







一、伙伴系统概述
1.什么是伙伴系统
伙伴系统(buddy system)是操作系统内核中用于管理物理内存的一种算法。所谓伙伴指的是物理内存中地址连续的页块之间互为伙伴。若两个页面块之间可以互为伙伴,则两个页面块可以合并为更大的一个页面块。
2.为什么要有伙伴系统
现代操作系统对于内存的管理都是以页为单位进行管理的,申请内存时往往是以连续的内存进行申请的,随着程序对内存的不断的申请与释放,会导致许多内存碎片的产生,从而使得系统中虽然还有很多的空闲物理内存,但却无法提供一块连续的内存。为了缓解内存碎片的产生,出现了伙伴系统。
在伙伴系统中,使用11个链表来管理11种不同大小的页面块,这11种页面块分别包含有1、2、4、8...、1024个连续页面。内存分配是以2^n个页面为单位进行分配与释放的,每次分配时尽量从连续页面个数较小的内存块中分配,释放时则尽量进行合并,合并为较大连续页面的页面块,通过这种方式,有效的缓解了内存碎片的问题。
3.伙伴系统的内存分配与释放
1)内存分配
Linux内核为了尽量减少空间的浪费,减少申请释放内存的消耗时间,采用基于伙伴算法的存储分配机制。伙伴系统算法把内存中的所有页框按照大小分成10组不同大小的页块,每块分别包含1,2,4,8,……,512个页框。每种不同的页块都通过一个free-area-struct结构体来管理。系统将10个free-area-struct结构体组成一个free-area[]数组。在free-area-struct包含指向空闲页块链表的指针。此外在每个free-area-struct中还包含一个系统空闲页块位图(bitmap),位图中的每一位都用来表示系统按照当前页块大小划分时每个页块的使用情况,同mem-map一样,系统在初始化时调用free-area-struct()函数来初始化每个free-area-struct中的位图结构。
2)内存释放
当向内存请求分配一定数目的页框时,若所请求的页框数目不是2的幂次方,则按稍大于此数目的2的幂次方在页块链表中查找空闲页块,如果对应的页块链表中没有空闲页块,则在更大的页块链表中查找。当分配的页块中有多余的页框时,伙伴系统将根据多余的页框大小插入到对应的空闲页块链表中。向伙伴系统释放页框时,伙伴系统会将页框插入到对应的页框链表中,并且检查新插入的页框能否和原有的页块组合构成一个更大的页块,如果两个块的大小相同且这两个块的物理地址连续,则合并成一个新页块加入到对应的页块链表中,并迭代此过程直到不能合并为止,这样可以极大限度地减少内存的外碎片。
伙伴系统提供了分配和释放页框的函数。get-zeroed-page()用于分配用0填充好的页框。和get-zeroed-page()相似,-get-free-page()用来分配一个新的页框,但是没有被0填充,-get-free-page()用来分配指定数目的页框。通过调用-free-page()和-free-pages()可以向伙伴系统释放已申请的页框。alloc-pages-node()是伙伴系统分配页框的核心函数,它有两个变体:alloc-page()和alloc-pages()。alloc-pages-node()函数在指定的节点中分配一定数目的页框。alloc-page()和alloc-pages()分别在当前节点中分配一个或指定数目的页框。
二、伙伴系统原理
为了便于页面的维护,将多个页面组成内存块,每个内存块都有2的方幂个页,方幂的指数被称为阶。在操作内存时,经常将这些内存块分成大小相等的两个块,分成的两个内存块被称为伙伴块,采用一位二进制数来表示它们的伙伴关系。当这个位为1,表示其中一块在使用;当这个位为0,表示两个页面块都空闲或者都在使用。系统根据该位为0或位为1来决定是否使用或者分配该页面块。系统每次分配和回收伙伴块时都要对它们的伙伴位跟1进行异或运算。所谓异或是指刚开始时,两个伙伴块都空闲,它们的伙伴位为0,如果其中一块被使用,异或后得1;如果另一块也被使用,异或后得0;如果前面一块回收了异或后得1;如果另一块也回收了异或后得0。
1.设计思路
伙伴系统主要思想是通过将物理内存划分成多个连续的块,然后以“块”作为基本单位进行分配。这些“块”的都是由一个或者多个连续的物理页组成,物理页的数量是2的n次幂(0 <= n <= MAX_ORDER)。
如下图所示:
数组 frea_area[0] 指向的链表就是 0 阶链表,他携带的内存块都是 1 (2 ^ 0)个页面,数组frea_area[3]指向的链表是3阶链表,它挂的都是 8(2 ^ 3)个页大小的内存块。以此类推。

MAX_ORDER定义为10, 即内核管理的最大的连续空闲物理内存为2 ^ (10+1 - 1) = 4MB。
/* include/linux/mmzone.h */
/* Free memory management - zoned buddy allocator. */
#ifndef CONFIG_ARCH_FORCE_MAX_ORDER
#define MAX_ORDER 10
#else
#define MAX_ORDER CONFIG_ARCH_FORCE_MAX_ORDER
#endif
#define MAX_ORDER_NR_PAGES (1 << MAX_ORDER)当前系统的buddy状态可以通过 cat /proc/buddyinfo 命令查看。
