






数据库分表分库的原则
1. 分表
分表的应用场景是当单个表中的数据量超过数据库的处理能力或性能需求时或者当单个表的并发读写操作过多,导致数据库性能下降时可以考虑分表,简单来说就是单表的数据量大影响了接口的响应时间,而数据库的实际负载却不高的时候。
分表也分为垂直分表和水平分表。
1.1 垂直分表
垂直分表就是将一张表按照字段进行拆分,为了使DML性能更好,通常采取冷热分离。或者分离存储数据量比较大的那一列(写多个中文的)。
冷热分离(Hot-Cold Separation):它通过将数据按照访问频率的高低进行分类和分离,将热数据和冷数据存储在不同的存储介质或数据库中,以实现更有效的数据管理和资源利用。
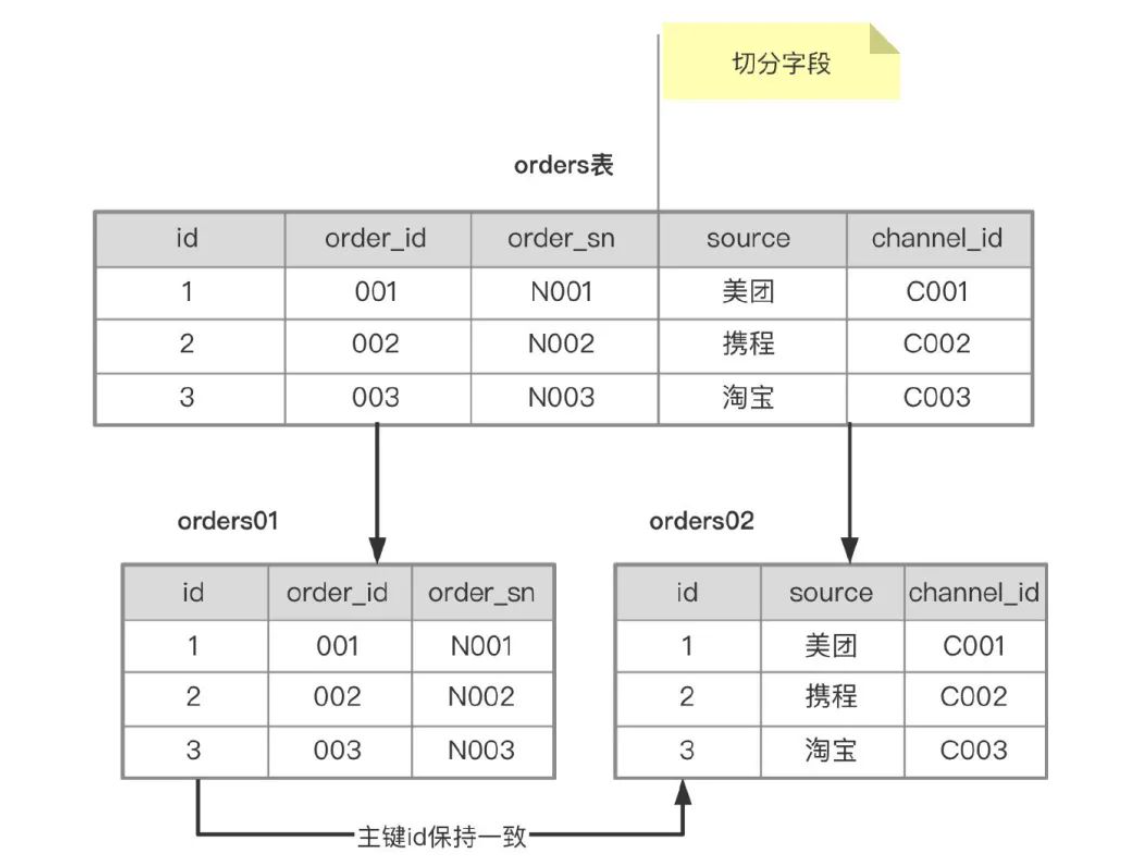
那将表划分以后的SQL语句又该怎么写呢?例:
select * from orders where order_id = '001';
拆分为两个表以后就需要从两个表中拿到所有的信息了,例:
select a.*,b.source,b.channer_id from oreders01 a,orders02 b where a.id = b.id and a.id = '001';
