







一,背景:
现有的分类器的设计都是基于类分布大致平衡这一假设的,通常假定用于训练的数据集是平衡的,即各类所含的样本数大致相当,然而这一假设在很多现实问题中是不成立的,数据集中某个类别的样本数可能会远远少于其它类别。许多实际的应用领域中都存在不均衡数据集,例如欺骗信用卡检测、医疗诊断、信息检索、文本分类等。还有些不平衡数据问题是来自于 多类(Multi-Class)问题和多类标(Multi-Label)问题 的分解。有些分类算法如 支持向量机(SVM) ,并不能直接应用于多个类别的分类问题,首先要将原 始问题分解成多个二类分类的子问题来解决,这样很容易导致分类数据的特 点由原来的平衡变成不平衡,原来不平衡的问题变得更加不平衡。
不平衡数据分类问题的难点:
不同于均衡数据的分类,不平衡数据的分类问题求解相对较难,其主要原因如下:
(1) 经典的分类精度评价准则不能适用于不平衡数据的分类器性能判别.在传统机器学习中通常采用分类精度作为评价准则,当对不平衡数据进行学习时,少数类对分类精度的影响可能会远远小于多数类.Weiss实验研究表明,以分类精度为准则的分类学习通常会导致少数类样本的识别率较低[1],这样的分类器倾向于把一个样本预测为多数类样本.若训练数据是极端不平衡的,学习的结果可能没有针对少数类的分类规则,因此对于不平衡数据的分类,以高分类精度为目标是不合适的,需要引入更加合理的评价标准[2].
(2) 仅有很少的少数类样本数据.仅有很少的少数类样本分两种情况:少数类样本绝对缺乏和少数类样本相对缺乏.无论哪种情况,我们称类分布的不平衡程度为少数类中的样本数与支撑类中的样本数之比.在实际应用中,该比例可以达到1∶100、1∶1000甚至更大.文献[1]对该比例与分类性能之间的关系进行了深入的研究,研究结果表明很难明确地给出何种比例会降低分类器的性能,这是因为分类器的性能还与样本数和样本的可分性有关.在某些应用下,1∶35的比例就会使某些分类方法无效,甚至1∶10的比例也会使某些分类方法无效.
对情况1,因少数类所包含的信息就会很有限,从而难以确定少数类数据的分布,即在其内部难以发现规律,进而造成少数类的识别率低.已有研究表明分类器的误差率大多源于小析取项[3].事实上小析取项本质上并非比大析取项更容易产生错误,使小析取项更容易产生错误的原因有分类器的偏移、噪声的干扰和缺失属性等.为有效避免因噪声信息的影响,如何判别有意义的小析取项是值得研究的课题[3,4].
对情况2,少数类样本数据相对缺乏,不同于少数类样本数据的绝对缺乏,相对缺乏是指少数类样本在绝对数量上并不少,但相对于多数类来说它的样本数目很少.在样本相对缺少的情况下,同样不利于少数类的判别,这是因为多数类样本会模糊少数类样本的边界,且使用贪心搜索法难以把少数类样本与多数类区分开来,而更全局性的方法通常难以处理[5]
.
(3) 数据碎片.从算法设计角度看,很多分类算法采用分治法,这些算法将原始的问题逐渐分为越来越小的一系列子问题,因而导致原空间被划分为越来越小的一系列子空间,样本空间的逐渐划分会导致数据碎片问题,这样只能在各个独立的子空间中寻找数据的规律,对于少数类来说每个子空间中包含了很少的数据信息,一些跨空间的数据规律就不能被挖掘出来[5].数据碎片问题也是影响少数类样本学习的一个突出的问题.
(4) 不恰当的归纳偏置.根据特定样本的归纳需要一个合理的偏置[3],否则学习就不能实现.归纳偏置对算法的性能有着很大的影响,为了获得较好的性能并避免过度拟合,许多学习算法使用的偏置往往不利于对少数类样本的学习.许多归纳推理系统在存在不确定时往往倾向于把样本分类为多数类.可见,不恰当的归纳偏置对不平衡数据的学习是不利的.此外,大多数分类器的性能都会受噪声的影响.在不平衡问题中,由于少数类的数量很少,因此分类器有可能难以正确区分少数类和噪声,故噪声对少数类的影响要大于对多数类的影响.噪声的存在使防止过拟合技术变得非常重要,如何抑制噪声、强化少数类样本的作用是具有挑战性的研究工作.
