







1、import urllib2
from HTMLParser import HTMLParser
2、HTMLParser
.feed() 向解析器喂数据,可以分段提供
.handle_starting(self , tag , attrs)
tag 标签名称
attars 属性列表
handle_data 处理标签里的数据体
data 数据文本
代码:
1 #coding: utf-8
2
3 import urllib2
4 from HTMLParser import HTMLParser
5
6 class MovieParser(HTMLParser): #继承父类HTMLParser
7 def __init__(self):
8 HTMLParser.__init__(self)
9 self.movies = []
10
11 def handle_starttag(self, tag, attrs): #handle_starting()处理html的开始标签 tag标签名称 attrs属性列表
12 def _attr(attrlist, attrname): #属性列表
13 for temp in attrlist:
14 if temp[0] == attrname:
15 return temp[1]
16 return None
17
18 if tag == 'li' and _attr(attrs, 'data-title') and _attr(attrs, 'data-category') == 'nowplaying': #条件限定
19 movie = {}
20 movie['title'] = _attr(attrs, 'data-title')
21 movie['score'] = _attr(attrs, 'data-score') #评分
22 #movie['director'] = _attr(attrs, 'data-director') #导演
23 #movie['actors'] = _attr(attrs, 'data-actors') #演员
24 movie['release'] = _attr(attrs,'data-release')
25 movie['region'] = _attr(attrs,'data-region')
26
27 self.movies.append(movie)
28 #print('%(title)s|%(score)s|%(director)s|%(actors)s' % movie)
29 print('%(title)s | %(score)s | %(release)s | %(region)s' %movie )
30
31 def nowplaying_movies(url):
32 #headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.73 Sa
fari/537.36'}
33 myheaders = {'User-Agent': 'Mzilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.71 S
afari/537.36'}
34 req = urllib2.Request(url,headers = myheaders)
35 s = urllib2.urlopen(req)
36 parser = MovieParser() #实例化MovieParser()类
37 parser.feed(s.read()) #feed()向解析器喂数据
38 s.close()
39 return parser.movies
40
41 if __name__ == '__main__':
42 #url = 'http://movie.douban.com/nowplaying/xiamen/'
43 url = 'https://movie.douban.com/cinema/nowplaying/nanjing/'
44 movies = nowplaying_movies(url)
45
46 #import json
47 #print('%s' % json.dumps(movies, sort_keys=True, indent=4, separators=(',', ': ')))执行:
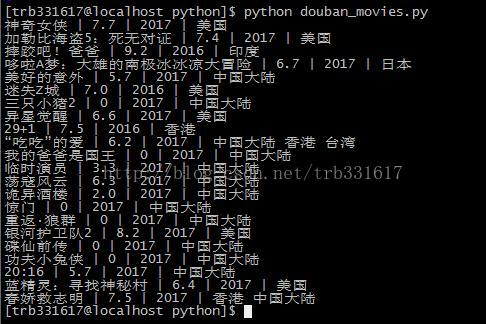
Google Chrome:
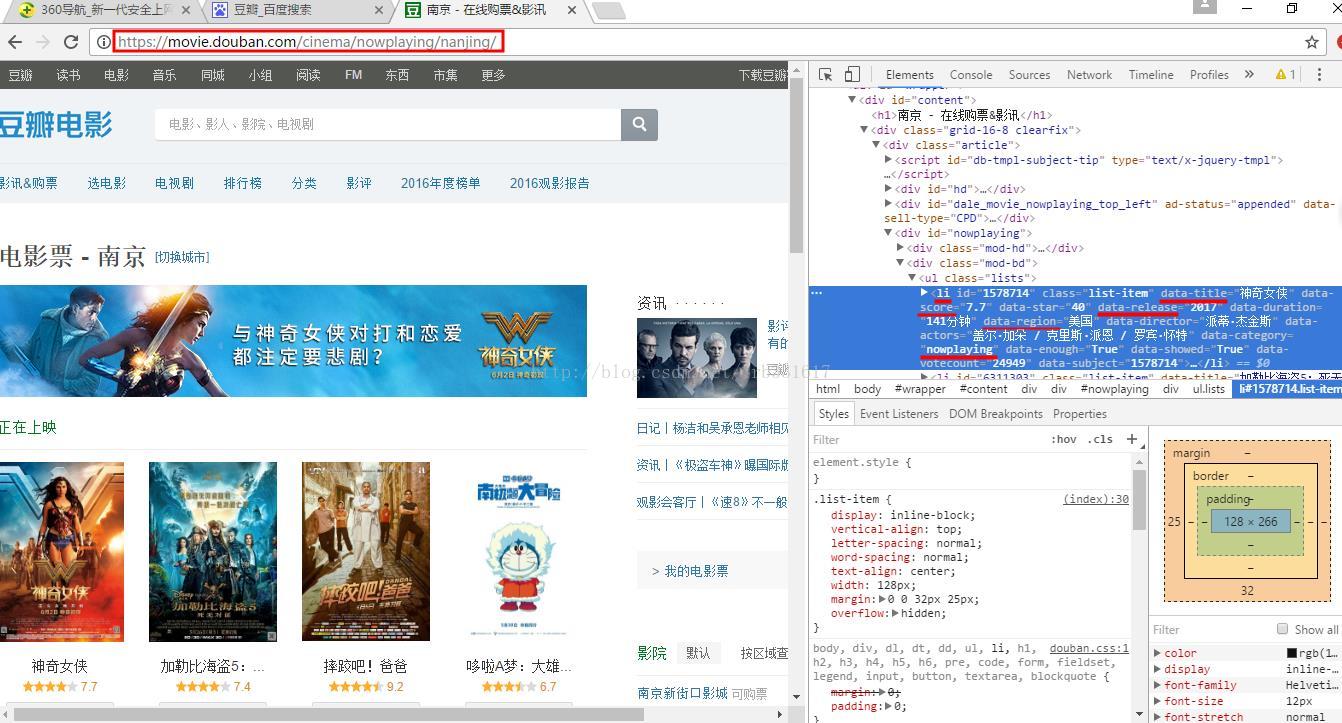















 1330
1330

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