# cat /proc/buddyinfo
Node 0, zone DMA 1 1 1 0 2 1 1 0 1 1 3
Node 0, zone DMA32 1423 840 497 1510 934 377 120 34 19 1 1
Node 0, zone Normal 25074 23455 578 222 234 76 21 42 32 28 0
Node 1, zone Normal 7427 215 65 0 0 0 0 0 0 0 0从左向右分别对应frea_area[0] ~ frea_area[10]。
2.数据结构
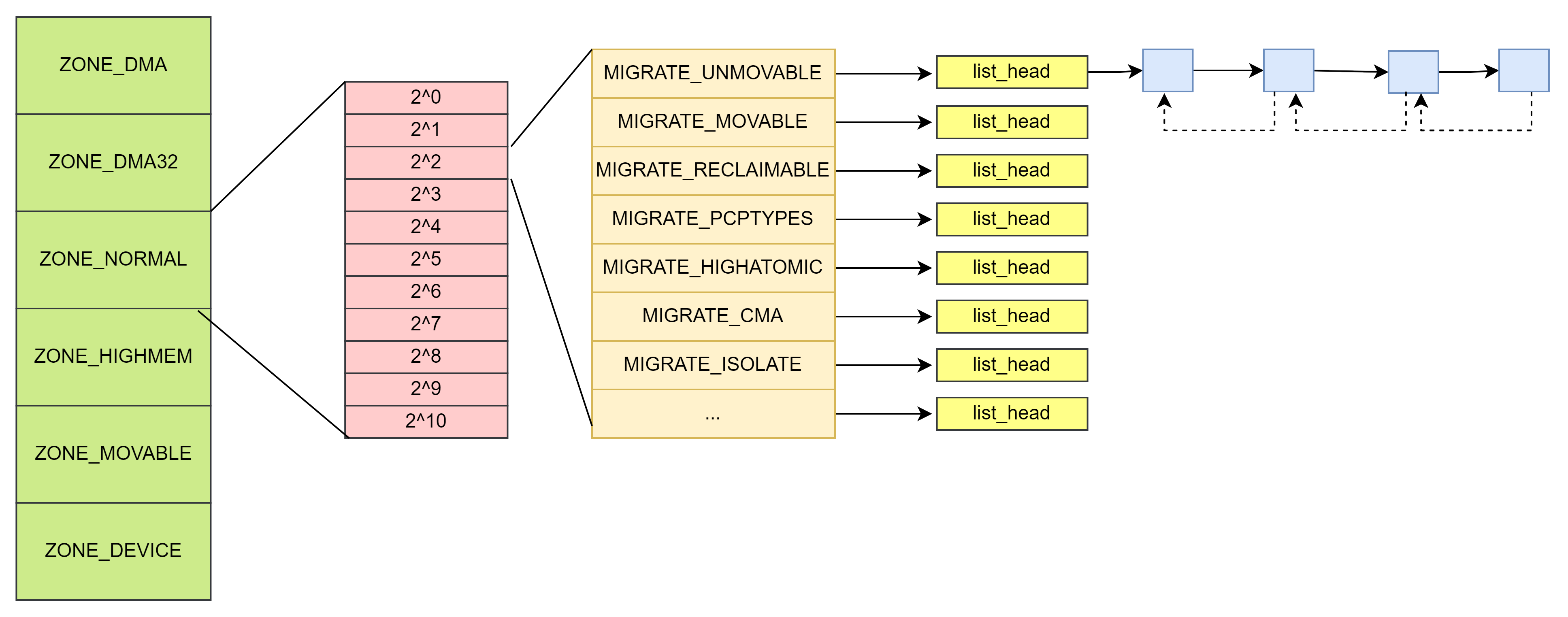
Zone的数据结构中free_area[MAX_ORDER + 1]数组用于保存每一阶的空闲内存块链表
struct zone {
...
struct free_area free_area[MAX_ORDER + 1];
} ____cacheline_internodealigned_in_smp;
struct free_area {
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;
};struct list_head {
struct list_head *next, *prev;
};free_list: 用于连接包含大小相同的连续内存区域的页链表
nr_free: 该区域中空闲页表的数量
每个free_list链表上的各个元素, 都是通过struct page中的双链表成员变量来连接的。
migratetype是页面迁移类型。
NUMA架构中,支持内存在节点间移动,保持内存的均衡性,因此内存定义了以下几种的迁移类型
enum migratetype {
MIGRATE_UNMOVABLE,
MIGRATE_MOVABLE,
MIGRATE_RECLAIMABLE,
MIGRATE_PCPTYPES, /* the number of types on the pcp lists */
MIGRATE_HIGHATOMIC = MIGRATE_PCPTYPES,
#ifdef CONFIG_CMA
/*
* MIGRATE_CMA migration type is designed to mimic the way
* ZONE_MOVABLE works. Only movable pages can be allocated
* from MIGRATE_CMA pageblocks and page allocator never
* implicitly change migration type of MIGRATE_CMA pageblock.
*
* The way to use it is to change migratetype of a range of
* pageblocks to MIGRATE_CMA which can be done by
* __free_pageblock_cma() function.
*/
MIGRATE_CMA,
#endif
#ifdef CONFIG_MEMORY_ISOLATION
MIGRATE_ISOLATE, /* can't allocate from here */
#endif
MIGRATE_TYPES
};| No | 类型 | 描述说明 |
| 1 | MIGRATE_UNMOVABLE | 不可移动, 核心内核分配的大部分页面都属于这一类。 |
| 2 | MIGRATE_MOVABLE | 可移动,属于用户空间应用程序的页属于此类页面,它们是通过页表映射的,因此我们只需要更新页表项,并把数据复制到新位置就可以了,当然要注意,一个页面可能被多个进程共享,对应着多个页表项 |
| 3 | MIGRATE_RECLAIMABLE | 可回收,不能直接移动,但是可以回收,因为还可以从某些源重建页面,比如映射文件的数据属于这种类别,kswapd会按照一定的规则,周期性的回收这类页面。 |
| 4 | MIGRATE_PCPTYPES | 用来表示每CPU页框高速缓存的数据结构中的链表的迁移类型数目。 |
| 5 | MIGRATE_HIGHATOMIC | 某些情况,内核需要分配一个高阶的页面块而不能休眠.如果向具有特定可移动性的列表请求分配内存失败,这种紧急情况下可从MIGRATE_HIGHATOMIC中分配内存 |
| 6 | MIGRATE_CMA | 预留一段的内存给驱动使用,但当驱动不用的时候,伙伴系统可以分配给用户进程用作匿名内存或者页缓存。而当驱动需要使用时,就将进程占用的内存通过回收或者迁移的方式将之前占用的预留内存腾出来,供驱动使用。 |
| 7 | MIGRATE_ISOLATE | 不能从这个链表分配页框,因为这个链表专门用于NUMA结点移动物理内存页,将物理内存页内容移动到使用这个页最频繁的CPU。 |
数据结构的关系如下图
3.内存分配与释放步骤
1)内存分配
内存分配的入口是struct page *rmqueue(),如下代码:
/*
* Allocate a page from the given zone.
