
if not list_trs: return []
rect = list_trs[-1][-1]['rect']
return sorted(set([td['rect']['x'] for tr in list_trs for td in tr])) + [rect['x'] + rect['width']]
@staticmethod
def _y_tds(list_trs: list) -> list:
"""
计算表格的tr中,每个td的y坐标
每行取的都是y坐标的平均值,
@param list_trs:
@return:
"""
if not list_trs: return []
y_tds = sorted(set([sum([td['rect']['y'] for td in tr]) / len(tr) for tr in list_trs]))
return y_tds + [sum([y_tds[-1] + td['rect']['height'] for td in list_trs[-1]]) / len(list_trs[-1])]
@staticmethod
def _xy_tds(table_parent: dict, table_child: dict):
"""
针对处理好的嵌套表格列表
计算某个单元格 (i, j) 在x、y方向上应该被划分成几行几列
@param table_parent:
@param table_child:
"""
xy_tds = {}
k_parent, parent = list(table_parent.items())[0]
for k_child, table in table_child.items():
i, j = np.where(np.array(parent['trs']) == k_child) # 查找当前表格在父表格的单元格
i, j = f"row_{int(i)}", f"col_{int(j)}"
trs = table['trs']
trs_child = np.array(trs)
num_row, num_col = trs_child.shape # 获取当前表格有多少行、多少列
row, col = xy_tds.get(i, []), xy_tds.get(j, [])
row.append(num_row)
col.append(num_col)
xy_tds.update({i: row, j: col})
for k, v in xy_tds.items():
xy_tds[k] = max(v)
return xy_tds
@staticmethod
def find_x_scope(x, x_tds: dict):
"""
通过x坐标找出当前td所在范围
@param x:
@param x_tds:
"""
result = None
for k, (x1, x2) in x_tds.items():
if x >= x1 and x <= x2:
result = k
return result
@staticmethod
def update_rect(td: dict, xy=[None, None], wh=[None, None], content=None):
"""
更新当前td的x、y坐标为基准坐标
更新当前td的宽、高
@param td:
@param xy: tuple or list, 指定的x、y坐标, 为None则不处理
@param wh: tuple or list, 指定的宽、高, 为None则不处理
@param content:
"""
rect = td['rect']
x, y = xy
w, h = wh
if x is not None:
rect['x'] = x
if y is not None:
rect['y'] = y
if w is not None:
rect['width'] = w
if h is not None:
rect['height'] = h
if content is not None:
td['content'] = content
td['rect'] = rect
return td
def pre_trs(self, x_tds, y_tds, list_trs=[]):
"""
将传入的 list_trs 不存在的单元格用 None 暂时替代
[[{'rect': {'x': 676, 'y': 40, 'width': 165, 'height': 50}, 'content': '广联达'}, # x_1, 横向第1个单元格
{'rect': {'x': 841, 'y': 40, 'width': 128, 'height': 25}, 'content': '郑磊'}, # x_2
{'rect': {'x': 969, 'y': 40, 'width': 274, 'height': 25}, 'content': '13812332568'}], # x_3
[{'rect': {'x': 841, 'y': 65, 'width': 128, 'height': 25}, 'content': '刘书丹'}, # x_2
{'rect': {'x': 969, 'y': 65, 'width': 274, 'height': 25}, 'content': '18651253807'}]] # x_3
python解析HTML有个特点:上术列表中”广联达“实际纵向跨过了第1行和第2行,即 index_tr=1 和 index_tr=2
@param x_tds: td在x方向上的x坐标集合
@param y_tds: td在y方向上的y坐标集合
@param list_trs:
"""
_x_tds = deepcopy(x_tds)
x_tds = dict([_x, [_x - self.affect_x, _x + self.affect_x]] for _x in x_tds[:-1])
trs_result = []
for i_tr, list_tds in enumerate(list_trs):
y = y_tds[i_tr]
h = y_tds[i_tr + 1] - y
tds_result = dict([[k, None] for k in x_tds])
for j_td, td in enumerate(list_tds): # 此处的list_tds长度与原始的td数量一致
k = self.find_x_scope(x=td['rect']['x'], x_tds=x_tds)
if k is None: raise Exception("数据有问题")
# 当前td的宽度远大于下一x坐标与当前x坐标的差值时,不更新w
w1, h1 = td['rect']['width'], td['rect']["height"]
w2 = _x_tds[j_td + 1] - k
w = w1 if w2 + self.affect_x < w1 else w2
h = h if h1 <= h or (h1 > h and h1 - self.affect_y <= h) else h1
tds_result[k] = self.update_rect(td=td, xy=[k, y], wh=[w, h])
trs_result.append(list(tds_result.values()))
