









作者Toby,来源公众号:Python风控模型,SMOTE Tomek非平衡数据处理算法
之前Toby老师讲了非平衡数据处理相关知识,具体内容和链接如下。
imbalanced data机器学习非平衡数据处理
Python非平衡数据处理_SMOTE-ENN 方法
非平衡数据处理ADASYN-基于自适应性的过采样方法
非平衡数据处理SMOTE的改良算法-borderline SMOTE, ADASYN
非平衡数据处理-Tomek link算法
今天介绍的是SMOTE Tomek算法,介绍前我们先了解一下具体背景。
概述
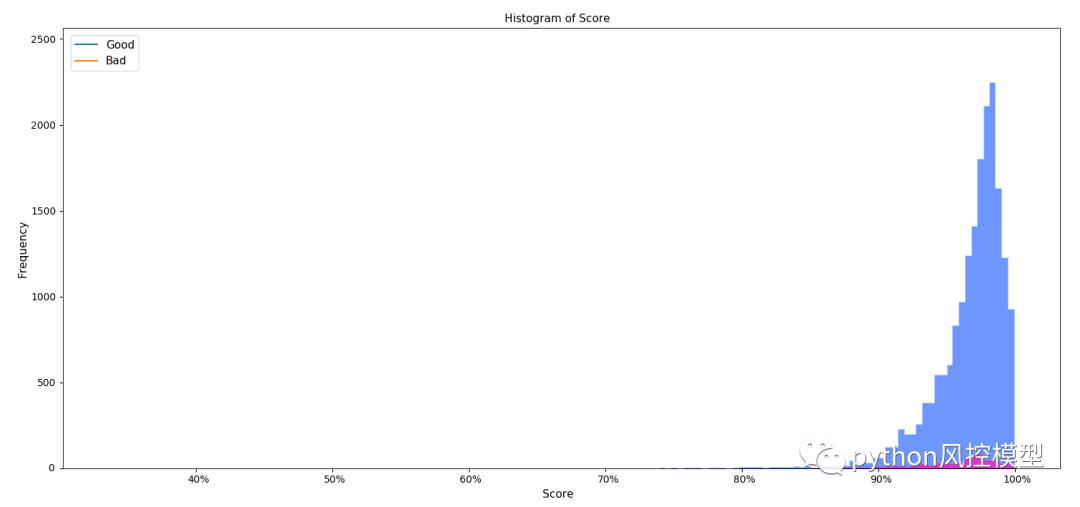
非平衡数据在金融风控领域、反欺诈客户识别、广告智能推荐和生物医疗中普遍存在。一般而言,不平衡数据正负样本的比例差异极大,如在Kaggle竞赛中的桑坦德银行交易预测和IEEE-CIS欺诈检测数据。对模型而言,不均衡数据构建的模型会更愿意偏向于多类别样本的标签。非平衡数据情况下,模型的准确率指标accuracy不具有太大参考价值,模型实际应用价值降低。如下图所示,为在不均衡数据下模型预测的概率分布。
历史背景
20 世纪 90 年代末,当时南佛罗里达大学的研究生 Niesh V Chawla(SMOTE 背后的主要大脑)正在研究二元分类问题。他正在处理乳房 X 光检查图像,他的任务是构建一个分类器,该分类器将像素作为输入,并将其分类为正常像素或癌变像素。当他达到 97% 的分类准确率时,他非常高兴。当他看到 97.6% 的像素都是正常的时,他的快乐是短暂的。
您可能会想,问题出在哪里?有两个问题
-
假设在 100 个像素的样本中,98 个像素是正常的,2 个是癌变的,如果我们编写一个程序,它可以预测任何情况都是正常的。分类准确率是多少?高达98%。程序学会了吗?一点也不。
-