* Use pcplists for THP or "cheap" high-order allocations.
*/
/*
* Do not instrument rmqueue() with KMSAN. This function may call
* __msan_poison_alloca() through a call to set_pfnblock_flags_mask().
* If __msan_poison_alloca() attempts to allocate pages for the stack depot, it
* may call rmqueue() again, which will result in a deadlock.
*/
__no_sanitize_memory
static inline
struct page *rmqueue(struct zone *preferred_zone,
struct zone *zone, unsigned int order,
gfp_t gfp_flags, unsigned int alloc_flags,
int migratetype)
{
struct page *page;
/*
* We most definitely don't want callers attempting to
* allocate greater than order-1 page units with __GFP_NOFAIL.
*/
WARN_ON_ONCE((gfp_flags & __GFP_NOFAIL) && (order > 1));
if (likely(pcp_allowed_order(order))) { /*--------------(1)-------------*/
/*
* MIGRATE_MOVABLE pcplist could have the pages on CMA area and
* we need to skip it when CMA area isn't allowed.
*/
if (!IS_ENABLED(CONFIG_CMA) || alloc_flags & ALLOC_CMA ||
migratetype != MIGRATE_MOVABLE) {
page = rmqueue_pcplist(preferred_zone, zone, order,
migratetype, alloc_flags);
if (likely(page))
goto out;
}
}
page = rmqueue_buddy(preferred_zone, zone, order, alloc_flags,
migratetype); /*--------------(2)-------------*/
out:
/* Separate test+clear to avoid unnecessary atomics */
/*--------------(3)-------------*/
if ((alloc_flags & ALLOC_KSWAPD) &&
unlikely(test_bit(ZONE_BOOSTED_WATERMARK, &zone->flags))) {
clear_bit(ZONE_BOOSTED_WATERMARK, &zone->flags);
wakeup_kswapd(zone, 0, 0, zone_idx(zone));
}
VM_BUG_ON_PAGE(page && bad_range(zone, page), page);
return page;
}(1)当pcp_allowed_order(order)成立,调用rmqueue_pcplist()函数, 走PCP分配机制。PCP即per_cpu_pages, 它是一个per-cpu变量,该变量中有一个单页面的链表,存放部分单个的物理页面,当系统需要单个物理页面时,直接从该per-cpu变量的链表中获取物理页面,这样能够做到更高的效率。
struct zone {
...
struct per_cpu_pages __percpu *per_cpu_pageset;
...
} ____cacheline_internodealigned_in_smp;/* Fields and list protected by pagesets local_lock in page_alloc.c */
struct per_cpu_pages {
spinlock_t lock; /* Protects lists field */
int count; /* number of pages in the list */
int high; /* high watermark, emptying needed */
int batch; /* chunk size for buddy add/remove */
short free_factor; /* batch scaling factor during free */
#ifdef CONFIG_NUMA
short expire; /* When 0, remote pagesets are drained */
#endif
/* Lists of pages, one per migrate type stored on the pcp-lists */
struct list_head lists[NR_PCP_LISTS];
} ____cacheline_aligned_in_smp;count: 表示链表中页面的数量
high: 表示当缓存的页面高于水位时就会回收页面到伙伴系统
batch: 表示每一次回收到伙伴系统的页面数量
lists[NR_PCP_LISTS]:页面列表,存储在pcp列表中的每个迁移类型一个
(2)如果PCP分配失败或者不允许被分配页,则通过rmqueue_buddy()函数分配页。直到分配的page是ok的,则退出while循环,记录vmstat状态,并返回page页。
static __always_inline
struct page *rmqueue_buddy(struct zone *preferred_zone, struct zone *zone,
unsigned int order, unsigned int alloc_flags,
int migratetype)
{
struct page *page;
unsigned long flags;
do {
page = NULL;
spin_lock_irqsave(&zone->lock, flags);
/*
* order-0 request can reach here when the pcplist is skipped
* due to non-CMA allocation context. HIGHATOMIC area is
* reserved for high-order atomic allocation, so order-0
* request should skip it.
*/
if (alloc_flags & ALLOC_HIGHATOMIC)
page = __rmqueue_smallest(zone, order, MIGRATE_HIGHATOMIC);
if (!page) {
page = __rmqueue(zone, order, migratetype, alloc_flags);
/*
* If the allocation fails, allow OOM handling access
* to HIGHATOMIC reserves as failing now is worse than
* failing a high-order atomic allocation in the
* future.
