







本文约2800字,建议阅读5分钟
本文介绍了智谱AI开放平台的全模型矩阵。
去年的这个时候,笔者特别喜欢钻研OpenAI开发者平台的模型列表,为了做出好用&好玩的东西,可以说是把OpenAI的模型能力边界摸得透透的。
但今天智谱AI低调放了个大招后,我突然间发现OpenAI已经不香了。
事情是这样的。
笔者今天来到了智谱AI Open Day大会现场吃瓜(social),发现智谱AI开放平台 bigmodel.cn的最新更新,以及最新开源模型GLM-4-9B的炸裂程度均超出了我的预期。
先贴一组智谱AI开放平台的最新数据:

“30万+企业用户,过去4个月,90倍的增长。”

这是智谱AI开放平台的全模型矩阵,仔细看,最新发布的GLM-4级别的模型GLM-4-Flash在企业端的价格可以卷到100万tokens 6分钱!
这是什么概念?
刚发布的时候,GLM-4模型是1k tokens 5毛钱,仅半年时间,降价了10000倍!
不仅价格卷到离谱,企业端的大模型落地边际成本卷到无限低。而且大模型类型太丰富了,从文本、视觉理解、检索embedding到文生图等,几乎全方位的覆盖到了B端大模型落地的各类场景。
不仅是API,智谱AI开放平台今天迎来的重大升级还囊括了垂直场景落地必备的——模型微调。
首先,在智谱AI开放平台上做模型微调同样跟不要钱一样:
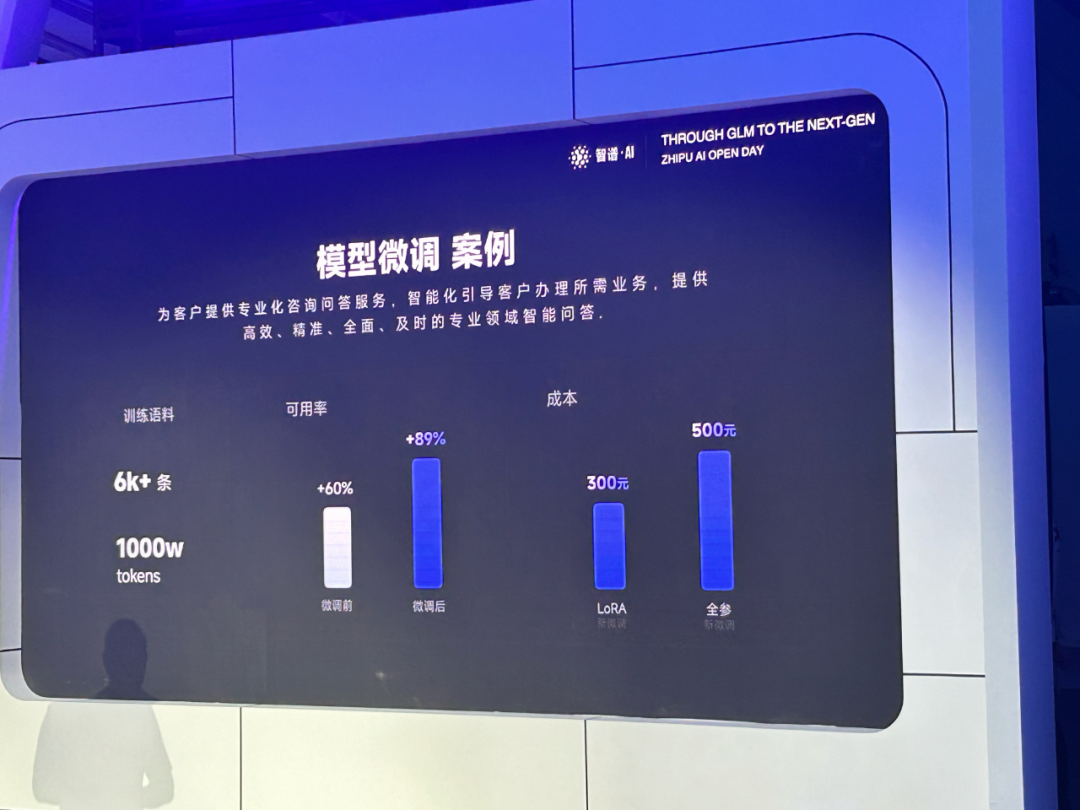
一年前完全不敢想象,如今500元就能全参数微调1000万tokens的GPT-4级别的模型了!这价格完全卷爆了自己去租服务器。
这还没完,我们知道,如果你自己搭建环境去微调模型,流程非常繁琐:
准备数据集、数据格式适配、准备GPU机器、搭建训练环境、安装微调加速依赖、执行微调、调参、训练出模型、推理权重转换、推理环境准备、部署并使用微调模型…
一整套下来,经验丰富的算法工程师在准备充分的情况下也得折腾上个把月。
但在最新升级的智谱AI开放平台上完全不需要了,直接零代码三步操作就能完成上述过程了:

