










作者Toby,原文来源公众号:信用卡欺诈检测:2024 年顶级机器学习解决方案(附代码)
从电子商务支付系统出现的那一刻起,总是有人会找到新的方法来非法获取某人的资金。这已成为现代时代的一个主要问题,因为只需输入您的信用卡信息即可轻松在线完成所有交易。即使在 2010 年代,许多美国零售网站用户在使用两步验证进行网上购物之前就已经成为网上交易欺诈的受害者。当数据泄露导致金钱失窃并最终失去客户忠诚度和公司声誉时,组织、消费者、银行和商家都会面临风险。
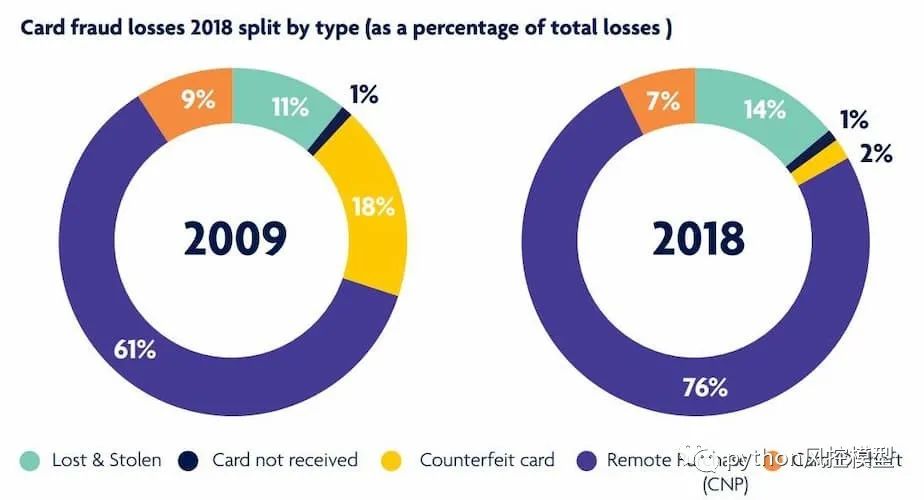
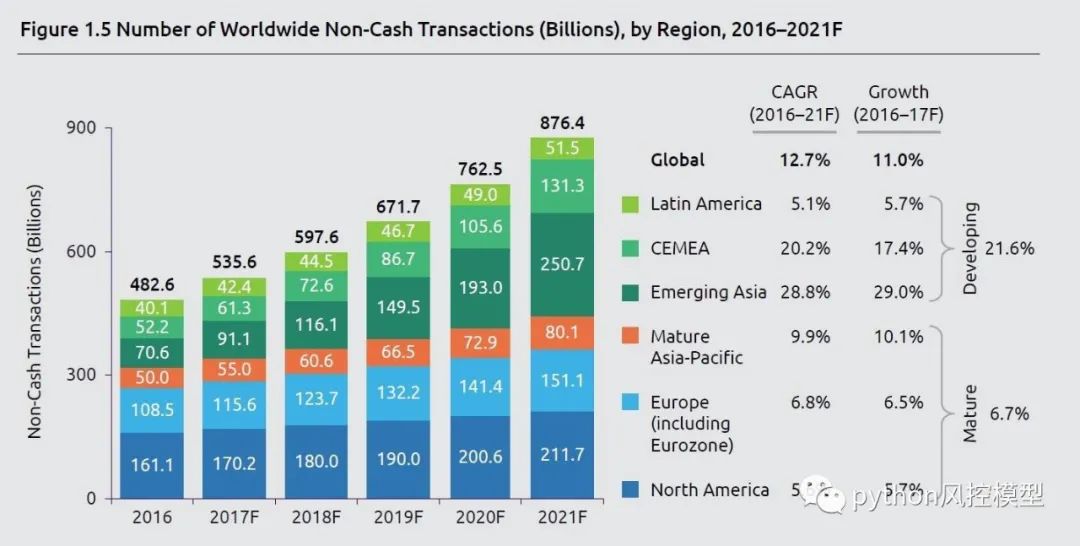
2017 年,未经授权的信用卡操作达到了惊人的 1670 万受害者。此外,据美国联邦贸易委员会 (FTC) 报告,2017 年信用卡欺诈索赔数量比上一年高出 40%。加利福尼亚州报告了大约 13,000 起案件,佛罗里达州报告了 8,000 起案件,这两个州是此类犯罪人均最多的州。到 2020 年,所涉金额将超过约 300 亿美元。以下是一些信用卡欺诈统计数据:
机器学习信用卡欺诈检测和传统欺诈检测有什么区别?
