







一、简介
在电子数字的世界里,所有的信息都是以简单的“0”与“1”表示;不过当数据在电子元件间进行传递时,是有可能发生数据“误传”的情形,也就是说原来该是0的比特数据,却被误植为1的比特数据,而产生错误。其可能发生的原因相当多,包括电子噪声、元件硬件上的问题,或是传输接口不稳等,都可能造成如此的结果。
而ECC(Error Correcting Code),中文全称为错误纠正码,就用于对存储器的数据进行完整性检查和纠正,主要用在SRAM、DDR、NAND等存储器设备上。ECC可以对数据进行单比特的纠错和多比特的检错,其原理基于汉明码编码而来。
直接看百度百科说明:百度百科-验证
ECC 具有如下特点:
• ECC 按照最小 ECC 计算单元进行组织,因此,即使仅写入一个字节,也将以这个储存单元的数据进行 ECC 计算并储存;所以按照存储器的 ECC 计算单元来写入存储器数据是最高效的;
• ECC 结果储存位不占用用户存储器地址空间,且其中的 ECC 对用户不可见(通过调试器也无法读取,因为其未做存储器地址映射);
• 对 NVM(EEPROM 和 Flash)的 和 都将产生 ECC 结果并储存;
• 只有对存储器数据进行读取时,才检查 ECC,也就意味着,只有读取存储器时才会触发 ECC 错误,注意 NVM 的 Verify 也是一个读取储存器的过程,因此 verify 也会触发ECC 错误;
• 因为单比特翻转的概率远大于 2-比特和多比特翻转,而实现多比特纠错需要更佳复杂的 ECC 算法和储存更多位的 ECC 计算结果,所以在通常的存储器ECC都仅支持单比特纠错,多比特检错。
二、原理
1、如何产生和纠正
前面提到Parity(奇偶校验),它的原理很简单。
一个奇偶校验位是用来添加至二进制数据中的比特位,他通过确保整个二进制数据信息中“1”的个数是奇数还是偶数,来判断数据是否在传输过程中发生的改变。因此,存在两种类型的检测方式:
1)奇校验
在奇校验检测方式中,对于需要发送的数据信息比特,检查其中1的个数。如果这串比特中1的个数是奇数,为了保证加上“冗余位“后,””整串数据中1的个数最后为奇数,可想而知,冗余位上应该设置为“0”。
如果在没有添加“冗余位”之前,数据比特流中的1的个数为偶数,那么为了最后把1的个数凑成一个奇数,冗余位上应该设置为1。
2)偶校验
同理,在偶校验检测方式中,对于需要发送的数据信息比特,仍然检查其中1的个数。如果这串比特中1的个数是奇数,为了保证加上“冗余位“后,””整串数据中1的个数最后为偶数,可想而知,冗余位上应该设置为“1”。
如果在没有添加“冗余位”之前,数据比特流中的1的个数为偶数,那么为了最后把1的个数凑成一个偶数,冗余位上应该设置为0。
例如以下示例:
写入场景1(偶数个1场景):

写入场景2(奇数个1场景):

读取场景1(数据‘101’,发生1位数据出错):

读取场景2(数据‘101’,发生2位数据出错):

说明:
①Parity(奇偶校验)只能够检测出奇数个数据出错的场景,无法检测出偶数个出错场景
②Parity(奇偶校验)只能检测出数据有错,但是无法得知出错的位在哪个位置
③由于Parity(奇偶校验)无法知道哪个位数据出错了,所以就不能准确纠正数据错误
而ECC其实就是“奇偶校验法”的升级版,它是多个“奇偶校验法”的组合糅合在一起,但是奇偶校验位的位置不一定再是最后一位了,而是有其他的计算方法。ECC不仅可以确定哪个位的数据出错了,还能减少需要增加的校验数据位数。它结合了汉明码算法,汉明码是一种“错误纠正码”,可以用来检测并且纠正数据从发送端发往接收端中发生的错误。
由于汉明码将所有2的幂次位做为“奇偶校验位”,因此2^0=1,2^1=2,2^2=4,2^3=8……也就是第1位,第2位,第4位,第8位...就成为了奇偶校验位,其他位为数据位。
比如数据1011001+海明校验码则需要11位编码数(n+k+1 <= 2^k即7+k+1<=2^k,则k=4,7+4=11位),所以数据1011001整个信息流有11个二进制位,它的校验位就包含以下几个
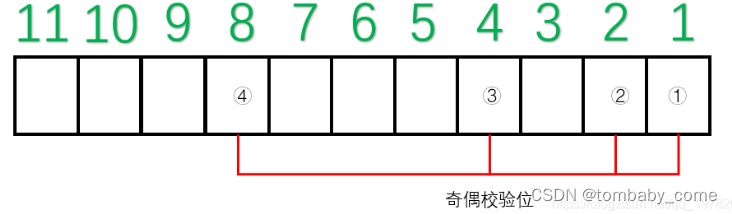
那这4个校验位对应的校验的数据位是哪些,这个就依据数据位索引的二进制表示中,对应的第x位都为1的所有索引号.
