







学习思路
内容来源于百度毕然老师学习课程教案。图1是毕然老师总结的“纵横学习方法”。
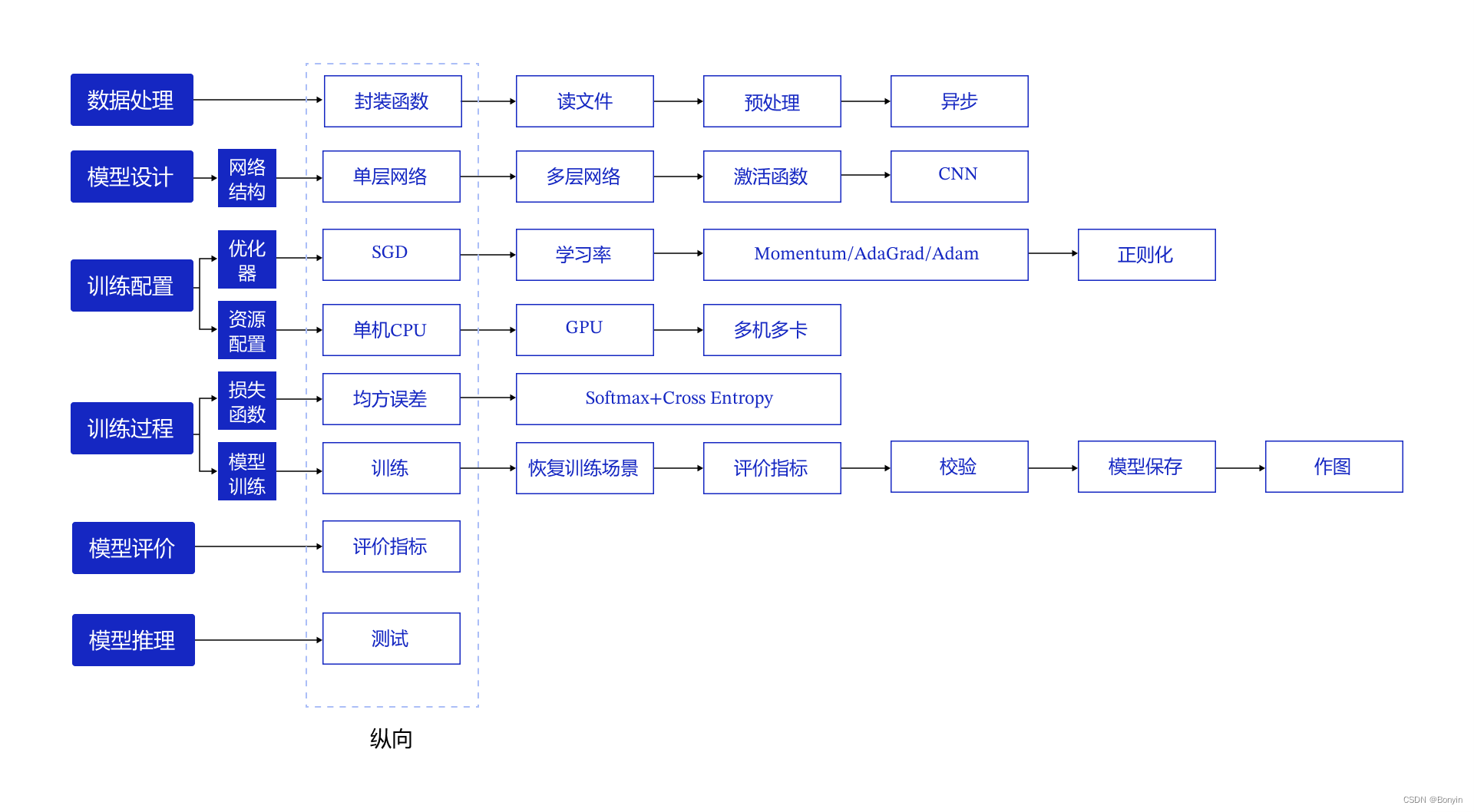 首先基于百度的paddle来建模解决一个问题的思路,纵向上分为六个步骤,横向上对每一个步骤进行细分学习。
首先基于百度的paddle来建模解决一个问题的思路,纵向上分为六个步骤,横向上对每一个步骤进行细分学习。
数据处理
# 设置数据读取器,API自动读取MNIST数据训练集
train_dataset = paddle.vision.datasets.MNIST(mode='train')
读取minst的train训练集数据,paddle内置了常规用于测试开发的数据集。
mnist
cifar
Conll05
imdb
imikolov
movielens
sentiment
uci_housing
wmt14
wmt16
可视化第一张图片数据
train_data_0 = np.array(train_dataset[0][0])
train_label_0 = np.array(train_dataset[0][1])
# 显示第一batch的第一个图像
import matplotlib.pyplot as plt
plt.figure("Image") # 图像窗口名称
plt.figure(figsize=(2,2))
plt.imshow(train_data_0, cmap=plt.cm.binary)
plt.axis('on') # 关掉坐标轴为 off
plt.title('image') # 图像题目
plt.show()
print("图像数据形状和对应数据为:", train_data_0.shape)
print("图像标签形状和对应数据为:", train_label_0.shape, train_label_0)
print("\n打印第一个batch的第一个图像,对应标签数字为{}".format(train_label_0))
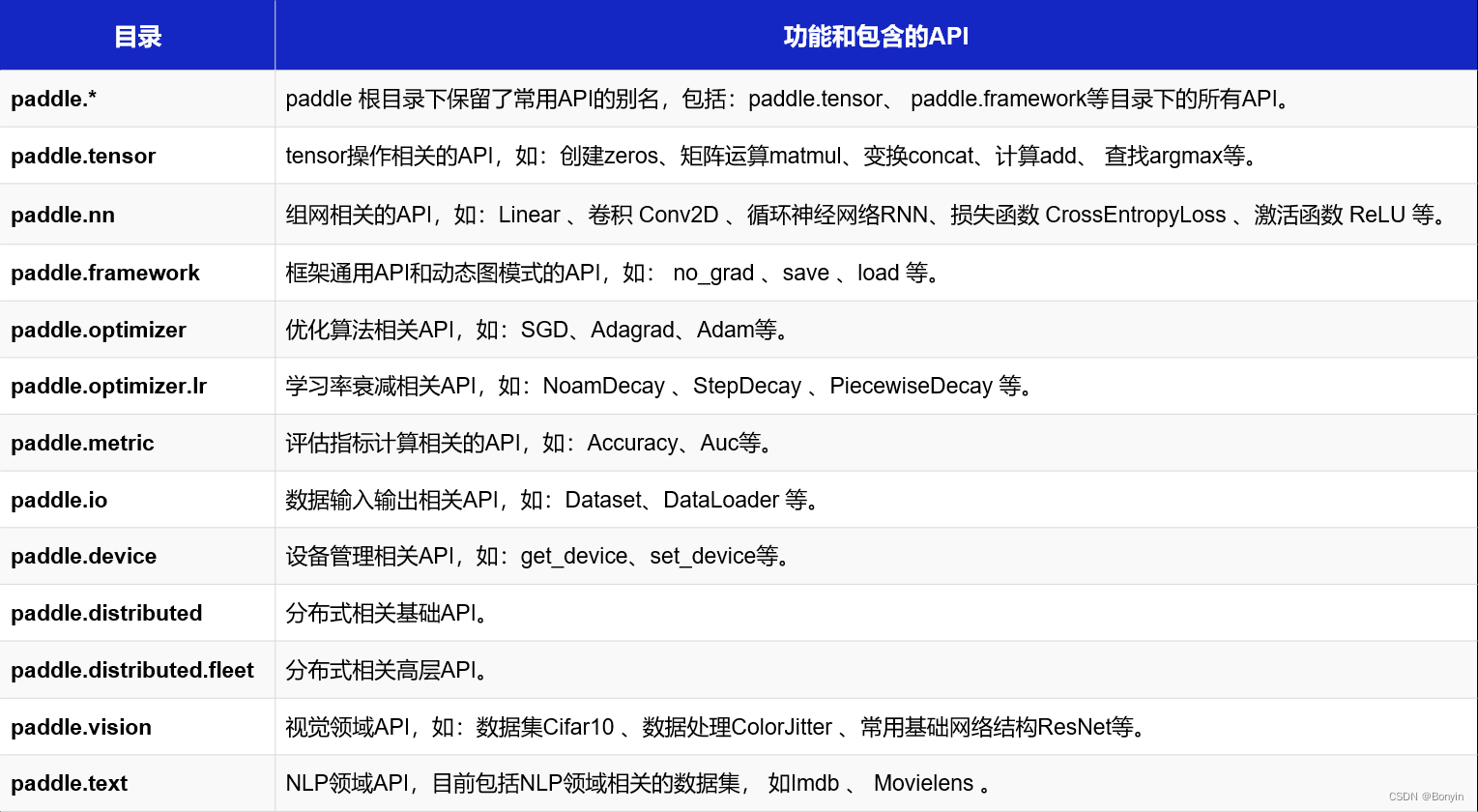
 飞将api介绍
飞将api介绍
模型设计
在房价预测深度学习任务中,我们使用了单层且没有非线性变换的模型,取得了理想的预测效果。在手写数字识别中,我们依然使用这个模型预测输入的图形数字值。其中,模型的输入为784维(28×28)数据,输出为1维数据,如 图4 所示。
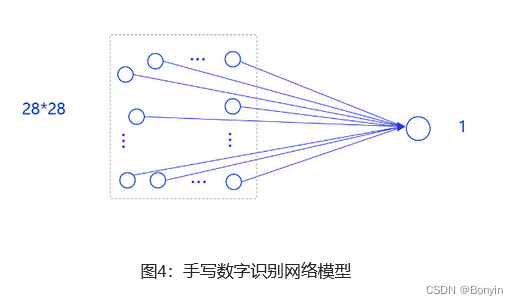
输入像素的位置排布信息对理解图像内容非常重要(如将原始尺寸为
28
×
28
28×28
28×28图像的像素按照
7
×
112
7×112
7×112的尺寸排布,那么其中的数字将不可识别),因此网络的输入设计为
28
×
28
28×28
28×28的尺寸,而不是
1
×
784
1×784
1×784,以便于模型能够正确处理像素之间的空间信息。
————————————————————————————————————
说明
在单层神经网络(对输入做加权求和)没有处理图像的像素点的位置信息,模型的输出结果很差的。