【TODO:有数据库中间件已经实现自动重写了,例如mycat、sharding-sphere,不使用中间件的话也是能实现的:在新建一张路由表(id,原表名,字段名,子表名),每次查询都需要先查此表对应。但这种方法代码量改造太大,而且容易出错,所以不建议使用。】
1.2 水平分表
水平分表就是将一张表按照主键进行拆分,可以划分的很均匀,也可以通过自己的需求按照不同的字段进行划分。
例:orders表就是通过user_id进行划分,因为查询订单号时使用id去查询的概率很小,更多时候是通过user_id进行查询,从整体来看,每一个user_id对应的orders不会差距太大,因此使用user_id作为标准来划分也是合理的。
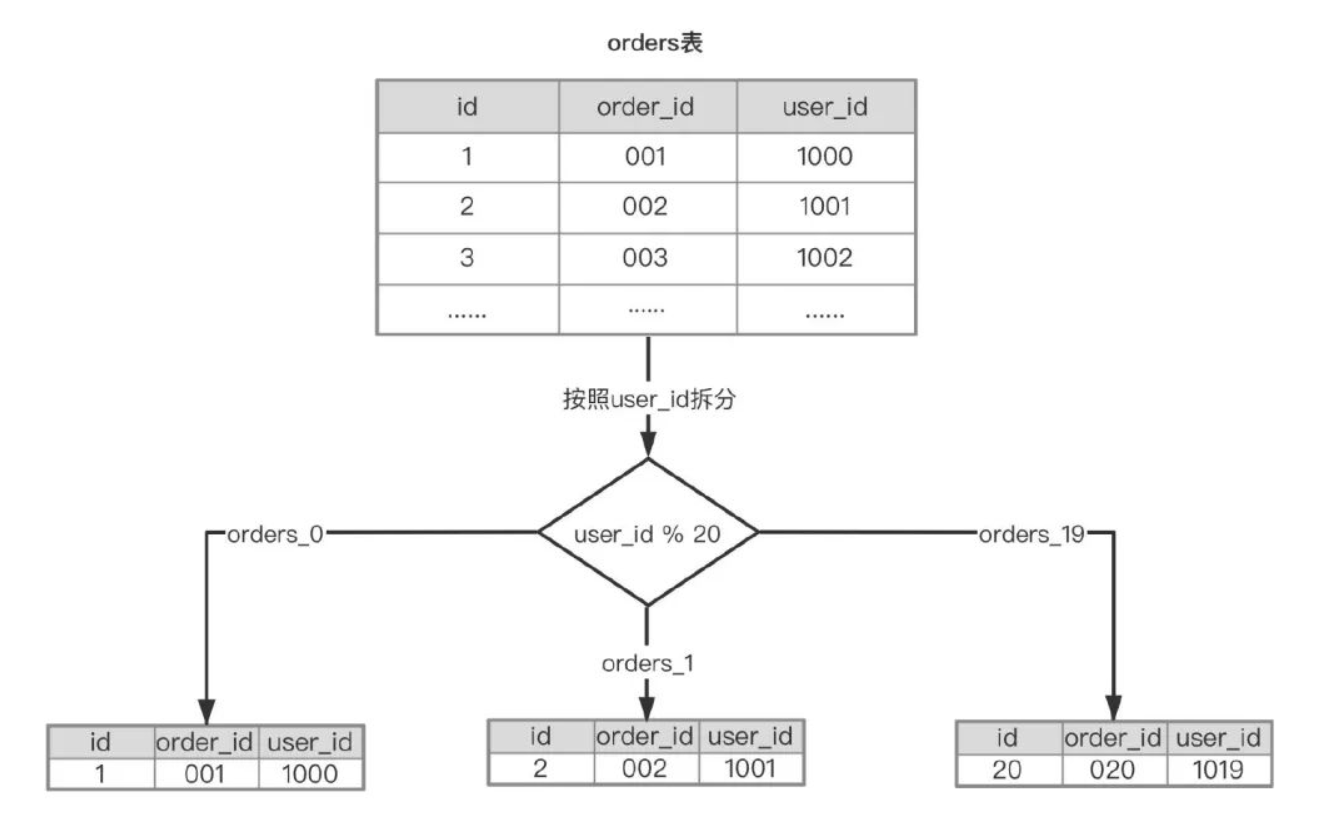
这次在划分时将orders划分为了20个子表,对应带innoDB上就是20个数据文件(orders_0.idb、orders_1.idb…orders_19.idb),这时又该怎么执行上面那条SQL语句呢?
