






 这篇博客详细介绍了Python的学习过程,从解释器安装到PyCharm的配置,包括Python的程序执行机制、语法基础如注释、变量、数据类型、运算符、输入输出,再到条件语句、循环结构、数据类型操作、函数、文件操作等基础知识,为Python初学者提供了全面的入门指导。
这篇博客详细介绍了Python的学习过程,从解释器安装到PyCharm的配置,包括Python的程序执行机制、语法基础如注释、变量、数据类型、运算符、输入输出,再到条件语句、循环结构、数据类型操作、函数、文件操作等基础知识,为Python初学者提供了全面的入门指导。
笔记目录
学前准备
Python解释器安装包
下载
安装
Windows:直接安装,勾选Add python3.x to PATH
Linux(ubuntu):
方法一:使用apt-get工具,在终端键入sudo apt-get install python3.x
方法二:编译源码安装,
1 下载源码:在目标文件夹中打开终端并键入wget-c https://www.python.org/ftp/python/3.8.1/Python- 3.x.tgz(在python官网中复制)![Dowdloads下选择Source code]
2 解压键入:tar -xzvf Python-3.x.tgz
3 配置:终端键入:cd python3.x的解压目录路径,然后键入:sudo ./configure
4 安装编译需要的依赖包:1.终端输入:sudo apt-get install bulid-essential checkinstall,2.sudo apt-get install libreadline-gplv2-dev libncursesw5-dev libssl-dev libsqlite3-dev tk-dev libgdbm-dev libc6-dev libbz2-dev
5 编译:终端键入make
6 安装:终端键入sudo make install完成安装

Pycharm
下载
官网
Pycharm有专业版(付费使用)和社区版(免费使用),如果所在的学校给学生发放了校园邮箱,可以利用校园邮箱申请教育版Pycharm,免费使用。
常用的快捷键
PEP-8代码规范自动改正:Ctrl+Alt+L
Shift+Enter:换行
Ctrl+/:注释
Ctrl+D:复制一行
Ctrl+Y:删除一行
Ctrl+0:复写代码
选中内容+Tab:退格
Ctrl+F:查找
Ctrl+R:替换
Ctrl+Shift+Numpad-:折叠所有代码
Ctrl+Shift+Numpad+:展开所有代码
Shift+TAB:减少一个缩进
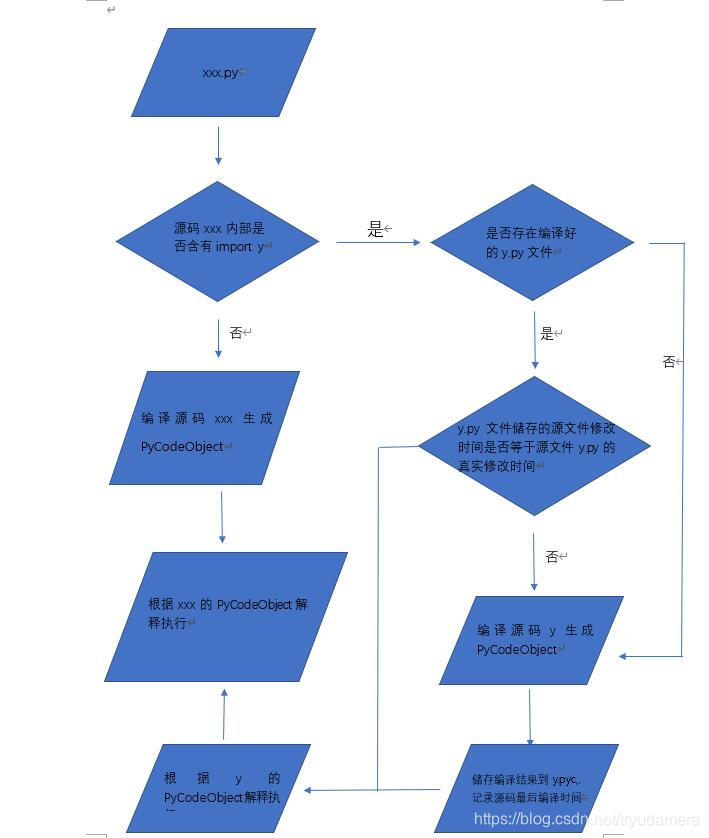
Python程序执行机制
语法基础
注释和中文乱码
1.注释的作用:
帮助我们理解代码逻辑
与别人合作时,减少沟通成本
开发模块时减少他人使用成本
可以临时注释一段代码方便调试
2.注释的类型:
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
1.单行注释:
1.使用'#' :
#这是注释
2.使用' "" ',或者" '' ":
"这是注释"
'这是注释'
2.多行注释:
使用" ''' ''' "
'''这是一个
多行注释'''
使用' "" "" '
"""这是一个
多行注释
"""
3 特殊注释
1.Linux中用于指定解释器
#!/use/bin/[env] python
2.pyhon2.x版本中用于处理中文乱码问题
# encoding=utf-8/_*_coding:utf-8_*_
变量
含义:
储存数据的容器
特性:
可以引用某个具体的数值;可以改变这个引用
定义变量的方法
# 方法一:变量名 = 值
num = 1
# 方法二:变量名1, 变量名2 = 值1, 值2
num1, num2 = 1, 2
# 方法三:变量名1 = 变量名2 = 值
num1 = num2 = 1
变量产生的原因:
方便维护;节省空间
变量使用注意事项:
一个变量只能对应一个值
命名规范:字母,数字(不能位于首位),下划线
见名知意
驼峰标识:多个单词组合第二个单词首字母大写
非关键字:['False', 'None', 'True', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif',
'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise',
'return', 'try', 'while', 'with', 'yield']
区分大小写
变量使用前一定要赋值
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
关键字查询方法:
import keyward
print(keyward.kwlist)
数据类型
定义:
对程序处理的相关数据进行分类
为什么要区分类型:
对不同类型的数据分配不同的储存空间
根据数据类型的特征,做相应的数据处理
数据类型:
Numbers(数值)、Bool(布尔)、String(字符串)、List(列表)、Set(集合)、Tuple(元组)、
Dictory(字典)、NoneType(空类型)
数据转化:
| 函数 | 说明 |
|---|---|
| int(x,[,base]) | 将x转化成一个整数(向下取整) |
| float(x) | 将x转化成一个浮点数 |
| str(x) | 将x转化成一个字符串 |
| repr(x) | 将x转化成一个表达式字符串 |
| chr(x) | 将x转化成一个对应的ASCII字符 |
| unicoed(x) | 将x转化成一个Unicode字符 |
| ord(x) | 将字符x转化成对应的ASCII整数值 |
| hex(x) | 将x转化成一个十六进制的字符串 |
| oct(x) | 将x转化成一个对应的八进制字符串 |
| eval(str) | 计算字符串中的有效表达式,并返回对象 |
| tuple(s) | 将序列s转换成一个元组 |
| list(s) | 将序列s转化成一个列表 |
动态类型与静态类型:
静态类型:数值类型是编译的时候确定的,后期无法修改(c语言)
静态类型:数值类型是运行时进行判定的,可以动态修改(python)
强类型与弱类型:
弱类型:数值类型比较弱势,不同的环境下,很容易·改变
强类型:数值类型比较强势,不会轻易随环境的变化而变化
查看数据类型的方法:
print(type('想要查看的数据'))
运算符
数值运算符
| 符号 | 含义 |
|---|---|
| + | 加法运算符 |
| - | 减法运算符 |
| * | 乘法运算符 |
| ** | 幂运算符 |
| / | 除法运算符(结果为浮点数) |
| // | 整除运算符(结果为整数,向下取整) |
| % | 求模运算符(求余运算符) |
| = | 赋值运算符 |
| 注意 | 除法除数不能为零,算术优先顺序和数学一致 |
复合运算符
| 符号 | 等价式子 |
|---|---|
| 公式 | x op y ==> x = x op y (op为二次运算符) |
| += | x += y ==> x = x + y |
| -= | x -= y ==> x = x - y |
| *= | x *= y ==> x = x * y |
| /= | x /= y ==> x = x / y |
| %= | x %= y ==> x = x % y |
| //= | x //= y ==> x = x // y |
| **= | x ** = y ==> x =x ** y |
比较运算符
| 符号 | 含义 |
|---|---|
| < | 小于 |
| > | 大于 |
| != / <>(仅限python2.x) | 不等于 |
| <= | 小于等于 |
| >= | 大于等于 |
| == | 等于 |
| is | 判断唯一标识是否相等(id(a) is id(b)) |
| a < b <c | 链式比较运算符 |
数据唯一标识获得方法:id(xxx)
逻辑运算符
| not | 非,真取假,假取真(not False >>>True |
| or | 或,一真全真 |
| and | 与,一假全假 |
注意:
1.非布尔类型的值,假如作为真假来判断,一般非零即真,非空即真
2.判断顺序从左至右,返回决定的值
3.整个逻辑表达式返回的结果不一定只是False或者True
and:1、print(5 and True)
# True
2、print(True and 5)
# 5
3、print(0 and True)
# 0
4、print(True and 0)
# 0
or: 1、print( 5 or True)
# 5
2、print(True or 5)
# True
3、print(5 or False)
# 5
4、print(False or 5)
# 5
输入输出和格式符
输入和输出
程序数据的来源:
1.程序内部已有的
2.从文件读取的
3.从网络服务器获取的
4.用户输入的
已经处理好的数据如何处理:
1.写回文件保存
2.返回到网络服务器保存
3.打印到控制台,通过一些界面展示给用户
输入函数:
python2.x:
raw_input()
将用户输入的内容当作字符串传递给变量
input() ==> raw_input(eval())
将用户输入的内容当作代码进行执行
python3.x:
input()
功能等价于python2.x中的raw_input()
输出:
python2.x
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
#python2.x输出,主要使用print语句
#1.格式化输出
#使用".format()"函数
print "我是{0},今年{1}岁".format(xxx,17)
# 我是xxx,今年17岁
#使用字符串格式化
#
print "我是%s,今年%d岁"%(xxx,17)
# 我是xxx,今年17岁
#2.输出到文件中
#没有文件将会自动创建
#
File = open(book.txt,"w")
print >>File,"xxxx"
#输出自动不换行
#输出目标末尾加上","
print '1',
print '2',
print '3'
# 1 2 3
#输出各值使用分隔符分割
#1.手动添加,2.使用join()函数
print '+'join.(["1","2","3"])
# 1+2+3
python3.x
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
# _*_ coding:utf-8 _*_
#python3.x输出,主要使用print(values,sep,end,file,flush)函数
#values:需要输出的值,sep:分割符,值与值之间添加特定的分隔符,end:输出结束后,以特定的符号结束,默认"/n",
#file: 输出的目标,默认是控制台,flush:直接输出,值为布尔类型
#格式化输出同python2.x
#输出到文件中
F = open(book.txt, "w")
print("xxxx", file = F)
#默认情况,输出到控制台
import sys
print('xxx', file = sys.stdout)
# xxx
#输出不换行
print('xxx', end = '')
# xxx
#输出各值使用分隔符分割
print("a", "b", "c", sep = '^*^')
# a^*^b^*^c
#flush参数说明
#在以下情况,程序将等待5s后才会打印xxxx
import time
print('xxxx',end = '')
time.sleep(5)
#想要先打印xxxx,在等待5s
import time
print('xxxx',end = '',flush = True)