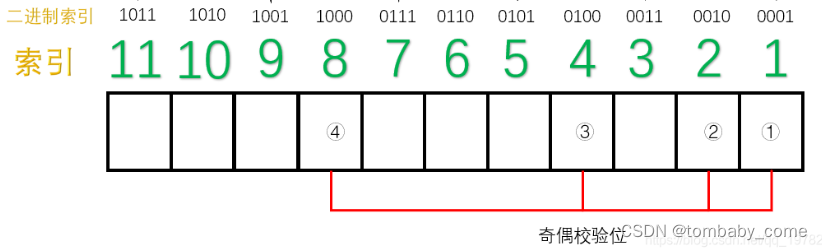
即:
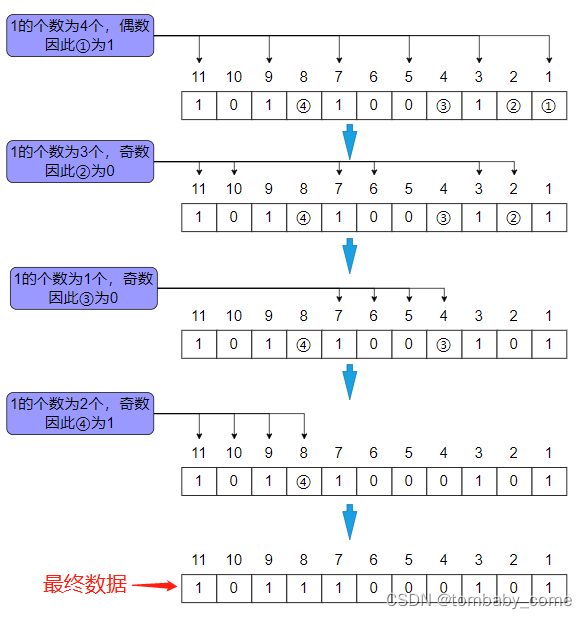
①二进制表示中,从右往左数第1位为1的所有索引,即1011,1001,0111,0101,0011,0001,分别对应的10进制索引为:11,9,7,5,3,1;
②二进制表示中,从右往左数第2位为1的所有索引,即1011,1010,0111,0110,0011,0010,分别对应10进制索引为:11,10,7,6,3,2;
③二进制表示中,从右往左数第3位为1的所有索引,即0111,0110,0101,0100,分别对应10进制索引为:7,6,5,4;
④二进制表示中,从右往左数第4位为1的所有索引,即1011,1010,1001,1000,分别对应10进制索引为:11,10,9,8。
如下表
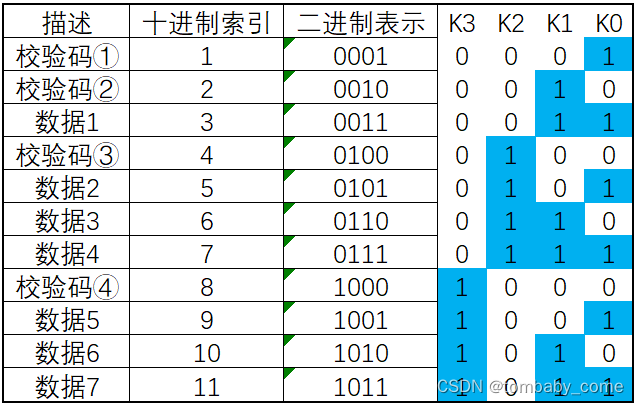
索引当写入数据时,最终写入的数据为:
读取数据时的“纠错”和“改正”:
上面,我们已经完成了“汉明码”的编码,那么,汉明码又是如何发现错误以及改正错误的呢?