二,不平衡数据分类的相关方法:
目前不平衡数据分类的相关方法主要
- 从数据层面-改变数据的分布
- 算法层面-设计新的分类方法
- 判别准则-设计新的分类器性能评价准则
(一) 数据层面
从数据层面采用的策略来看,大体上采用过抽样、欠抽样两种方法.具有描述如下:
(1)过抽样.(over-sampling)
抽样处理不平衡数据的最常用方法,基本思想就是通过改变训练数据的分布来消除或减小数据的不平衡.过抽样方法通过增加少数类样本来提高少数类的分类性能[6],最简单的办法是简单复制少数类样本,缺点是引入了额外的训练数据,会延长构建分类器所需要的时间,没有给少数类增加任何新的信息,而且可能会导致过度拟合.改进的过抽样方法通过在少数类中加入随机高斯噪声或产生新的合成样本等方法,一定程度上解决了上述问题,如Chawla等人提出的SMOTE算法[7].此外,文献[8]提出了一种基于初分类的过抽样算法,基本思想是:一个多数类样本,若它在训练集中的k个近邻也都属于多数类,根据k近邻的思想则该样本离分类边界较远,对分类是相对安全的.将多数类中满足上述条件的所有样本放入集合E,将少数类与集合E合并记为训练集A,利用A对多数类样本进行最近邻分类,误分类的多数类样本放入集合H.将少数类和集合H合并为第二个新的训练集B.
- SMOTE算法
主要算法思想:
对少数类的每一个样本x,搜索其k个最近邻,然后随机选取这k个最近邻中的一个设为
x
∗
x^*
x∗,再在x与
x
∗
x^*
x∗之间进行随机线性插值,构造出新的少数类样本,即新样本
x
n
e
w
=
x
+
r
a
n
d
(
0
,
1
)
×
(
x
∗
−
x
)
x_{new}=x+rand(0,1) × (x^* - x)
xnew=x+rand(0,1)×(x∗−x)
重复上述步骤增加更多构造样本。
(SMOTE算法增加的样本一般集中在原始样本分布的内部,在边缘处较少)
R包:DMwR
基于SMOTE还衍生出了MSMOTE,去除噪声和利群点。
(2)欠抽样.(under-sampling)
欠抽样方法通过减少多数类样本来提高少数类的分类性能,最简单的方法是通过随机地去掉一些多数类样本来减小多数类的规模,缺点是会丢失多数类的一些重要信息,不能够充分利用已有的信息[9].因此人们提出了许多改进的欠抽样方法.Kubat等人提出的One-sided selection算法尽可能地不删除有用的样本,多数类样本被分为“噪音样本”、“边界样本”和“安全样本”,将边界样本和噪音样本从多数类中删除,得到的分类效果会比随机欠抽样理想一些.也可以把对少数类的过抽样与对多数类的欠抽样两者结合起来[7].One2sidedselection算法是通过判断样本间的距离的方式来把多数类划分为“噪音样本”、“边界样本”和“安全样本”的,文献[10]提出了一种基于geneticalgorithms(GA)的方式来对多数类进行抽样,找出噪音样本并将它们去除.文献[11]提出了一种基于聚类的欠抽样算法,先用聚类的方法将训练集划分成几个簇,每个簇都包含一定数目的多数类和少数类,对每个簇,取出其中所有的少数类,然后按照一定规则对该簇中的多数类进行欠抽样,最后将从每个簇中取出的样本进行合并,得到一个新的训练集,对其进行训练.
Informed undersampling采样技术,也可以解决随机欠采样造成的数据信息丢失问题。informed undersampling采样技术主要有两种方法分别是EasyEnsemble算法和BalanceCascade算法。
-
EasyEnsemble算法类似于随机森林的Bagging方法,它把数据划分为两部分,分别是多数类样本和少数类样 本,对于多数类样本S_maj,通过n次有放回抽样生成n份子集,少数类样本分别和这n份样本合并训练一个模型,这样可以得到n个模型,最终的模型是 这n个模型预测结果的平均值。
-
BalanceCascade算法是一种级联算法,BalanceCascade从多数类中有效地选择N…。依次迭代直到满足某一停止条件,最终的模型是多次迭代模型的组合。
(二) 算法层面
(1)代价敏感方法.在处理不平衡问题时,传统的分类器对少数类的识别率很低,对多数类的识别率却很高,然而在现实生活中往往是少数类的识别率更为重要,因此少数类的错分代价要远远大于多数类.例如在入侵检测中,可能在1000次通信中只有少数几次是攻击,但将攻击误报为正常和将正常误报为攻击所引起的代价是截然不同的.在代价敏感学习方法中,代价信息通常由领域专家给出,在进行学习时假设各个类别的代价信息是已知的,在整个学习过程中是固定不变的.
目前对代价敏感学习的研究主要集中在以下两个方面:(引入正则化项)
- 根据样本的不同错分代价重构训练集,不改变已有的学习算法.重构训练集的方法是根据样本的不同错分代价给训练集中的每一个样本加权,接着按权重对原始样本集进行重构,但其存在的缺点就是重构的过程中丢失了一些有用样本的信息.
