







词法分析
--------
编译原理学习笔记
(1)
一:
词法分析的一般过程是:
1. 语言的词法描述.
2. 根据描述产生正则表达式.
3. 根据正则表达式产生NFA->DFA
4. 根据DFA来构造程序.
参考<<编译原理与实践>> <<编译原理>>(龙书)
例子是根据<<编译原来与实践>>中提供的TINY语言
二: 词法描述
TINY的词法描述:
数: 一个或多个数字.
标识符: 一个或多个字母.(关键字被看作是特殊的标识符)
符号:
+ - = < ( ) ; :=
注释: 在大括号内, 一行或多行
{ … }
空白符: 空格, 制表符, 换行
关键字(属于标识符):
if then else end repeat until read write
三: 由词法描述产生正则表达式
digit = [0-9]
letter = [a-zA-Z]
number = digit+
number = digit+
identifier = letter+
assign =
:=
sign =
+ | - | = | < | ( | ) | ;
comment =
{ other* }
whitespace =
‘ ‘ | ‘/n’ | ‘/t’
四: 由正则表达式产生DFA
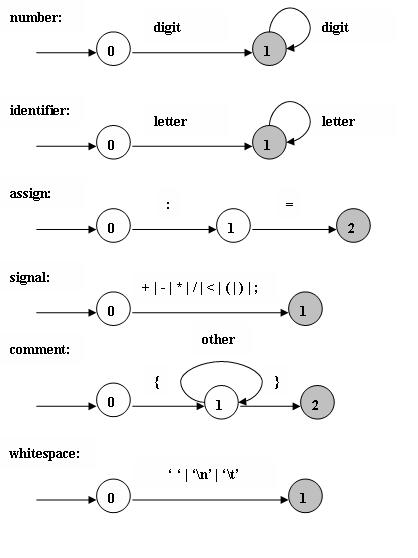
五: 由DFA 合并成整个词法的NFA

