源码
# !/usr/bin/env python
# -*- coding:utf-8 -*-
import requests
from lxml import etree
import json
def main():
while True:
page=input('请输入页码: ')
if isinstance(int(page),int):
url='https://www.qiushibaike.com/8hr/page/{page}/'.format(page=page)
request_header={
'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36'
}
resp=requests.get(url,headers=request_header)
html=resp.text
# 一页所有段子的xpath
content_xpath='//div[contains(@id,"qiushi_tag")]'
# 文字xpath
text_xpath='./a//span[1]'
# 图片xpath
img_xpath='./div/a/img/@src'
# 好笑
vote_xpath='./div[@class="stats"]/span[1]//i/text()'
# 评论
comments_xpath='./div[@class="stats"]/span[2]//i/text()'
html_et=etree.HTML(html)
# 内容区节点
content_et=html_et.xpath(content_xpath)
for element in content_et:
text=element.xpath(text_xpath)[0].text.strip()
img=element.xpath(img_xpath)
vote=element.xpath(vote_xpath)[0]
comments=element.xpath(comments_xpath)[0]
print(text)
print(img)
print(vote)
print(comments)
print()
if __name__ == '__main__':
main()
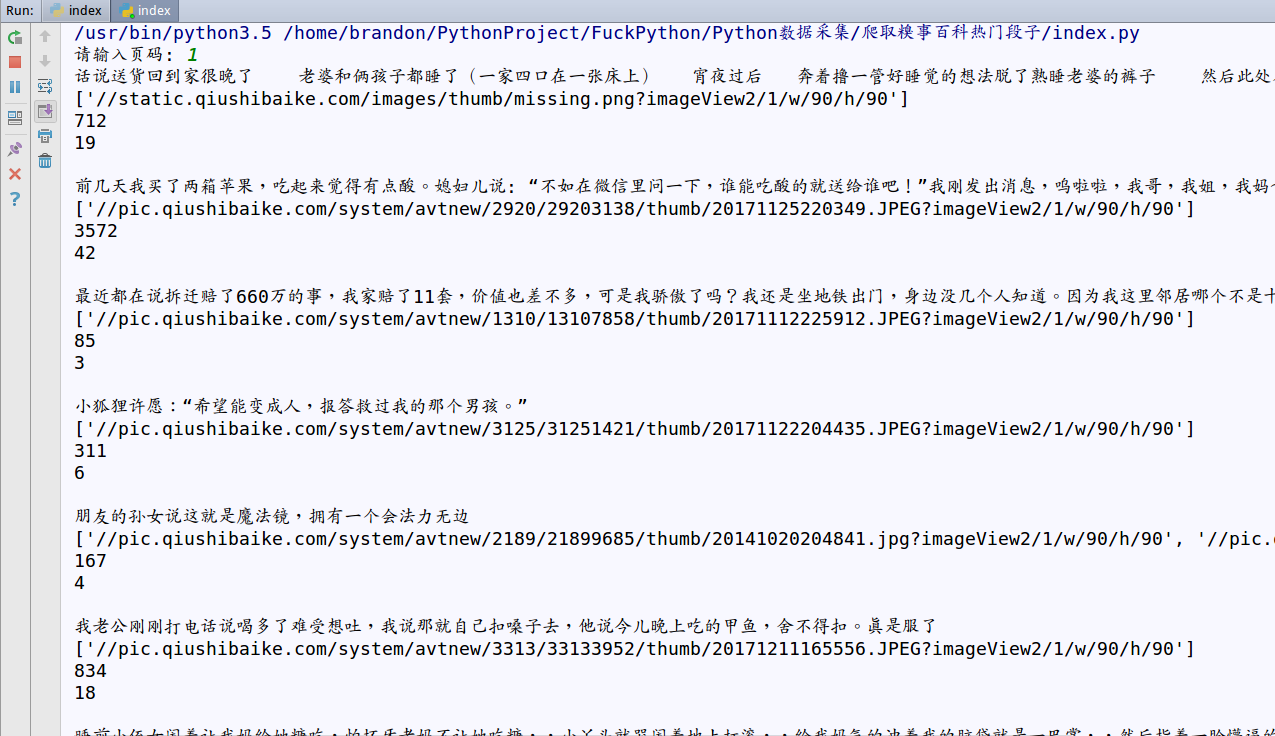
运行结果























 516
516

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









