







 本文探讨了回归模型中特征变量的筛选方法,包括逐步回归、全子集回归及各种模型评估指标,如R2、调整的R2、Mallows' Cp统计量、信息量准则、预测平方和与预测拟合优度。
本文探讨了回归模型中特征变量的筛选方法,包括逐步回归、全子集回归及各种模型评估指标,如R2、调整的R2、Mallows' Cp统计量、信息量准则、预测平方和与预测拟合优度。
简介
根据前两节的内容,我们的模型就建立完成了嘛?答案是 NO。
如果我们有10个候选变量,每个候选变量在回归模型中都有选中和非选中两种状态,那么模型的组合形式有 2 10 = 1024 2^{10}=1024 210=1024种。假设用了显著性的检验,以及诊断检验方法后,还有24种模型,那我们要如何选择呢 ?
回归模型对于特征变量的选取有下面四种形式:
- 变量与实际情况基本吻合
- 缺失了几个相关的重要变量(不用关心缺失不重要变量的情况)
- 多了几个无关变量
- 多了几个相关的冗余变量
我们如何选取一个模型避免上述后三种情况呢?
本章主要介绍经典统计学上的特征变量筛选的方法,与第四章的“一,经典统计方法”一致。所以第四章中,也没有重复表述。
正文
一,逐步回归法
逐步回归有向前回归(逐个加入变量),与向后回归(逐个剔除变量)两种策略。
这种逐步的循环会比较上一次的结果,用若干个衡量模型好坏的指标,直到指标不再有大幅度改善变好为止,停止策略。
以向前回归为例,有我们有四个变量,数据如文件内容
1,分别对四个变量进行回归
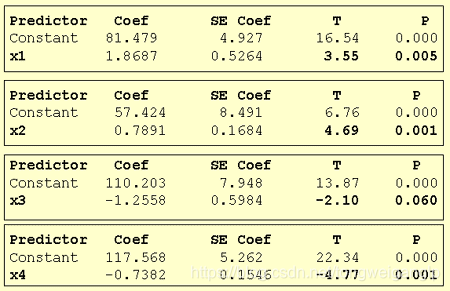
根据t分布的特点,我们得到 x 4 x_4 x4的P值更小,所以我们第一项先选 x 4 x_4 x4.
2,定了一个变量后,再依次添加其余变量
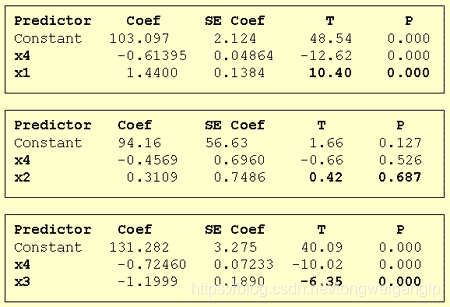
根据t分布的特点,我们得到 x 1 x_1 x1的P值更小,所以我们第二项先选 x 1 x_1 x1.
3,定了两个变量后,再依次添加其余变量
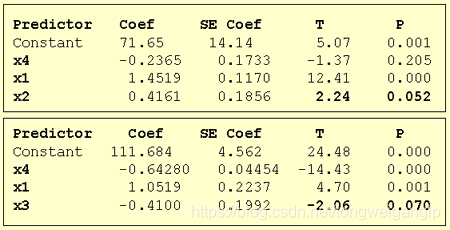
根据t分布的特点,我们得到
x
2
x_2
x2的P值更小,所以我们第二项先选
x
2
x_2
x2.