time.sleep(5)
#产生原因:python输出时,先将要输出的内容转存到缓冲器当中。默认情况下,print()函数以'/n'结尾,自动换行,
#程序会等待print语句执行后才继续前进。去掉'/n'后,函数不会自动换行,会将下一句与print()识别为同一句一并执
#行,使用flush = True可以强制先执行print(),再执行后面的语句。
格式符
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
python占位格式符
# %[(name)[flags][width][.precision]typecode
#[]是可以省略的选项
#1.name为数据设置标识,制定的名称(key),查找对应的值,并格式化到字符串中
name = 'Jack'
score = 90
print("%(N)s的分数是%(S)d"%({'N':name, 'S':score}))
# Jack的分数是90
#2.width,表示占用的宽度
hour, minute = 6, 4
print("当前时间是:%(H)2d:%(M)2d"%({"H":hour,"M":minute}))
# 当前时间是: 6: 4
#3.flags设置数据格式
#空格,向右对齐
hour, min = 6, 4
print("当前时间是:%(H) 5d:%(M) 5d"%({"H":hour,"M":min}))
# 当前时间是: 6: 4
#-,向左对齐
hour, min = 6, 4
print("当前时间是:%(H)-5d:%(M)-5d"%({"H":hour,"M":min}))
# 当前时间是:6 :4
#0,表示用0填充
hour, min = 6, 4
print("当前时间是:%(H)02d:%(M)02d"%({"H":hour,"M":min}))
# 当前时间是:06:04
#4..precision,申明保留几位小数(四舍五入)
num = 1.296764
print("请保留小数点后四位:%.4f"%num)
# 请保留小数点后四位:1.2968
typecode
| 类型 | 符号 | 含义 |
|---|---|---|
| 数值 | i/d | 将整数、浮点数转化成十进制数 |
| 数值 | o | 将整数转化成八进制数 |
| 数值 | x | 将整数转化成十六进制数 |
| 数值 | e | 将整数、浮点数转化成科学计数法(小写e) |
| 数值 | E | 将整数、浮点数转化成科学计数法(大写E) |
| 数值 | f | 将整数、浮点数转化成浮点数(默认保留小数点后六位 |
| 数值 | F | 同f |
| 数值 | g | 自动调整将整数、浮点数转化成浮点数或者科学计数法表示(通常超过六位用科学计数法) |
| 数值 | G | 同g |
| 字符串 | s | 获取传入对象的_str_方法的返回值 |
| 字符串 | r | 获取传入对象的_repr_方法的返回值 |
| 字符串 | c | 将数字转化成其对应的Unicode编码,十进制范围为0<=i<=1114111 |
| 特殊 | % | 当字符串中存在格式换标志时,需要用%%表示一个百分号 |
| 注意 | Python中百分号格式化不存在自动将整数转化成二进制表示的方式,即不存在print(’%b’%121) |
单分支和多分支(if语句)
python程序执行顺序
大体上从上至下
分支:进入不同的分支
循环:多次执行相同的代码
单分支
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
# if 条件:
# 条件满足时,执行语句
age = 19
if age >= 18:
print('你已成年,可以上网')
# 你已成年,可以上网
双分支
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
#if 条件:
# 条件满足时执行的语句
#else:
# 条件不满足时执行的语句
age = 11
if age >= 18:
print("可以上网")
else:
print("未成年,不能上网,赶紧回家吃饭")
# 未成年,不能上网,赶紧回家吃饭
if嵌套
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
# if嵌套
# if 条件:
# 满足条件时执行的语句
# else:
# 不满足条件时需要执行的语句
# if:
# 满足条件时执行的语句
# else:
# 不满足条件时执行的语句
# if:
# 满足条件时需要执行的语句
# else:
# 不满足条件时执行的语句
Score = 98
if 85 <= Score <= 100:
print('优秀')
else:
if 70 <= Score < 85:
print('良好')
else:
if 60 <= Score < 70:
print('合格')
else:
print('不及格')
# 优秀
if嵌套的优略:减少对冗余代码的执行,提升代码的性能。但是难以阅读
if多分支
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
# if多分支,elif部分根据需要可以重复执行
# if 条件:
# 满足条件时执行的语句
# elif:
# 条件满足时执行的语句
# else:
# 条件满足时执行的语句
Score = 98
if 85 <= Score <= 100:
print('优秀')
elif 70 <= Score < 85:
print('良好')
elif 60 <= Score < 70:
print('合格')
else:
print('不及格')
# 优秀
if注意事项
1.强制缩进,一般使用TAB
2.区分代码块隶属于那个分支;区分else与那个if匹配(主要用于if嵌套)
3.python中没有类似与其他语言的switch...case语法
循环
while循环
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
#语法
#while 条件:
# 满足条件时执行的代码
num = 1
while num < 3:
num += 1
print(num)
# 3
# 计算1-10的和
num, result = 0, 0
while num < 10:
num += 1
result += num
print(result)
# 55
while循环与else连用:
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
# 语法
# while 条件:
# 满足条件时执行的代码
# else:
# 因条件不满足而结束循环时执行的代码
num = 0
while num < 10:
num += 1
else:
print(num)
# 10
# 如果while循环因为break打断,那么后续的else代码块将不会被执行
num = 0
while num < 10:
num += 1
print(num)
if num == 3:
break
else:
print('程序结束')
# 1
# 2
# 3
注意事项:
注意循环结束条件,防止死循环
python语言中,没有其他语言中的do...while循环
for循环
# for xx in xxx:
# 循环的代码块
# xxx一般是集合;xx是从集合里面取出的一个元素,在循环体中可以直接使用xx的值
# 当集合中的元素被遍历完后,循环结束
notice = '富强、民主、和谐'
for i in notice:
print(i, end='+')
# 富+强+、+民+主+、+和+谐+
for循环与else连用:方法与while与else连用一致。
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
# python循环打断:break与continue
# 当满足break的条件时,打断本次循环并结束整个循环
# 当满足continue的条件时,跳过当前循环,继续下一个循环
# break
for i in range(5):
if i == 2 or i == 3:
break
print(i, end=',')
# 0,1,
# continue
for i in range(5):
if i == 2 or i == 3:
continue
print(i, end=',')
# 0,1,4,
pass语句:
含义:是空语句,不做任何事情,一般用作占位符
作用:为了保持程序的完整性
python常用数据类型操作
数值
表现形式
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
# 表现形式:python3.x中的整型可以自动的调整大小,相当于python2.x中的long类型;数值区分正负
# 整数(int)
# 二进制,0b/0B,只包含0,1
num1, num2 = 0b01, 0B01
print(num1, num2)
# 1 1
# 八进制,0o/0O,只包含0-7
num1, num2 = 0o01234567, 0O01234567
print(num1, num2)
# 342391 342391
# 十六进制,0x/0X,只包含0-15,10-15使用a、b、c、d、e、f表示
num1, num2 = 0x0123456789abcdef, 0X0123456789abcdef
print(num1, num2)
# 81985529216486895 81985529216486895
# 浮点数(float),包含整数和小数部分,可以用科学计数法表示
num = 1.234e2
print(num)
# 123.4
# 复数(complex),包含实部和虚部
# num = a + bj
num = 1 + 2j
print(num)
# (1+2j)
# num = complex(a, b)
num = complex(1,2)
print(num)
# (1+2j)
进制转换
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
# 进制
# 概念:逢x进1即x进制
# 进制转换
# 其他进制转化成十进制
# n位x进制数=>十进制:an*x**(n-1)+a(n-1)*x**(n-2)···a1*x**0
num = '0b1111111'
# 获取数字长度,以及储存结果
Len = len(num) - 2
Ten = 0
# 通过循环满足转换式子
for i in range(Len):
i = i + 1
an = eval(num[-i])
Ten = Ten + an * 2 ** (i - 1)
# 打印两个结果查看是否相等
print(Ten == eval(num))
# True
# num转化成十进制数后是:127
# 十进制转换成其他进制
# 方法:除K取余法
# 函数法:二进制bin()、八进制oct()、十六进制hex()
# 除K取余法
num = 123456789
BNum = bin(num)
# 设置余数
K = 2
result = ''
# 建立循环进行除K
while True:
result = str(num % K) + result
# 设置循环结束条件
if num // K == 0:
result = '0b' + result
print('num转化成二进制数是:{}'.format(result))
# 验证方法是否正确
print(result == BNum)
break
num = num // K
# num转化成二进制数是:0b111010110111100110100010101
# True
# 函数法
# 二进制,bin()函数
num = 1548421
print('num的二进制数是:{}'.format(bin(num)))