*/
if (!page && (alloc_flags & ALLOC_OOM))
page = __rmqueue_smallest(zone, order, MIGRATE_HIGHATOMIC);
if (!page) {
spin_unlock_irqrestore(&zone->lock, flags);
return NULL;
}
}
__mod_zone_freepage_state(zone, -(1 << order),
get_pcppage_migratetype(page));
spin_unlock_irqrestore(&zone->lock, flags);
} while (check_new_pages(page, order));
__count_zid_vm_events(PGALLOC, page_zonenum(page), 1 << order);
zone_statistics(preferred_zone, zone, 1);
return page;
}页面尽可能分配MIGRATE_HIGHATOMIC类型的空闲页面,如果分配MIGRATE_HIGHATOMIC类型的空闲页面失败,则调用__rmqueue()函数分配内存,如果__rmqueue()函数分配内存也失败,则调用__rmqueue_smallest 函数分割”块“。
/*
* Go through the free lists for the given migratetype and remove
* the smallest available page from the freelists
*/
static __always_inline
struct page *__rmqueue_smallest(struct zone *zone, unsigned int order,
int migratetype)
{
unsigned int current_order;
struct free_area *area;
struct page *page;
/* Find a page of the appropriate size in the preferred list */
for (current_order = order; current_order <= MAX_ORDER; ++current_order) { /*---------(1)---------*/
area = &(zone->free_area[current_order]);
page = get_page_from_free_area(area, migratetype);
if (!page)
continue;
del_page_from_free_list(page, zone, current_order);
expand(zone, page, order, current_order, migratetype); /*---------(2)---------*/
set_pcppage_migratetype(page, migratetype);
trace_mm_page_alloc_zone_locked(page, order, migratetype,
pcp_allowed_order(order) &&
migratetype < MIGRATE_PCPTYPES);
return page;
}
return NULL;
}(1) 从current order开始查找zone的空闲链表。如果当前的order中没有空闲对象,那么就会查找上一级order
(2) del_page_from_free_list函数只会将空闲的对象摘出链表, 真正分配的功能在expand()函数实现。
expand()会将空闲链表上的页面块分配一部分后,将剩余的空闲部分挂在zone上更低order的页面块链表上。
/*
* The order of subdivision here is critical for the IO subsystem.
* Please do not alter this order without good reasons and regression
* testing. Specifically, as large blocks of memory are subdivided,
* the order in which smaller blocks are delivered depends on the order
* they're subdivided in this function. This is the primary factor
* influencing the order in which pages are delivered to the IO
* subsystem according to empirical testing, and this is also justified
* by considering the behavior of a buddy system containing a single
* large block of memory acted on by a series of small allocations.
* This behavior is a critical factor in sglist merging's success.
*
* -- nyc
*/
static inline void expand(struct zone *zone, struct page *page,
int low, int high, int migratetype)
{
unsigned long size = 1 << high;
while (high > low) {
high--;
size >>= 1;
VM_BUG_ON_PAGE(bad_range(zone, &page[size]), &page[size]);
/*
* Mark as guard pages (or page), that will allow to
* merge back to allocator when buddy will be freed.
* Corresponding page table entries will not be touched,
* pages will stay not present in virtual address space
*/
if (set_page_guard(zone, &page[size], high, migratetype))
continue;
add_to_free_list(&page[size], zone, high, migratetype);
set_buddy_order(&page[size], high);
}
}这里的high就是current_order, 如果分配的页面块大于需求的页面块,那么就将order降一级, 最后通过add_to_free_list把剩余的空闲内存添加到低一级的空闲链表中。
(3)这里主要是优化内存外碎片。如果&zone->flags设置了ZONE_BOOSTED_WATERMARK标志位,就会唤醒kswapd线程回收内存。ZONE_BOOSTED_WATERMARK在fallback流程里会被设置,说明此时页面分配器已经向备份空闲链表借用内存,有内存外碎片的可能。
2)内存释放
释放页面的函数是free_page(),它相关的核心代码如下
static inline void free_the_page(struct page *page, unsigned int order)
{
if (order == 0) /* Via pcp? */
free_unref_page(page);
else
__free_pages_ok(page, order, FPI_NONE);
}
void __free_pages(struct page *page, unsigned int order)
{
if (put_page_testzero(page))
free_the_page(page, order);
else if (!PageHead(page))
while (order-- > 0)
free_the_page(page + (1 << order), order);
}释放页面会分两种情况
(1) order = 0, free_unref_page()释放单个页面。 在该函数中首先会调用local_irq_save()关闭本地中断,因为中断可能会触发页面分配, pcp链表可能会被改变。free_unref_page_commit()会释放单个页面到pcp链表中。
(2) order > 0,这部分代码很长,它的大致流程如下图

核心代码如下:
...
/*
* This function checks whether a page is free && is the buddy
* we can coalesce a page and its buddy if
* (a) the buddy is not in a hole (check before calling!) &&
* (b) the buddy is in the buddy system &&
* (c) a page and its buddy have the same order &&
* (d) a page and its buddy are in the same zone.
*
* For recording whether a page is in the buddy system, we set PageBuddy.
* Setting, clearing, and testing PageBuddy is serialized by zone->lock.
*
* For recording page's order, we use page_private(page).
*/
static inline bool page_is_buddy(struct page *page, struct page *buddy,
unsigned int order)
{
if (!page_is_guard(buddy) && !PageBuddy(buddy))
return false;
if (buddy_order(buddy) != order)
return false;
/*
* zone check is done late to avoid uselessly calculating
* zone/node ids for pages that could never merge.
*/
if (page_zone_id(page) != page_zone_id(buddy))
return false;
VM_BUG_ON_PAGE(page_count(buddy) != 0, buddy);
return true;
}
...
/*
* Find the buddy of @page and validate it.
* @page: The input page
* @pfn: The pfn of the page, it saves a call to page_to_pfn() when the
* function is used in the performance-critical __free_one_page().
* @order: The order of the page
* @buddy_pfn: The output pointer to the buddy pfn, it also saves a call to
* page_to_pfn().
*
* The found buddy can be a non PageBuddy, out of @page's zone, or its order is
* not the same as @page. The validation is necessary before use it.
*
* Return: the found buddy page or NULL if not found.
*/
static inline struct page *find_buddy_page_pfn(struct page *page,
unsigned long pfn, unsigned int order, unsigned long *buddy_pfn)
{
unsigned long __buddy_pfn = __find_buddy_pfn(pfn, order);
struct page *buddy;
buddy = page + (__buddy_pfn - pfn);
if (buddy_pfn)
*buddy_pfn = __buddy_pfn;
if (page_is_buddy(page, buddy, order))
return buddy;
return NULL;
}
...
/*
* Freeing function for a buddy system allocator.
