







 FLIP基于CLIP的预训练方法,通过在图片中随机mask部分patch,减少了ViT的计算量,提高训练速度且利用更多batch增强准确性。实验表明,不重构patch有助于模型学习上下文信息,消融实验显示50%的mask比例最优,文本mask则效果稍逊。
FLIP基于CLIP的预训练方法,通过在图片中随机mask部分patch,减少了ViT的计算量,提高训练速度且利用更多batch增强准确性。实验表明,不重构patch有助于模型学习上下文信息,消融实验显示50%的mask比例最优,文本mask则效果稍逊。
FLIP由CLIP改进而来,其思想非常简单,通过在图片侧mask掉相当比例的patch(无须重构patch),实现速度和准确性的双重提升。
模型结构
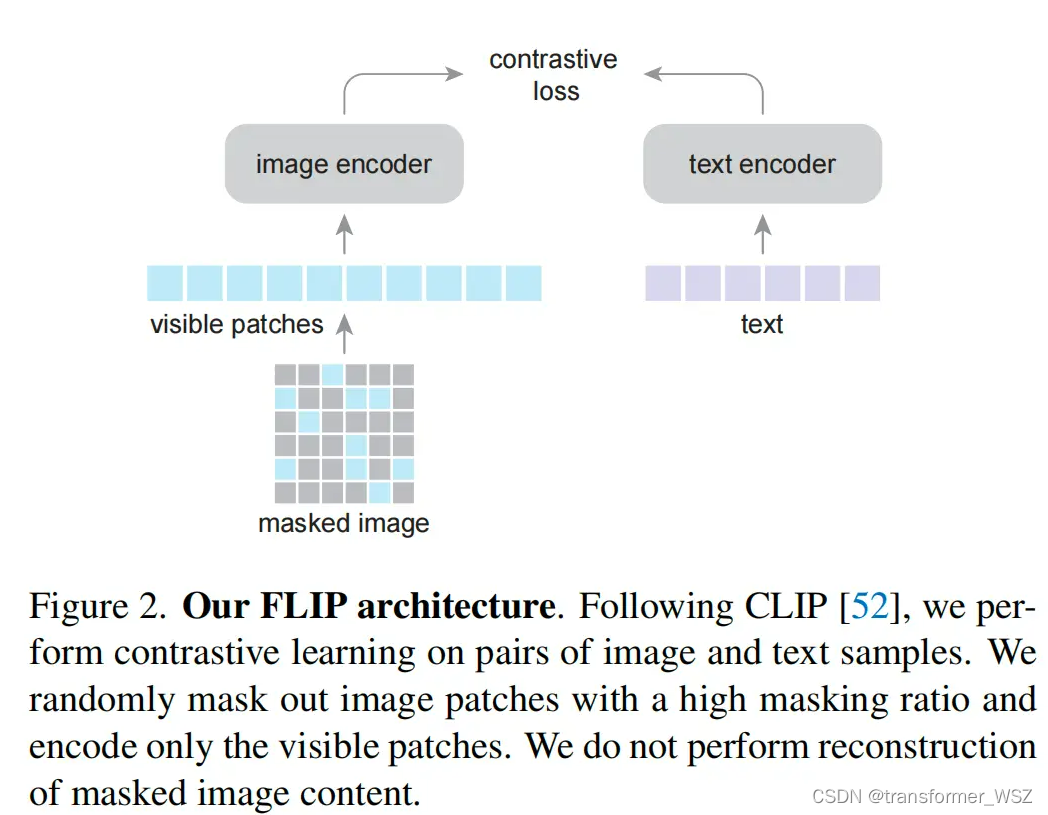
受MAE启发,FLIP对图像进行了mask来预训练。该方法有两方面收益:
- 速度:ViT对图像编码的计算量大幅减少,训练速度更快
- 准确性:相同的显存可以存放更多的batch,从而构造更多的图文对进行对比学习,准确性得以提高
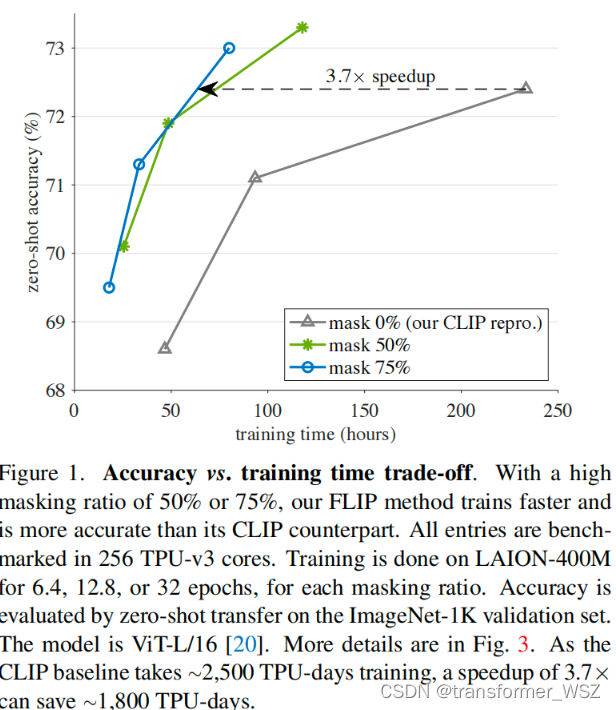
值得注意的是,该预训练任务没有重构patch,个人理解:
- 图片本身就包含了大量的冗余信息,mask掉部分patch不影响图片理解
- mask部分patch,可以强制两边编码器去学习对方的上下文语义信息
实验结果
FLIP在下游实验的结果一片绿:

消融实验
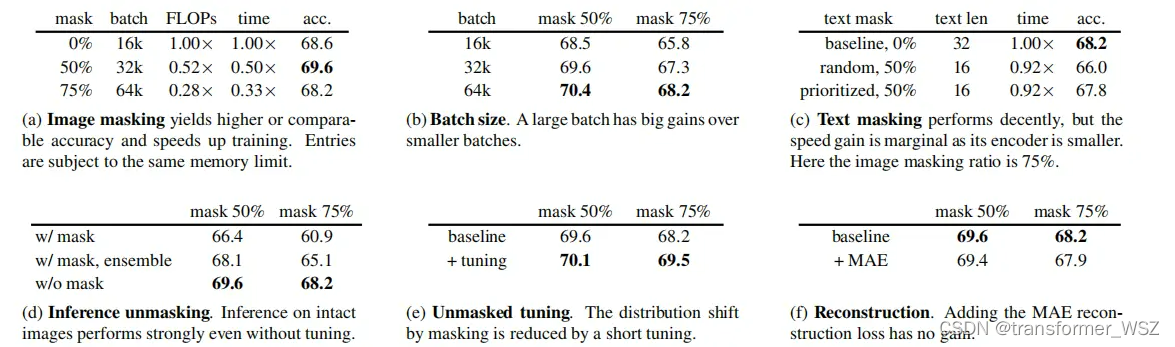
- 作者尝试在图像上的不同mask比例,50%最佳
- 作者也尝试了在文本上做mask,但性能略微有所下降
- 重构patch没有收益

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