基于机器学习的欺诈检测:
-
自动检测欺诈
-
实时流媒体
-
验证方法所需的时间更少
-
识别数据中隐藏的相关性
常规欺诈检测:
-
确定方案的决策规则应手动设置。
-
需要大量时间
-
需要多种验证方式;从而给用户带来不便
-
仅发现明显的欺诈活动

什么是信用卡欺诈检测?
“欺诈检测是一系列旨在防止通过虚假借口获取金钱或财产的活动。”
欺诈可以以不同的方式在许多行业实施。大多数检测方法结合了各种欺诈检测数据集,形成有效和无效支付数据的连接概览,以做出决策。该决定必须考虑 IP 地址、地理位置、设备标识、“BIN”数据、全球纬度/经度、历史交易模式和实际交易信息。在实践中,这意味着商家和发卡行部署基于分析的响应,这些响应使用内部和外部数据来应用一组业务规则或分析算法来检测欺诈。
使用机器学习进行信用卡欺诈检测是数据科学团队进行数据调查的过程,并开发了一个模型,该模型将在揭示和防止欺诈交易方面提供最佳结果。这是通过将卡用户交易的所有有意义的特征(例如日期、用户区域、产品类别、金额、供应商、客户的行为模式等)结合在一起来实现的。然后通过一个经过巧妙训练的模型来运行信息,该模型会发现模式和规则以便它可以对交易是欺诈还是合法进行分类。
信用卡诈骗及防范技巧
| 秩 | 类别 | 报告数量 |
|---|---|---|
| 1 | 互联网服务 | 62,942 |
| 2 | 信用卡 | 51,129 |
| 3 | 卫生保健 | 47,410 |
| 4 | 电视和电子媒体 | 38,336 |
| 5 | 外币优惠和伪造支票诈骗 | 27,443 |
| 6 | 计算机设备和软件 | 18,350 |
| 7 | 投资相关 | 14,884 |
克隆交易。
克隆交易通常是一种与原始交易类似的交易或复制交易的流行方法。当组织试图通过向不同部门发送相同的发票来多次从合作伙伴那里获得付款时,就会发生这种情况。
基于规则的欺诈检测算法的传统方法不能很好地将欺诈交易与不规则或错误交易区分开来。例如,用户可能会不小心点击提交按钮两次或订购同一产品两次。
更好的选择是,如果系统能够将欺诈交易与错误交易区分开来。在这里,机器学习方法将更有效地区分由人为错误和真实欺诈引起的克隆交易。
帐户盗窃和可疑交易。
当个人的个人信息(例如社会安全号码、秘密问题答案或出生日期)被犯罪分子窃取时,他们可以使用这些信息进行财务操作。许多欺诈交易都与身份盗用有关,因此金融欺诈预防系统应最关注创建对用户行为的分析。
如果客户付款的方式有一定规律,例如某人每周同一时间访问某个酒吧一次,并且总是花费大约 40 到 60 美元。如果使用同一个帐户在位于城镇另一部分的酒吧支付超过 60 美元的款项,则这种行为将被视为不正常。下一步是向卡号所有者发送验证请求,以验证他或她是否进行了交易。
标准偏差、平均值和高/低值等指标对于发现不规则行为最有用。将单独的付款与个人基准进行比较,以识别具有高标准偏差的交易。然后,如果发生这种偏差,最好的选择是验证帐户持有人。
虚假申请欺诈。