*
* The concept of a buddy system is to maintain direct-mapped table
* (containing bit values) for memory blocks of various "orders".
* The bottom level table contains the map for the smallest allocatable
* units of memory (here, pages), and each level above it describes
* pairs of units from the levels below, hence, "buddies".
* At a high level, all that happens here is marking the table entry
* at the bottom level available, and propagating the changes upward
* as necessary, plus some accounting needed to play nicely with other
* parts of the VM system.
* At each level, we keep a list of pages, which are heads of continuous
* free pages of length of (1 << order) and marked with PageBuddy.
* Page's order is recorded in page_private(page) field.
* So when we are allocating or freeing one, we can derive the state of the
* other. That is, if we allocate a small block, and both were
* free, the remainder of the region must be split into blocks.
* If a block is freed, and its buddy is also free, then this
* triggers coalescing into a block of larger size.
*
* -- nyc
*/
static inline void __free_one_page(struct page *page,
unsigned long pfn,
struct zone *zone, unsigned int order,
int migratetype, fpi_t fpi_flags)
{
struct capture_control *capc = task_capc(zone);
unsigned long buddy_pfn = 0;
unsigned long combined_pfn;
struct page *buddy;
bool to_tail;
VM_BUG_ON(!zone_is_initialized(zone));
VM_BUG_ON_PAGE(page->flags & PAGE_FLAGS_CHECK_AT_PREP, page);
VM_BUG_ON(migratetype == -1);
if (likely(!is_migrate_isolate(migratetype)))
__mod_zone_freepage_state(zone, 1 << order, migratetype);
VM_BUG_ON_PAGE(pfn & ((1 << order) - 1), page);
VM_BUG_ON_PAGE(bad_range(zone, page), page);
while (order < MAX_ORDER) {
if (compaction_capture(capc, page, order, migratetype)) {
__mod_zone_freepage_state(zone, -(1 << order),
migratetype);
return;
}
buddy = find_buddy_page_pfn(page, pfn, order, &buddy_pfn);
if (!buddy)
goto done_merging;
if (unlikely(order >= pageblock_order)) {
/*
* We want to prevent merge between freepages on pageblock
* without fallbacks and normal pageblock. Without this,
* pageblock isolation could cause incorrect freepage or CMA
* accounting or HIGHATOMIC accounting.
*/
int buddy_mt = get_pageblock_migratetype(buddy);
if (migratetype != buddy_mt
&& (!migratetype_is_mergeable(migratetype) ||
!migratetype_is_mergeable(buddy_mt)))
goto done_merging;
}
/*
* Our buddy is free or it is CONFIG_DEBUG_PAGEALLOC guard page,
* merge with it and move up one order.
*/
if (page_is_guard(buddy))
clear_page_guard(zone, buddy, order, migratetype);
else
del_page_from_free_list(buddy, zone, order);
combined_pfn = buddy_pfn & pfn;
page = page + (combined_pfn - pfn);
pfn = combined_pfn;
order++;
}
done_merging:
set_buddy_order(page, order);
if (fpi_flags & FPI_TO_TAIL)
to_tail = true;
else if (is_shuffle_order(order))
to_tail = shuffle_pick_tail();
else
to_tail = buddy_merge_likely(pfn, buddy_pfn, page, order);
if (to_tail)
add_to_free_list_tail(page, zone, order, migratetype);
else
add_to_free_list(page, zone, order, migratetype);
/* Notify page reporting subsystem of freed page */
if (!(fpi_flags & FPI_SKIP_REPORT_NOTIFY))
page_reporting_notify_free(order);
}
...
static void __free_pages_ok(struct page *page, unsigned int order,
fpi_t fpi_flags)
{
unsigned long flags;
int migratetype;
unsigned long pfn = page_to_pfn(page);
struct zone *zone = page_zone(page);
if (!free_pages_prepare(page, order, fpi_flags))
return;
/*
* Calling get_pfnblock_migratetype() without spin_lock_irqsave() here
* is used to avoid calling get_pfnblock_migratetype() under the lock.
* This will reduce the lock holding time.
*/
migratetype = get_pfnblock_migratetype(page, pfn);
spin_lock_irqsave(&zone->lock, flags);
if (unlikely(has_isolate_pageblock(zone) ||
is_migrate_isolate(migratetype))) {
migratetype = get_pfnblock_migratetype(page, pfn);
}
__free_one_page(page, pfn, zone, order, migratetype, fpi_flags);
spin_unlock_irqrestore(&zone->lock, flags);
__count_vm_events(PGFREE, 1 << order);
}
...
/*
* Free a pcp page
*/
void free_unref_page(struct page *page, unsigned int order)
{
unsigned long __maybe_unused UP_flags;
struct per_cpu_pages *pcp;
struct zone *zone;
unsigned long pfn = page_to_pfn(page);
int migratetype;
if (!free_unref_page_prepare(page, pfn, order))
return;
/*
* We only track unmovable, reclaimable and movable on pcp lists.
* Place ISOLATE pages on the isolated list because they are being
* offlined but treat HIGHATOMIC as movable pages so we can get those
* areas back if necessary. Otherwise, we may have to free
* excessively into the page allocator
*/
migratetype = get_pcppage_migratetype(page);
if (unlikely(migratetype >= MIGRATE_PCPTYPES)) {
if (unlikely(is_migrate_isolate(migratetype))) {
free_one_page(page_zone(page), page, pfn, order, migratetype, FPI_NONE);
return;
}
migratetype = MIGRATE_MOVABLE;
}
zone = page_zone(page);
pcp_trylock_prepare(UP_flags);
pcp = pcp_spin_trylock(zone->per_cpu_pageset);
if (pcp) {
free_unref_page_commit(zone, pcp, page, migratetype, order);
pcp_spin_unlock(pcp);
} else {
free_one_page(zone, page, pfn, order, migratetype, FPI_NONE);
}
pcp_trylock_finish(UP_flags);
}
...
static inline void free_the_page(struct page *page, unsigned int order)
{
if (pcp_allowed_order(order)) /* Via pcp? */
free_unref_page(page, order);
else
__free_pages_ok(page, order, FPI_NONE);
}
...