————————————————————————————————————
下面以类的方式组建手写数字识别的网络:
# 定义mnist数据识别网络结构,同房价预测网络
class MNIST(paddle.nn.Layer):
def __init__(self):
super(MNIST, self).__init__()
# 定义一层全连接层,输出维度是1
self.fc = paddle.nn.Linear(in_features=784, out_features=1)
# 定义网络结构的前向计算过程
def forward(self, inputs):
outputs = self.fc(inputs)
return outputs
训练配置
训练之前先需要生成模型实例。在设置优化算法和学习率。
model = MNIST()
def train(model):
# 启动训练模式
model.train()
paddle.io.Dataloader(paddle.vision.datasets.MNIST(mode='train'), batch_size=16,shuffle=True)
# 定义优化器
opt = paddle.optimizer.SGD(learning_rate=0.001, parameters=model.parameters())
训练过程
训练过程采用二层循环嵌套。训练完成后保存模型和参数,方便后续使用。
- 内层循环:负责整个数据集的一次遍历,遍历数据采用分批次batch_size。
- 外层循环:定义遍历数据集的次数,本次 训练中外层循环10次,epoch设置。
model = MNIST()
def train(model):
# 启动训练模式
model.train()
paddle.io.Dataloader(paddle.vision.datasets.MNIST(mode='train'), batch_size=16,shuffle=True)
# 定义优化器
opt = paddle.optimizer.SGD(learning_rate=0.001, parameters=model.parameters())
EPOCH_NUM= 10
loss_list=[]
for epoch in range(EPOCH_NUM):
for batch_id, data in enumerate(train_loader()):
images = norm_img(data[0]).astype('float32')
labels = data[1].astype('float32')
#前向计算的过程
predicts = model(images)
# 计算损失
loss = F.square_error_cost(predicts, labels)
avg_loss = paddle.mean(loss)
#每训练了1000批次的数据,打印下当前Loss的情况
if batch_id % 1000 == 0:
loss = avg_loss.numpy()[0]
