







用到的知识
1.用urllib库发送GET请求
2.用XPath搜索匹配文档节点
W3Cschool XPath教程: http://www.w3school.com.cn/xpath/index.asp
3.lxml库解析HTML文档
官网: http://lxml.de/
源码
# !/usr/bin/env python
# -*- coding:utf-8 -*-
from lxml import etree
import urllib.request
import urllib.parse
import random
import time
import os
"""
抓取百度贴吧图片
"""
def work(tieba_name,begain_page,end_page):
base_url = "https://tieba.baidu.com/f?"
tieba_name = urllib.parse.urlencode({"kw": tieba_name})
base_url = urllib.parse.urljoin(base=base_url, url=tieba_name)
for page in range(begain_page, end_page + 1):
pn = (page - 1) * 50
final_url = base_url + "&pn=" + str(pn)
# print("每一页的url: "+final_url)
# 加载页面
load_page(final_url)
def load_page(url):
"""
加载html页面信息
"""
req=urllib.request.Request(url)
req.add_header(key="User-Agent", val="ConnectionResetError: [Errno 104] Connection reset by peer")
resp=urllib.request.urlopen(req)
html=resp.read().decode('utf-8')
# print(html)
# 解析HTML页面
parse_page(html)
def parse_page(html):
# 楼层链接的xpath
xpath_reply = '//div[@class="t_con cleafix"]/div/div/div/a/@href'
# 获取所有楼层的链接
data=etree.HTML(html)
links_reply=data.xpath(xpath_reply)
# print(links_reply.__len__())
for link in links_reply:
url='https://tieba.baidu.com'+link
# print("楼层url"+url)
req = urllib.request.Request(url)
resp=urllib.request.urlopen(req)
html_reply=resp.read().decode('utf-8')
# 楼层中图片的xpath
xpath_img = r'//img[@class="BDE_Image"]/@src'
# 获取每层楼中的所有图片链接
links_img=etree.HTML(html_reply).xpath(xpath_img)
# 下载图片
for link in links_img:
img_name=link[-8:]
print("图片url: "+link)
download_img(link,img_name)
def download_img(img_url,img_name):
"""
下载图片到本地
"""
print("正在下载" + img_name)
req = urllib.request.Request(img_url)
resp = urllib.request.urlopen(req)
data=resp.read()
path='img/'
if not os.path.exists(path):
os.mkdir(path)
img_path=path+img_name
with open(img_path,mode='wb') as f:
f.write(data)
# 频繁下载图片时,会报以下错误
# ConnectionResetError: [Errno 104] Connection reset by peer
# 原因未知,添加休眠时间后,可以解决该问题
time.sleep(0.2)
def tieba_spider(tieba_name,begain_page,end_page):
# 开始爬取
work(tieba_name,begain_page,end_page)
if __name__=='__main__':
tieba_name=input("输入贴吧名: ")
begain_page=int(input("请输入开始页:"))
end_page=int(input("请输入结束页:"))
# 开始采集
tieba_spider(tieba_name,begain_page,end_page)
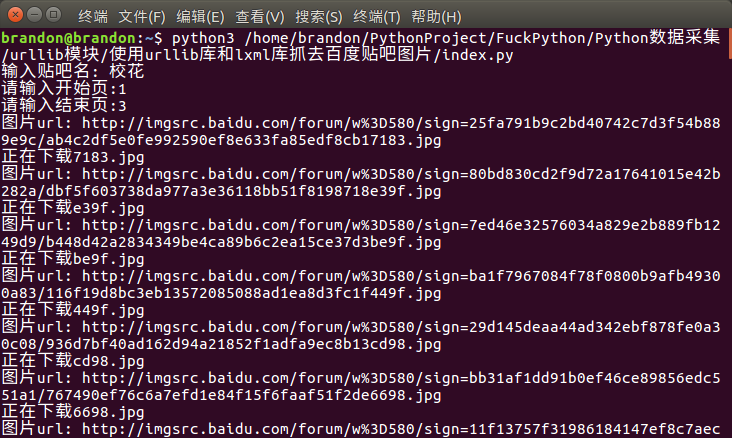
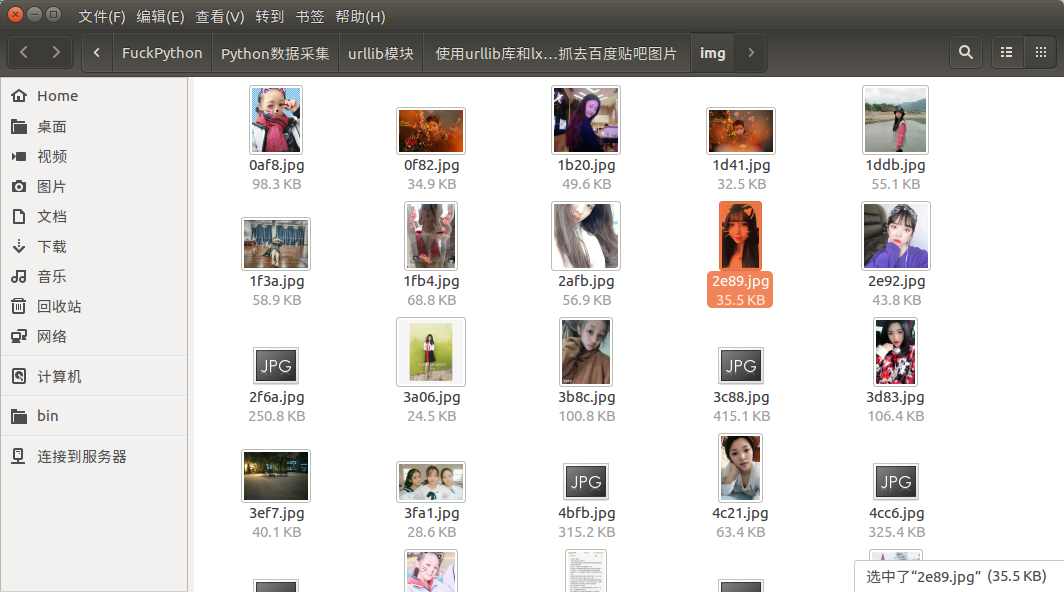
运行效果















 8006
8006

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