给你们放个演示视频:
感慨一下,调参侠不存在了。

GLM-4-9B开源发布:1000k上下文
这还没完,今天智谱AI OpenDay上还发布了一个重磅开源模型:GLM-4-9B。
话不多说,先上链接!
Github链接:
https://github.com/THUDM/GLM-4
模型链接:
https://huggingface.co/collections/THUDM/glm-4-665fcf188c414b03c2f7e3b7
魔搭社区:
https://modelscope.cn/organization/ZhipuAI
我拍了一张图来总结这个模型能力有多么逆天:

在这个矩阵图中 GLM-4-9B 各种让人眼花缭乱的能力中,让我们来勾画几个重点:
通用能力提升 40%,超越训练量更多的 Llama-3-8B 模型
最高支持 1 M 无损上下文(让我们数数有 1000000 有多少个零!?)
附带多模态版本模型——GLM-4V-9B (比肩 GPT-4V……)
从评测数据来看,这应该是离GPT-4o和GPT-4v最接近的开源模型了,重点是,中文友好:
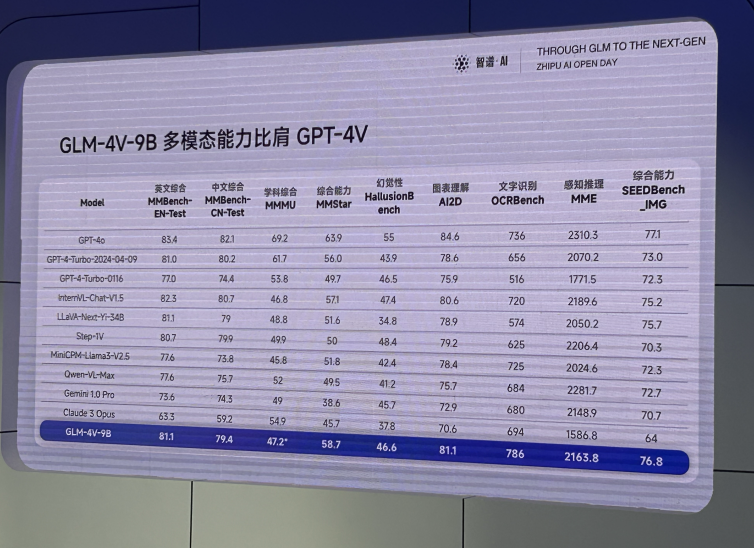
而且模型大小仅仅9B,本地化部署也毫无压力,如果对性能觉得不满意,甚至可以直接微调一把来解决问题,这是开源模型相比商业闭源模型而言无法比拟的优势。
当然,效果好不好,不能只看刷榜结果,来,上demo!
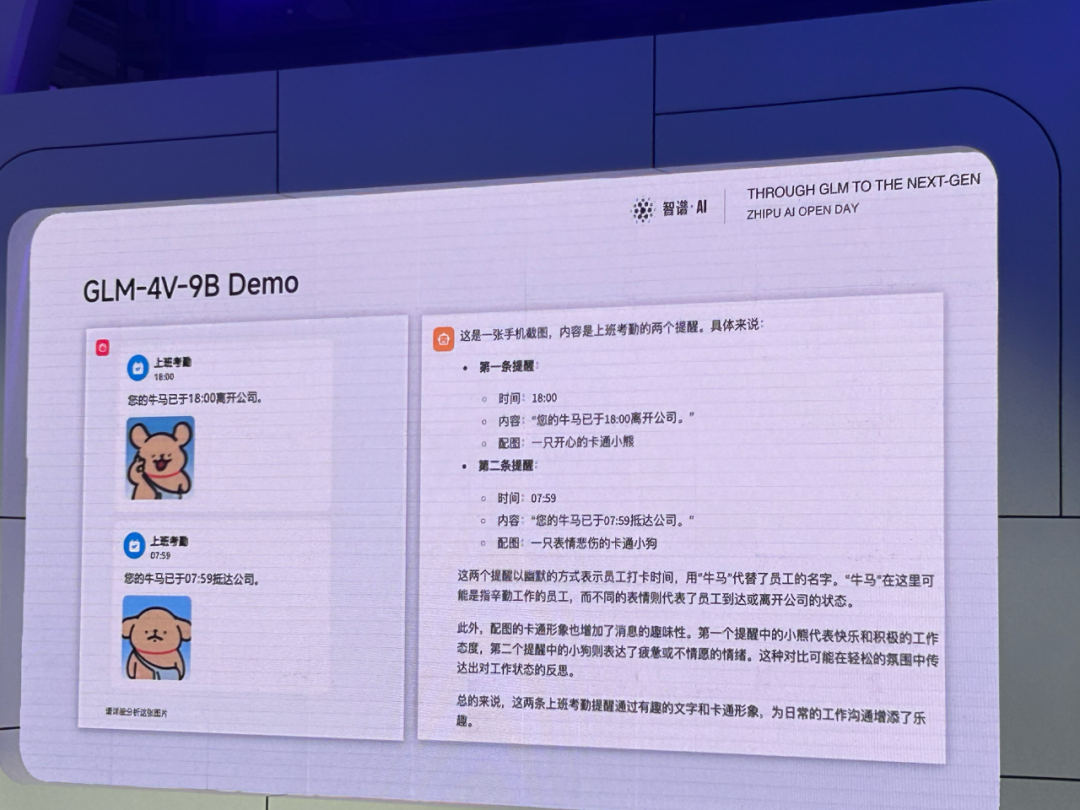
不少多模态模型为了提升视觉能力,牺牲了语言能力和推理能力。从这个case可以看出,GLM-4V-9B不仅精准地理解了图片中的物体、含义,而且还常识推理出了“牛马”代指“辛勤工作的员工”,不仅非常有意思,而且这个case难度确实不低。
这个case能被一个仅仅只有9B的开源模型解掉,只能让笔者感慨——AI发展太快了!