六: 由NFA 转换到DFA
参看<<龙书>>中的方法(子集构造法):
{0}~表示{0}的$-闭包($ 表示空集合)
A = {0}~ = {0, 1, 3, 5, 8, 10, 13} B = Adigit = {2}~ = {2, 15}
C = Aletter = {4}~ = {4, 15} D = A: = {6}~ = {6}
E = A+|-|*|/|<|=|(|)|; = {9}~ = {9, 15} F = A{ ={11}~ = {11}
G = A’ ‘|’/n’|’/t’ = {14}~ = {14, 15} H = Bdigit= {2}~ = {2, 15} = B
I = Cletter = {4}~ = {4, 15} = C J = D= = {7}~ = {7, 15}
K = Fother =
{11}~ = {11} = F L = F} = {12}~ = {12, 15}
至此不再有新的集合了, 其中包含开始状态0的集合都为开始状态, 包含终止状态15的集合都为终止状态.
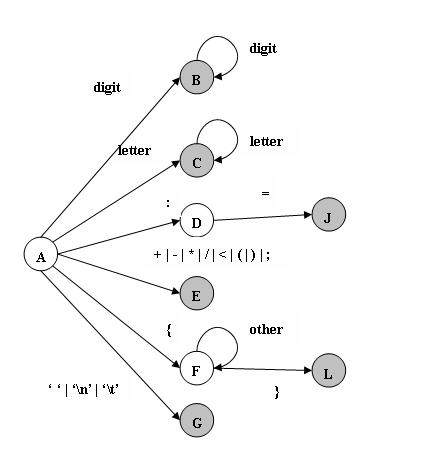
七 DFA 最小化
先将状态分为两个集合: 非终止状态和终止状态集合
非终止状态集合
S1 = {A, D, F}
终止状态集合
S2 = {B, C, J, E, L, G}
对于每一个集合, 选定一个输入(如
digit)是的集合中的状态的转换状态落在不同的集合中, 那么原来的集合就必须被分开(对于某个状态没有该转换的视为一种特殊的转换, 转换后落到一个特殊的集合死集合中, 并且与其他的集合不同), 直到不能再将集合分开为止.
例如: 非终止集合
S1中输入状态
digit,
A转换后的状态落在终止状态集合中,
D F转换后的状态落在了死集合中, 所以必须将
S1
= {A, D, F}分为
S11={A}, S12 = {D, F}依此类推最后的集合为:
S11={A}
S121={D}
S122={F}
S21={B}
S221={C}
S222={J, E, L, G}
重新命名一下
S0 = S11 S1 = S121 S2 = S122 S3 = S21 S4 = S221 S5 = S222
最后的DFA:
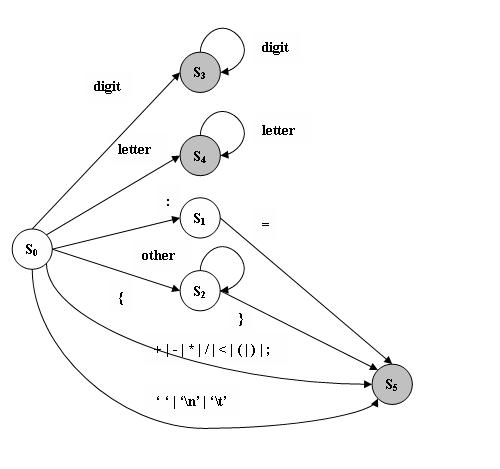
八: 确定中间状态
对于词法的分析, 注释和空白符是被忽略掉地, 所以程序中的注释和空白符不应表示为终止状态, 通过让它们回到开始状态来简单的丢弃它们.
确定词法分析的开始, 中间和接受状态后TINY的DFA:
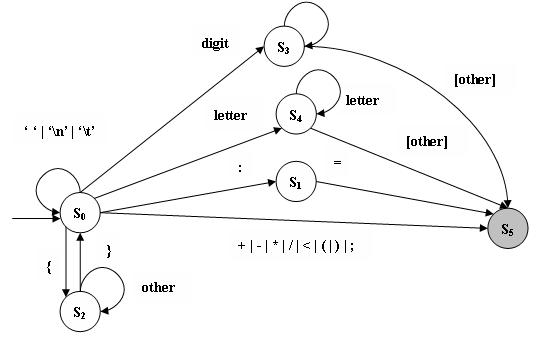
其中
[other]可接受转换以外的转换.
定义程序内部状态
S0 = START S1
= IN_ASSIGN S2 = IN_COMMENT
S3 = IN_NUMBER
S4
= IN_IDENTIFIER S5 = ACCEPT
九 代码示例:
TokenType get_token(void)
{
TokenType token; /* current token */
StateType state = START; /* current state */
int c = 0x00; /* next in buffer */
int is_save = FALSE; /* save flage */
int token_string_index = 0; /* token string index*/
while(state != ACCEPT)
{
c = get_next_char();
is_save = TRUE;
switch(state)
{
case START:
if(isalpha(c))
state = IN_ID;
else if(isdigit(c))
state = IN_NUM;
else if(c == ':')
state = IN_ASSIGN;
else if(c == '{')
{
is_save = FALSE;
state = IN_COMM;
}
else if((c == '/n') || (c == '/t') || (c == ' '))
{
is_save = FALSE;
state = IN_WS;
}
else
{
state = ACCEPT;
switch(c)
{
case '+':
token = PLUS;
break;
case '-':
token = MINUS;
break;
case '*':
token = MULT;
break;
case '/':
token = DIV;
break;
case '<':
token = LT;
break;
case '>':
token = GT;
break;
case '(':
token = LPAREN;
break;
case ')':
token = RPAREN;
break;
case '=':
token = EQ;
break;
case ';':
token = SEMI;
break;
case EOF:
is_save = FALSE;
token = END_FILE;
break;
default:
token = ERROR;
break;
}
}
break;
case IN_NUM:
if(!isdigit(c))
{
is_save = FALSE;
unget_next_char();
state = ACCEPT;
token = NUM;
}
break;
case IN_ID:
if(!isalpha(c))
{
is_save = FALSE;
unget_next_char();
state = ACCEPT;
token = ID;
}
break;
case IN_ASSIGN:
if(c == '=')
{
state = ACCEPT;
token = ASSIGN;
}
else
{
is_save = FALSE;
unget_next_char();
state = ACCEPT;
token = ERROR;
}
break;
case IN_COMM:
is_save = FALSE;
if(c == '}')
{
state = START;
}
else if(c == EOF)
{
state = ACCEPT;
token = END_FILE;
}
break;
case IN_WS:
is_save = FALSE;
if(c == EOF)
{
state = ACCEPT;
token = END_FILE;
}
else if((c != ' ') && (c != '/t') && (c != '/n'))
{
unget_next_char();
state = START;
}
break;
case ACCEPT:
default:
state = ACCEPT;
token = ERROR;
break;
}
if((is_save) && (token_string_index <= MAX_TOKEN_LEN))
token_string[token_string_index++] = (char)c;
if(state == ACCEPT)
{
token_string[token_string_index] = '/0';
if(token == ID) /* key words is a kind of identifier */
token = lookup_keywords();
}
}
#ifdef TRACE_SCAN
if(token == END_FILE)
fprintf(listing, "%4d: ", line_no);
else
fprintf(listing, "/t%d: ", line_no);
print_token(token, token_string);
#endif
return token;
}















 430
430











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