但是我们却看到,最开始入选的
x
4
x_4
x4反而变的不显著了。
4,我们再去掉
x
4
x_4
x4看看
x 1 , x 2 x_1,x_2 x1,x2之间的显著性比以前更低,所以我们重新确定选取的两个变量为 x 1 , x 2 x_1,x_2 x1,x2再依次添加其他变量。
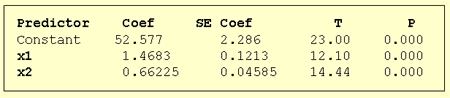
5,选定
x
1
,
x
2
x_1,x_2
x1,x2
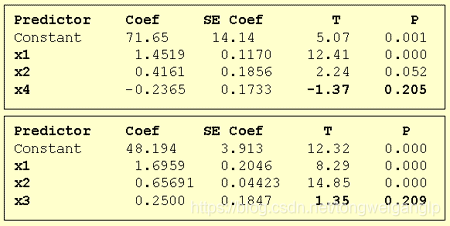
x 3 , x 4 x_3 ,x_4 x3,x4都不显著了,所以最终我们的回归模型选择的变量是 x 1 , x 2 x_1,x_2 x1,x2
注意:我们不能因此过分注重逐步回归的结果,因为依然可能存在下面的问题:
- 可能依旧存在简介中描述的四种形式的问题
- 逐步回归的结果可能最后有若干个相似模型
二,全子集回归,又叫最优子集回归
步骤:
step1,构建全部可能的回归模型
step2,从中挑选出最好的模型
注意:该方法不适合太复杂,候选变量太多的情况,如开篇所说,10个候选变量就能组合出1024种回归模型,随着候选变量的增多,回归模型的数量会指数增加。
三,如何定义”最好“
除了,显著性检验以外,用什么指标来衡量模型所选取的候选变量是最好的结果呢?
下面我们来介绍几种度量指标。
1, R 2 R^2 R2
由前两节我们讲到,对于多元线性线性回归模型, R 2 R^2 R2会随着变量的增加而增加。所以单独看拟合优度的量级是没有意义的。此处我们比较的是 R 2 R^2 R2增长的幅度。
如下图所示
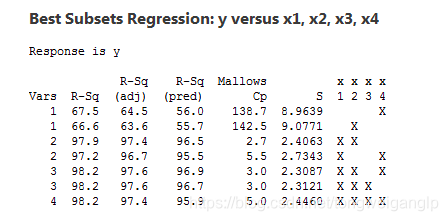
单变量的模型 R 2 R^2 R2在60多的量级,当变成两变量模型时,增长到了97的量级,而更多变量所带来的增加幅度都在个位数。所以,从拟合优度增幅的角度来看,两变量模型”最优“,而两变量回归模型中,又属 x 1 , x 2 x_1,x_2 x1,x2的组合结果最好。
2,调整的 R 2 R^2 R2
R a 2 = 1 − ( n − 1 n − p ) ( S S E S S T ) = 1 − ( n − 1 S S T ) M S E = S S T n − 1 − S S E n − p S S T n − 1 R_{a}^{2}=1-\left(\frac{n-1}{n-p}\right)\left(\frac{SSE}{SST}\right)=1-\left(\frac{n-1}{SST}\right)MSE=\frac{\frac{SST}{n-1}-\frac{SSE}{n-p}}{\frac{SST}{n-1}} Ra2=1−(n−pn−1)(SSTSSE)=1−(SSTn−1)MSE=n−1SSTn−1SST−n−pSSE
调整的拟合优度,对于SSE以及SST都分别除以各自的自由度,其中p表示变量的个数。调整后的值对于增加变量的个数起到了约束性,并且也是关于均方误差MSE的一个公式。
M S E = S S E n − p = ∑ ( y i − y ^ i ) 2 n − p MSE=\frac{SSE}{n-p}=\frac{\sum(y_i-\hat{y}_i)^2}{n-p} MSE=n−pSSE=n−p∑(yi−y^i)2
因此得到最大的 R 2 R^2 R2与最小的MSE是等价的。
所以,在上例中,仅根据调整后的 R 2 R^2 R2来判断, R 2 = 97.6 R^2=97.6 R2=97.6最大, M S E = 2.3087 MSE=2.3087 MSE=2.3087最小,所以 x 1 , x 2 , x 4 x_1,x_2,x_4 x1,x2,x4组合最优。
3, M a l l o w s ′ C p Mallows'C_p Mallows′Cp统计量
M a l l o w s ′ C p Mallows'C_p Mallows′Cp统计量运用的思想是Bias-variance tradeoff原则。
原则思想如下:

从上图中的公式与说明中,我们知道均方误差可以分解成:
Error = Bias + Variance + Noise