return trs_result
def process_xy(self, x_tds, list_trs=[]):
"""
拆分在x方向合并的单元格,利用y坐标
@param x_tds: td在x方向上的x坐标集合
@param list_trs:
"""
max_tds = len(x_tds) - 1
trs_result = []
for i_tr, list_tds in enumerate(list_trs):
if None not in list_tds and len(list_tds) >= max_tds:
trs_result.append(list_tds)
continue
for j_x in range(1, len(list_tds), 1):
td_pre = list_tds[j_x - 1]
td_cur = list_tds[j_x]
if td_cur is not None or td_pre is None: continue
x1 = td_pre['rect']['x']
x2 = x1 + td_pre['rect']['width']
if x2 > x_tds[j_x] + self.affect_x if self.affect_x > 0 else 1.0:
list_tds[j_x - 1] = self.update_rect(td=deepcopy(td_pre), wh=[x_tds[j_x] - x1, None])
list_tds[j_x] = self.update_rect(td=deepcopy(td_pre),
xy=[x_tds[j_x], None],
wh=[x2 - x_tds[j_x], None],
content=None if self.repeat_x else "")
trs_result.append(list_tds)
return trs_result
def process_yx(self, x_tds, y_tds, list_trs=[]) -> list:
"""
拆分在y方向合并的单元格,利用x坐标
ps: 必须保证第一行的td数量等于最大td数
@param x_tds: td在x方向上的x坐标集合
@param y_tds: td在y方向上的y坐标集合
@param list_trs:
"""
max_tds = len(x_tds) - 1
trs_result = []
for i_tr, list_tds in enumerate(list_trs):
if None not in list_tds and len(list_tds) >= max_tds:
trs_result.append(list_tds)
continue
y_base = y_tds[i_tr] # 当前行左上角y坐标
tds_result = dict([[x, None] for x in x_tds[:-1]])
for j_x, td in enumerate(list_tds):
if td is not None:
tds_result[x_tds[j_x]] = td
continue
# 判断上一行同位置td是否纵向跨单元格
pre_line_td = trs_result[i_tr - 1][j_x] # 上一行同位置的td
rect = pre_line_td['rect']
h1 = rect['height']
y1 = rect['y'] + h1 # 上一行同位置td左下角y坐标
if y1 <= y_base or (y1 > y_base and y1 - self.affect_y <= y_base):
pre_line_td = {"rect": {"height": y_tds[i_tr + 1] - y_base, # 当前行td的高度
"width": rect['width'],
"x": rect['x'],
"y": y_base},
"content": ""}
tds_result[x_tds[j_x]] = self.update_rect(td=deepcopy(pre_line_td),
xy=[None, y_base],
wh=[None, h1 - y_base + y_tds[i_tr - 1]],
content=None if self.repeat_y else "")
trs_result.append(list(tds_result.values()))
return trs_result
def assemble(self, table):
"""
@param table: 单独的table
@return:
"""
def _get_text(list_trs: list) -> list:
results = []
for i, tr in enumerate(list_trs):
tr = [re.sub(r"\n+", "\n", td['content']) if td['content'] else self.placeholder for td in tr]
if not any(tr): continue
results.append(tr)
return results
# 通过html字符串打开 方式一 慢
# data_uri = "data:text/html;charset=utf-8," + urllib.parse.quote(table)
# self.browser.get(data_uri)
# 通过html字符串打开 方式二 快
self.browser.execute_script("document.open(); document.write(arguments[0]); document.close();", table)
list_trs = []
for i, tr in enumerate(self.browser.find_elements(by=By.TAG_NAME, value='tr')):
tds = []
for td in tr.find_elements(by=By.TAG_NAME, value='td') + tr.find_elements(by=By.TAG_NAME, value='th'):
tds.append({"rect": td.rect, "content": td.text.strip()})
if not tds: continue
# list_trs.append(tds)
list_trs.append(sorted(tds, key=lambda td: td['rect']['x'])) # 一个tr里,有些用td,有些用th
# print(list_trs)
# 如果表格是标准的,直接返回
if len(set([len(tr) for tr in list_trs])) == 1:
return _get_text(list_trs=list_trs)
x_tds, y_tds = self._x_tds(list_trs=list_trs), self._y_tds(list_trs=list_trs)
list_trs = self.pre_trs(x_tds=x_tds, y_tds=y_tds, list_trs=list_trs)
xy = self.process_xy(x_tds=x_tds, list_trs=list_trs)
