






【问题1】Java克隆对象的方式
【回答】浅拷贝,通过调用对象的clone方法实现;深拷贝,通过递归调用引用数据类型的clone实现或者通过序列化的方式来实现;
【问题2】LinkedList和ArrayList的区别;
【答案】LinkedList底层数据结构为链表,采用离散分配方式,ArrayList底层数据结构为数组,采用连续分配方式;查找时间复杂度为O(n)和O(1);
【问题3】hashcode()和equals()方法区别;
【答案】hashcode相同不等于equals为true,equals为true,hashcode一定相同;
【问题4】ConncurentHashMap的演进,为什么要替换分段锁,为什么要改为红黑树;
【答案】最早的版本采用分段锁,每个分段由若干个entry构成,这样设计是为了提升并发性;后面针对每个entry采用cas的方式实现,进一步提升并发性,每个entry后面是一个链表,为了提升查找效率,后面改成红黑树,查找时间复杂度从O(n)提升到O(logn);
【问题5】Volatile关键字解决了什么问题;
【答案】是为了解决内存可见性的问题以及指令重排问题;在多核架构上,每个核有自己的cache line;当程序对变量进行更新的时候,一般不会及时刷新cache line,对其他core变量的变化是不可见的,如果将变量申明为volatile,在更新变量值的时候会使用总线锁,通知其他core对本core的cache line进行刷新操作,每次读取都是从内存获取最新的值;所谓的指令重排是编译器为了优化代码,会对指令进行重新排序,可能会导致和预想的执行结果不一致的情况;
【问题6】CAS底层如何实现的,适用于什么场景;
【答案】乐观锁采用cas来实现,cas一般使用自旋的方式来实现,在cpu上循环判断状态变量,可能带来的问题是ABA问题;
【问题7】JDK1.6的synchronized关键字做了什么优化;锁的状态分为几种,分别如何实现的,锁升级指的是什么;
【答案】锁的状态分为:无锁,偏向锁,轻量级锁和重量级锁;
其中,偏向锁是指,会在对象头存放当前获取锁资源的线程id,先判断该线程id是否等于对象头的线程id,如果相等不需要用cas来加锁和解锁;如果不相等,需要进行锁升级,升级为轻量级锁,轻量级锁通过自旋来获取锁资源,如果自旋的时间太长,需要再次进行锁升级,升级为重量级锁,重量级锁需要释放cpu资源,未获取锁的线程都需要进入阻塞状态;
【问题8】Thread.sleep()和Object.wait()区别是什么,Thread.sleep(0)的作用是什么;
【答案】Thread.sleep调用后,会让出cpu但是不会释放锁资源,Object.wait调用后,会让出cpu并且会释放锁资源;Thread.sleep(0)主要是为了让出CPU,重新排入就绪队列;
【问题9】如何确定一个对象是可以被回收的,分别有什么方法,对比一下;
【答案】有两种方法,一种是引用计数,另一种是可达性分析;
引用计数:当引用计数器为0的时候,表示该对象可以被回收;存在的问题是,循环引用,解决方法是引入弱引用;
GC Root可达性分析:存在一条从GC Root到对象的一条路径,表示该对象可达,如果不可达,表示对象是可以被回收的;
哪些对象可以作为GC Root呢?JVM栈上的对象,方法区的静态变量以及常量,本地方法栈中的对象;
【问题10】JAVA的内存模型是怎样的;什么是分代回收,年轻代为什么采用复制算法,老年代为什么使用标记清理/压缩算法;G1垃圾回收器的卡表的作用是什么;
【回答】
JAVA内存模型:JAVA内存模型由工作内存以及主内存组成,工作内存是线程专属的,主内存是所有线程共享的,所有变量的存储都在主内存中,每个线程对变量的操作都在工作内存中进行;