应用程序欺诈通常伴随着帐户/身份盗窃。这意味着某人以另一个人的名义申请新的信用账户或信用卡。首先,犯罪分子窃取将作为其虚假申请的支持证据的文件。
异常检测有助于识别交易是否有任何异常模式,例如日期和时间或商品数量。如果算法发现这种异常行为,银行账户的所有者将受到一些验证方法的保护。
信用卡略读(电子或手动)。
信用卡窃取是指使用可读取和复制原始卡信息的设备制作信用卡或银行卡的非法副本。欺诈者使用名为“撇渣器”的机器提取卡号和其他信用卡信息,将其保存并转售给犯罪分子。
与身份盗窃的情况一样,通过电子或手动卡的副本进行的可疑交易将因交易信息而被披露。分类技术可以根据硬件、地理位置和有关客户行为模式的信息来定义交易是否具有欺诈性。
帐户接管。
欺诈者可以向持卡人发送欺骗性电子邮件。这些消息看起来非常合法(例如,非常相似的银行 URL 和值得信赖的徽标),就好像它们是由银行发送的一样。实际上,此类消息可用于窃取某人的个人信息、银行帐号和在线密码。如果您点击错误的链接或提供有价值的信息以响应来自虚假银行网站的消息,则在几个小时内,您的银行账户将被犯罪分子转移到他们持有的账户中。
为了避免这种欺诈模式,人工智能驱动的解决方案依赖于神经网络或模式识别。神经网络可以学习可疑的模式以及检测类别和集群以使用这些模式进行欺诈检测。
信用卡诈骗是如何发生的?
信用卡欺诈通常是由于持卡人对其数据的疏忽或网站安全性遭到破坏。这里有些例子:
-
消费者向不熟悉的人透露他的信用卡号。
-
卡片丢失或被盗,被其他人使用。
-
邮件从目标收件人处窃取并被犯罪分子使用。
-
企业员工复制其所有者的卡片或卡号。
-
制作假信用卡。
当您的卡丢失或被盗时,可能会发生未经授权的收费;换句话说,发现它的人使用它进行购买。不法分子还可以伪造您的姓名并使用该卡或通过手机或电脑订购一些商品。此外,还存在使用假信用卡的问题——一张具有从持有人那里窃取的真实账户信息的假卡。这是特别危险的,因为受害者拥有他们的真实卡,但不知道有人复制了他们的卡。这种欺诈性卡片看起来非常合法,并且带有原始卡片的标识和编码磁条。欺诈性信用卡通常在多次成功付款后被犯罪分子销毁,就在受害者意识到问题并报告之前。
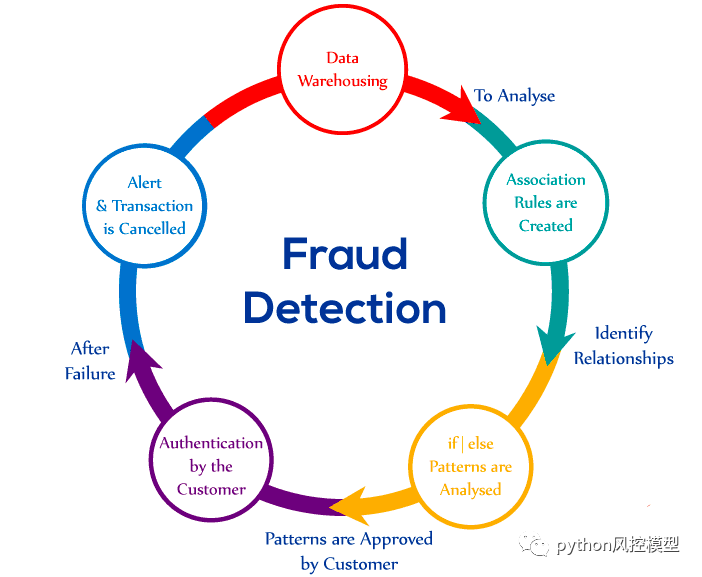
信用卡欺诈检测系统和实施人工智能欺诈检测系统的步骤
信用卡欺诈检测系统:
-
从第三方反欺诈公司提取的现成欺诈风险评分。
-
从先前数据中学习并估计欺诈性信用卡交易的概率的预测机器学习模型。
-
设置交易必须通过才能获得批准的条件的业务规则(例如,没有 OFAC 警报、SSN 匹配、低于存款/取款限额等)。
在这些欺诈分析技术中,预测性机器学习模型属于智能互联网安全解决方案。
AI欺诈检测系统实施步骤:
-
数据挖掘。意味着对数据进行分类、分组和分段,以搜索数百万笔交易以查找模式并检测欺诈。
-
模式识别。意味着检测可疑行为的类别、集群和模式。此处的机器学习代表选择最适合某个业务问题的模型/模型集。例如,神经网络方法有助于自动识别欺诈交易中最常见的特征;如果您有大量交易样本,此方法最有效。