还有一个问题。分类器努力在训练数据中获得良好的性能,并且随着正常观察的增多,它们将更多地专注于学习“正常”类的模式。这就像任何学生知道 98% 的问题来自代数而 2% 来自三角学时会做的那样。他们会安全地忽略三角函数
那么,为什么会出现这个问题,是因为类别的频率或数量之间存在很大的差异。我们称这样的数据集为表现类别不平衡的数据集。正常类称为多数类,稀有类称为少数类。

白色海鸥作为少数群体
这在现实生活中的应用中存在吗?以垃圾邮件检测、假新闻检测、欺诈检测、可疑活动检测、入侵检测等为例,类别不平衡问题就表现出来了。
带来一些平衡的解决方案:
基本方法称为重采样技术。有两种基本方法。
欠采样:-
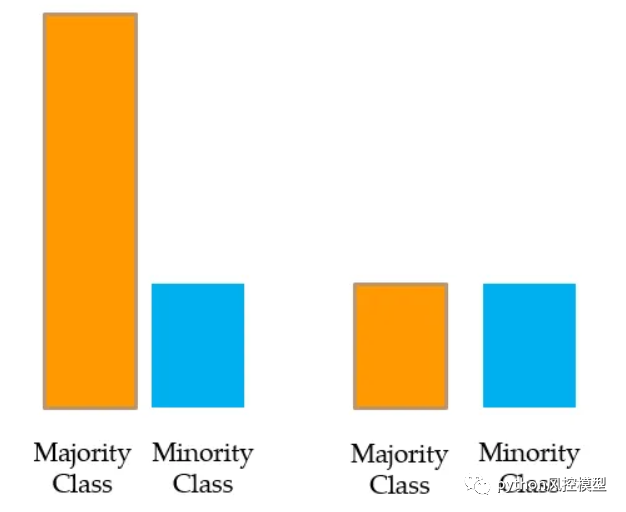
对多数类进行欠采样或下采样
我们从多数类中随机抽取样本,并使其等于少数类的数量。这称为多数类的欠采样或下采样。
问题:忽略或放弃如此多的原始数据并不是一个好主意。
过采样:
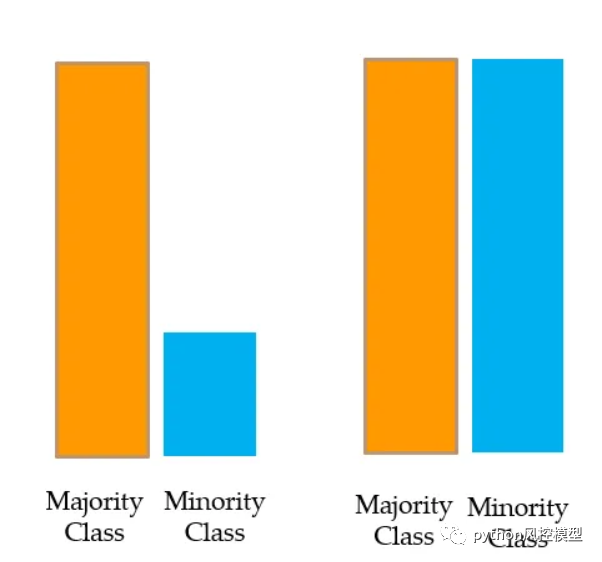
对少数类进行过采样或上采样
在这里,对少数类应用放回抽样,以创建与多数类中一样多的观测值,并且两个类是平衡的。这称为少数类的过采样或上采样。
问题:重复相同的少数类数据会导致过度拟合。
SMOTE-过采样算法

有多种方法可用于对典型分类问题中使用的数据集进行过采样(使用分类算法对一组图像进行分类,给定一组带标签的训练图像)。最常见的技术被称为 SMOTE:合成少数过采样技术。[4]为了说明这种技术是如何工作的,考虑一些训练数据,其中有s 个样本,以及数据特征空间中的f 个特征。请注意,为简单起见,这些特征是连续的。例如,考虑用于分类的鸟类数据集。我们想要对其进行过采样的少数类的特征空间可以是喙长、翼展和重量(都是连续的)。为了过采样,从数据集中取一个样本,并考虑它的k 个最近邻(在特征空间中)。要创建合成数据点,请获取这k 个邻居之一与当前数据点之间的向量。将此向量乘以介于 0 和 1 之间的随机数x。将其添加到当前数据点以创建新的合成数据点。