# num的二进制数是:0b101111010000010000101
# 八进制,oct()函数
print('num的八进制数是:{}'.format(oct(num)))
# num的八进制数是:0o5720205
# 十六进制数,hex()函数
print('num的十六进制数是:{}'.format(hex(num)))
# num的十六进制数是:0x17a085
# 二进制转化成八进制:1.先转换成十进制,再转换成八进制;2.使用函数;3.整合三位为一位
num = 0b1001011
# num1 = 001 001 011
# 0b001 = 0o1
# 0b011 = 0o3
# num = 0o113
num2 = oct(num)
print(num2, num2 == '0o113')
# 0o113 True
# 二进制数转化成十六进制数:1.先转换成十进制,再转换成十六进制;2.使用函数;3.整合四位为一位
num = 0b10010001010
# num1 = 0100 1000 1010
# ob0100 = 0x4
# 0b1000 = 0x8
# 0b1010 = 0xa
num2 = hex(num)
print(num2, num2 == "0x48a")
# 0x48a True
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
# 常用操作
# 部分函数使用前需要导入
# 方法一:
# import 模块名
# 模块名.函数名(参数)
import time
print(time.localtime())
# 方法二:
# form 模块名 import 函数
# 函数(参数)
from datetime import datetime
print(datetime.now())
# 方法三:
# import 模块名 as 名称
# 名称.函数(参数)
import time as T
print(T.localtime())
# 方法四:
# from 模块名 import 函数 as 名称
# 名称(参数)
from datetime import datetime as Dt
print(Dt.now())
# 方法五:
# import 模块名, 模块名, 模块名, 模块名(适用于导入多个模块)
import time, datetime
print(time.localtime(), datetime.datetime.now())
# 常用的数学函数
# 求绝对值, abs(num)
num = - 19
print(abs(num))
# 19
# 求最大值, max(num1, num2, num3, ······)
print(max(1, 5, 6, 3, 20))
# 20
# 求最小值, min(num1, num2, num3, ······)
print(min(10, 39, 42, 1, 12))
# 1
# 四舍五入, round(x[, n]),n是保留的位数,默认为0
num = 22/7
print(round(num, 3))
# 3.143
# 幂运算, pow(x, y), x是底数,y是指数
x, y = 2, 4
print(pow(x, y))
# 16
# math模块函数
import math
num = 22/7
# ceil(), 向上取整
print(math.ceil(num))
# 4
# floor(), 向下取整
print(math.floor(num))
# 3
# sqrt(), 开方运算
print(math.sqrt(16))
# 4
# log(x, base), 以base为底数,求x的对数
print(math.log(10000, 100))
# 2
# math模块三角函数
import math
# 常量Π的表示
print(math.pi)
# 3.141592653589793
# degrees(x), 弧度转化为角度
degree1 = 1 / 6 * math.pi
print(math.degrees(degree1))
# 29.999999999999996
# radians(x), 角度转化为弧度
degree2 = 60
print(math.radians(degree2))
# 1.0471975511965976
# sin(x), 正弦; cos(x), 余弦: tan(x), 正切; asin(x), 反正弦; acos(x), 反余弦; atan(x), 反正切.
# x传递的是弧度
print(math.sin(degree1), math.cos(degree1), math.tan(degree1), math.asin(degree1), math.acos(degree1), math.atan(degree1))
# 0.49999999999999994 0.8660254037844387 0.5773502691896257 0.5510695830994463 1.0197267436954502 0.48234790710102493
# random随机函数模块
import random
# random(), 返回一个[0, 1)之间的小数
print(random.random())
# 0.8519072713974626
# choice(seq), 从序列seq中随机挑选一个数
seq = [5, 2, 6, 1, 7, 8, 4]
print(random.choice(seq))
# 2
# uniform(x, y), 返回一个[x, y]之间的随机小数
print(random.uniform(1, 9))
# 3.5754090587362395
# randint(x, y), 返回一个[x, y]之间的随机整数
print(random.randint(1, 9))
# 5
# randrange(start, stop = None, step = 1), 随机返回一个位于[start, end)之间的,步长为step的整数
print(random.randrange(1, 9, 3))
# 4
布尔(bool)
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
# 布尔类型
# 值:True, False
# 是int类型的子类,sisubclass()判断前一个变量是否是后一个变量的子类
print(issubclass(bool, int))
# True
# 当作int类型参与运算
result1 = True + 1
result2 = False + 1
print(result1, result2)
# 2 1
# 用于比较表达式的运算结果
# 用于if判定条件和while循环条件
字符串(str)
概念、形式
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
# 概念:由单个字符组成的集合
# 补充:转义符:'\',通过转换某个指定的字符,使它具有特殊的含义
# 常见转义符:
# \ 位于行尾时 续航符
Str = '天道' \
'酬勤'
print(Str)
# 天道酬勤
# \' 单引号 \" 双引号
Str1 = "神曰:\"不可说\"!"
Str2 = '神曰:\'不可说\'!'
# \n 换行
print('Do\nWhat\nYou\nLove')
# Do
# What
# You
# Love
# \t 制表符
print('2\t4\t8')
# 2 4 8
# 字符串形式
# 非原始字符串,使用单引号、双引号、三个单引号、三个双引号
Str3 = '这是一个\n字符串'
Str4 = "这是一个\n字符串"
Str5 = '''这是一\
个多行
字符串\n'''
Str6 = """这是一\
个多行
字符串\n"""
print(Str3, Str4, Str5, Str6)
# 这是一个
# 字符串 这是一个
# 字符串 这是一个多行
# 字符串
# 这是一个多行
# 字符串
# 原始字符串,使用单引号、双引号、三个单引号、三个双引号
Str7 = r'这是一个字符串'
Str8 = r"这是一个\n字符串"
Str9 = r'''这是一\
个多行
字符串'''
Str0 = r"""这是一\
个多行
字符串"""
print(Str7, Str8, Str9, Str0)
# 这是一个字符串 这是一个\n字符串 这是一\
# 个多行
# 字符串 这是一\
# 个多行
# 字符串
# 跨行:使用换行符\,或者使用小括号
name1 = ('天道'
'酬勤')
name2 = "天道" \
'酬勤'
print(name1, name2)
# 天道酬勤 天道酬勤
字符串操作
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
# 字符串的一般操作
# 字符串的拼接
# str1 + str2
print('天道' + "酬勤")
# 天道酬勤
# str1str2
print('天道'"酬勤")
# 天道酬勤
# 'xxx%sxx'%''或者format()
print('天道%s' % "酬勤")
print('天道{}'.format("酬勤"))
# 天道酬勤
# 字符串乘法
print('天道酬勤\t' * 3)
# 天道酬勤 天道酬勤 天道酬勤
# 字符串的切片操作
# 概念:获取某一个字符串中的某一段
# 获取某个字符,str[下标], 下表有两种,顺序从0开始,倒序从-1开始
Str = 'abcdefgh'
print(Str[2], Str[-1])
# c h
# 获取字符串的一个片段
# str[start:end:k], 截取范围[start, end), start默认值是0,end默认值是len(str),k步长的默认值是1
# 当k > 0时,截取顺序从左至右,当k < 0时,截取顺序从右至左
# 不能从头部跳到尾部,反之亦然;即不能str[0:len(str):-1] 或者 str[-len(str):-1:1]
Str = 'abcdefg'
print(Str[0:4:2])
# ac
# 反转字符串str[::-1]
print(Str[::-1])
# gfedcba
字符串函数操作
查找计算
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
# 字符串的函数操作
# 内建函数可直接使用,对象方法使用方法为:对象.方法(参数)
# 查找计算
# len()函数(内建)
# 作用:计算字符串长度
# 语法:len(str)
# 参数:str字符串
# 返回值:字符串长度,int类型
# 注意:转义符整个算一个字符
Str = 'Do what you love'
print(type(len(Str)), len(Str))
Str1 = 'Do what\n you love'
print(len(Str1))
# <class 'int'> 16
# 17
# find()函数(对象方法)
# 作用:查找子串索引位置
# 语法:str.find(sub, start=0, end=len(str))
# 参数:sub:需要检索的子串,start:检索的起始位置,默认为0,end:检索的结束位置,默认为len(str)
# 返回值:
# 找到了:指定索引,int类型
# 没找到:-1
# 注意:
# 查找范围{start, end)
# 从左至右找,找到后立即停止
print(type(Str.find('o', 4)), Str.find('o', 4))
# <class 'int'> 9
# rfind()函数(对象方法)
# 作用:同find()
# 语法:同find()
# 参数:同find()
# 返回值:同find()
# 注意:
# 同find()
# 区别:从右至左查找
print(type(Str.rfind('o', 4, 13)), Str.rfind('o', 4, 17))