yx = self.process_yx(x_tds=x_tds, y_tds=y_tds, list_trs=xy)
return _get_text(list_trs=yx)
def split_table(self, tables):
"""
通过bs4 将嵌套表格拆解,每个表格通过 assemble() 返回列表
@param tables:
@return:
"""
len_tables = len(tables)
if len_tables == 0: return {}
results, record_child = {}, {}
tables = tables[::-1]
for i, table in enumerate(tables):
parent = table.find_parent('table')
k, k_parent = f"[㊚>{i}<㊛]", None
if parent is not None:
k_parent = f"[㊚>{tables.index(parent)}<㊛]"
table.replace_with(k)
item = record_child.get(k_parent, [])
item.append(k)
record_child[k_parent] = item
results[k] = {"parent": k_parent, "child": record_child.get(k, []), "index": k, "title": "",
'trs': self.assemble(table=str(table))}
return results
def process_group_xy(self, table_parent: dict, xy_tds: dict):
"""
x方向上拆分单元格
@param table_parent:
@param xy_tds:
"""
results = []
for k, table in table_parent.items():
for i, tr in enumerate(table['trs']):
trs = []
for j, td in enumerate(tr):
num_col = xy_tds.get(f"col_{j}", 0)
num_col = num_col - 1 if num_col > 1 else num_col
if re.findall(r'\[㊚>\d+<㊛\]', td):
trs.extend([td] + [td] * num_col)
continue
trs.extend([td] + [td if self.repeat_x else self.placeholder] * num_col)
results.append(trs)
table_parent[k].update({"trs": results, "child": []})
break
return table_parent
def process_group_yx(self, table_parent: dict, table_child: dict, xy_tds: dict):
"""
y方向上拆分单元格
@param table_parent:
@param table_child:
@param xy_tds:
"""
results, k_parent = [], None
for k, table in table_parent.items():
k_parent = k
for i, tr in enumerate(table['trs']):
intersection = set(table_child.keys()) & set(tr)
if not intersection:
results.append(tr)
continue
trs = {}
num_row = xy_tds.get(f"row_{i}", 0)
num_row = num_row - 1 if num_row > 1 else num_row
for j, td in enumerate(tr):
li = trs.get(j, [])
if re.findall(r'\[㊚>\d+<㊛\]', td):
li.extend([td] + [td] * num_row)
trs[j] = li
continue
li.extend([td] + [td if self.repeat_y else self.placeholder] * num_row)
trs[j] = li
results.extend(np.array(list(trs.values())).transpose().tolist())
break
# 利用numpy将子单元格填入父表格
for k_child, table in table_child.items():
table = np.array(table['trs'])
num_row, num_col = table.shape
num_row, num_col = num_row - 1, num_col - 1
x_base, y_base = -1, -1
_x, _y = np.where(np.array(results) == k_child)
for i, (x, y) in enumerate(zip(_x, _y)):
# 这里的x,y对应多少行、多少列
if i == 0:
x_base, y_base = x, y
x_child, y_child = x - x_base, y - y_base
if x_child <= num_row and y_child <= num_col:
results[x][y] = table[x_child, y_child]
continue
if y_child > num_col and x_child <= num_row:
results[x][y] = table[x_child, num_col] if self.repeat_x else self.placeholder
if x_child > num_row and y_child <= num_col:
results[x][y] = table[num_row, y_child] if self.repeat_y else self.placeholder
# if x_child > num_row and y_child > num_col:
# if self.repeat_x and self.repeat_y:
# results[x][y] = table[num_row, num_row]
# elif self.repeat_x and not self.repeat_y:
# results[x][y] = results[x][y - 1]
# else:
# results[x][y] = results[x - 1][y]
table_parent[k_parent].update({"trs": results, "child": []})
return table_parent
def main(self, tables_bs4):
"""
@param tables_bs4:
"""
tables = obj.split_table(tables=tables_bs4)
results = {}