一旦机器学习驱动的欺诈保护模块被集成到电子商务平台中,它就会开始跟踪交易。每当用户请求交易时,它都会被处理一段时间。根据预测的欺诈概率水平,存在三种可能的结果:
-
如果概率小于 10%,则允许交易。
-
如果概率介于 10% 和 80% 之间,则应应用额外的身份验证因素(例如一次性 SMS 代码、指纹或秘密问题)。
-
如果概率超过 80%,则交易被冻结,因此应手动处理。
使用基于 AI 的方法进行支付欺诈检测的要求
要为信用卡欺诈分析运行 AI 驱动的策略,应满足许多关键要求。这些将确保模型达到其最佳检测分数。
数据量。
训练高质量的机器学习模型需要大量的内部历史数据。这意味着如果您之前没有足够的欺诈和正常交易,则很难在其上运行机器学习模型,因为其训练过程的质量取决于输入的质量。因为很少有训练集包含两个类中等量的数据样本的情况,所以使用降维或数据增强技术。
数据质量。
模型可能会因历史数据的性质和质量而存在偏差。这种说法意味着,如果平台维护者没有对数据进行整齐、适当的收集和排序,甚至将欺诈交易的信息与正常交易的信息混合在一起,那么很可能会导致模型结果出现重大偏差。
因素的完整性。
如果您有足够多的结构良好且无偏见的数据,并且您的业务逻辑与机器学习模型完美匹配,那么欺诈检测很可能对您的客户和您的业务有效。
先进的信用卡欺诈识别方法及其优势
高级信用卡欺诈识别方法分为:
-
无监督。如PCA、LOF、One-class SVM、Isolation Forest。
-
监督。例如决策树(例如 XGBoost 和 LightGBM)、随机森林和 KNN。
我们已经介绍了机器学习用于欺诈检测的工作原理的基本愿景。现在让我们深入研究使之成为可能的确切模型。
无监督。
无监督机器学习方法使用未标记的数据来查找信用卡欺诈检测数据集中的模式和依赖关系,从而可以通过相似性对数据样本进行分组,而无需手动标记。
PCA(主成分分析)可以执行探索性数据分析,以揭示数据的内部结构并解释其变化。PCA 是最流行的异常检测技术之一。
PCA 搜索特征之间的相关性——在信用卡交易的情况下,可能是时间、地点和花费的金额——并确定哪些值的组合会导致结果的可变性。这种组合的特征值允许创建名为主成分的更紧密的特征空间。PCA的Python代码如下
import numpy as npfrom sklearn.decomposition import PCAfrom sklearn.datasets import load_irisimport matplotlib.pyplot as plt# 加载数据集data = load_iris()X = data.data# 选择要保留的主成分数量n_components = 2# 创建PCA对象pca = PCA(n_components=n_components)# 对数据进行拟合和转换X_pca = pca.fit_transform(X)# 打印主成分解释的方差比例print("Explained