# <class 'int'> 13
# index()函数(对象方法)
# 作用:获取子串索引位置
# 语法:str.index(sub, start=0, end=len(str))
# 参数:sub:需要检索的字符串,start:检索起始的位置,end:检索结束的位置
# 返回值:
# 找到了:指定索引,int类型
# 没找到:异常:ValueError: substring not found
# 注意:
# 查找范围:[start, end)
# 从左至右查找,找到后立即停止
print(type(Str.index('t', 4, 7)), Str.index('t', 4, 7))
# <class 'int'> 6
# rindex()函数(对象方法)
# 作用:同index()
# 语法:同index()
# 参数:同index()
# 返回值:同index()
# 注意:
# 同index()
# 区别:从右至左查找
print(type(Str.rindex('o')), Str.rindex('o'))
# <class 'int'> 13
# count()函数(方法类型)
# 作用:计算某个子字符串出现的次数
# 语法:str.count(sub, start=0, end=len(str))
# 参数:sub:需要检索的子字符串,start:检索起始的位置,end:检索结束的位置
# 返回值:子字符串出现的次数,int类型
print(type(Str.count('o')), Str.count('o'))
# <class 'int'> 3
转换操作
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
# 转换操作
# replace()函数(对象方法)
# 作用:使用给定的新字符串替换原字符串中的旧的字符串
# 语法:str.replace(old, new, count)
# 参数:old:需要替换的旧字符串,new:用来替换的新字符串,count:替换的次数,默认为str.count(new)
# 返回值:替换字符串后的新字符串
# 注意:
# 并不会修改原字符串
# 从左至右替换,直到替换次数为0
Str = 'Do what you love'
print(Str.replace('o', "O", 2))
print(Str)
# DO what yOu love
# Do what you love
# capitalize()函数(对象方法)
# 作用:将字符串的首个字符大写
# 语法:str.capitalize()
# 参数:无
# 返回值:将首字符大写后的字符串
# 注意:并不会修改原字符串
Str1 = 'do what you love'
print(Str.capitalize())
print(Str1)
# Do what you love
# do what you love
# title()函数(对象方法)
# 作用:将字符串中的每个单词首字母大写
# 语法:str.title()
# 参数:无
# 返回值:每个字母首字母大写后的字符串
# 注意:
# 并不会修改原字符串
# 使用间隔符分割也视为单个单词
print(Str.title())
print(Str)
print('a!b@cd$e$f%g^h'.title())
# Do What You Love
# Do what you love
# A!B@CD$E$F%G^H
# lower()函数(对象方法)
# 作用:将字符串中的所有字母小写
# 语法:str.lower()
# 参数:无
# 返回值:所有字母小写后的字符串
# 注意:并不会修改原字符串
Str2 = 'DO WHAT YOU LOVE'
print(Str2.lower())
# do what you love
# DO WHAT YOU LOVE
# upper()函数(对象方法)
# 作用:将字符串中的所有字符大写
# 语法:str.upper()
# 参数:无
# 返回值:字符串中的所有字母大写后的字符串
# 注意:并不会修改原字符串
print(Str.upper())
print(Str)
# DO WHAT YOU LOVE
# Do what you love
填充压缩
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
# 填充压缩
# ljust()函数(对象方法)
# 作用:在字符串右侧填充指定字符达到指定长度
# 语法:str.ljust(width, fillchar)
# 参数:width:填充后字符串长度,fillchar:指定的填充字符,只能指定一个,默认为空格
# 返回值:填充完成后的字符串
# 注意:
# 并不会修改原字符串
# 空格也会占位
Str = """WEWER Though astronauts currently on the International Space Station WEWE"""
print(Str.ljust(80, '*'))
print(Str)
# WEWER Though astronauts currently on the International Space Station WEWE*******
# WEWER Though astronauts currently on the International Space Station WEWE
# rjust()函数(对象方法)
# 作用:在字符串左侧填充指定字符达到指定长度
# 语法:同ljust()
# 参数:同ljust()
# 返回值:同ljust()
# 注意:同ljust()
print(Str.rjust(80, '*'))
print(Str)
# *******WEWER Though astronauts currently on the International Space Station WEWE
# WEWER Though astronauts currently on the International Space Station WEWE
# center()函数(方法对象)
# 作用:字符串置中,在两侧填充指定字符达到指定长度
# 语法:str.center(width, fillchar)
# 参数:width:填充后字符串的长度,fillchar:指定的填充字符,只能指定一个,默认为空格
# 返回值:填充完成后的字符串
# 注意:
# 并不会修改原字符串
# 空格也会占位
print(Str.center(80, '*'))
print(Str)
# ***WEWER Though astronauts currently on the International Space Station WEWE****
# WEWER Though astronauts currently on the International Space Station WEWE
# lstrip()函数(对象方法)
# 作用:仅仅移除最左侧的指定字符串集
# 语法:str.lstrip(chars)
# 参数:chars:指定的字符串集,默认为空格
# 返回值:移除字符串集后的字符串
# 注意:
# 不会修改原字符串
# 指定字符串,有空格或者其他非指定字符时,不会产生效果
Str1 = """ WEWER Though astronauts currently on the International Space Station WEWER """
print(Str.lstrip('WE'))
print(Str.lstrip('W'))
print(Str)
print(Str1.lstrip('WE'))
# R Though astronauts currently on the International Space Station WEWE
# EWER Though astronauts currently on the International Space Station WEWE
# WEWER Though astronauts currently on the International Space Station WEWE
# WEWER Though astronauts currently on the International Space Station WEWER
# rstrip()函数(对象方法)
# 作用:仅仅移除最右侧的指定字符串集
# 语法:同lstrip()
# 参数:同lstrip()
# 返回值:同lstrip()
# 注意:同lstrip()
Str2 = """ WEWER Though astronauts currently on the International Space Station WEWER """
print(Str.rstrip('WE'))
print(Str)
print(Str2.rstrip('WE'))
# WEWER Though astronauts currently on the International Space Station
# WEWER Though astronauts currently on the International Space Station WEWE
# WEWER Though astronauts currently on the International Space Station WEWER
分割拼接
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
# 分割拼接
# split()函数
# 作用:将原字符串分割成几个字符串
# 语法:str.split(sep, maxsplit)
# 参数:sep:指定的分隔符,maxsplit:最大的分割次数,省略是有多少分割多少
# 返回值:分割后子字符串组成的列表,list类型
# 注意:并不会修改原字符串
Str = 'Do-what-you-love'
print(type(Str.split('-')), Str.split('-'))
print(Str)
# <class 'list'> ['Do', 'what', 'you', 'love']
# Do-what-you-love
# partition()函数
# 作用:根据指定的分隔符将原字符串分割
# 语法:str.partition(sep)
# 参数:sep:指定的分隔符
# 返回值:
# 查找到指定的分隔符:(sep左侧的字符串, sep, sep右侧的字符串),tuple类型
# 没找到指定的分隔符:(原字符串, '', ''), tuple类型
# 注意:
# 不会修改原字符串
# 从左至右开始检索
Str1 = 'Do^what*you^love'
print(type(Str1.partition('^')), Str1.partition('^'))
print(Str1.partition('!'))
print(Str1)
# <class 'tuple'> ('Do', '^', 'what*you^love')
# ('Do^what*you^love', '', '')
# Do^what*you^love
# rpartition()函数
# 作用:同partition()函数
# 语法:同partition()函数
# 参数:同partition()函数
# 返回值:
# 找到指定的分隔符:(sep左侧的字符串, sep, sep右侧的字符串),tuple类型
# 未找到指定的分隔符:('', '', 原字符串),tuple类型
# 注意:
# 不会修改原字符串
# 从右至左开始检索
print(type(Str1.rpartition('^')), Str1.rpartition('^'))
print(Str1.rpartition('!'))
