







这种错误类型今天第一次使用Scrapy框架,就出现了,找了很多博客中的解决方法,还是不能访问,改了一下execute.py文件的位置就ok了
如图: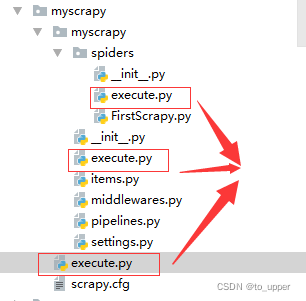
书上说这三个位置放置execute.py文件都可以,我把文件放在第二个目录下,就不会抛出异常错误了。
下面总结一下,出现这种错误的解决方法:
1、修改execute.py文件的位置
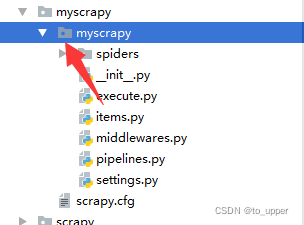
2、类继承scrapy父类CrawlSpider。
# class Test1Spider(scrapy.Spider):
from scrapy.spiders import CrawlSpider
class Test1Spider(CrawlSpider):
# Spider的名称,需要该名称启动Scrapy
name = 'FirstSpider'
# 指定要抓取的Web资源的URL
start_urls = {
'https://www.jd.com'
}
3、带有response参数的函数的函数名改为parse
def parse(self,response):
# 输出日志信息
self.log('hello world')
最近正在学习《Python爬虫技术 深入原理、技术与开发》,点个赞呗~















 8452
8452











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