variance ratio:", pca.explained_variance_ratio_)# 可视化降维后的数据plt.figure(figsize=(8, 6))plt.scatter(X_pca[:, 0], X_pca[:, 1], c=data.target, cmap='viridis', edgecolor='k')plt.xlabel('Principal Component 1')plt.ylabel('Principal Component 2')plt.title('PCA of IRIS dataset')plt.colorbar()plt.show()
LOF(Local Outlier Factor)是帮助了解某个数据样本成为异常值(异常)的可能性有多大的分数因子。这是另一种最流行的异常检测方法。
为了计算 LOF,考虑相邻数据点的数量来计算其密度并将其与其他数据点的密度进行比较。如果某个数据点与其近邻相比具有低得多的密度,则它是一个异常值。
LOF的Python代码如下
from sklearn.neighbors import LocalOutlierFactorfrom sklearn.datasets import make_blobsimport matplotlib.pyplot as plt# 创建一个合成的数据集X, _ = make_blobs(n_samples=200, centers=3, cluster_std=0.60, random_state=0)# 创建LOF对象lof = LocalOutlierFactor(n_neighbors=20, contamination='auto')# 拟合数据并预测y_pred = lof.fit_predict(X)# 将正常点标记为1,异常点标记为-1y_pred[y_pred == -1] = 0# 可视化结果plt.figure(figsize=(10, 8))plt.scatter(X[:, 0], X[:, 1], color='k', s=20, label='Data points')plt.scatter(X[y_pred == 0, 0], X[y_pred == 0, 1], color='r', s=50, marker='x', label='Outliers')plt.legend()plt.title('LOF Outlier Detection')plt.show()
一类 SVM(支持向量机)是一种分类算法,有助于识别数据中的异常值。该算法允许人们处理与数据不平衡相关的问题,例如欺诈检测。
One-class SVM 背后的想法是仅对大量合法交易进行训练,然后通过将每个新数据点与它们进行比较来识别异常或新奇事物。
孤立森林 (IF)是决策树系列中的一种异常检测方法。IF 区别于其他流行的异常值检测算法的主要思想是它精确检测异常而不是分析正数据点。孤立森林由决策树构建,其中数据点的分离首先发生,因为在所选特征的最小值和最大值中随机选择一个分割值。