happen-before:为了提升程序执行的效率,编译器和处理器都会对指令进行优化重排,重排的过程是程序源代码,编译阶段编译器重排,执行阶段处理器重排以及内存系统重排,最后生成可执行的指令;编译器重排是指在不改变单线程语义的情况下改变指令执行的顺序;处理器重排是指利用处理器的指令并行技术,将多条指令重叠在一起执行,如果不存在数据依赖,那么指令可以改变顺序;内存系统重排是指由于使用了缓冲区,这使得加载Load和存储Store操作是在乱序执行;主要的规则:程序顺序执行规则,对象监视器的加锁和解锁规则(加锁happen before解锁),volatie规则(写happen before读),传递性;
JVM内存布局:包括方法区,堆,本地方法区,JVM栈和程序计数器;其中前两部分是所有线程共享的,后面三部分是线程独享的;其中方法区主要存放常量,静态变量等;堆主要是存放程序中new出来的对象,JVM栈主要存放函数入参,函数返回值以及局部变量等;程序计数器主要存放当前线程执行的程序行号;
分代回收:分为年轻代(分为enden区和survior区,其中survior区又分为from区和to区),老年代和持久代;为什么使用分代回收策略,因为年轻代的对象生命周期较短,采用复制算法效率很高,年轻代的回收主要是体现回收效率;老年代对象的生命周期比较长,采用标记压缩(清除)算法主要考虑内存的利用率;
G1的RSet和Card Table:这两个数据结构是用来记录Old区对象到Young区的引用;每个Region会有一个RSet,它是points-in数据结构,用来表示哪些Region到该Region存在引用;一个Region被划分成若干个Card,类似于与物理内存被划分为Page;一个Card是512K,Card Table是一个一维数组,数组下标是记录本Region到Card的索引,数组的值表示,如果该Card被引用,那么标记为dirty_card;RSet是一个HashTable的数据结构,Key记录了Region的首地址,Value是Region的Card Table;RSet可以定位到某个区域的某个Card;
【问题11】动态代理的实现方式有几种,区别在哪里;
【回答】动态代理有两种实现方法,一种是JDK的实现方式,另一种是利用字节码CGLIB(子类代理)的实现方式,两种方式区别在于,前者被代理类需要实现接口,如果没有实现接口,需要使用后者,利用子类生成代理类,那么被代理类不能申明为final;
【问题12】类加载器有几种,顺序是怎样的?什么是双亲委派模型,解决了什么问题;
类加载的过程包含一下几个步骤:
加载:虚拟机将.class的字节码加载到方法区,并且在堆区创建相应的对象;
验证:对加载进jvm的字节码进行安全验证,符合java规范,比如文件格式验证,元数据验证,字节码验证和符号引用验证;
准备:为静态变量分配内存空间,并进行初始化操作;
解析:将符号引用转化成直接引用;
初始化:对类成员变量进行初始化操作等;
使用:使用类以及对象;
卸载:结束生命周期,比如执行System.exit,进程crash,程序正常结束等;
双亲委派模式:当一个类加载器收到了类加载的请求的时候,他不会直接去加载指定的类,而是把这个请求委托给自己的父加载器去加载。只有父加载器无法加载这个类的时候,才会由当前这个加载器来负责类的加载,类加载器分为:
启动类加载器:主要负责java核心类库的加载,比如rt.jar,resources.jar等等;
扩展类加载器:负责lib/ext目录下面的类的加载;
应用类加载器:负责CLASS_PATH指定目录下面的类的加载;
自定义类加载器:继承了ClassLoader的类加载器;
按照双亲委派模式的定义,优先从启动类加载器开始加载,如果没找到合适的类加载器,就会抛出ClassNotFoundException;
【问题13】Spring的事务传播级别;
public class TransactionTest {
@Transactional
public void test0() {}
@Transactional(propagation = ?)