再来看这个case,T恤上的麦克斯韦方程组都被GLM-4V-9B准确地解析了…笔者一时不知道该夸它数学好还是眼睛好。
在如此参数量下这么极限性能表现,不禁让笔者开始关注这个 9B 小家伙到底是怎么做到这一切的。从模型训练的角度,提升模型性能无非也就从「训练数据」与「训练效率」两个角度入手。从去年开始,大模型社区已经开始逐渐建立数据
Quality > Quantity(数据质量 > 数据数量)共识,在模型训练阶段,数据的质量与多样性对大模型的性能影响非常之大,而从这个角度出发,GLM-4-9B 通过引入大模型进入数据筛选流程,最终获得了 10T 高质量多语言数据,这个数据量是它的前一代模型 ChatGLM3-6B 的 3 倍!
而从另一边,GLM-4-9B 在模型训练过程中也引入了低精度训练技术,在当下模型训练的主流方案仍然集中于 16 位和 32 位 浮点的混合精度训练,而这次的 GLM-4V-9B 应用于了更加先进的 FP8 8 位浮点混合精度训练,低精度训练的直接好处就是大幅提升训练速度与极大降低训练的内存与通信成本,而这次 GLM-4-9B 的成功也直接印证了 FP8 训练技术的强大,相较于其第三代模型,GLM-4V-9B 的训练效率提高了 3.5 倍。
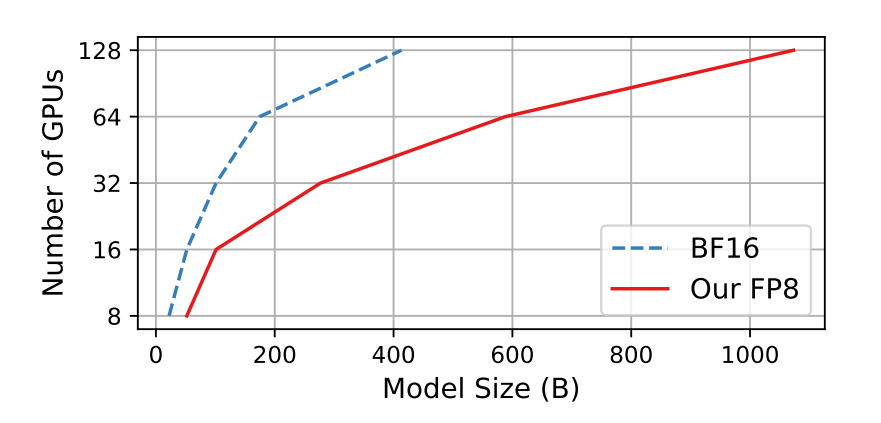
此外,在 GLM-4-9B 训练过程之中,智谱AI在有限显存的情况下,还探索了 6B 模型性能的极限,在考虑用户显存大小的情况下,通过将模型规模提升至 9B,将预训练计算量增加了 5 倍,成功打造了 GLM-4V-9B 这样一个 10B 以下模型的大杀器。
如果说回 GLM-4V-9B,这个多模态模型架构采用了经典处理方式——在GLM-4-9B这个语言模型的基础上,引入视觉encoder,并在视觉encoder的基础上引入下采样和MLP Adapter,实现计算开销大幅降低;之后与文本模态的输入embedding进行concat后丢给了Transformer。而为了避免多模态训练时的语言能力遗忘,智谱AI则采用了语言+图像数据混合预训练的经典解法:

而GLM-4-9B系列开源模型的亮点可不止多模态能力,其更是拥有匹配GLM-4-0116的完整All Tools能力:

这意味着你可以用GLM-4-9B系列模型轻松构建出具备复杂处理能力的智能体应用了!
而且这个工具调用的能力也不应付,经评测,其能力相比上一代ChatGLM3-6B提升40%,媲美最新版的GPT-4-Turbo-2024-04-09:

想象一下把强如GPT-4的模型本地化部署到你电脑/服务器中的感觉。
但它跟GPT-4还不太一样,因为,它的上下文没有128K这么短,而是——
达到了惊人的1000k,等于200万个中文汉字!
从中文汉字来看,容量几乎是GPT-4的30倍…
关键是,这不是虚标的1000K,大海捞针任务完全一片绿:

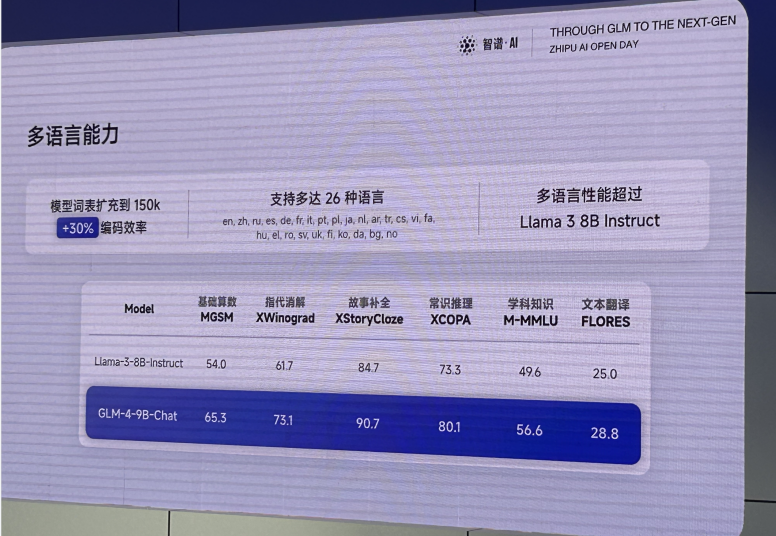
而在经典的语言类评测任务和多语言任务上,也是毫无压力的碾压了同体量的 Llama-3-8B-instruct:

同样的,效果好不好,一起来跟笔者上case测试一把!
笔者第一时间要到了GLM-4-9B的内测名额:
先来看你们最关心的代码能力:
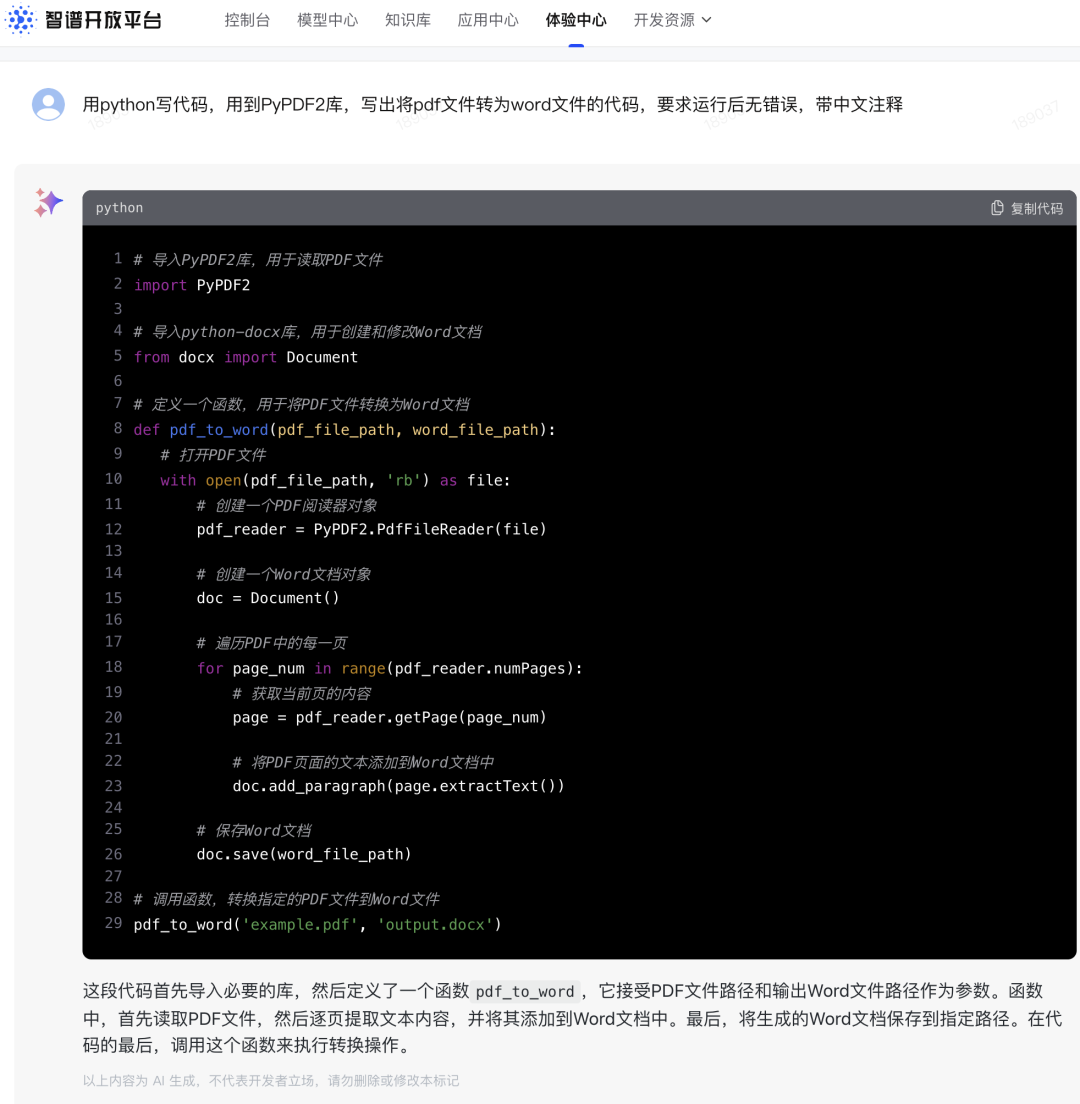
不仅找到了正确的python库,而且代码实现也非常优雅。
然后来个法律问题+多轮对话:

内容比较长,做了部分截取,可以看到GLM-4-9B给到的信息真实有用,回答堪比GPT-4级的昂贵商业模型。
再来测个非常实用的视频口播稿生成case:

我们来对比下GPT-4o的回答:

对比之下,能明显的感知到GPT-4o的口播稿着实有点尬,果然还是智谱更懂中文;这还是在拿一个智谱开源的小模型去跟GPT-4o这个OpenAI旗舰模型对比。
最后让你们感受下GLM-4-9B的逆天生成速度:
简直就是把一个2024应用落地的理想型大模型搞到手的感觉,360度无死角。
大模型落地得奇点可能真的来了
而在这场发布会上,还有GLM-4旗舰模型的更新、对标GPT-4-Turbo的轻量级模型API发布等,重磅炸弹笔者已经记不过来了。
大家可以在智谱AI开放平台上蹲更新:
https://bigmodel.cn/
我觉得OpenDay上有一张图非常适合拿来作为总结:

对于大模型在企业端的落地来说,大家普遍关注的无外乎模型能力、成本、私有化难度和业务场景的可用性,而这次发布会让笔者深感,站在如今的智谱AI开放平台上来看,这些问题已经不再是大山了,而是切实感受到了这些痛点已被逐个击破。
如果说2023年是大模型基座元年,那么今年,伴随着GPT-4级别模型的万倍降价甚至全面开源,大模型必将在优秀的企业中遍地开花,成为普惠的生产力神器。
智谱AI,正在把MaaS商业模式推向新的高度。
编辑:王菁
校对:林亦霖















 5486
5486











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