随后,如果我们有一组合法交易,孤立森林算法将根据它们的价值来定义欺诈性信用卡交易——这通常与正交易的价值非常不同(即它们发生在离正常数据点更远的地方)特征空间)。
有监督算法
有监督的机器学习方法使用标记的数据样本,因此系统将预测这些标记在未来数据之前看不见。在受监督的 ML 欺诈识别方法中,我们定义了决策树、随机森林、KNN 和朴素贝叶斯。
K-Nearest Neighbors是一种分类算法,它根据多维空间中的距离计算相似性。因此,数据点将被分配到最近邻居所具有的类别。KNN在我们大数据实验中,效果并不好。
这种方法不易受到噪声和数据点缺失的影响,这意味着可以在更短的时间内组成更大的数据集。此外,它非常准确,并且需要开发人员进行较少的工作来调整模型。
KNN的Python代码如下,如果要提升KNN模型性能,需要对N_neighbor的调参。
n_neighborsfrom sklearn.neighbors import KNeighborsClassifierfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import accuracy_score# 加载数据集iris = load_iris()X = iris.datay = iris.target# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 创建KNN分类器对象# n_neighbors指定了K的值,即邻居的数量knn_classifier = KNeighborsClassifier(n_neighbors=3)# 训练模型knn_classifier.fit(X_train, y_train)# 预测测试集y_pred = knn_classifier.predict(X_test)# 计算准确率accuracy = accuracy_score(y_test, y_pred)print(f'Accuracy: {accuracy:.4f}')
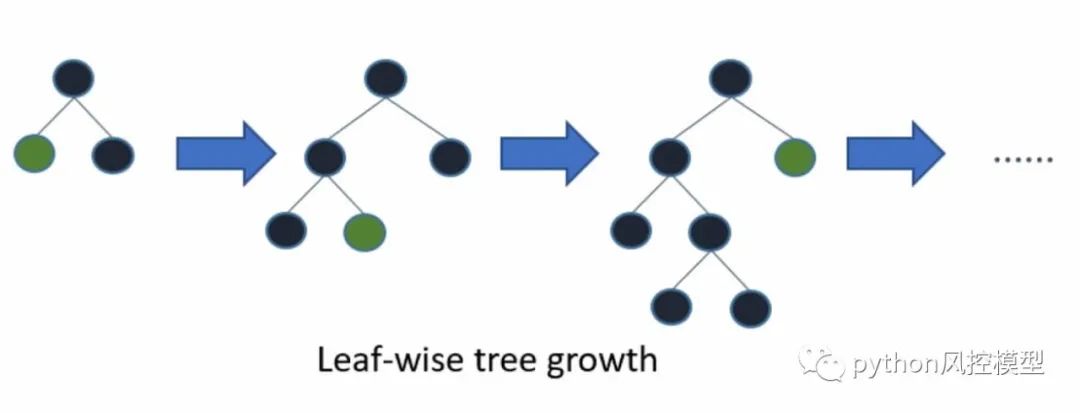
XGBoost (Extreme Gradient Boosting)和Light GBM (Gradient Boosting Machine)是一种单一类型的梯度提升决策树算法,它的创建是为了速度以及最大化计算时间和内存资源的效率。该算法是一种混合技术,其中添加新模型以修复由现有模型引起的错误。
LightGBM 与其他基于树的技术的不同之处仅在于它遵循叶子方向而不是水平方向来构建条件(图 1,2)。一般来说,所有基于树的梯度提升算法背后的思想都是一样的。
为了将交易归类为欺诈性费用,许多决策树的结果(概率)被汇总——而每个未来的决策树都根据其前辈所犯的错误来改进其结果。
随机森林是一种由许多决策树组成的分类算法。每棵树都有带条件的节点,这些节点定义了基于最高值的最终决策。