如果看不懂smote术语解释没关系,我用可视化图解smote原理。
如下图,红色数据是minority class,即占比较小的数据集,一共只有4个。
绿色数据是majority class,即占比较大的数据集,一共13个。
为了训练模型时解决非平衡数据问题,我们使用smote方法。
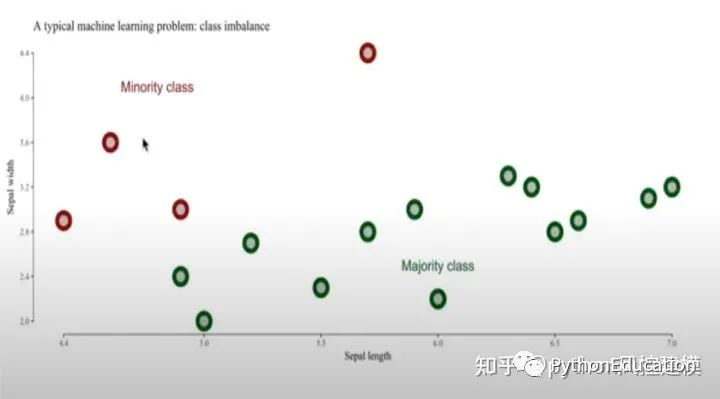
我们通过向量方法链接四个红色点,新的数据(创造的伪数据)就会出现在红色点链接的线上。
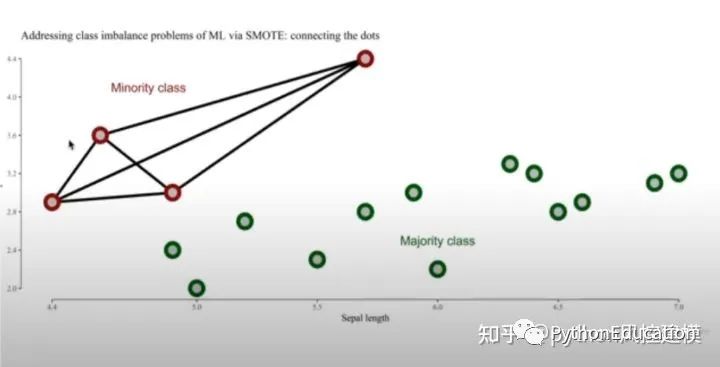
大家看,新创造的8个点出现在红色点链接的线上。这样红色数据集就有12个,蓝色数据集有13个,基本是5:5平衡了。
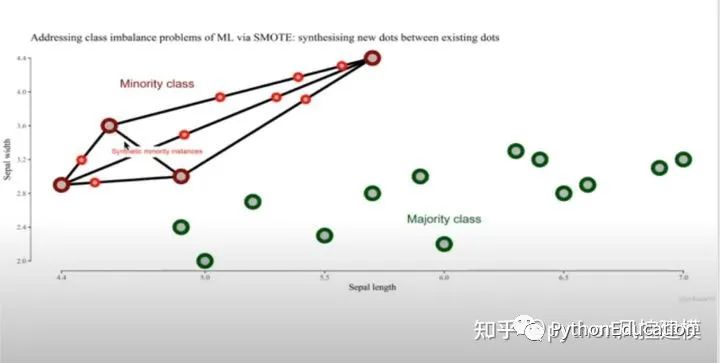
通过上述smote方法,我们解决了非平衡数据问题。
Tomek's link-欠采样方法
Tomek's link是一种用于处理类不平衡数据集的欠采样方法,通过移除近邻的反例样本来改善模型的性能。这种方法可以有效地解决类别不平衡问题,提高分类器的准确性。
Tomek Links是一种欠采样技术,由Ivan Tomek于1976年开发。它是从Condensed Nearest Neighbors (CNN)中修改而来的一种技术。它可以用于找到与少数类数据具有最低欧几里得距离的多数类数据的所需样本,然后将其删除。
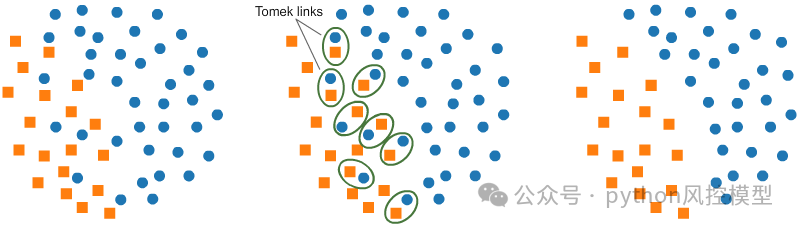
Tomek's link支持多分类器模型。下面是英文原释义:
Tomek's link supports multi-class resampling. A one-vs.-rest scheme is used as originally proposed in.