loss_list.append(loss)
print("epoch_id: {}, batch_id: {}, loss is: {}".format(epoch, batch_id, loss))
#后向传播,更新参数的过程
avg_loss.backward()
opt.step()
opt.clear_grad()
return loss_list
loss_list = train(model)
paddle.save(model.state_dict(), './mnist.pdparams')
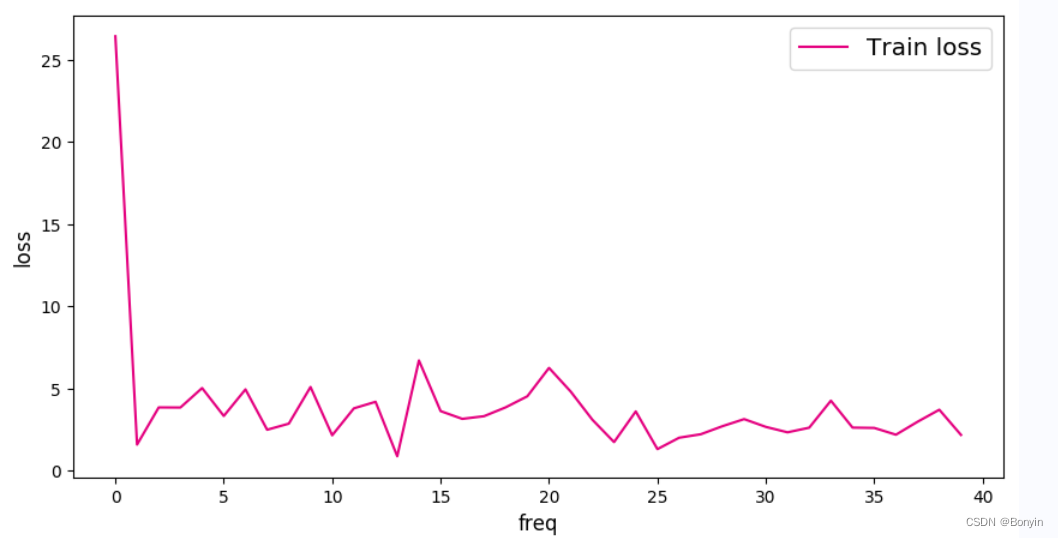
绘制损失变化曲线
def plot(loss_list):
plt.figure(figsize=(10,5))
freqs = [i for i in range(len(loss_list))]
# 绘制训练损失变化曲线
plt.plot(freqs, loss_list, color='#e4007f', label="Train loss")
# 绘制坐标轴和图例
plt.ylabel("loss", fontsize='large')
plt.xlabel("freq", fontsize='large')
plt.legend(loc='upper right', fontsize='x-large')
plt.show()
plot(loss_list)
模型测试
模型测试主要目的是验证训练好的模型是否可以正确识别出数字,包括已下步骤:
1.声明实例。
2.加载模型,加载训练过程中保存的模型。
3.灌入模型,将测试样本传入模型实例,模型的状态设置为eval模式,告诉框架接下来只是做前向计算,不会计算梯度和反向传播梯度。
4.获取预测结果,取整后作为预测标签输出。
# 模型在测试集上的准确率计算过程
params_file_path = 'mnist.pdparams'
def test(params_file_path):
# 定义预测过程
model = MNIST()
# 加载模型参数
param_dict = paddle.load(params_file_path)
model.load_dict(param_dict)
# 灌入数据
model.eval()
accs = []
for batch_id,data in enumerate(test_loader):
images = norm_img(data[0]).astype('float32')
labels = data[1].astype('int64')
#前向计算的过程
predicts = model(images)
acc = paddle.metric.accuracy(predicts,labels)
accs.append(acc.numpy()[0])
avg_acc = np.mean(accs)
print("平均准确率", avg_acc)
下面随机加载自己准备的一张图片来做测试:
# 导入图像读取第三方库
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