public void test1(){}
}如果test1方法的事务传播机制申明为:
REQUIRED: 如果没有事务,则创建一个新的事务,如果已经存在事务,则加入到当前的事务中执行;单独调用test1,则创建一个新事务,如果test0调用test1,则加入到test0的事务中执行;
REQUIRED_NEW:不管当前是否存在事务,都将创建一个新的事务去执行,如果存在事务,将事务先挂起,再创建新的;单独调用test1,则创建一个新的事务运行,如果test0调用test1,则将test0的事务挂起,再为test1创建一个新的事务;
SUPPORTS:支持事务,如果当前没有事务,就以非事务方式运行,如果存在事务就按照存在事务的方式运行;单独调用test1以非事务的方式运行,test0调用test1,则在test1的事务空间中运行;
MANDATORY:必须以事务的方式运行;如果事务不存在抛出异常;test1单独调用,则抛出异常;如果test0调用test1,则在test0的事务空间中运行;
NOT_SUPPORT:以非事务的方式运行,如果存在事务则把事务挂起;如果test1单独调用,以非事务的方式运行;如果test0调用test1,则会把当前事务挂起,以非事务的方式运行;
NEVER:不支持事务,如果存在事务则报错;如果单独调用test1,以非事务的方式运行;如果test0调用test1,则会报错;
NESTED:嵌套事务,如果当前存在事务,则嵌套执行,如果不存在就按照REQUIRED的方式来做;如果test1单独调用,则为其创建一个事务运行;如果test0调用test1,test1会创建一个回滚点,如果test1发生异常回滚,只会回滚到这个回滚点,test0的代码仍然不受影响继续运行;如果test0发生异常回滚,则test1也会回滚;
【问题14】5种I/O模型有哪些;他们的底层实现;
【问题15】零拷贝是什么,解决了什么问题,sendfile和mmap分别有几次拷贝以及几次用户态到内核态的切换;
【问题16】Linux进程和线程的区别
【回答】进程是资源拥有的基本单位,线程是调度的基本单位;一个进程可以拥有多个线程;线程可以有自己的专属存储区,也可以和其他线程共享进程地址空间;进程切换的开销大于线程切换开销;
【问题17】Linux fork系统调用,描述一下COW技术;
【回答】fork系统调用,用于在一个进程中创建一个子进程的方法,该系统调用能返回两次,一次在父进程中返回,返回的是子进程的id,另一次是在新的子进程中返回,返回是0,可以使用getpid获取自己的进程id;调用之后,父子进程拥有相同的代码段和数据段,相当于copy了一份;这个时候,如果需要在子进程中执行其他代码段,需要使用exec系列函数来覆盖老的代码段;COW是写时复制技术,也就是说在创建子进程之后,父子进程是共享代码段和数据段的(物理页面),只有对新的进程发起写操作,这个时候才会为新的进程分配内存页面;
【问题18】Linux的虚拟内存管理;
【回答】一台机器的物理内存是有限的,使用虚拟内存技术来扩大每个进程可以寻址的最大地址空间,我们通过MMU这个硬件来做实地址到虚地址之间的转换;物理内存划分为若干物理页面,每个页面4kb,这些页面通过页表来管理,页表在逻辑上是连续的,我们需要提升内存利用率,就需要将页表也离散化,也就是页表也被离散化到物理页,页表的物理页也需要一个页表来管理;所以linux采用了三级页表来做虚存管理,当要访问的页面没在内存时,需要产生一个缺页中断,操作系统将页面加载到内存,操作系统对页面也提供了一些缓存的能力;
【问题19】select和epoll对比,epoll的水平触发和边缘触发;
【回答】select和epoll的区别底层数据结构前者采用线性表,后者采用红黑树;内核态和用户态数据交换,前者采用拷贝后者采用共享内存;支持的文件描述符数量前者默认1024,随着数量增大性能急剧下降,后者可以支持65535,红黑树效率很高;epoll的水平触发是指只要缓冲区有数据,epoll_wait就会不停触发,保证数据完整性,但是当数据量比较大,需要多次内核态和用户态的切换。边缘触发是指缓存区有数据只会触发一次事件通知,只需要一次切换,后者对编程要求比较高,需要在用户态自己保证数据完整性逻辑;