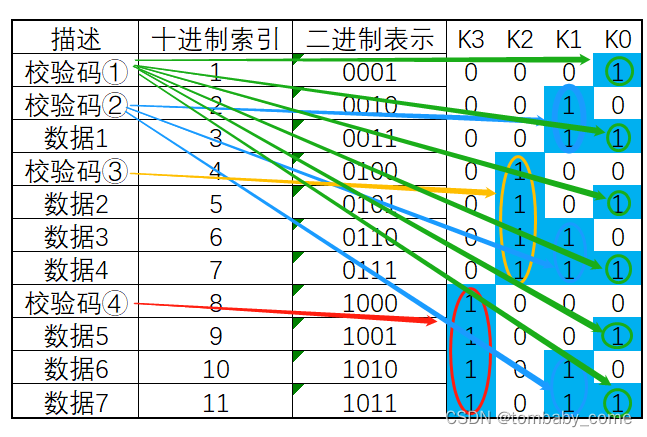
假设,第“5”号位上的“0”在传输过程中变成了“1”,接收方收到的数据则为:10111010101。
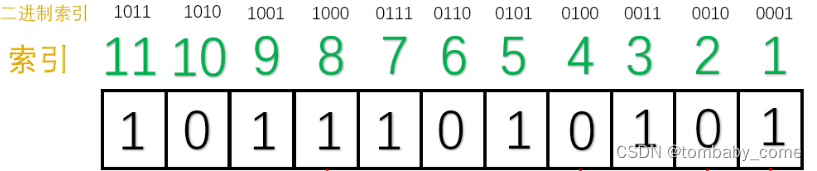
汉明码通过检查每一小组的“奇校验”,来确定是否发生了错误。
首先第一组(1,3,5,7,9,11位):1的个数为6位,不再是奇数个了,因此,我们可以断定,这一组中肯定有某个数据发生了错误,但不能确定是哪一位上发生了错误。为了达到“奇校验”,我们必须补1个1来达到奇数个1。
接下来,我们检查第二组(2,3,6,7,10,11) ,1的个数为3位,仍然满足“奇校验”,因此我们也可以断定这一组中没有任何一位数据发生了改变。所以,我们只需要补0。
我们继续检查第三组(4,5,6,7),1的个数为2个,不在满足“奇校验”,因此,我们可以断定,这一组中也有数据发生改变。为了达到“奇校验”,我们必须补1个1来达到奇数个1。
我们检查第4组(8,9,10,11位),1的个数为3位,满足“奇校验”,因此没有发生改变。所以我们只需要补0。
如下图所示:
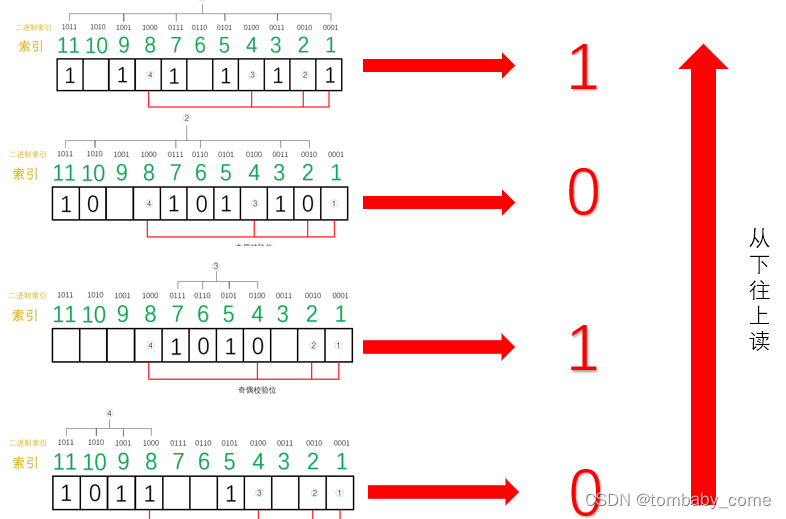
最后得出来的二进制数是:0101,我们会神奇地发现,0101就是10进制5的二进制表现,因此,我们可以准确的知道,5号位上发生了数据的改变,我们只要对5号位进行置反操作即可。最后,接收方就可以修改成为正确的数据啦。
同理,任何一个位置的数据发生错误,ecc都是能检测出来并且进行纠正的。
除了能够检查到并改正单比特错误之外,ECC码还能检查到(但不改正)单DRAM芯片上发生的任意2个随机错误,并最多可以检查到4比特的错误。当有多比特错误发生的时候,ECC内存会生成一个不可隐藏(non-maskable interrupt)的中断(NMI),会中止系统运行,以避免出现数据恶化。
显然ECC码的长度跟数据的长度是成对数关系,如下表为Parity和ecc校验数据位的对比:
| 数据位数 | Parity需要增加的数据位数 | ECC需要增加的数据位数 |
| 8 | 1 | 5 |
| 16 | 2 | 6 |
| 32 | 4 | 7 |
| 64 | 8 | 8 |
| 128 | 16 | 9 |
| 256 | 32 | 10 |
| 512 | 64 | 11 |
| 1024 | 128 | 12 |
| 2048 | 256 | 13 |
| 4096 | 512 | 14 |