用于欺诈检测和预防的随机森林算法有两个主要因素,使其擅长预测事物。第一个是随机性,这意味着数据的行和列是从数据集中随机选择的,并适合不同的决策树。假设树 1 接收前 1,000 行,树 2 接收 4,000 到 5,000 行,而树 3 有 8,000 到 9,000 行。
第二个因素是多样性,这意味着有一片树林有助于最终决策,而不仅仅是一棵决策树。这里最大的优势是这种多样性降低了模型过度拟合的机会,而偏差保持不变。
随机森林的Python代码如下
from sklearn.ensemble import RandomForestClassifierfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import accuracy_score# 加载数据集iris = load_iris()X = iris.datay = iris.target# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 创建随机森林分类器对象rf_classifier = RandomForestClassifier(n_estimators=100, random_state=42)# 训练模型rf_classifier.fit(X_train, y_train)# 预测测试集y_pred = rf_classifier.predict(X_test)# 计算准确率accuracy = accuracy_score(y_test, y_pred)print(f'Accuracy: {accuracy:.4f}')
catboost是一个高效的机器学习库,由Yandex公司开发,专门用于处理分类和回归问题。它是基于梯度提升决策树(Gradient Boosted Decision Trees, GBDT)的算法,特别适合处理具有大量类别特征(categorical features)的数据集。Toby老师在大量实验中,发现catboost有非常优秀性能。
NGBoost是一种新的提升算法,它使用自然梯度提升,一种用于概率预测的模块化提升算法。该算法由基学习器、参数概率分布和评分规则组成。
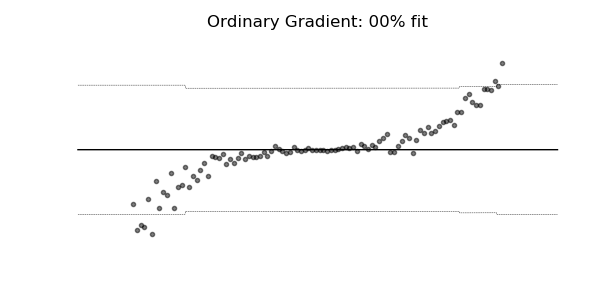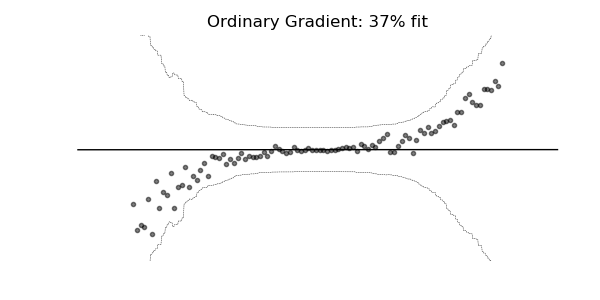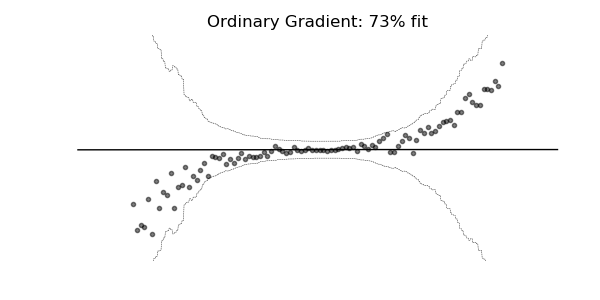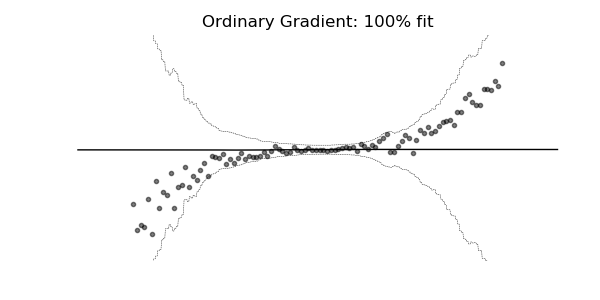
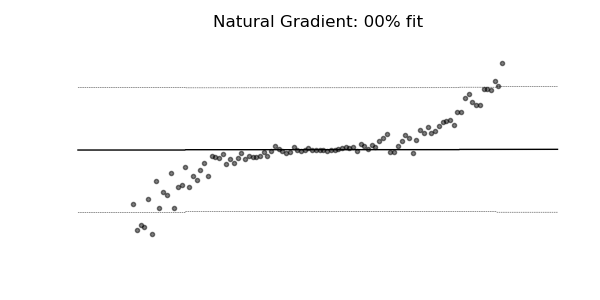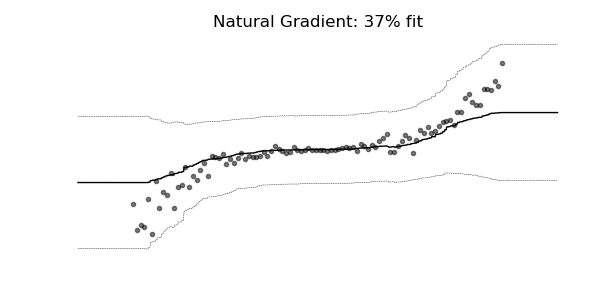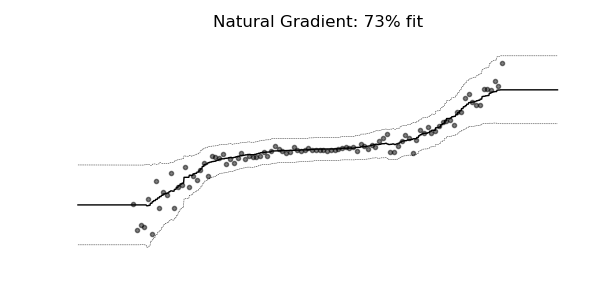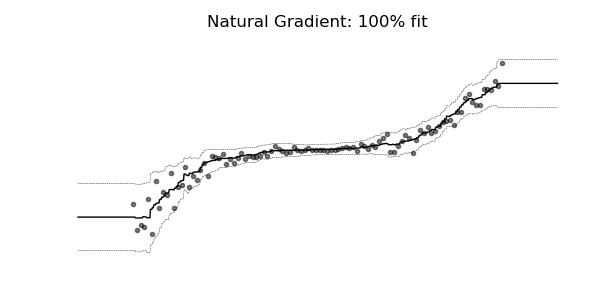
