









作者Toby,来源公众号:Python风控模型 SimpleImputer缺失数据处理报错解决方案
今天有学员反馈缺失值代码报错,由于sklearn缺失值处理的包升级,下面把官网最新的缺失值处理代码奉上。
参考https://scikit-learn.org/stable/modules/generated/sklearn.impute.SimpleImputer.html
例子
>>> import numpy as np>>> from sklearn.impute import SimpleImputer>>> imp_mean = SimpleImputer(missing_values=np.nan, strategy='mean')>>> imp_mean.fit([[7, 2, 3], [4, np.nan, 6], [10, 5, 9]])SimpleImputer()>>> X = [[np.nan, 2, 3], [4, np.nan, 6], [10, np.nan, 9]]>>> print(imp_mean.transform(X))[[ 7. 2. 3. ][ 4. 3.5 6. ][10. 3.5 9. ]]
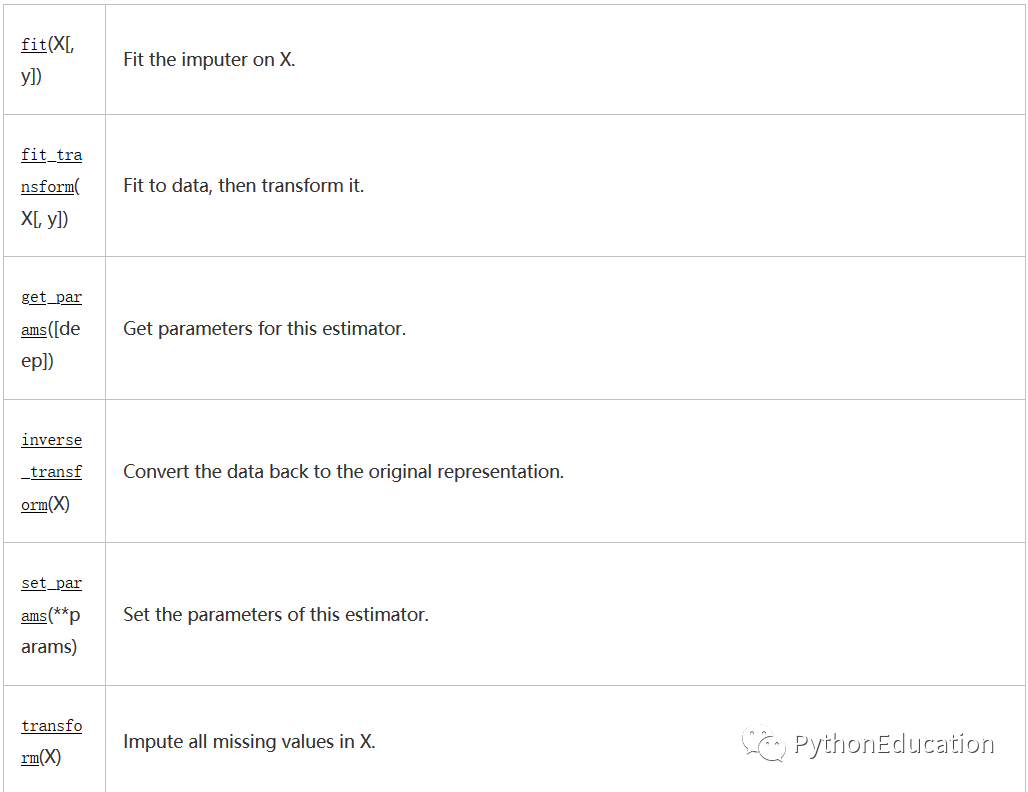
sklearn.impute.SimpleImputer
-
class
sklearn.impute.SimpleImputer(*, missing_values=nan, strategy='mean', fill_value=None, verbose=0, copy=True, add_indicator=False)[source]
Imputation transformer for completing missing values.
Read more in the User Guide.
New in version 0.20: SimpleImputer replaces the previous sklearn.preprocessing.Imputer estimator which is now removed.
-
Parameters
-
-
If X is not an array of floating values;
-
If X is encoded as a CSR matrix;
-
If add_indicator=True.
-
If “mean”, then replace missing values using the mean along each column. Can only be used with numeric data.
-
If “median”, then replace missing values using the median along each column. Can only be used with numeric data.
-
If “most_frequent”, then replace missing using the most frequent value along each column. Can be used with strings or numeric data. If there is more than one such value, only the smallest is returned.
-
If “constant”, then replace missing values with fill_value. Can be used with strings or numeric data.
-
missing_valuesint, float, str, np.nan or None, default=np.nan
-
The placeholder for the missing values. All occurrences of
missing_valueswill be imputed. For pandas’ dataframes with nullable integer dtypes with missing values,missing_valuesshould be set tonp.nan, sincepd.NAwill be converted tonp.nan. -
strategystring, default=’mean’
-
The imputation strategy.
New in version 0.20: strategy=”constant” for fixed value imputation.
-
fill_valuestring or numerical value, default=None
-
When strategy == “constant”, fill_value is used to replace all occurrences of missing_values. If left to the default, fill_value will be 0 when imputing numerical data and “missing_value” for strings or object data types.
-
verboseinteger, default=0
-
Controls the verbosity of the imputer.
-
copyboolean, default=True
-
If True, a copy of X will be created. If False, imputation will be done in-place whenever possible. Note that, in the following cases, a new copy will always be made, even if
copy=False: -
add_indicatorboolean, default=False
-
If True, a
MissingIndicatortransform will stack onto output of the imputer’s transform. This allows a predictive estimator to account for missingness despite imputation. If a feature has no missing values at fit/train time, the feature won’t appear on the missing indicator even if there are missing values at transform/test time.
-
-
Attributes
-
-
statistics_array of shape (n_features,)
-
The imputation fill value for each feature. Computing statistics can result in
np.nanvalues. Duringtransform, features corresponding tonp.nanstatistics will be discarded. -
indicator_
MissingIndicator -
Indicator used to add binary indicators for missing values.
Noneif add_indicator is False.
-















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