已知是按照user_id%20进行划分的,所以拿到(user_id%20)的值即可知道数据在哪个表中。
# 示例,伪代码
select * from orders_(1001%20) where user_id = 1001;
【TODO:同样这种分表方式造成的动态SQL也有数据库中间件帮我们实现了,例:sharding-sphere 或者 sharding-jdbc】
MySQL分区表
其实MySQL内部是有分表的解决方法的,其中最常用的就是Hash分区,常规的hash也是基于分区个数取模(%)实现的,跟上面的实例是一样的。怎么创建呢?例:
CREATE TABLE orders (
`id` BIGINT ( 20 ) NOT NULL COMMENT 'id',
`order_id` VARCHAR ( 20 ) NOT NULL COMMENT '订单id',
`user_id` BIGINT ( 20 ) NOT NULL COMMENT '用户id',
PRIMARY KEY ( id, user_id ),-- 分区键必须包含在主键中
KEY id_user_id ( user_id )) PARTITION BY HASH ( user_id ) -- 使用Hash分区,分区主键为user_id
PARTITIONS 20;-- 20个分区
-- 设置主键id自增
ALTER TABLE orders auto_increment = 1;
-- 插入数据
INSERT INTO orders(order_id,user_id) VALUES('001',1000),('002',1001),('003',1002),('004',1003),('0020',1019);
这样就创建了20个分区,来看一下SQL的执行过程。
EXPLAIN SELECT * FROM orders WHERE user_id = 1019;

可以看出,通过分区主键user_id过滤,直接可以定位到数据所在的19号分区(1019%20 ),进而去访问p19对应的数据文件获得最终的数据。这种方案就是MySQL自动帮我们实现了SQL路由的功能,不用去手动改造了。
2. 分库
MySQL 的高可用架构大多都是一主多从,所有写入操作都发生在 Master 上,随着业务的增长,数据量的增加,很多接口响应时间变得很长,经常出现 Timeout,而且通过升级 MySQL 实例配置已经无法解决问题了,这时候就要分库,通常有两种做法:垂直分库和水平分库。