- 在传统的分类算法的基础上引入代价敏感因子,设计出代价敏感的分类算法.代价敏感的学习中不同类的错分代价是不同的,通常多数类的代价比少数类大得多,对小样本赋予较高的代价,大样本赋予较小的代价,期望以此来平衡样本之间的数目差异[12].文献[13]对Veropoulos的代价敏感SVM进行了改进,但基本思想都是将代价与松弛变量相关联来使SVM的超平面对代价敏感.Lee等人为多类问题设计了代价敏感的SVM,并考虑了采样偏置[14].文献[15]提出了一种加权Fisher线性判别模型(WFLD),通过对正负两类的类内离散度矩阵进行分别加权,使正负两类样本的协方差矩阵对总类内离散度矩阵的贡献平衡.但这些代价敏感学习方法主要是针对全局模型.为此,文献[16]提出了一种局部代价敏感算法,预测一个新样本时,首先选定一种合适的距离度量方式,选出该测试样本的k个近邻,然后用加权的方式对这k个近邻进行训练,得到一个分类器用来进行预测.
(2) 集成学习方法.按照基本分类器之间的种类关系可以把集成学习方法划分为异态集成学习和同态集成学习两种[17],异态集成学习指的是使用各种不同的分类器进行集成,同态集成学习是指集成的基本分类器都是同一种分类器,只是这些基本分类器之间的参数有所不同.在不平衡数据的分类问题上,由于异态集成学习的每个基本算法都有独到之处,因而某种基本算法会对某类特定数据样本比其余的基本算法更为有效.同态集成学习方法中针对不平衡数据的多数是把抽样与集成结合起来,对原始训练集进行一系列抽样,产生多个分类器,然后用投票或合并的方式输出最终结果.AdaBoost应用于不平衡数据分类可取得较好效果,但有实验结果表明AdaBoost提高正类样本的识别率的能力有限[18],因为AdaBoost是以整体分类精度为目标的,负类样本由于数目多所以对精度的贡献大,而正类样本由于数目很少因此贡献相当小,故分类决策是不利于正类的.为此,一些改进相继被提出,如AdaCost[19]、RareBoost[20],主要策略是改变权值更新规则,使分类错误的正类样本比负类样本有更高的权值.文献[21,22]将过抽样与集成方法进行融合,既能利用过抽样的优点增加少数类样本的数量,使分类器能够更好地提高少数类的分类性能,又能利用集成方法的优点提高不平衡数据集的整体分类性能,如文献[23]提出的C2SMOTE算法就是过抽样和集成结合的成功例子.
(3) 单类分类器方法.在实际应用中有时想要获取两类或多类样本是很困难的,或者就是需要很高的成本,只能获取单类样本集.在这种情况下,对只含有单一类的数据进行训练是唯一可能的解决办法.单分类器是用来对只有一种类别的训练集进行分类的,它是一个能有效解决不平衡数据问题的办法[3].文献[13]用SVM来仅对正类进行训练,实验表明该方法是有效的.单类分类器由于只需要一类数据集作为训练样本,训练数据量变小了,从而减少了构建分类器所需要的时间,节约了开销,因此在很多领域都有着良好的应用前景.
(4) 面向单个正类的FLDA方法.某些极端的情况下,少数类只有一个样本.针对该情况,文献[24]提出了一种解决单个正例的Fisher线性判别方法,找出单个正例在负类中的k个近邻,然后按照一定规则依次在单个正例和它的各个近邻的连线上产生合成样本,并把这些合成样本添加到原始的正类中,再用分类器进行分类.
(5) 多类数据不平衡问题的解决方法.目前针对多类的不平衡问题研究较少,通常仍然采用已有的多类分类方法和两类不平衡分类策略结合.Lee等人结合采样偏置[14],提出针对多类的代价敏感的SVM.文献[25]用k个超球来对k类数据进行描述,其中每个超球包含一类数据.WangDefeng等人提出了结构性单分类器(StructuredOne2ClassClassification),考虑了数据分布情况,将一类目标数据用多个超椭球来描述,通过对目标类的描述将目标数据与非目标数据分开.文献[3]在StructuredOne2ClassClassification的基础之上对多类样本中的每一类都用多个超球描述,而不仅将一类目标数据用多个超球来描述,该算法根据每一类样本的数目多少用多个超球来包围起来,以获得比单个超球更好的描述.
(6) 其它方法.主动学习[27]、随机森林[28]、子空间方法[29]、特征选择方法[30,31]和SVM模型下的后验概率求解方法[32]等也是学习不平衡数据集的有效方法
(三) 判别层面
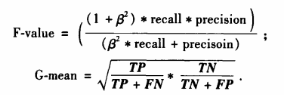
传统的根据混淆矩阵来计算出的,准确率、精确率是对数据集的整体分类性能进行评价的,但是不能反映不平衡数据集的分类性能。
举例,一个正例只占5%的样本,一个分类器,可以把所有样本判为负类,则准确率有95%…
传统的一些方法有 F值,G-mean,公式如下:














 3645
3645











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