print(Str1)
# <class 'tuple'> ('Do^what*you', '^', 'love')
# ('', '', 'Do^what*you^love')
# Do^what*you^love
# splitlines()函数
# 作用:根据换行符(\r,\n),将字符串分割成多个元素,保存到列表中
# 语法;str.splitlines(keepends)
# 参数:keepends:是否保留换行符,bool类型,默认为False
# 返回值:被换行符分割后的元素组成的列表,list类型
# 注意:不会修改原字符串
Str2 = 'Do\nwhat\tyou\rlove'
print(type(Str2.splitlines()), Str2.splitlines())
print(Str2.splitlines(True))
print(Str2)
# <class 'list'> ['Do', 'what\tyou', 'love']
['Do\n', 'what\tyou\r', 'love']
# Do
# love
# join()函数
# 作用:根据指定的字符串,将给定的可迭代对象进行拼接,得到拼接后的字符串
# 语法:join(iterable)
# 参数:iterable:可迭代对象,即可被for遍历的对象,包括:字符串、列表、元组、字典等
# 返回值:拼接好的字符串,str类型
List1 = ['Do', 'what', 'you', 'love']
print(type('-'.join(List1)), '-'.join(List1))
# <class 'str'> Do-what-you-love
判断
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
# 判定
# isalpha()函数
# 作用:判断字符串中的所有字符是否都是字母
# 语法:str.isalpha()
# 参数:无
# 返回值:bool值
# 注意:标点符号、特殊符号(\n之类的)、空串、空格都会被判定为False
Str = '123'
Str1 = "abc"
Str2 = ''
Str3 = " "
Str4 = '123\n'
Str5 = "abc\n"
print(type(Str.isalpha()), Str.isalpha(), Str1.isalpha(),
Str2.isalpha(), Str3.isalpha(), Str4.isalpha(), Str5.isalpha())
# <class 'bool'> False True False False False False
# isdigit()函数
# 作用:判断字符串中的所有字符是否为数字
# 语法:str.isdigit()
# 参数:无
# 返回值:bool值
# 注意:标点符号、特殊符号(\n之类的)、空串、空格都会被判定为False
print(type(Str.isdigit()), Str.isdigit(), Str1.isdigit(),
Str2.isdigit(), Str3.isdigit(), Str4.isdigit(), Str5.isdigit())
# <class 'bool'> True False False False False False
# isalnum()函数
# 作用:判断字符串是否有字母或者数字组成
# 语法:str.isalnum()
# 参数:无
# 返回值:bool值
# 注意:标点符号、特殊符号(\n之类的)、空串、空格都会被判定为False
Str6 = '123abc'
Str7 = '123abc\n'
Str8 = '123abc '
print(type(Str6.isalnum()), Str1.isalnum(), Str6.isalnum(),
Str7.isalnum(), Str8.isalnum())
# <class 'bool'> True True False False
# isspace()函数
# 作用:判断字符串是否由空格组成
# 语法:str.isspace()
# 参数:无
# 返回值:bool值
# 注意:标点符号、空串都会被判定为False
Str9 = '\n'
print(type(Str3.isspace()), Str3.isspace(), Str2.isspace(), Str9.isspace())
# <class 'bool'> True False True
# startswith()函数
# 作用:判断字符串在指定范围内是否以指定前缀开头
# 语法:str.startwith(prefix, start=0, end=len(str))
# 参数:prefix:用于判断的指定前缀,start:检索开始的位置,end:检索结束的位置
# 返回值:bool值
# 注意:
# 判断范围:[start, end)
# 空格也被视为一个字符
StrA = 'xxxx.docx'
StrB = ' xxxx.docx '
print(type(StrA.startswith('xxx')), StrA.startswith('xx'), StrB.startswith('xx'))
# <class 'bool'> True False
# endswith()函数
# 作用:判断字符串指定范围是否以指定后缀结尾
# 语法:同startswith()
# 参数:同startswith()
# 返回值:同startswith()
# 注意:同startswith()
print(type(StrA.endswith('docx')), StrA.endswith('docx'), StrB.endswith('docx'))
# <class 'bool'> True False
# 补充
# in:判断一个字符串是否被另一个字符串所包含
print('ou' in 'Do what you love')
# True
# not in:判断字符串是否不被另一个字符串所包含
print('ou' not in 'Do what you love')
# False
列表(list)
概念、定义
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
# 列表
# 概念:有序可变的集合
# 定义:
# 方式一:list = [元素1, 元素2, 元素3,·······]
# 方式二:列表生成式:range()函数
# 语法:range(start, end, step)
# 参数:start:起始数值,默认为0,end:结束数值,step:步长,默认为1
# 注意:python2.x中会立即生成列表,而python3.x只有用到列表中的数值时才会生成
# 方式三:列表推导式:从一个list推导出另一个list
# 语法:
# 映射解析:[表达式 for 变量 in list]
# 过滤:
# [表达式 for 变量 in list if 条件]
# [表达式 for 变量 in list for 变量 in list]
# 注意:
# 列表嵌套:列表中的元素还可以是列表
# 与c语言中的列表的区别:int nums[] = [1,2,3,4],c语言已经定义好列表中的数据的类型,不能插入其他类型的数据
import math
List1 = range(10)
List2 = [pow(num, 2) for num in List1]
List3 = [math.sqrt(num) for num in List2 if num % 3 == 0]
List4 = [num for num1 in List3 for num in List2]
print(type(List1), type(List2), type(List3), type(List4))
print('列表一是:{},列表二是:{},列表三是:{},列表四是:{}'.format(List1, List2, List3, List4))
# <class 'range'> <class 'list'> <class 'list'> <class 'list'>
# 列表一是:range(0, 10),列表二是:[0, 1, 4, 9, 16, 25, 36, 49, 64, 81],列表三是:[0.0, 3.0, 6.0, 9.0],列表四是:[0, 1, 4, 9, 16, 25, 36, 49, 64, 81, 0, 1, 4, 9, 16, 25, 36, 49, 64, 81, 0, 1, 4, 9, 16, 25, 36, 49, 64, 81, 0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
列表的操作
增
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
# 增
# append()
# 作用:在原列表末尾追加一个新的元素
# 语法:list.append(object)
# 参数:object:需要追加的新的元素
# 返回值:None
# 注意:会修改原列表
List = [1, 2, 3, 'a', 'b']
print(List.append('c'))
print(List)
# None
# [1, 2, 3, 'a', 'b', 'c']
# insert()
# 作用:在指定位置追加一个新的元素
# 语法:list.insert(index, object)
# 参数:index:新元素追加的位置,object:需要追加的新元素
# 返回值:None
# 注意:会修改原列表
print(List.insert(6, 'd'))
print(List)
# None
# [1, 2, 3, 'a', 'b', 'c', 'd']
# extend()
# 作用:往列表里面扩展另一个可迭代序列
# 语法:list.extend(iterable)
# 参数:iterable:可迭代序列
# 返回值:None
# 注意:
# 会直接修改原列表
# 会将可迭代序列的元素分别加入原列表中
# 和append()的区别:append()是将object作为一个整体(元素)加入list中,而extend()可以看作为两个列表的相加
List1 = 'efghijk'
print(List.extend(List1))
print(List)
# None
# [1, 2, 3, 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k']
# 乘法运算
# 语法:list * n
print(List * 2)
# [1, 2, 3, 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 1, 2, 3, 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k']
# 加法运算
# 语法:list1 + list2
# 与extend()的区别:只能进行列表之间的相加
print(List + [4, 5, 6])
# [1, 2, 3, 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 4, 5, 6]
删
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
# 删
# del语句
# 作用:删除指定元素
# 语法:del list[指定元素索引]
# 参数:无
# 返回值:无
# 注意:可以删除一个列表,也可以删除一个元素,也可以删除一个变量
List0 = [1, 2, 3, 4, 5, 4, 3, 2, 1]
del List0[2]
print(List0)
# [1, 2, 4, 5, 4, 3, 2, 1]
del List0
print(List0)
# NameError: name 'List0' is not defined
# pop()
# 作用:返回并删除指定元素
# 语法:list.pop(index = -1)
# 参数:index:指定元素的索引,默认为-1
# 返回值:指定元素
# 注意:会直接修改原列表
List1 = [1, 2, 3, 4, 5, 4, 3, 2, 1]
result0 = List1.pop(2)
print(result0, List1)
# 3 [1, 2, 4, 5, 4, 3, 2, 1]
# remove()
# 作用:移除列表内的指定元素
# 语法:list.remove(object)
# 参数:object:想要移除的元素
# 返回值:None
# 注意:
# 会修改原列表
# 如果元素不存在会报错
# 如果存在多个相同的指定元素:只会删除最左边的
# 使用循环内删除列表相同的元素的元素可能会出错(一般要指定得元素三个及以上相连)
List2 = [1, 2, 1, 3, 4, 4, 3, 2, 1]
result1 = List2.remove(1)
print(result1, List2)
# None [2, 1, 3, 4, 4, 3, 2, 1]
List3 = [1, 2, 1, 1, 1, 4, 4, 3, 2, 1]
for num in List3:
print('现在遍历的元素是:{},列表List3是:{}'.format(num, List3))
if num == 1:
List3.remove(num)
print("删除后得列表List3是{}".format(List3))
print("列表List3最终是:{}".format(List3))
# 现在遍历的元素是:1,列表List3是:[1, 2, 1, 1, 1, 4, 4, 3, 2, 1]
# 删除后得列表List3是[2, 1, 1, 1, 4, 4, 3, 2, 1]
# 现在遍历的元素是:1,列表List3是:[2, 1, 1, 1, 4, 4, 3, 2, 1]
# 删除后得列表List3是[2, 1, 1, 4, 4, 3, 2, 1]
# 现在遍历的元素是:1,列表List3是:[2, 1, 1, 4, 4, 3, 2, 1]
# 删除后得列表List3是[2, 1, 4, 4, 3, 2, 1]
# 现在遍历的元素是:4,列表List3是:[2, 1, 4, 4, 3, 2, 1]
# 现在遍历的元素是:3,列表List3是:[2, 1, 4, 4, 3, 2, 1]
# 现在遍历的元素是:2,列表List3是:[2, 1, 4, 4, 3, 2, 1]
# 现在遍历的元素是:1,列表List3是:[2, 1, 4, 4, 3, 2, 1]
# 删除后得列表List3是[2, 4, 4, 3, 2, 1]
# 列表List3最终是:[2, 4, 4, 3, 2, 1]
改