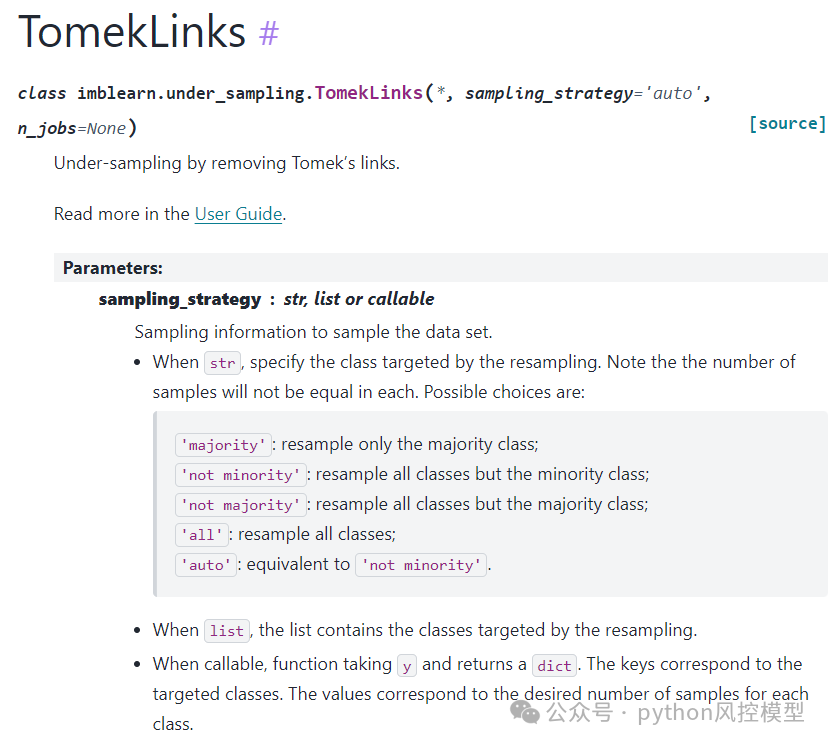
Tomek'slink的参数如下,具体参考链接:https://imbalanced-learn.org/stable/references/generated/imblearn.under_sampling.TomekLinks.html
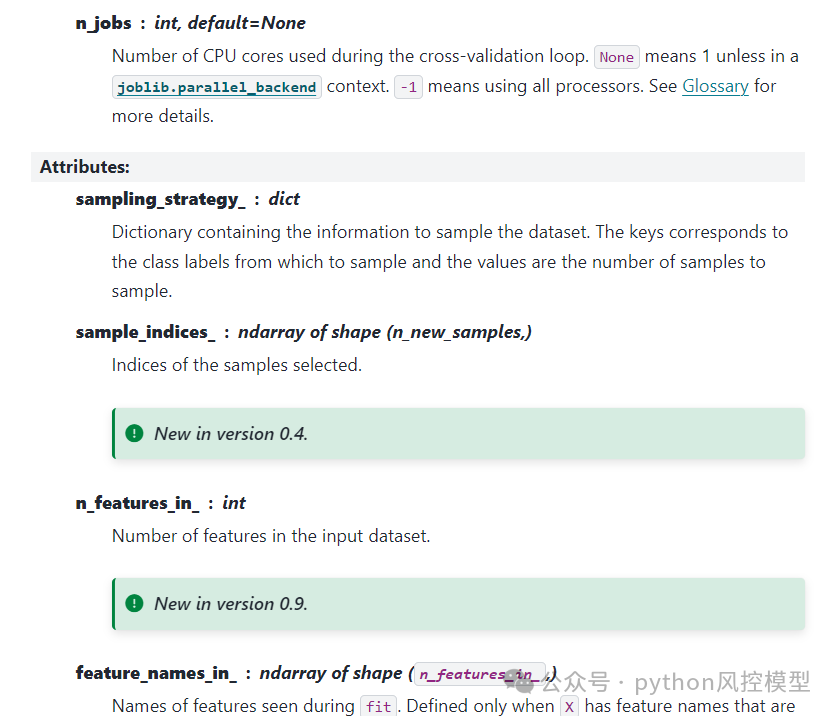
SMOTETomek
当SMOTE和Tomek link结合使用时,可用于进一步改善机器学习模型在不平衡数据集上的性能,通过对少数类进行过采样并同时清理数据集。这种组合技术被称为SMOTETomek。原英文释义如下:
SMOTE (Synthetic Minority Over-sampling Technique) is a popular algorithm used in machine learning for dealing with imbalanced datasets. It works by generating synthetic samples from the minority class to balance out the distribution of classes in the dataset.
Tomek links are pairs of instances that are close to each other but belong to different classes. The Tomek links removal technique is used to clean up the dataset by removing these pairs of instances, making the decision boundary between classes clearer.
When combined, SMOTE and Tomek links can be used to further improve the performance of a machine learning model on imbalanced datasets by oversampling the minority class and cleaning up the dataset at the same time. This combined technique is known as SMOTETomek.SMOTE(Synthetic Minority Over-sampling Technique)