【问题20】redis常见的几种key的淘汰机制
【回答】
- noeviction:不淘汰,内存不够报错;
- allkeys-lru:内存不够,在所有key中应用lru算法;
- volatile-lru:内存不够,在过期key中应用lru算法;
- allkeys-random:内存不够,在所有key中应用random算法;
- volatile-random:内存不够,在过期key中应用random算法;
- volatile-ttl:内存不够,在过期key中将ttl最短的key回收;
【问题21】redis经常使用的集群方案有哪些;
【回答】
- 使用twemproxy,在twemproxy做分片逻辑,缩容扩容的时候需要重新分片;
- 使用codis,和twemproxy类似,不过在缩扩容的时候能自动迁移数据到新的分片;
- redis-cluster:采用一致性hash算法;
【问题22】一致性hash算法
【回答】
构建一个hash环,环上有2的32次方个虚拟节点,如何将这些虚拟节点映射到物理节点,通过hash(物理节点的IP地址)%2的32次方;如何将key映射到物理节点呢,也是通过hash(key)%2的32次方,结构和第一步产生的结果关联即可;
假如其中一个节点挂掉,按照顺时针方向,将key距离最近的节点进行数据迁移,扩容也是一样的方法,所以在缩扩容或者发生节点故障的时候,只会影响某个分片数据;
如何解决物理节点数量很少导致数据分配不均衡的问题,可以通过增加多个虚拟的物理节点来达到目的,比如有两个节点IP0和IP1,新增IP0#0,IP0#1,IP0#2,IP1#0,IP1#1,IP1#2;
redis-cluster的一致性hash算法,支持的节点数量按照16384来计算;
【问题23】B树和B+树的区别在哪里,分别适用于怎样的业务场景;
MYSQL数据库的innodb引擎,使用了B+树作为索引组织树,B+树在叶子节点存放数据,非叶子节点只存放key,并且叶子节点构成一条有序的单向链表;B树在非叶子节点也可以存储数据;B+树的优势是可以再一个page中加载更多的索引到内存,减少查询中的磁盘IO次数;B树的优势是对于某些hotkey,可以维护在离根节点更近的节点上,快速查询;
【问题24】索引组织表和堆表的区别;
堆表:按照物理内存的使用情况,随机插入,也就是说插入顺序和存储顺序很有可能是不一致的;
索引组织表:把数据按照索引的组织方式来存储,保证插入顺序和物理存储顺序一致性;
索引组织表比较适用于有范围查询的情况;常见的MYSQL是索引组织表,POSTGRSQL是堆表,ORACLE两则都支持;
【问题25】为什么要避免使用子查询;(子查询结果无法使用索引,临时表使用多余的存储空间)
【回答】
- 子查询结果无法使用索引;
- 临时表使用多余的存储空间;
【问题26】Hash索引和B+索引区别有哪些;
【回答】Hash索引,适合通过key查找value,单值查询,不适合范围查询。B+树适合范围查询,多值和单值查询。B+树叶子节点形成一个按主键递增的链表,如果按照主键排序那是很有优势的;
【问题27】MyISAM和InnoDB对比;
【回答】MyISAM和Innodb都采用了B+树的存储结构,不同之处:
- MyIsam支持表级锁,Innodb支持表级锁和行锁;
- MyIsam不支持事务,Innodb支持事务;
- Innodb支持外键,MyIsam不支持;
- Innodb不支持全文检索,MyIsam支持;
- MyIsam支持GIS数据结构,Innodb不支持;
- select count(1) from table,该条语句MyIsam性能高,不需要遍历,因为MyIsam内置了一个计数器;
【问题28】Innodb中使用的Record lock,Gap lock,Next-Key lock和插入意向锁分别解决什么问题;不走索引,走非唯一索引以及走唯一索引分别使用了什么锁;