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
# 改
# 语法:list[index] = 想要修改成得元素
# 参数:index:索引
# 返回值:无
# 注意:不能越界
num = [1, 2, 5, 4]
num[2] = 3
print(num)
# [1, 2, 3, 4]
查
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
# 查
# list[index]
# 作用:获取单个元素
# 语法:items[index]
# 参数:index:索引
# 返回值:先要获取的元素
# 注意:不能越界
List0 = range(9)
print(List0[2])
# 2
# index()
# 作用:获取单个元素的索引
# 语法:items.index[value, start, end]
# 参数:value:想要获取索引的元素,start:检索的起始,默认为0,end:检索结束的位置,默认为len(list)
# 返回值:元素的索引,int类型
# 注意:
# 检索的范围:[0, len(list)]
# 检索从左至右,多个相同的元素时只返回最左侧得元素的索引
List1 = ['a', 'b', 'c', 'd', 'e', 'f', 'a']
print(type(List1.index('a')), List1.index('a'))
# <class 'int'> 0
# count()
# 作用:获取指定元素得个数
# 语法:list.count(value)
# 参数:value:想要获取个数的元素
# 返回值:指定元素的个数,int类型
# 注意:
List2 = [1, 2, 3, 4, 5, 3, 2, 4, 3, 2, 1]
print(type(List2.count(3)), List2.count(3))
# <class 'int'> 3
# items[start:end:step]
# 作用:获取多个元素
# 语法:items[start:end:step]
# 参数:start:检索起始的位置,end:检索结束的位置,step:截取的步长
# 返回值:截取后的列表,list类型
# 注意:截取范围[start, end)
List3 = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
print(type(List3[1:6:2]), List3[1:6:2])
# <class 'list'> [1, 3, 5]
查——遍历
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
# 遍历
# 方法一:根据元素进行遍历
# for item in list:
# print(item)
List = [1, 2, 3, 4, 5, 1]
length = 0
for i in List:
print('元素:{} 的索引是:{}'.format(i, List.index(i, length)))
length += 1
# 元素:1 的索引是:0
# 元素:2 的索引是:1
# 元素:3 的索引是:2
# 元素:4 的索引是:3
# 元素:5 的索引是:4
# 元素:1 的索引是:5
# 方法二:根据索引遍历
# for index in range(len(list)):
# print(list[index], index)
for index in range(len(List)):
print('元素:{} 的索引是:{}'.format(List[index], index))
# 元素:1 的索引是:0
# 元素:2 的索引是:1
# 元素:3 的索引是:2
# 元素:4 的索引是:3
# 元素:5 的索引是:4
# 元素:1 的索引是:5
# 创建对应的枚举对象
# 概念:通过枚举函数生成一个新的对象
# 作用:用于将一个可遍历的数据对象(如列表、元组、字符串)组合成一个索引序列(同时出现下标和数据)
# 语法:enumerate(sequence, [start=0])
# 参数:sequence:一个序列、迭代器或者其他支持迭代对象,start:下标起始得位置
List1 = enumerate(List)
for idx, val in List1:
print('元素:{} 的索引是:{}'.format(val, idx))
# 元素:1 的索引是:0
# 元素:2 的索引是:1
# 元素:3 的索引是:2
# 元素:4 的索引是:3
# 元素:5 的索引是:4
# 元素:1 的索引是:5
# 使用迭代器进行遍历
# 语法:
# list = iter(list)
# for item in list:
# pass
# 访问集合的方式:迭代器
# 概念:
# 迭代:访问集合元素的一种方式,按照某种顺序逐个访问集合中的每一项
# 可迭代对象:
# 能够被迭代的对象
# 判定依据:能够用于for循环
# 判定方法:
# import collections
# isinstance(object, collections.Iterable)
# 迭代器:
# 可以记录遍历位置的对象
# 从第一个元素开始,通过next()函数向后进行遍历
# 只能往后,不能往前
# 判定依据:能够作用于next()函数
# 判定方法:
# import collections
# isinstance(object, collections.Iterator)
# 注意:迭代器也是可迭代对象,可以用于for循环
# 为什么会产生迭代器:
# 仅仅迭代到某个元素是才处理某个元素。在此之前,该元素可以不存在;在这之后,该元素可以被销毁;适合于遍历一些巨大或者无限的集合
# 提供一个统一访问集合的接口:
# 可以把所有迭代对象转化为迭代器进行使用
# iter(iterable)
# 迭代器的简单使用:
# 使用next()函数:从迭代器中取出下一个对象,从第一个元素开始
# 因为迭代器比较常用,在python中,可以直接作用于for循环(内部会自动调用迭代器对象的next(),会自动处理迭代完毕的错误)
# 注意事项:
# 如果取出完毕再继续取,则会报错StopIteration
# 迭代器一般不能多次迭代
# DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated since Python 3.3, and in 3.9 it will stop working
# print(isinstance(Str, collections.Iterable))
List = [1, 3, 4, 6, 2]
List1 = iter(List)
for i in List1:
print(i, end=' ')
# 1 3 4 6 2
List1 = iter(List)
for a in range(5):
print(next(List1))
# 1 3 4 6 2
print(next(List1))
# StopIteration
额外操作
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
# 额外操作
# 判定:
# 元素 in 列表
# 元素 not in 列表
List = [1, 2, 3, 4]
print(1 in List)
print(10 not in List)
# True
# True
# 比较:
# python2.x使用cmp()函数
# python3.x中使用'<','==','>'
# 针对每一个元素,从左至右比较
List0 = [1, 2, 3, 4]
List1 = [1, 2, 3]
print(List0 == List1, List0 < List1, List0 > List1)
# False False True
# 排序
# 方式一:使用内建函数sorted()
# 作用:对所有可迭代对象进行排序
# 语法:sorted(iterable, key=None, reverse=False)
# 参数:iterable:可迭代对象,key:排序的关键字,值为一个函数,此函数只有一个参数且返回一个值进行比较,reverse:控制升序降序,默认为False(升序)
# 返回值:一个排好序的列表,list类型
List = [('xs1', 180), ('xs2', 170), ('xs3', 178), ('xs4', 150), ('xs5', 198)]
def getKey(X):
return (X[1])
result = sorted(List, key=getKey, reverse=True)
print(type(result), result)
# <class 'list'> [('xs5', 198), ('xs1', 180), ('xs3', 178), ('xs2', 170), ('xs4', 150)]
# 方式二:列表对象方法
# 语法:list.sort(key, reverse)
# 参数:key:排序的关键字;reverse:控制升序降序,默认为False(升序)
# 返回值:None
# 注意:会直接修改原列表
result = List.sort(key=getKey, reverse=True)
print(result, List)
# None [('xs5', 198), ('xs1', 180), ('xs3', 178), ('xs2', 170), ('xs4', 150)]
# 乱序
# random模块
# 语法:
# import random
# random.shuffle(list)
# 参数:list:想要乱序的列表
# 返回值:None
# 注意:会直接修改原列表
import random
List = [1, 2, 3, 4, 5, 6]
result = random.shuffle(List)
print(result, List)
# None [2, 1, 4, 5, 6, 3]
# 反转
# 语法:list.reverse()
# 返回值:None
# 注意:会直接修改原列表
result = List.reverse()
print(result, List)
# None [3, 6, 5, 4, 1, 2]
# 切片反转
# 语法:list[::-1]
# 返回值:反转后的列表
# 注意:与list.reverse的区别:切片反转不会修改原列表
result = List[::-1]
print(result, List)
# [2, 1, 4, 5, 6, 3] [3, 6, 5, 4, 1, 2]
元组(tuple)
概念和定义
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
# 概念:有序的不可变的元素集合(与列表相比最大的区别是元组不可修改)
# 定义:
# 一个元素的写法:(x,)
print(type(('k',)))
# <class 'tuple'>
# 多个元素的写法:(x, y, z)
print(type((1, 2, 3)))
# <class 'tuple'>
# 多个对象,使用逗号隔开,默认为元组
Tuple = 22, 33, 'zse'
print(type(Tuple))
# <class 'tuple'>
# 从列表转化为元组:tuple(seq)函数
List = [1, 2, 'a', 'e']
Tuple = tuple(List)
print(type(Tuple), Tuple)
# <class 'tuple'> (1, 2, 'a', 'e')
常用操作
查
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
# 常用操作
# 查
# 查询单个元素
# 语法:tuple[index]
# 参数:index:索引
Tuple = ('a', 'b', 'c', 'd', 'e')
print(Tuple[2])
# c
# 切片
# 语法:tuple[start:end:step]
# 参数:start:索引起始的位置,end:索引结束的位置,step:步长
print(Tuple[3:0:-1])
# ('d', 'c', 'b')
# 获取
# 对象方法
# count()
# 作用:统计元组中指定元素的个数
# 语法:tuple.count(item)
# 参数:item想要查询的元素
# 返回值:元素的个数,int类型
Tuple = ('a', 'c', 'f', 'g', 'f', 'g', 'a', 'f')
print(type(Tuple.count('F')), Tuple.count('f'))
# <class 'int'> 3
# index()
# 作用:获取指定元素的索引
# 语法:index(item)
# 参数:想要查询的元素
# 返回值:
# 找到了:元素的索引,int类型
# 没找到:报错
print(type(Tuple.index('a')), Tuple.index('a'))
print(Tuple.index(1))
# <class 'int'> 0
# ValueError: tuple.index(x): x not in tuple
# 函数
# len()
# 作用:返回指定元组的长度
# 语法:len(tuple)
# 参数:tuple:想要获取长度的元组
# 返回值:指定元组的长度,int类型
print(type(len(Tuple)), len(Tuple))
# <class 'int'> 8
# max()
# 作用:获取元组中的最大元素的值
# 语法:max(tuple)
# 参数:tuple:元组
# 返回值:最大的元素
print(max(Tuple))
# g
# min()
# 作用:获取元组中最小元素的值
# 语法:min(tuple)
# 参数:tuple:元组
# 返回值:最小的元素
print(min(Tuple))
# a
# 判定
# 语法:
# 元素 in 元组
# 元素 not in 元组
print('a' in Tuple, 1 not in Tuple)
# True True
# 比较
# python2.x中使用cmp(x, y)函数
# python3.x中使用'<','==','>'
# 注意:
# 如果比较对象都是元组,则按照从左至右依次比较
# 如果比较对象不相同,则会报错
print((1, 2) < (2, 3))
# True
print([1, 2] < (1, 2))