SMOTETomek具体算法是通过对少数类别(异常)进行过采样和对多数类别(正常)进行欠采样的组合,可以比仅对多数类别进行欠采样的方法获得更好的分类器性能。这种方法最早由Batista等人在2003年提出。
SMOTE-Tomek Links的过程如下:
1.开始SMOTE:从少数类别中随机选择数据。
2.计算随机数据与其k个最近邻之间的距离。
3.将差值乘以0到1之间的随机数,然后将结果添加到少数类别中作为合成样本。
4.重复步骤2-3,直到满足所需的少数类别比例(结束SMOTE)。
5.开始Tomek Links:从多数类别中随机选择数据。
6.如果随机数据的最近邻是来自少数类别的数据(即创建Tomek Link),则移除Tomek Link。
Python关于SMOTETomek代码参数如下:

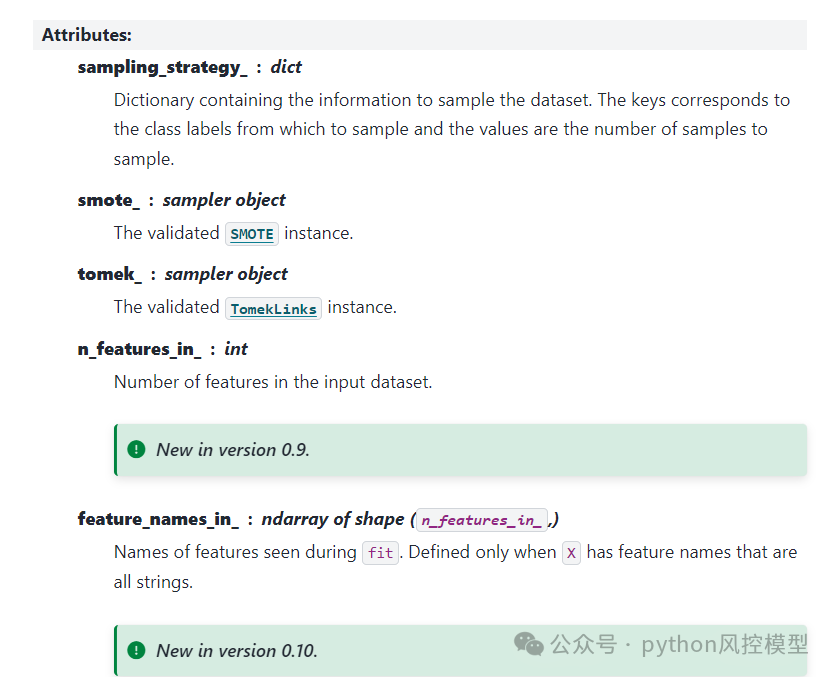
lendingclub实验SMOTETomek VS TomekLinks VS SMOTE
Toby老师用12万大样本的lendingclub数据集来实验SMOTETomek算法,观察是否真的能够提升模型性能。Toby老师实验了三种算法对比SMOTETomek VS TomekLinks VS SMOTE
下图是部分lendingclub数据展示
TomekLinks VS SMOTETomek
通过对比发现TomekLinks和SMOTETomek在不同指标上各有优势。如何选择非平衡算法,取决于你的模型竞赛或业务方对具体哪个指标关注。
如下图SMOTETomek的AUC,f1分数,sensitivity等指标高于TomekLinks。
TomekLinks的accuracy和precision高于SMOTETomek。

SMOTE VS TomekLinks VS SMOTETomek
通过对比发现SMOTE,TomekLinks和SMOTETomek在不同指标上各有优势。
SMOTE的AUC值最高。
TomekLinks的accuracy和precision值最高。