Error反映的是整个模型的准确度,被拆解为两个重要部分(噪声先不考虑)。Bias反映的是模型在样本上的输出与真实值之间的误差,即模型本身的精准度,Variance反映的是如果可以重复建模的过程,生成多个模型,则模型每一次输出结果与模型输出期望之间的误差,即模型的稳定性或泛化能力。在一个实际系统中,Bias与Variance往往是不能兼得的。如果要降低模型的Bias,就一定程度上会提高模型的Variance,反之亦然。
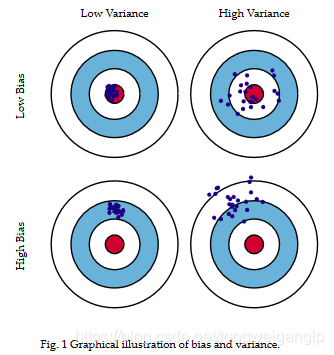
在统计学习中:一般采用抽样,逐步回归、假设检验、以及类似于AIC的统计指标等方法来平衡bias+variance。
在机器学习中:一般用到k折交叉验证(K-fold Cross Validation),以及正则化项(Regularization)一起来平衡bias+variance。当然还有bagging以及boosting的方法,bagging主要是减小了variance,boosting主要是减小bias。
总的来说,统计学习更注重中间过程,对模型生成的机理有很好的假设,也有比较完整的假设检验、模型筛选的方法。而机器学习更注重结果,模型的好坏也基本由最终预测结果来衡量,所以对模型原假设以及假设检验的方法并不是那么关心。因为机器学习的模型筛选方法都融合到了参数求解算法中了,即结构风险最小化—损失函数+正则化。
我们返回来,说
M
a
l
l
o
w
s
′
C
p
Mallows'C_p
Mallows′Cp统计量
定义
Γ
p
\Gamma_p
Γp如下,统计量表示了方差variance与偏差bias的组合
Γ p = 1 σ 2 { ∑ i = 1 n σ y ^ i 2 + ∑ i = 1 n [ E ( y ^ i ) − E ( y i ) ] 2 } \Gamma_p=\frac{1}{\sigma^2} \left\{ \sum_{i=1}^{n}\sigma_{\hat{y}_i}^{2}+\sum_{i=1}^{n} \left[ E(\hat{y}_i)-E(y_i) \right] ^2 \right\} Γp=σ21{∑i=1nσy^i2+∑i=1n[E(y^i)−E(yi)]2}
最小的 Γ p \Gamma_p Γp即是最优的模型,理论最小值为参数的数量 p p p。
下面我们用 C p C_p Cp来估计 Γ p \Gamma_p Γp
C p = p + ( M S E p − M S E a l l ) ( n − p ) M S E a l l = S S E p M S E a l l − ( n − 2 p ) C_p=p+\frac{(MSE_p-MSE_{all})(n-p)}{MSE_{all}}=\frac{SSE_p}{MSE_{all}}-(n-2p) Cp=p+MSEall(MSEp−MSEall)(n−p)=MSEallSSEp−(n−2p)
4,信息量准则
信息量准则,结合了回归模型的SSE,样本量,参数个数的因素,形成一个综合性的指标,来衡量模型的优劣。
相对熵(relative entropy)又称为KL散度(Kullback–Leibler divergence,简称KLD),信息散度(information divergence),是两个概率分布P(x)和Q(x)差别的非对称性的度量。
D ( P ∣ Q ) = ∫ p ( x ) l n p ( x ) q ( x ) d x = ∫ p ( x ) l n ( p ( x ) ) d x − ∫ p ( x ) l n ( q ( x ) ) d x D(P|Q) =\int p(x)ln\frac{p(x)}{q(x)}dx=\int p(x)ln(p(x))dx-\int p(x)ln(q(x))dx D(P∣Q)=∫p(x)lnq(x)p(x)dx=∫p(x)ln(p(x))dx−∫p(x)ln(q(x))dx
假设P(x)是总体的真实模型,Q(x)是样本估计出来的一个模型,那么最小化
D
(
P
∣
Q
)
D(P|Q)
D(P∣Q)
等价于最大化
∫
p
(
x
)
l
n
(
q
(
x
)
)
d
x
\int p(x)ln(q(x))dx
∫p(x)ln(q(x))dx,即最大化,
1
n
∑
l
n
(
q
(
x
;
θ