/**
* __free_pages - Free pages allocated with alloc_pages().
* @page: The page pointer returned from alloc_pages().
* @order: The order of the allocation.
*
* This function can free multi-page allocations that are not compound
* pages. It does not check that the @order passed in matches that of
* the allocation, so it is easy to leak memory. Freeing more memory
* than was allocated will probably emit a warning.
*
* If the last reference to this page is speculative, it will be released
* by put_page() which only frees the first page of a non-compound
* allocation. To prevent the remaining pages from being leaked, we free
* the subsequent pages here. If you want to use the page's reference
* count to decide when to free the allocation, you should allocate a
* compound page, and use put_page() instead of __free_pages().
*
* Context: May be called in interrupt context or while holding a normal
* spinlock, but not in NMI context or while holding a raw spinlock.
*/
void __free_pages(struct page *page, unsigned int order)
{
/* get PageHead before we drop reference */
int head = PageHead(page);
if (put_page_testzero(page))
free_the_page(page, order);
else if (!head)
while (order-- > 0)
free_the_page(page + (1 << order), order);
}
EXPORT_SYMBOL(__free_pages);
void free_pages(unsigned long addr, unsigned int order)
{
if (addr != 0) {
VM_BUG_ON(!virt_addr_valid((void *)addr));
__free_pages(virt_to_page((void *)addr), order);
}
}
EXPORT_SYMBOL(free_pages);
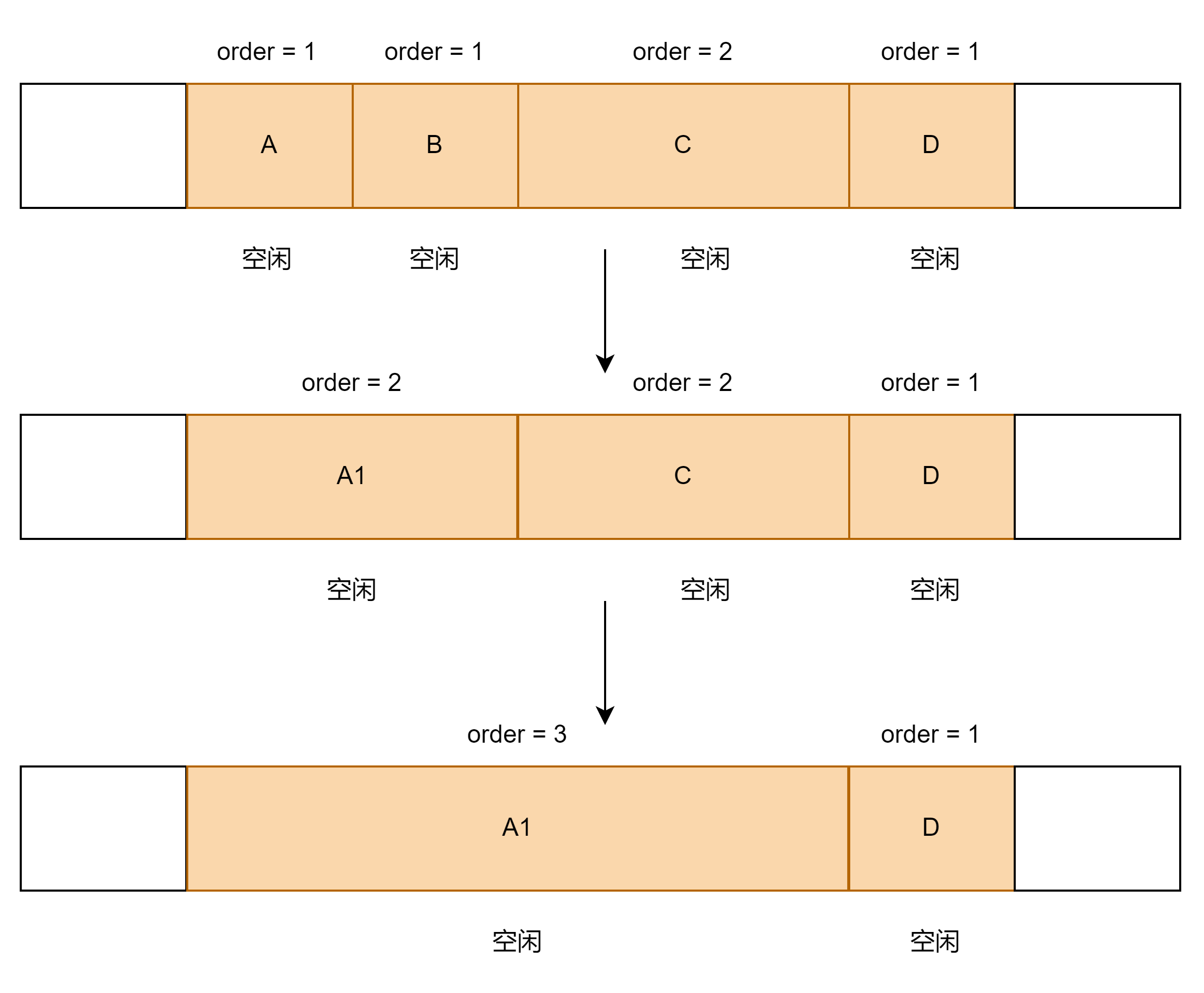
...它的思路通过以下几个例子说明:
① A/B/C/D为相邻的内存,现在要释放内存A,且B/C/D均为空闲状态。
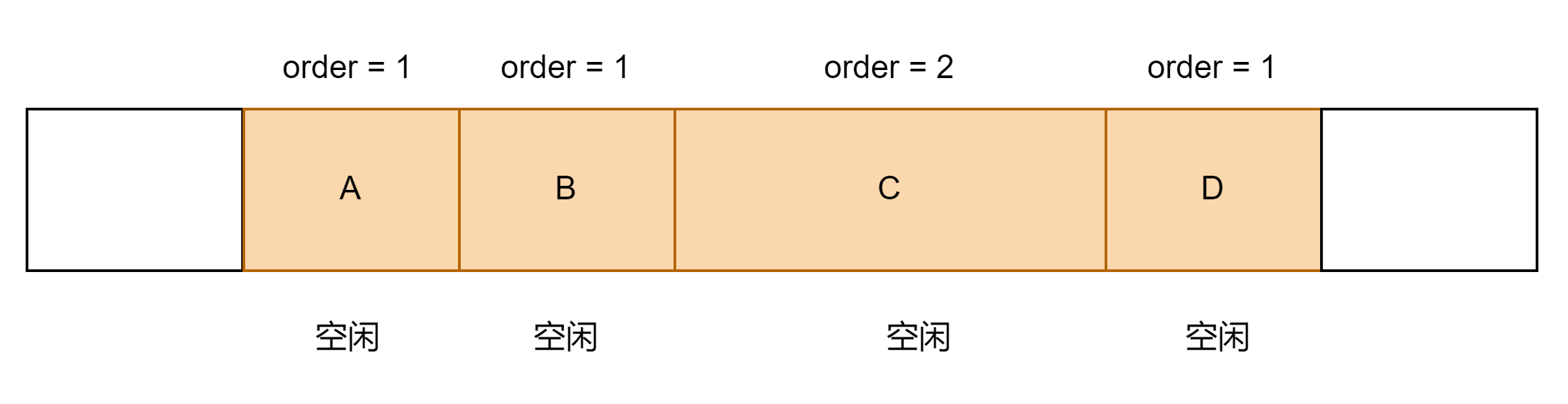
step1:内存A和内存B为相邻内存,我们判断这两块内存是否为buddy关系, 如果为buddy关系,就将这两块内存合并
step2:满足条件后,内存A和内存B互为伙伴,我们将这A和B两块内存合并,并将合并的内存A1 和相邻内存C进行比较,A1和C互为伙伴,将A1和C两块内存合并。