【回答】行锁是对表的一行的key加锁,间隙锁是针对范围查询,在此范围之内不在数据库中的记录行加锁,next-key lock是行锁+间隙锁组合;next-key lock可以解决幻读问题;所谓的幻读是在多次读取中获取的记录行数不一样;走唯一索引使用的是行锁,走非唯一索引使用的是next-key lock;插入意向锁是一种Gap锁,只在insert操作时产生,在多个事务同时写入数据到统一Gap的时候,不会发生锁等待;
【问题29】死锁发生的4个必要条件;
【回答】
- 互斥条件:一个资源每次只能被一个进程使用;
- 请求保持条件:一个进程阻塞后,不释放以获取的资源;
- 不剥夺条件:一个进程获取资源后,在没使用完之前,不能强行夺取;
- 循环等待条件:进程资源的获取形成了一个环形;
避免死锁只需要四个条件有一个不满足即可;
【问题30】数据库的三大范式分别解决了什么问题;
【回答】第一范式保证列是不可分割的,具有原子性;第二范式非主键列不能部分依赖于主键列;第三范式,不能存在传递依赖;
【问题31】事务隔离级别有哪些,分别解决什么问题,不可重复读和幻读的区别;
【回答】分为四个事务隔离级别:
- Read-Uncommited: 读未提交,可能导致脏读,不可重复读和幻读;
- Read-commited:读已提交,可能导致不可重复读和幻读;
- Repeatable-Read:可重复读,可能导致幻读;
- Serial-Read:串行化读;
不可重复读和幻读的区别在于,前者在于更新产生,后者在于插入/删除产生;
【问题32】SQL内联查询和外联查询的区别
【答案】内联是指连接结果只包含符合连接条件的记录;外联是指连接结果既包括符合连接结果的行也包括部分部分和连接结果的行,外联分为左连接(符合条件的行+左表不符合条件的行),右连接(符合条件的行+右表不符合连接条件的行)和全连接(左连接union右连接);
【问题33】MYSQL中,in和exist性能对比
【回答】在都走了索引的情况下,如果子查询的结果集很大那么建议用exist,如果子查询的结果集很小建议用in。因为in是内表驱动的,exist是外查询驱动的。
【问题34】binlog, redo log和undo log的区别;
【回答】
binlog是用于mysql记录写入操作的二进制文件,包括三种模式:
- statement模式:记录的是SQL语句,不过对于SQL中有函数的语句不是很适合;
- row模式:记录的是发生变化的数据类容,对于DDL会产生大量的数据;
- mixed模式:是以上两种的混合模式;
redolog是用于事务提交时的数据变更,针对DML,他包括两个阶段,redo log buffer和redo log file;先会提交到buffer中,然后定时刷盘到redo log file。这个过程就是WAL;
undolog是用于记录事务回滚时数据版本,也是MVCC实现的基础;
【问题35】为什么innodb主键采用自增id;
【回答】innodb是一个索引组织表,其中叶子节点是一个按照主键有序的单向链表,如果采用自增id,在新增数据的时候,只需要向链表最后面新增节点即可,不会存在在中间插入数据,这样会导致页分裂,导致性能下降。另外,如果采用整型的自增id,一个id的大小是固定的,并且占用的存储空间很小,所以一个物理页面能存储的key会相对较多,减少查询过程中的IO次数,提升查询性能;
【问题36】请对select * from table where age > 20 limit 1000000,10这句SQL进行优化;(子查询+覆盖索引)
【回答】select * from table where id in (select id from table where age > 20 limit 1000000,10)
【问题37】MYSQL innodb的主键使用自增id还是UUID;性能上有什么不同;
【回答】建议使用自增id,因为innodb是一颗索引组织树,叶子节点是一个按照主键递增的链表,如果使用uuid,那么最后的key是通过对uuid字符串求hash值运算出来的,因为hash算法的不稳定性(插入顺序和存储顺序不一致),可能会导致在插入新数据的时候导致页分裂。