SMOTETomek的AUC,f1分数值最高。

未经过非平衡数据处理 VS SMOTE VS TomekLinks VS SMOTETomek

最后对比未经过非平衡数据处理,SMOTE,TomekLinks和SMOTETomek建模后模型性能。我们发现未经过非平衡数据处理模型的f1分数和accuracy值最高。
SMOTE的AUC值最高。
TomekLinks的precision值最高。
综合来看SMOTE,TomekLinks和SMOTETomek三种算法通过牺牲f1分数来提升模型的区分能力AUC。
提醒:上述实验结果仅限于lendingclub部分实验数据,不具有普遍性结论。在不同数据集上测试,可能得到不同实验结论。
SMOTEENN VS SMOTETomek
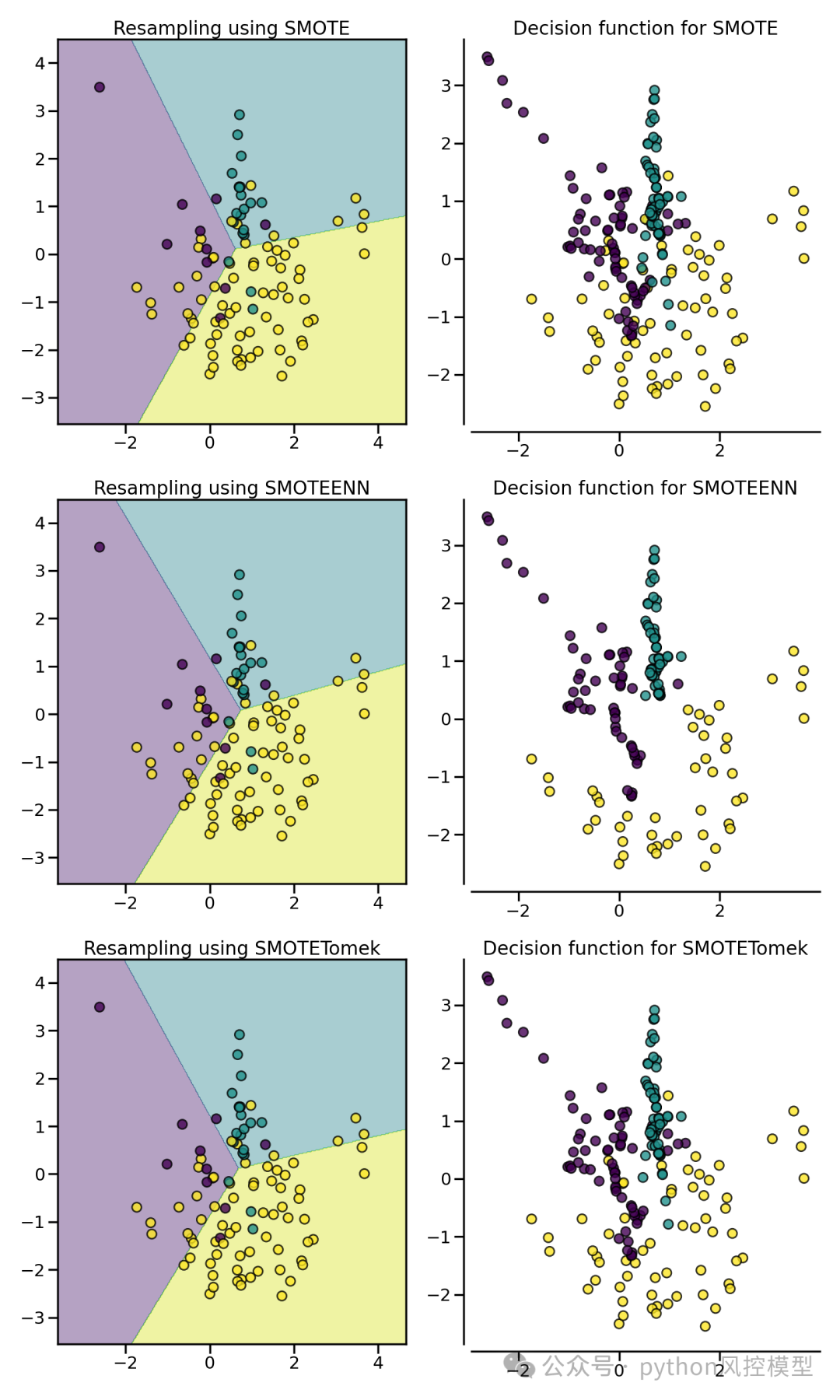
SMOTEENN和SMOTETomek经常作实验对比。我们还可以在下面的例子中看到,SMOTEENN比SMOTETomek清除更多的噪音样本。
'''
商务咨询QQ:231469242
python金融风控评分卡模型和数据分析(加强版)
https://study.163.com/series/1202915601.htm?share=2&shareId=400000000398149
'''
from collections import Counter
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=5000, n_features=2, n_informative=2,
n_redundant=0, n_repeated=0, n_classes=3,
n_clusters_per_class=1,
weights=[0.01, 0.05, 0.94],
class_sep=0.8, random_state=0)
print(sorted(Counter(y).items()))
from imblearn.combine import SMOTEENN
smote_enn = SMOTEENN(random_state=0)
X_resampled, y_resampled = smote_enn.fit_resample(X, y)