| 8192 | 1024 | 15 |
显然当数据长度在64位以上的时候,ECC码在空间占用上就会凸现优势。
此外,ECC校验最大的优点是如果数据中有一位错误,它不但能发现而且可以对其更正,ECC校验还可以发现2~4位错误(不能更正),当然这样的情况出现的几率是非常低的。但ECC码的校验算法比奇偶校验复杂不少,需要专门的芯片来支持,所以普通的电脑主板不一定支持。而且因为系统需要时间来等待校验的结果,所以ECC校验会降低系统速度2%-3%左右,但这小小的代价换来系统稳定性的大大提高可以说事非常值得的。
2、发生概率
2009年,Google和多伦多大学公布的一项研究结果表明,DRAM内存模块的数据错误率要远远高于人们的预想,而且更有可能成为系统宕机和服务中断的罪魁祸首。这项研究采用了上百万台Google服务器,结果表明所有DIMM中有大约8.2%受到了可修正错误的影响,平均一个DIMM每年要发生3700次可修正错误。
也就是每个 DIMM 位置每24小时内约10个事件,一天10个bit错误,再算到16G内里的比例,再加上这10个bit出错的地址又正好是写入过数据后发生出错直到又被需要读取的概率,多方面综合下来概率可以说是非常非常的低了。
也因为它的概率极低,个人用户根本不需要使用ecc内存,而对于7*24小时在线的服务器则往往会考虑ecc内存(内存条价格提升20%,内存性能损失2-3%)以保证系统的稳定性。
三、实践
ras.rst « admin-guide « Documentation - kernel/git/stable/linux.git - Linux kernel stable tree这里有关于ECC的说明指导文档,这里不做说明了,感兴趣可以看下。
einj.rst « apei « acpi « firmware-guide « Documentation - kernel/git/stable/linux.git - Linux kernel stable tree这里是手动模拟内存错误的指导文档
1、模拟步骤:
(1)前置条件确认
①# 查看是否存在EINJ表
# ls /sys/firmware/acpi/tables/EINJ
②# grep <以下字段> /boot/config-xxx
CONFIG_DEBUG_FS=y
CONFIG_ACPI_APEI=y
CONFIG_ACPI_APEI_EINJ=m
③# modprobe einj
④其他确认