for k, table in tables.items():
parent, child = table['parent'], table['child']
if parent is None and not child: # 表示该表格只有一个
result = {k: table}
result.update(results)
results = result
continue
if not child: continue # 表示该表格是子表格
table_child, table_parent = {}, {k: table}
for k_child in child:
table_child[k_child] = tables[k_child]
xy_tds = obj._xy_tds(table_parent=table_parent, table_child=table_child)
table_parent = obj.process_group_xy(table_parent=table_parent, xy_tds=xy_tds)
table_parent = obj.process_group_yx(table_parent=table_parent, table_child=table_child, xy_tds=xy_tds)
if parent is None:
table_parent.update(results)
results = table_parent
return results
if __name__ == '__main__':
with open(r'C:/Users/Administrator/Desktop/1-4-2.html', 'r', encoding="utf-8") as f:
html = f.read()
obj = AssembleTable(html=html, repeat_x=True, repeat_y=True)
soup = BeautifulSoup(html, 'html.parser')
try:
results = obj.main(tables_bs4=soup.find_all('table'))
for k, table in results.items():
for tr in table['trs']:
print("\t-|-\t".join(tr))
print("\n")
print("-" * 100)
finally:
obj.browser.quit()
8、bug修复:隐藏单元格的rect各项都为空
def process_yx(self, x_tds, y_tds, list_trs=[]) -> list:
"""
拆分在y方向合并的单元格,利用x坐标
ps: 必须保证第一行的td数量等于最大td数
@param x_tds: td在x方向上的x坐标集合
@param y_tds: td在y方向上的y坐标集合
@param list_trs:
"""
max_tds = len(x_tds) - 1
trs_result = []
td_default = {'rect': {'height': -1, 'width': -1, 'x': -1, 'y': -1}, 'content': ''}
for i_tr, list_tds in enumerate(list_trs):
if None not in list_tds and len(list_tds) >= max_tds:
trs_result.append(list_tds)
continue
y_base = y_tds[i_tr] # 当前行左上角y坐标
tds_result = dict([[x, None] for x in x_tds[:-1]])
for j_x, td in enumerate(list_tds):
if td is not None:
tds_result[x_tds[j_x]] = td
continue
# 判断上一行同位置td是否纵向跨单元格,上一行同位置的td
pre_line_td = trs_result[i_tr - 1][j_x] if i_tr != 0 else td_default
# 如果第一个tr中就有None;如果上一行是 td_default,则当前行也是td_default
if (td is None and i_tr == 0) or len(set(pre_line_td['rect'].values())) == 1:
tds_result[x_tds[j_x]] = td_default
continue
rect = pre_line_td['rect']
h1 = rect['height']
y1 = rect['y'] + h1 # 上一行同位置td左下角y坐标
if y1 <= y_base or (y1 > y_base and y1 - self.affect_y <= y_base):
pre_line_td = {"rect": {"height": y_tds[i_tr + 1] - y_base, # 当前行td的高度
"width": rect['width'],
"x": rect['x'],
"y": y_base},
"content": ""}
tds_result[x_tds[j_x]] = self.update_rect(td=deepcopy(pre_line_td),
xy=[None, y_base],
wh=[None, h1 - y_base + y_tds[i_tr - 1]],
content=None if self.repeat_y else "")
trs_result.append(list(tds_result.values()))
return trs_result9、ChatGPT推荐从html提取正文-20241206
1. html2text
特点:将 HTML 转换为 Markdown 格式,保留大部分结构,如段落、标题、列表、链接等。
适用场景:需要生成 Markdown 格式的内容,排版接近原网页。
安装:pip install html2text
示例代码:
import html2text
html_content = "<h1>标题</h1><p>段落内容</p><ul><li>列表1</li><li>列表2</li></ul>"
h = html2text.HTML2Text()
h.ignore_links = False # 是否保留链接
text = h.handle(html_content)
print(text)
2. html-text
特点:专注于从 HTML 提取纯文本,支持自动处理空白字符、换行等,生成更优雅的文本排版。
适用场景:需要较好的自动排版效果。
安装:pip install html-text
示例代码:
from html_text import extract_text
html_content = "<html><body><h1>标题</h1><p>段落内容</p><ul><li>列表1</li><li>列表2</li></ul></body></html>"
text = extract_text(html_content)
print(text)

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