【问题38】TCP/IP协议中,CLOSE_WAIT和TIME_WAIT那种可能属于程序异常导致的,分别代表什么;
【回答】CLOSE_WAIT是程序bug引起的,在TCP断开连接时,需要四次挥手,在服务端收到Fin回给客户端Ack之后,就会处于CLOSE_WAIT状态,如果服务端不主动发起FIN,那么该状态会一直保留,其原因就是服务端没有主动关闭socket连接回收资源。TIME_WAIT是一种正常的状态,在客户端收到服务端发过来的FIN,并且向服务端Ack之后,需要将连接保留2MSL时间,因为他必须要确保服务端收到了Ack,可以通过调整内核参数改变TIME_WAIT存活的时间。
【问题39】TCP流量控制算法如何工作,它和拥塞控制算法的区别;
【回答】TCP流量控制,是对发送方的发送速率进行控制,TCP拥塞控制,是全局控制,确保进入网络的流量不会太多导致网络拥塞。
TCP流量控制在发送方和接收方都有一个滑动窗口,控制发送速率,接收方接收到发送方的数据,会回一个ack,捎带接收方还允许发送的字节数,如果还允许发送的字节数为0,发送方会启动一个定时器,timeout之后会发一个试探报文,获取接收方可以接受的字节数。
TCP拥塞控制算法包括四个,慢启动,拥塞避免,快速重传,快速恢复;有一个阈值threshold,这个阈值有一个初始值,从慢启动算法开始,报文的发送size指数增长,达到threshold之后,开始拥塞避免算法,报文size开始线性增长,如果超时,启动快速重传,这个时候需要将阈值更改为当前congestion window size的一半,再一次进入慢启动阶段和拥塞避免阶段,在拥塞避免阶段,如果发现连续收到三个相同的ack,表示丢包,需要将阈值更新为当前的一半,进入快速恢复阶段,继续拥塞避免。
【问题40】MSS和MTU的区别
【回答】MSS是TCP层用来限制上层协议能一次性传输的最大报文大小,他是第四层的概念;MTU是数据链路层的概念,是用来限制IP层到数据链路层一次性传输报文的大小,默认是1500 bytes,MSS的默认值是1500-20(TCP header)-20(IP header);
【问题41】Https的握手过程
【回答】
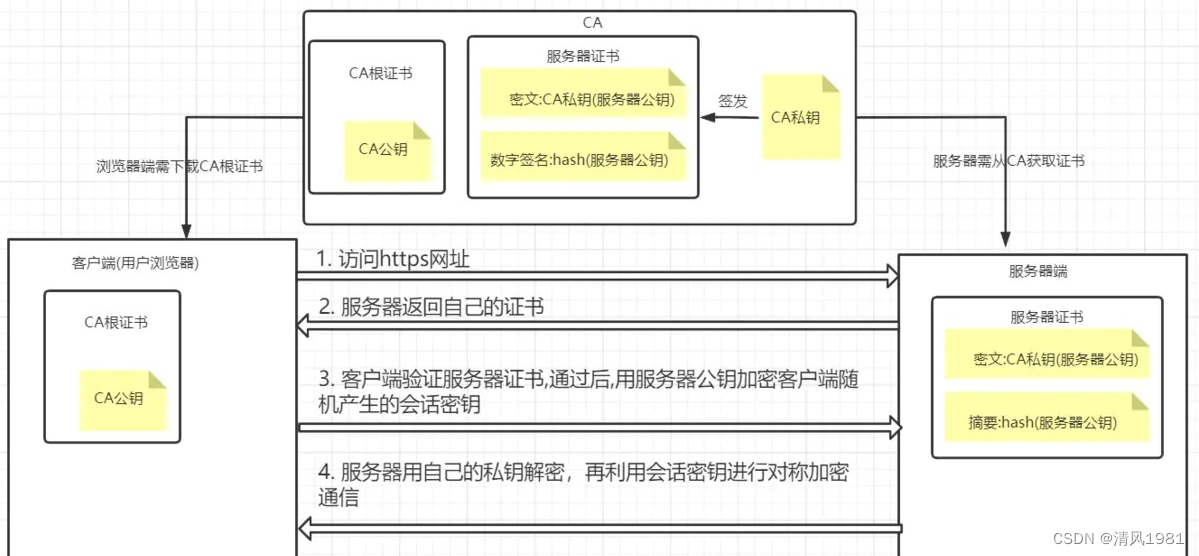
在第二步,服务器端返回服务端CA证书,其中包含了服务端的公钥,客户端收到后,使用CA根证书的公钥对服务端证书密文解密获得服务端公钥,客户端接着会生成随机数,使用解密出来的公钥进行加密,发送给服务端,服务端使用服务端的私钥进行解密,获取这个随机串,这个随机串就是对称加密的秘钥,用于数据传输中加解密;
【问题42】DNS什么时候使用TCP协议,什么时候使用UDP协议;
【答案】DNS在域名查询的时候使用UDP协议,在域名信息同步的时候使用TCP协议;主从DNS服务器之间使用TCP协议,浏览器和DNS服务端之间进行域名查询使用UDP。
【问题43】DDOS攻击原理;
【回答】通过大量的肉鸡,向受攻击的机器发起进攻的方式;包括两种类型的攻击,流量型攻击,能导致网络瘫痪,另一种是资源耗尽型攻击,导致服务器CPU和内存等资源耗尽;常见的DDOS攻击有以下几种:
- Syn Flood攻击:利用了TCP三次握手的漏洞,客户端向服务器端发起连接建立的请求,发送Sync到服务端,服务端收到后,会Ack+sync到客户端,这个时候,如果客户端是一个虚假的ip,会导致服务端进行重发,如果有大量的这种请求,就会导致服务器瘫痪;
- TCP全连接攻击:一般的防火墙对于正常的TCP连接是放过的,那么攻击者可以利用肉鸡向服务端发起TCP建连攻击,服务端应用服务器能接受的文件描述符是有限的,这样就能导致正常连接进不来;
- 应用层的CC攻击:利用服务端脚本,攻击者发现某些脚本访问数据库等资源很慢,就利用这个漏洞向这个服务器提交大量的执行该脚本的请求;
【问题44】DNS劫持和DNS污染有什么区别;(前者是撰改服务器上面的数据,后者是利用网络入侵检测技术实现协议层面的拦截)