普通梯度可能非常不适合学习多参数概率分布(例如正态分布)。如上面的概率回归示例所示,使用自然梯度的训练动态往往更加稳定并产生更好的拟合。
在不确定性估计和传统指标方面的竞争表现
与竞争方法相比,NGBoost 所需的专业知识要少得多,并且在常见的基准测试中表现同样出色。NGBoost 在较小的数据集上具有特别强的性能。
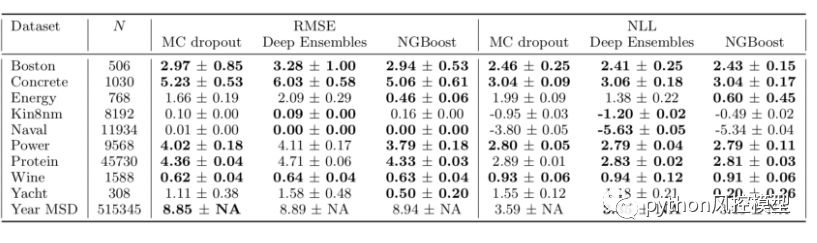
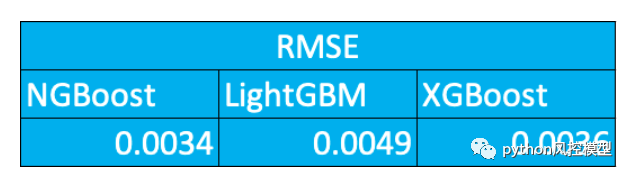
在一个回归模型的实验中,我们发现ngboost获得更低的rmse.
总结
可以使用不同的机器学习模型来检测欺诈;它们中的每一个都有其优点和缺点。有些模型很难解释、解释和调试,但它们具有很好的准确性(例如神经网络、Boosting、Ensembles 等);其他的更简单,因此它们可以很容易地被解释和可视化为一堆规则(例如决策树)。
每当有数据到达时,不断训练欺诈检测模型非常重要,因此可以学习新的欺诈模式/模式并尽早检测欺诈数据。关于更多风控模型知识,请参考《python金融风控评分卡模型和数据分析》,提供逻辑回归评分卡,集成树xgboost,lightgbm,catboost,svm,神经网络等诸多主流算法实战案例。
常见的信用卡欺诈问题
让我们回答一些经常与信用卡欺诈相关的有趣问题。
谁应对信用卡欺诈负责?
在美国,联邦法律(即《公平信用账单法案》)为持卡人设定了 50 美元的责任限额,无论未经授权的用户收取多少费用。此规则适用于不安全的在线连接或数据泄露的情况。
如果受害者在未经授权的交易发生之前报告卡丢失或被盗,他或她将不承担任何费用。
个人信息被盗是很危险的,因为虽然受害者不承担任何经济损失,但他或她可能会花几年时间处理犯罪分子造成的所有金融和信用欺诈。
银行会调查信用卡欺诈吗?
在用户通知银行他或她注意到可疑的信用卡交易后,银行会开始信用卡欺诈调查。
受害者必须立即通知银行有关欺诈交易的信息,并且不得迟于事件发生后的 60 天。他或她必须提供有关损失的确切金额、日期以及交易看似欺诈的原因的描述的信息。然后,银行开始调查,必须在不超过 45 天内解决。如果 10 天后银行发现欺诈确实发生,银行必须向受害者赔偿被盗的金额。
银行必须将调查结果书面通知持卡人。如果这些文件影响了银行的决定,持卡人有权要求银行在调查过程中创建或收集的任何文件的副本。
总结
欺诈是整个信用卡行业的一个主要问题,随着电子货币转账的日益普及,该行业变得越来越大。为有效防范导致银行账户信息泄露、盗刷、伪造信用卡、每年数十亿美元被盗以及声誉和客户忠诚度损失的犯罪行为,信用卡发卡机构应考虑实施高级信用信用卡欺诈预防和欺诈检测方法。基于机器学习的方法可以根据每个持卡人的行为信息不断提高欺诈预防的准确性。
版权声明:文章来自公众号(python风控模型),未经许可,不得抄袭。遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