print(sorted(Counter(y_resampled).items()))
from imblearn.combine import SMOTETomek
smote_tomek = SMOTETomek(random_state=0)
X_resampled, y_resampled = smote_tomek.fit_resample(X, y)
print(sorted(Counter(y_resampled).items()))
下图是通过生成三种类比随机点
from sklearn.datasets import make_classification
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_context("poster")
X, y = make_classification(
n_samples=100,
n_features=2,
n_informative=2,
n_redundant=0,
n_repeated=0,
n_classes=3,
n_clusters_per_class=1,
weights=[0.1, 0.2, 0.7],
class_sep=0.8,
random_state=0,
)
_, ax = plt.subplots(figsize=(6, 6))
_ = ax.scatter(X[:, 0], X[:, 1], c=y, alpha=0.8, edgecolor="k")
在上图基础上,然后对比SMOTE,SMOTEENN,SMOTETomek非平衡数据处理效过,可视化如下图。
SMOTE Tomek 就介绍到这里,如果大家喜欢就收藏,点赞,转发文章。欢迎各位同学报名<python金融风控评分卡模型和数据分析微专业课>,我们提供专业评分卡模型,集成树模型,风控业务等知识,实现自动化信用评分功能,打造金融风控信贷审批模型,降低风险。
我们公司有金融风控机器学习模型定制服务(针对企业建模和论文科研),提供公司正规发票,如果你需要建模项目定制服务,商务联系作者,文章末尾有联系方式。


















 1508
1508

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









