







Tensorflow 基本运算机制
本人学习编写有关深度学习的第一篇博客,包括CSDN博客的写法不是很熟悉,所以不要太在意排版的错误,哈哈哈一起学习到内容才是我的初衷,继续加油吧思文!!!该系列专栏所涉及到的Tensorflow配置的环境说明
1.CPU版本的Tensorflow == 1.13.1
2.GPU版本的Tensorflow == 2.6.2 , 英伟达显卡驱动CUDA版本 ==11.6,Python版本 == 3.6, 显卡为3060,本系列文章若没有特别说明Tensorflow版本,默认为使用CPU版本的Tensorflow!!!
一、基本概念和操作
1. Tensorflow
Tensor表示张量,就是所谓的多维数组,有整型多维数组,浮点型多维数组,布尔型多维数组等等,Flow则表示张量在不同节点之间的流动转换,具体看下图:
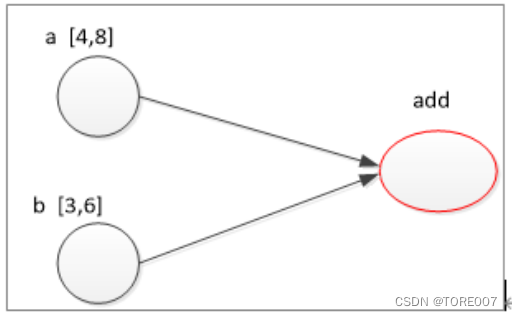
其中 a,b 以及add就是三个节点,为三个计算单元,图中的箭头指示则表示的是相互的依赖关系,实际上只是一种模型图。
2. 计算图
实际上描述的是需要依次完成的计算单元以及这些计算单元之间的相互依赖关系,计算图实际上只是一种模型,并不能进行直接运算,如果直接运算其得到的就是含有三个参数的张量,并不是最后的数值运算结果。
----------1--------
import tensorflow as tf
a = tf.constant([2,4],dtype=tf.int32)
b = tf.constant([3,6],dtype=tf.int32)
sum = tf.add(a,b)
print(sum)
输出的结果为
> Tensor("Add:0", shape=(2,), dtype=int32)
通过 tf.get_default_graph() 函数判断计算图的计算的结果是否为Tesnsorflow程序中系统默认的计算图,返回值为True or Flase ,可以继续在上面的基础上增加一行代码进行测试,
print(sum.graph is tf.get_default_graph())
输出结果为
> True ,说明其计算结果是采用系统默认的一种计算图
通过 tf.Graph() 函数获取默认的计算图,在里面建立新的张量,不同计算图上即使使用相同名称的张量和运算也不会产生冲突,通过指令 .get_operation_by_name() 获取在定义的不同计算图中张量信息;
import tensorflow as tf
g1 = tf.Graph()
g2 = tf.Graph()
#其中 .as_default 的操作是将新建的计算图在当前这个with语句块的范围内设置为默认图供全局使用,即创建的一个新图作为全局默认图使用,这样with语句外面也能使用这个会话执行
with g1.as_default():
a = tf.constant([2,4],name="v",dtype=tf.int32)
with g2.as_default():
a = tf.constant([3,6],name="v",dtype=tf.int32)
m = g1.get_operation_by_name("v")
n = g2.get_operation_by_name("v")
print(m,n)
输出的结果为
name: "v"
op: "Const"
attr {
key: "dtype"
value {
type: DT_INT32
}
}
attr {
key: "value"
value {
tensor {
dtype: DT_INT32
tensor_shape {
dim {
size: 2
}
}
tensor_content: "\002\000\000\000\004\000\000\000"
}
}
}
name: "v"
op: "Const"
attr {
key: "dtype"
value {
type: DT_INT32
}
}
attr {
key: "value"
value {
tensor {
dtype: DT_INT32
tensor_shape {
dim {
size: 2
}
}
tensor_content: "\003\000\000\000\006\000\000\000"
}
}
}
3. 会话
只有在会话提供的上下文环境中才能返回张量的值,执行输出相关节点运算的结果,而不再是如上所述包含参数的向量了,创建会话的方式有以下两种:
1、需明确调用会话生成函数
tf.Session()和会话关闭函数.close(),具体格式如下:
sess = tf.Session() #创建会话
sess.run(...) #使用该会话运行相关节点运算得到结果
sess.close(...) #关闭会话
2、通过上下文管理器来使用会话,不需要调用关闭函数,当上下文退出时会话关闭,资源自动释放
with tf.Session() as sess:
see.run(...)
执行输出相关节点运算的结果的方式为
----------1--------
import tensorflow as tf
a = tf.constant([2,4],dtype=tf.int32)
b = tf.constant([3,6],dtype=tf.int32)
sum = a+b
with tf.Session() as sess:
print(sess.run(sum))
输出的结果为:
[ 5 10]
4. 指定计算图运行设备
通过 with tf.device("/cpu:0") 指令指定设备的第一块cpu设备进行节点运算,数字 “0” 可以依次类推,然后在该上下文环境下进行张量的初始化。如果可以在CPU或者GPU版本的Tensorflow下运行,也可以通过 tf.ConfigProto 函数进行配置选项指定GPU或CPU,然后在Session中传入配置选项使其参数绑定进行运算。
如果你的电脑包含多块cpu模块就可以进行指定操作,我是没有哈哈哈哈,在此说明就是为了能看懂程序而进行说明的!
其中 tf.ConfigProto 具体参数名和含义如下:
| 参数名 | 含义 |
|---|---|
| allow_soft_placement | 如果指定GPU/CPU不存在,是否允许TensorFlow自动分配设备,可选值True,Flase |
| log_devive_placement | 是否打印设备分类分配日志,可选值True,Flase |
| gpu_options.allow_growth | 是否允许GPU容量按需分配,即开始使用少量GPU资源,然后慢慢增加,可选值True,Flase |















 676
676











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