# 查看内存地址范围,这一步是因为/proc/iomem这个文件记录的是物理地址的分配情况,有些内存地址是系统预留存放以及其他设备所占用的,无法进行错误注入。
# cat /proc/iomem | grep "System RAM"
00001000-000997ff
00100000-69f79fff
6c867000-6c9e6fff
6f345000-6f7fffff
100000000-407fffffff
# 查看内存页大小
# getconf PAGESIZE
4096 即4KB
# cat /proc/mounts | grep debugfs
debugfs /sys/kernel/debug debugfs rw,relatime 0 0
即先要确保内核开启了DEBUG_FS和ACPI_APEI功能,然后还需要加载einj驱动,modprobe einj,且操作RAM地址。
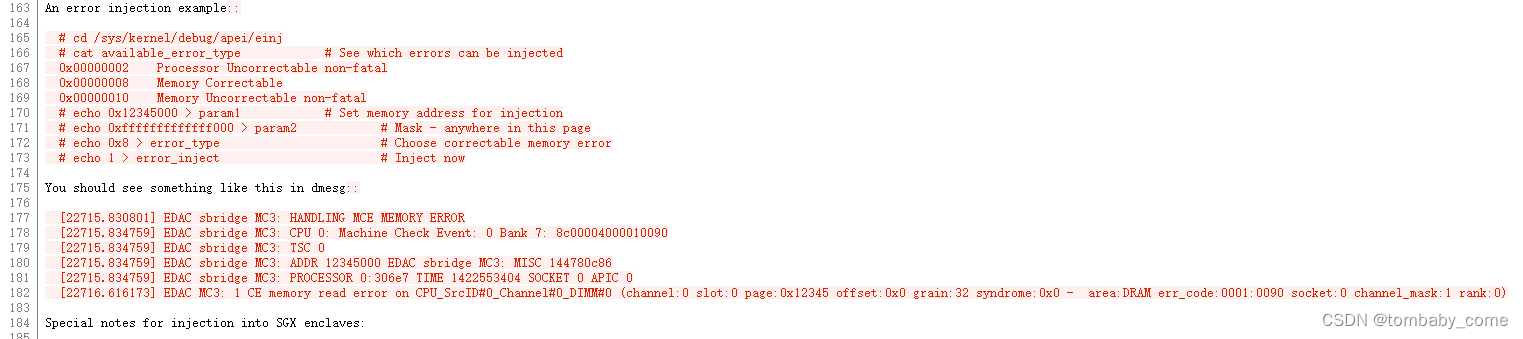
(2)实际模拟核心步骤
# cd /sys/kernel/debug/apei/einj # cat available_error_type # See which errors can be injected 0x00000002 Processor Uncorrectable non-fatal 0x00000008 Memory Correctable 0x00000010 Memory Uncorrectable non-fatal # echo 0x12345000 > param1 # Set memory address for injection # echo 0xfffffffffffff000 > param2 # Mask - anywhere in this page # echo 0x8 > error_type # Choose correctable memory error # echo 1 > error_inject # Inject now
(3)模拟结果
2、采集事件实践
所有的元器件上都会有传感器,上报硬件状态信息,我们可以通过ipmitools去查看内存事件,可以通过ipmi界面显示的日志查看有无相关信息,或者直接命令行查看ipmitool sdr和ipmitool sensor等用法,可以对元器件状态信息进行采集和观察。不多介绍了,感兴趣自己研究吧。



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