【回答】前者是伪造DNS服务器,截获DNS请求,对客户端做出虚假响应,导致客户端访问了错误的页面;后者是修改了DNS缓存映射关系,并没伪装DNS服务器;两者本质都是改变了域名和ip的映射关系;
【问题45】各层的网络设备
【答案】
- 集线器:L1设备,一个口收到信号,原封不动的发送到其他口,由接收口确定该信号的处理方式;
- 网桥:L2设备,网桥会匹配目的MAC地址,只有匹配上的才会被转发出去;也叫两口交换机;HUB是纯转发不做匹配;
- 交换机:可以看成是多个bridging,维护一个MAC table;兼顾L2和L3;
- 路由器:L3设备,IP报文routing;
【问题46】HTTP协议502和504的区别
【回答】502是网关错误,504是网关超时;502是代理服务器后面的服务器挂掉了,504是代理服务器后面的服务器过载超时;
【问题47】描述一下CSRF攻击方式
【回答】跨站请求伪造攻击,如果登录逻辑采用了cookie实现,那么通过正常的流程从合法网站获取登录权限后,cookie将存放在本地浏览器,每次提交请求都会带上,服务端会进行验证,如果将请求提交到一个非法站点,就会存在cookie泄露,被攻击;解决方案可以再cookie和页面加上一个csrf_token,服务端收到请求后进行验证,如果相等则认为是合法请求;黑客利用登录态,对源站发起进攻;
【问题48】SQL注入攻击
【回答】通过输入改变SQL,服务端对修改后的SQL进行执行达到攻击的目的,我们禁止使用sql拼接,尽量使用prepared statement。
【问题49】CAP原理是指,其中ZK和erueka分别满足什么。
【回答】CAP是指一致性(C),可用性(A)和分区容忍性(P),在一个分布式系统中,不可能三者全满足,满足三者中二,其中分区容忍性(P)一定需要支持,不可避免在分布式环境中会发生网络丢包的问题。ZK满足的是CP,Erueka满足的是AP;
【问题50】雪花算法的优缺点
【回答】雪花算法主要依赖机器的时间戳(毫秒维度)和本地的自增id(避免同一毫秒id重复),所以整个算法运行在本地,效率非常高,在分布式环境中,可以保证单节点的id是单调递增的,id是64bit整型,如果用于mysql的自增id,也是符合mysql自增id规范的;缺点是一旦服务器的时间回拨,会导致大量重复的id生成,最好在生成前先比较一下上一次时间戳是否小于等于本次的;
【问题51】什么是数字签名?CA证书用来解决什么问题?
【回答】数字签名是用来解决信息的真实性的问题,而不是解决信息加密的问题;数字签名是基于非对称加密算法的,首先对原始信息运用散列函数,求得Digest(摘要),然后,对Digest运用私钥进行加密(数字签名防的是信息生成端,这点和SSL有着本质区别,SSL使用私钥进行解密,也就是防的是信息获取端);最后,将签名附在信息上一同传给对方;对方获取之后,需要验证信息生成端的可信性,需要先通过公钥对传输过来的加密串进行解密得到Digest(摘要),同样对原始信息使用散列函数对摘要进行计算(比如MD5)得到的Digest,然后用私钥解密信息中的签名串得到的Digest和上一步运算出来的Digest不一致,说明对方是不可信的;
CA证书,用来解决公钥真实性的问题;通过第三方机构对公钥做认证;验证原理和数字签名方式一样;
SSL简述思想: 数字证书(数字签名)+非对称加密+对称加密,数据面,为了保证性能,采用对称加密,对称加密的密钥通过非对称加密算法进行传递,如何将非对称加密的公钥给到对方,保证公钥的合法性呢,通过数字证书(数字签名),通过对公钥进行数字签名;所以浏览器访问资源之前,会先要求安装一个数字证书,这个证书主要包含CA机构的公钥,通过公钥解密被私钥加密的hash0,然后再用证书中的hash算法,对信息进行运算生成hash1,如果hash0==hash1,那么就确认了证书的真实性,就能证明数字证书里面用于解密对称加密的密钥的公钥是正确的;















 1114
1114











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