img_path = './work/example_0.jpg'
# 读取原始图像并显示
im = Image.open('./work/example_0.jpg')
plt.imshow(im)
plt.show()
# 将原始图像转为灰度图
im = im.convert('L')
print('原始图像shape: ', np.array(im).shape)
# 使用Image.ANTIALIAS方式采样原始图片
im = im.resize((28, 28), Image.ANTIALIAS)
plt.imshow(im)
plt.show()
print("采样后图片shape: ", np.array(im).shape)
预测:
# 读取一张本地的样例图片,转变成模型输入的格式
def load_image(img_path):
# 从img_path中读取图像,并转为灰度图
im = Image.open(img_path).convert('L')
# print(np.array(im))
im = im.resize((28, 28), Image.ANTIALIAS)
im = np.array(im).reshape(1, -1).astype(np.float32)
# 图像归一化,保持和数据集的数据范围一致
im = 1 - im / 255
return im
# 定义预测过程
model = MNIST()
params_file_path = 'mnist.pdparams'
img_path = './work/example_0.jpg'
# 加载模型参数
param_dict = paddle.load(params_file_path)
model.load_dict(param_dict)
# 灌入数据
model.eval()
tensor_img = load_image(img_path)
result = model(paddle.to_tensor(tensor_img))
print('result',result)
# 预测输出取整,即为预测的数字,打印结果
print("本次预测的数字是", result.numpy().astype('int32'))
result Tensor(shape=[1, 1], dtype=float32, place=CPUPlace, stop_gradient=False,
[[1.19249249]])
本次预测的数字是 [[1]]
从打印结果来看,模型预测出的数字是与实际输出的图片的数字不一致。这里只是验证了一个样本的情况,如果我们尝试更多的样本,可发现许多数字图片识别结果是错误的。因此完全复用房价预测的实验并不适用于手写数字识别任务!
接下来我们会对手写数字识别实验模型进行逐一改进,直到获得令人满意的结果。















 2379
2379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