)
)
\frac{1}{n}\sum ln(q(x;\theta))
n1∑ln(q(x;θ))
A I C 1 = 2 n ∗ ( 1 n ∑ l n ( q ( x ; θ ) ) − d n ) AIC_1=2n*(\frac{1}{n}\sum ln(q(x;\theta))-\frac{d}{n}) AIC1=2n∗(n1∑ln(q(x;θ))−nd)
至于为什么要乘2n,是历史原因,理论上乘任何数都是可以的。实际上因此有了很多AIC的版本。比如说,乘以(-2)
A
I
C
2
=
−
2
L
L
s
+
2
d
n
AIC_2=\frac{-2LL_s + 2d}{n}
AIC2=n−2LLs+2d
则目标就变为寻找最小的AIC值对于的模型。
其中,d为模型中参数的数量;n是观测数量; L L s LL_s LLs是所设模型的估计最大似然值的自然对数。在其他条件不变的情况下,AIC_2越小表示模型拟合数据越好。AIC_2还常常应用于比较不同样本的模型,或应用于非嵌套关系的模型(非嵌套模型不能用LRT).
备注:有软件中的AIC公式为 A I C = − 2 L L s + 2 d AIC=-2LL_s + 2d AIC=−2LLs+2d,调整的 − 2 L L s -2LL_s −2LLs没有被观测数n所除。所以,它不能视为针对每个观测对 − 2 L L s -2LL_s −2LLs的调整所做的贡献。因此,这种定义下,只能用于比较对同一数据的不同模型。
另一种对AIC的改进指标是SC:
S C = − 2 L L s + d × l n ( n ) SC=-2LL_s + d×ln(n) SC=−2LLs+d×ln(n)
同样,SC也只能用于比较对同一数据所设的不同模型。
还有一种贝叶斯信息标准BIC:
B I C = − 2 L L s + d . f . s × l n ( n ) BIC=-2LL_s + d.f._s × ln(n) BIC=−2LLs+d.f.s×ln(n)
其中, d . f . s = n − k − 1 d.f._s=n-k-1 d.f.s=n−k−1为模型的自由度,它等于样本规模与模型估计系数数目只差。饱和模型的BIC=0,当BIC>0,说明所设模型比饱和模型差,而BIC<0,说明饱和模型包括了太多的自变量,所设模型更好。
A P C = ( n + p ) n ( n − p ) S S E APC =\frac{(n + p)}{n(n − p)}SSE APC=n(n−p)(n+p)SSE
5,预测平方和、与预测拟合优度
预测平方和,prediction sum of squares (or PRESS),是对于预测值与样本值差异的衡量,检验的是模型的泛化能力,借此可定义出预测拟合优度的指标。
PRESS = ∑ i = 1 n ( y i − y ^ i ( i ) ) 2 \textrm{PRESS}=\sum_{i=1}^{n}(y_{i}-\hat{y}_{i(i)})^{2} PRESS=∑i=1n(yi−y^i(i))2
R p r e d 2 = 1 − PRESS SSTO R^{2}_{pred}=1-\frac{\textrm{PRESS}}{\textrm{SSTO}} Rpred2=1−SSTOPRESS
6,交叉验证
我们如何知道模型预测的准确性如何呢?
预测平方和下的预测拟合优度安
R
p
r
e
d
2
R^{2}_{pred}
Rpred2,似乎给了我们一个方向。我们需要比较预测的值与真实值之间的差异。
我们一般会把样本数据分成两部分,训练集(training set)和验证集(validation set)。
运用验证集的数据,我们就能验证在训练集下得到的模型的预测能力如何。
在PRESS的基础上,得到 预测值的均方误差,mean squared prediction error (MSPE)。
关于如何划分样本数据,有很多种情况,如果样本够的话,一般五五开。
如果样本不够的时候,一般进行K-fold 交叉验证。
比如把样本分成k等份,每次用其中的一份当做训练集,最后得到k个MSPE,取均值来衡量。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