2.1 垂直分库
垂直分库是指将不同的业务模块或功能按照功能划分到不同的数据库中。这样可以实现业务之间的隔离,降低数据库的复杂度,并提高性能和可扩展性。
例:交易系统 trade 数据库单独部署在一台 RDS 实例,现在交易需求及功能越来越多,订单,价格及库存相关的表增长很快,部分接口的耗时增加,同时有大量的慢查询告警,升级 RDS 配置效果不大,这时候就需要考虑拆分业务,将库存,价格相关的接口独立出来。
RDS:关系型数据库服务(Relational Database Service)
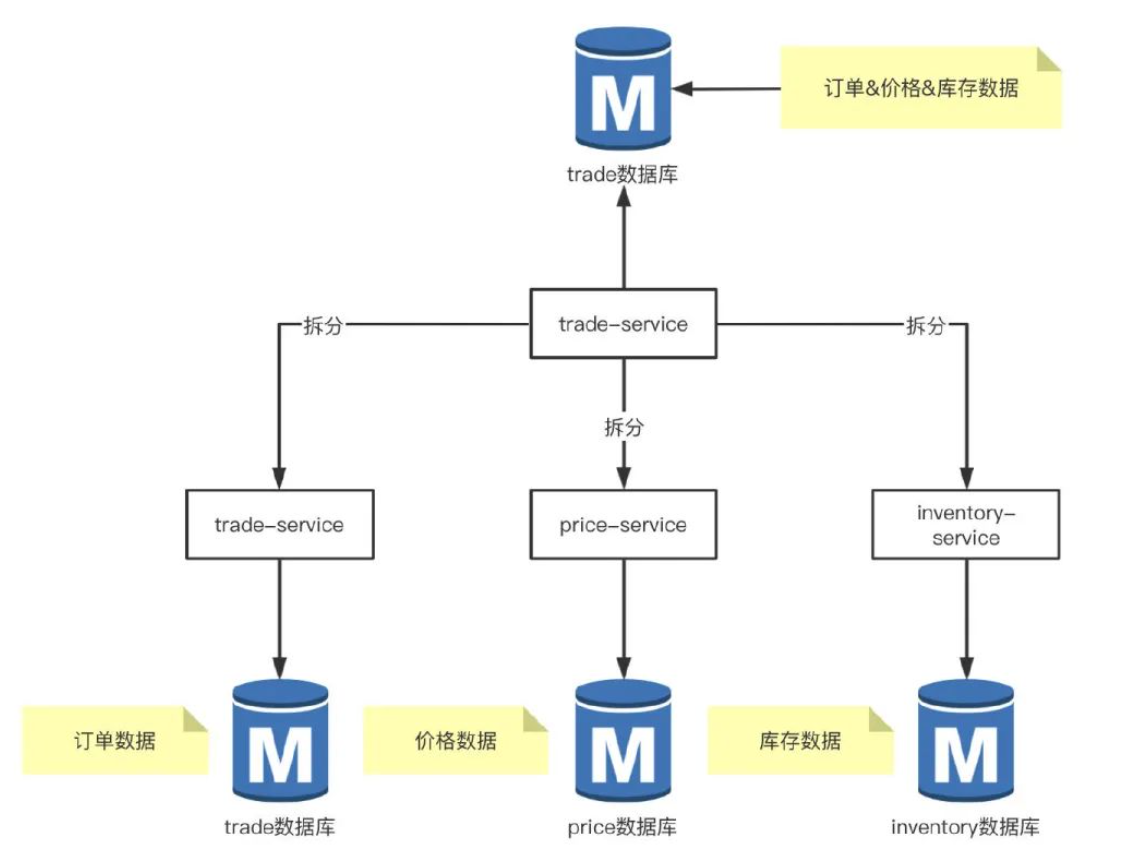
这样按照业务模块拆分之后,相应的 trade 数据库被拆分到了三个 RDS 实例中,数据库的写入能力提升,服务的接口响应时间也变短了,提高了系统的稳定性。
水平分库
水平分库是指将同一个业务模块或功能中的数据按照某个维度进行划分,将数据分散到多个数据库中。这样可以提高数据库的并发处理能力和读写性能。其中水平分库所用的比例要远高于垂直分库。
例:交易数据库的订单表 orders 有2亿多数据,RDS 实例遇到了写入瓶颈,普通的 insert 都需要50ms,时常也会收到 CPU 使用率告警,这时就要考虑分库了。根据业务量增长趋势,计划扩容一台同配置的RDS实例,将订单表 orders 拆分20个子表,每个 RDS 实例10个。
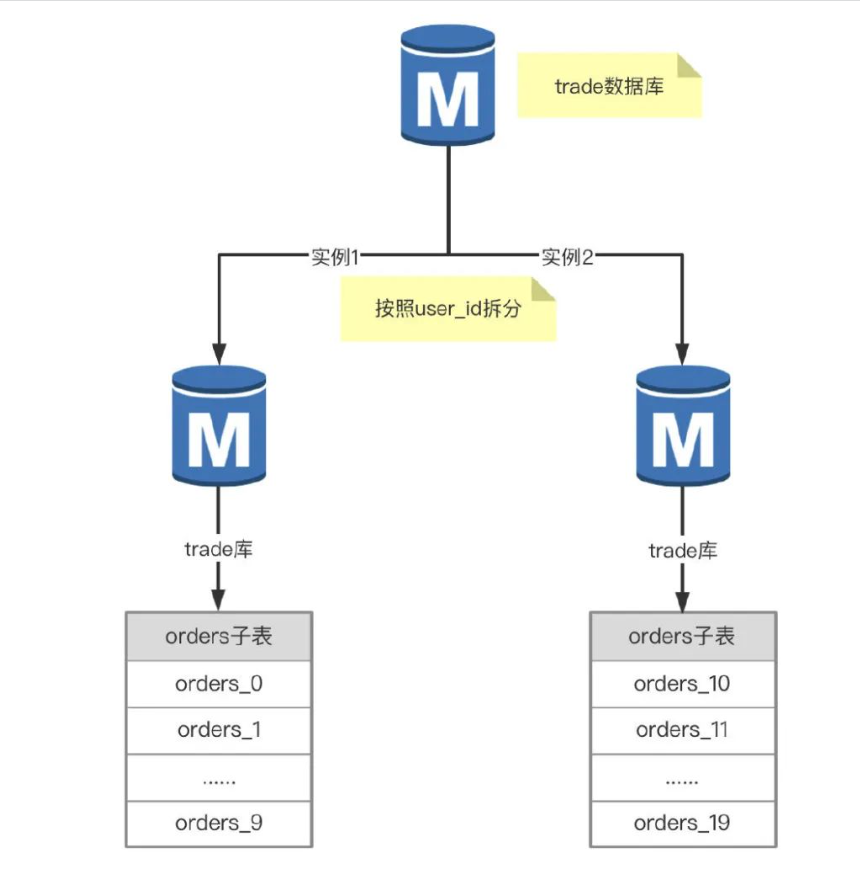
务量增长趋势,计划扩容一台同配置的RDS实例,将订单表 orders 拆分20个子表,每个 RDS 实例10个。
[外链图片转存中…(img-RuQl9k7P-1698479367191)]
这样解决了订单表 orders 太大的问题,查询的时候要先通过分区键 user_id 定位是哪个 RDS 实例,再定位到具体的子表,然后做 DML操作,问题是代码改造的工作量大,而且服务调用链路变长了,对系统的稳定性有一定的影响。其实已经有些数据库中间件实现了分库分表的功能,例如常见的 mycat,阿里云的 DRDS 等。















 327
327











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