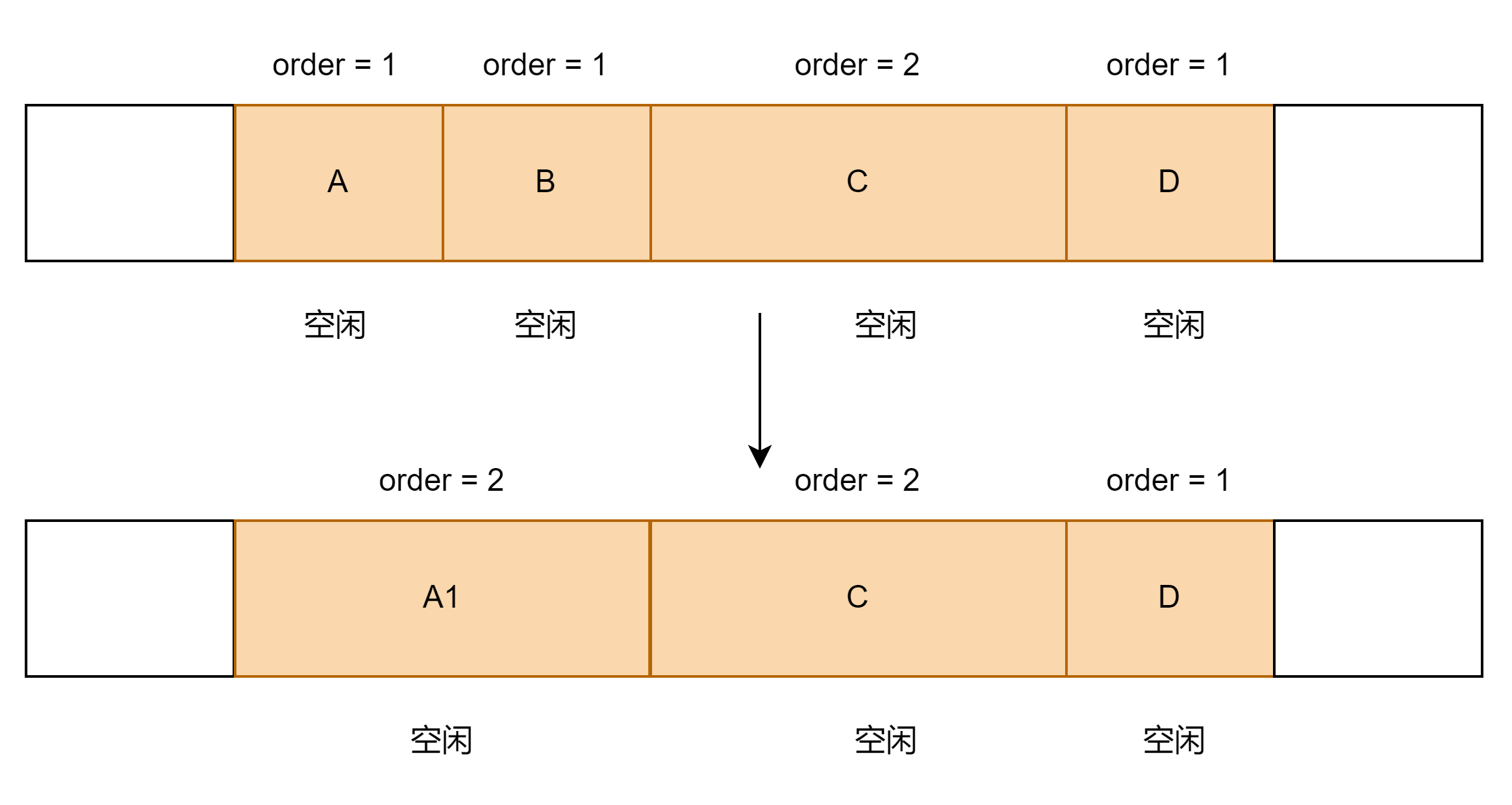
step3:以此类推,直到将能合并的内存块处理完
②A/B/C/D为相邻的内存,现在要释放内存A,且B/D均为空闲状态,C为非空闲状态。
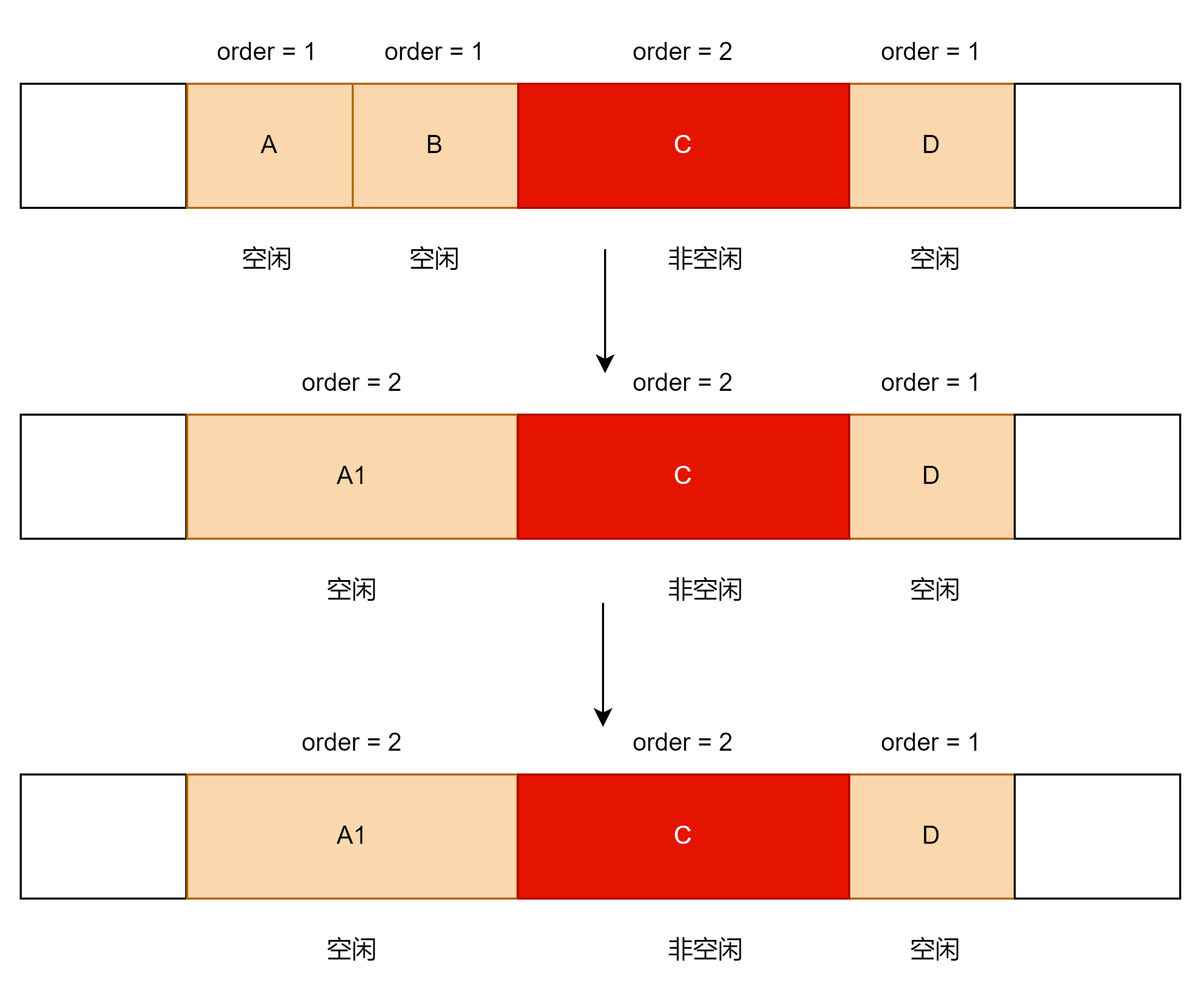
step1:内存A和内存B为相邻内存,我们判断这两块内存是否为buddy关系, 如果为buddy关系,就将这两块内存合并
step2:满足条件后,内存A和内存B互为伙伴,我们将这A和B两块内存合并,并将合并的内存A1 和相邻内存C进行比较,A1和C互为伙伴,但是C在用,不能将A1和C两块内存合并。
三、伙伴系统优缺点
1.优点
伙伴系统能够解决内存外部碎片问题,当需要分配若干个内存页面时,用于DMA的内存页面必须连续,伙伴算法很好的满足了这个要求。只要请求的块不超过1024个页面,内核就尽量分配连续的页面。
2.缺点
①合并的要求太过严格,只能是满足伙伴关系的块才能合并。
②. 碎片问题:一个连续的内存中仅仅一个页面被占用,导致整块内存区都不具备合并的条件
③. 浪费问题:伙伴算法只能分配2的幂次方内存区,当需要2的幂次时,好说,当需要35K时,那就需要分配64K的内存空间,但是实际只用到35K空间,多余的29K空间就被浪费掉。
4. 算法的效率问题: 伙伴算法涉及了比较多的计算还有链表和位图的操作,开销还是比较大的,如果每次2^n大小的伙伴块就会合并到2^(n+1)的链表队列中,那么2^n大小链表中的块就会因为合并操作而减少,但系统随后立即有可能又有对该大小块的需求,为此必须再从2^(n+1)大小的链表中拆分,这样的合并又立即拆分的过程是无效率的。
















 1148
1148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