# TypeError: '<' not supported between instances of 'list' and 'tuple'*
# 拼接
# 乘法:
# 语法:(元素1, 元素2, 元素3,,,) * n
# 返回值:(元素1, 元素2, 元素3,,,元素1, 元素2, 元素3,,,元素1, 元素2, 元素3,,,,,,)
print((1, 3, 4) * 2)
# (1, 3, 4, 1, 3, 4)
# 加法:
# 语法:(元素1, 元素2) + (元素3, 元素4)
# 返回值:(元素1, 元素2, 元素3, 元素4)
print((1, 2, 3) + (5, 4))
# (1, 2, 3, 5, 4)
# 拆包
# 语法:a, b = tuple()
Tuple = (1, 3)
a, b = Tuple
print(a, b)
# 1 3
字典(dict)
概念及定义
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
# 概念:无序的、可变的键值对集合
# 定义:
# 方法一:{key1: value, key2: value···}
Dict = {'name': 'L', "age": '18', 'gender': 'male'}
print(type(Dict), Dict['name'])
# <class 'dict'> L
# 方法二:静态方法:类和对象都可以调用,fromkeys(S, v = None)
# 类调用:dict.fromkeys(seq, values) 此处的dict指的是字典类型
Seq0 = ['name', 'age', 'gender']
Seq1 = ['L', '18', 'male']
for Seq in Seq1:
Dict = dict.fromkeys(Seq0, Seq)
print(type(Dict), Dict)
# <class 'dict'> {'name': 'male', 'age': 'male', 'gender': 'male'}
# 对象调用:dict.fromkeys(seq, values) 此处的dict指的是实例化的字典
Seq0 = ['name', 'age', 'gender']
Seq1 = ['L', '18', 'male']
for Seq in Seq1:
Dict = {'weather': 'sun', 'date': '2-27'}.fromkeys(Seq0, Seq)
print(type(Dict), Dict)
# <class 'dict'> {'name': 'male', 'age': 'male', 'gender': 'male'}
# 注意:
# key不能重复,如果重复,后面的value会覆盖前面的value
Dict = {'a': 1, 'b': 2, 'c': 3, 'a': 12}
print(Dict)
# {'a': 12, 'b': 2, 'c': 3}
# key必须是任意不可变(主要有数值、布尔、字符串、元组等)的类型(即数值改变,id也会发生改变)
Dict = {[1, 2]: 1}
print(Dict)
# TypeError: unhashable type: 'list'
# 验证
List = [1, 2]
ID0 = id(List)
List.append(3)
ID1 = id(List)
print(ID0 == ID1)
Str = 'a'
ID2 = id(Str)
Str += 'b'
ID3 = id(Str)
print(ID2 == ID3)
# True False
# 产生上述要求的原因
# 1.python的字典采用哈希(hash)的方式实现的
# 2.简单的储存过程:
# 1.初始化一个表格,用来储存所有值:这个表格被称为哈希表,暂理解为列表
# 2.在储存键值对时,进行如下操作:
# 1.根据给定的key,通过“哈希函数”转化成一个整型数字(哈希值),
# 将该数字对数组长度进行取余,取余的结果就当作数组的下标,
# 2.如果产生“哈希冲突”,例如两个不同的key计算出来的索引是同一
# 个,则会采用“开发寻址法”(通过探测函数寻找下一个空位
# 3.根据索引位置储存给定的“值”
# 简单的查找过程:再次使用哈希函数将key转化成对应的索引,并定位到所在位置获取value
# 存在意义:
# 1.可以通过key,访问对应的值,使得查找更有意义
# 2.查询效率有了很大的提升
常用操作
增
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
# 常用操作
# 增
# dict[key] = value
# 当key不存在时,即为增的操作
Dict = {'name': 'Jack', 'age': '19'}
Dict['weight'] = '63'
print(Dict)
# {'name': 'Jack', 'age': '19', 'weight': '63'}
删
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
# 删
# del语句
# 作用:删除指定的键值对
# 语法:del dict[key]
# 参数:key:想要删除的键值对的键
# 返回值:无
# 注意:key必须存在,否则会报错,如果不填key会直接删除整个字典
Dict0 = {'name': 'Jack', 'age': '19', 'weight': '63'}
del Dict0['weight']
print(Dict0)
# {'name': 'Jack', 'age': '19'}
del Dict0
print(Dict0)
# NameError: name 'Dict0' is not defined
# pop()
# 作用:删除指定键值对,并返回对应的值
# 语法dict.pop(key[, default])
# 参数:key:想要删除的键值对的键,default:key不存在时返回的值
# 返回值:所删除键值对对应的值或者default
# 注意:key不存在时返回给定的default,并且不做删除操作;如果default为给定,则报错
Dict1 = {'name': 'Jack', 'age': '19', 'weight': '63'}
res0 = Dict1.pop('weight')
res1 = Dict1.pop('weight', 'None')
print(res0, res1, Dict1)
# 63 None {'name': 'Jack', 'age': '19'}
# popitem()
# 作用:删除key按升序排列后的第一个键值对,并以元组的形式返回键值对
# 语法:dict.popitem()
# 参数:无
# 返回值:删除的键值对的元组类型的值
# 注意:字典为空时会报错
Dict2 = {'name': 'Jack', 'age': '19', 'weight': '63'}
Dict3 = {}
res = Dict2.popitem()
print(type(res), res)
# <class 'tuple'> ('weight', '63')
Dict3.popitem()
# KeyError: 'popitem(): dictionary is empty'
# clear()
# 作用:清空字典内的键值对
# 语法:dict.clear()
# 参数:无
# 返回值:None
# 注意:与del dict的区别,clear()只是清空字典内的键值对,但字典本身还存在
Dict4 = {'name': 'Jack', 'age': '19', 'weight': '63'}
res = Dict4.clear()
print(res, Dict4)
# None {}
改(只能改值,不能改键)
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
# 改(只能改值,不能改键)
# dict[key] = newValue
# 作用:修改单个键值对
# 参数:key:想要修改的键值对的键;newValue:想要修改成的值
# 返回值:无
Dict0 = {'name': 'Jack', 'age': '19', 'weight': '63'}
Dict0['weight'] = '64'
print(Dict0)
# {'name': 'Jack', 'age': '19', 'weight': '64'}
# update()
# 作用:修改多个键值对
# 语法:oldDict.update(newDict)
# 参数:newDict:想要修改的键值对组成的集合
# 返回值:None
# 注意:newDict中的键值对在oldDict中不存在时会新建
Dict1 = {'name': 'Jack', 'age': '19', 'weight': '63'}
Dict2 = {'age': 20, 'mail': '111111111@qq.com'}
res = Dict1.update(Dict2)
print(res, Dict1)
# None {'name': 'Jack', 'age': 20, 'weight': '63', 'mail': '111111111@qq.com'}
查
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
# 查
# 获取单个值
# dict[key]
# 返回值:指定键值对的值
# 注意;如果key不存在则会报错
Dict0 = {'name': 'Jack', 'age': '19', 'weight': '63'}
print(Dict0['age'])
# 19
print(Dict0['age1'])
# KeyError: 'age1'
# get()
# 语法:dict.get(key[, default])
# 参数:key:想要获取的键值对对应的键;default:未找到key时返回的值,默认为None
# 返回值:想要查询的键值对的值或者default
Dict1 = {'name': 'Jack', 'age': '19', 'weight': '63'}
print(Dict1.get('name'), Dict1.get("#"))
# Jack None
# setdefault()
# 语法:dict.setdefault(key[,default])
# 参数:key:想要获取的键值对对应的键;default:未找到key时返回的值以及新增键值对的值,默认为None
# 返回值:想要查询的键值对的值或者default
Dict2 = {'name': 'Jack', 'age': '19', 'weight': '63'}
Dict2.setdefault('address', '30N, 100E')
print(Dict2)
# {'name': 'Jack', 'age': '19', 'weight': '63', 'address': '30N, 100E'}
# 获取多个值
# 获取所有的值
# values()
# 语法:dict.values()
# 返回值:dict中的所有的值,dict_values类型
# 注意:返回值不能直接索引,必须转化为列表或者元组等类型
Dict = {'name': 'Jack', 'age': '19', 'weight': '63'}
res0 = Dict.values()
print(type(res0), res0)
# <class 'dict_values'> dict_values(['Jack', '19', '63'])
res = list(res0)
print(res[1])
# 19
# 获取所有的键
# keys()
# 语法:dict.keys()
# 返回值:dict中所有的键,dict_keys
# 注意:返回值不能直接索引,必须转化为列表或者元组等类型
res1 = Dict.keys()
print(type(res1), res1)
# <class 'dict_keys'> dict_keys(['name', 'age', 'weight'])
# 获取所有的键值对
# items()
# 语法:dict.items()
# 返回值:dict中所有的键值对,dict_items
# 注意:返回值不能直接索引,必须转化为列表或者元组等类型
res2 = Dict.items()
print(type(res2), res2)
# <class 'dict_items'> dict_items([('name', 'Jack'), ('age', '19'), ('weight', '63')])
# 注意:
# python2.x与python3.x之间关于获取键、值、item存在区别:
# python2.x直接是一个列表,可以通过索引获取其中的值
# python3.x中是Dictionary view objects
# 在python2.x中提供了viewkeys()、viewvalues()、viewitems()的作用等同于Dictionary view objects
# Dictionary view objects:当字典发生变化时dict_keys,dict_values,dict_items的值也会发生变化,不会像python2.x中不会发生变化
print(res0, res1, res2)
# dict_values(['Jack', '19', '63']) dict_keys(['name', 'age', 'weight']) dict_items([('name', 'Jack'), ('age', '19'), ('weight', '63')])
Dict['address'] = '30N, 100E'
print(res0, res1, res2)
# dict_values(['Jack', '19', '63', '30N, 100E']) dict_keys(['name', 'age', 'weight', 'address']) dict_items([('name', 'Jack'), ('age', '19'), ('weight', '63'), ('address', '30N, 100E')])
# 遍历(Dictionary view object类型可遍历)
# 方法一:先遍历key,再通过key获得value
Dict = {'name': 'Jack', 'age': '19', 'weight': '63', 'address': '30N, 100E'}
Keys = Dict.keys()
for Key in Keys:
print('键:{} 所对应的值是:{}。'.format(Key, Dict[Key]))
# 键:name 所对应的值是:Jack。
# 键:age 所对应的值是:19。
# 键:weight 所对应的值是:63。
# 键:address 所对应的值是:30N, 100E。
# 方法二:遍历所有的键值对
keyValues = Dict.items()
for Key, Value in keyValues:
print('键:{} 对应的值是:{}。'.format(Key, Value))
# 键:name 所对应的值是:Jack。
# 键:age 所对应的值是:19。
# 键:weight 所对应的值是:63。
# 键:address 所对应的值是:30N, 100E。
计算
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
# 计算
# len()
# 语法:len(dict)
# 返回值:键值对的个数,int类型
Dict = {'name': 'Jack', 'age': '19', 'weight': '63', 'address': '30N, 100E'}
print(type(len(Dict)), len(Dict))
# <class 'int'> 4
# 判定
# 语法in、not in
# 返回值:布尔类型
# 注意:
# dict.has_key()已经不能使用
# 判定的是key是否在字典中
print('name' in Dict, 'name' not in Dict)
# True False
集合(set)
概念和定义
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
# 概念:
# 无序的、不可随机访问的、不可重复的元素集合
# 与数学中的集合的概念类似,可以进行交、并、差、补等逻辑运算
# 分为可变集合和不可变集合:
# set为可变集合,可以进行增、删、改
# frozenset为不可变集合,创建之后,无法修改
# 定义
# 可变集合
# 方式一:set = {}
Set0 = {1, 2, 3}
print(type(Set0), Set0)
# <class 'set'> {1, 2, 3}
# 方式二:set()
# 语法:set(iterable)
# 参数:iterable:可迭代对象
# 返回值:集合,set类型
# 注意:以字典生成集合,只返回由键构成的集合
Dict = {'name': 'Jack', 'age': '19', 'weight': '63', 'address': '30N, 100E'}
Set1 = set(Dict)
print(type(Set1), Set1)
# <class 'set'> {'address', 'age', 'weight', 'name'}
# 方式三:推导式
# 语法:set = set(表达式 for循环 if判断), set = {表达式 for循环 if判断语句}
# 返回值:集合,set类型
# 注意:for循环可设置多个
Set2 = set(Key1 * 2 for Key0 in Dict for Key1 in Dict if Key0 != 'name')
print(Set2)
# <class 'set'> {'namename', 'ageage', 'weightweight', 'addressaddress'}
# 不可变集合
# frozenset()
# 语法:frozenSet = frozenset(iterable)
# 注意:同可变集合的set()
frozenSet = frozenset({'name': 'Jack', 'age': '19', 'weight': '63', 'address': '30N, 100E'})
print(type(frozenSet), frozenSet)
# <class 'frozenset'> frozenset({'address', 'weight', 'name', 'age'})
# 推导式
# 语法:frozenSet = frozenset(表达式 for循环 if判断语句)
frozenSet = frozenset(hex(x) for x in range(100) if x % 9 == 0)
print(type(frozenSet), frozenSet)
# <class 'frozenset'> frozenset({'0x2d', '0x0', '0x63', '0x12', '0x3f', '0x5a', '0x9', '0x36', '0x48', '0x51', '0x1b', '0x24'})
# 注意:
# 1.创建一个空的集合时必须使用set()或者frozenset(),而不能使用set = {},否则会被识别为字典
Set0 = {}
Set1 = set()
print(type(Set0), type(Set1))
# <class 'dict'> <class 'set'>
# 2.集合中的元素必须是可哈希值,即一个对象在自己的生命周期中有一哈希值(hash value)是不可改变
# 的,那么他就是可哈希(hashable)的,可暂理解为不可改变类型
Set2 = {'111', 1, [1, 3], {'address': '30N, 100E'}}
# TypeError: unhashable type: 'list'
# 3.如果集合中的元素出现重复的,会合并为一个
Set3 = {1, 2, 3, 4, 2, 1, 3}
print(Set3)
# {1, 2, 3, 4}
常用操作
单一集合
1.可变集合
增
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
# 增
# add()
# 语法:set.add(element)
# 参数:element:元素
# 注意:会直接修改原集合;并且不能添加不可哈希值
Set0 = {1, 2, 3, 4, 5, 6}
Set0.add(7)
print(type(Set0), Set0)
# <class 'set'> {1, 2, 3, 4, 5, 6, 7}
删
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
# 删
# remove()
# 作用:删除指定元素
# 语法:set.remove(element)
# 返回值:None
# 注意:元素不存在时会报错:KeyError
Set1 = {1, 2, 3, 4, 5, 6, 7, 8, 9, 0}
res = Set1.remove(1)
print(res, Set1)
# None {0, 2, 3, 4, 5, 6, 7, 8, 9}
# discard()
# 作用:删除指定元素
# 语法:set.discard(element)
# 返回值:None
# 注意:元素不存在时不做任何事情
res =Set1.discard(10)
print(res, Set1)
# None {0, 2, 3, 4, 5, 6, 7, 8, 9}
# pop()
# 作用:随机删除并返回集合中的一个元素
# 语法:set.pop(element)
# 返回值:删除的元素
# 集合为空时会报错:KeyError
res = Set1.pop()
print(res, Set1)
# 0 {2, 3, 4, 5, 6, 7, 8, 9}
# clear()
# 作用:清空集合中的所有元素
# 语法:set.clear()
# 返回值:None
# 注意:删除一个集合需要使用del set
res = Set1.clear()
print(res, Set1)
# None set()
改
列表输入
查
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 查
# 遍历
Set0 = {1, 2, 3, 4, 5, 6, 7, 8, 9, 0}
for Set in Set0:
print(Set, end=' ')
# 0 1 2 3 4 5 6 7 8 9
# 使用迭代器
Iter = list(Set0)
Its = iter(Iter)
# 使用next()函数遍历
for i in Iter:
print(next(Its), end=' ')
# 使用for循环遍历
Its = iter(Iter)
for i in Its:
print(i, end=' ')
集合之间的操作
交集
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 集合之间的操作
# 交集
# intersection()
# 作用:求两个可迭代对象的交集
# 语法:iterable.intersection(iterable)
# 注意:
# 与字符串求交集时,只判定字符串中的非数字
# 与字典求交集时,判定key
# 可变集合和非可变集合求交集时,结果的类型是左侧集合的类型
# iterable内部也只能是可哈希值
Set0 = frozenset('sa1dfsedf')
Set1 = set('sdf1awefadf')
res = Set0.intersection(Set1)
print(type(res), res)
# <class 'frozenset'> frozenset({'e', 'a', 's', 'f', '1', 'd'})
print(Set0, Set1)
# frozenset({'e', 'a', 's', 'f', '1', 'd'}) {'w', 'e', 'a', 's', 'f', '1', 'd'}
# 逻辑运算符 &
# 语法:set & set
res = Set0 & Set1
print(type(res), res)
# <class 'frozenset'> frozenset({'e', 'a', 's', 'f', '1', 'd'})
print(Set0, Set1)
# frozenset({'e', 'a', 's', 'f', '1', 'd'}) {'w', 'e', 'a', 's', 'f', '1', 'd'}
# intersection_update()
# 作用:计算交集,并将值返回给原对象
# 语法:set.intersection_update(set)
# 注意:会修改原对象,只能作用与可变集合,即左侧集合不能为frozenset类型,否则会报错
Set1.intersection_update(Set0)
print(Set1)
# {'e', 'a', 's', 'f', '1', 'd'}
并集
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 并集
# union()
# 语法:set.union(set)
# 作用:返回并集
# 返回值:两个集合的并集
# 注意:返回值的类型与左侧的类型一致
Set0 = {1, 2, 3, 4, 5}
Set1 = frozenset([9, 10, 187, 17, 15])
res = Set1.union(Set0)
print(type(res), res)
# <class 'frozenset'> frozenset({1, 2, 3, 4, 5, 9, 10, 15, 17, 187})
print(Set0, Set1)
# {1, 2, 3, 4, 5} frozenset({9, 10, 15, 17, 187})
# 逻辑运算符 |
# 作用:同union()
# 语法:set | set
# 返回值:同union()
# 注意:同union()
res = Set0 | Set1
print(type(res), res)
# <class 'set'> {1, 2, 3, 4, 5, 9, 10, 15, 17, 187}
print(Set0, Set1)
# {1, 2, 3, 4, 5} frozenset({9, 10, 15, 17, 187})
# update
# 作用:计算两个集合的交集并返回给原对象
# 语法:set.update(set)
# 返回值:None
# 注意:会直接修改原对象;左侧的集合不能是frozenset类型,否则会报错
res = Set0.update(Set1)
print(type(res), res)
# <class 'NoneType'> None
print(Set0, Set1)
# {1, 2, 3, 4, 5, 9, 10, 15, 17, 187} frozenset({9, 10, 15, 17, 187})
差集
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 差集
# difference()
# 作用:求两个集合的差集
# 语法:set.difference(set)
# 返回值:左边的集合相对于右边的集合的差集
# 注意:返回结果的类型与左侧的集合保持一致
Set0 = frozenset('asdfg')
Set1 = set('sdahg')
res = Set0.difference(Set1)
print(type(res), res)
# <class 'frozenset'> frozenset({'f'})
print(Set0, Set1)
# frozenset({'s', 'f', 'a', 'd', 'g'}) {'s', 'h', 'a', 'd', 'g'}
# 逻辑运算符 -
# 作用:同difference()
# 语法:set - set
# 返回值:同difference()
# 注意:同difference()
res = Set0 - Set1
print(type(res), res)
# <class 'frozenset'> frozenset({'f'})
print(Set0, Set1)
# frozenset({'s', 'f', 'a', 'd', 'g'}) {'s', 'h', 'a', 'd', 'g'}
# difference_update()
# 作用:计算两个集合的差集并返回给原对象
# 语法:set.difference_update(set)
# 返回值:None
# 注意:左侧的集合不能是frozenset类型,否则会报错;会直接修改原对象
res = Set1.difference_update(Set0)
print(type(res), res)
# <class 'NoneType'> None
print(Set0, Set1)
# frozenset({'f', 'g', 'a', 's', 'd'}) {'h'}
判定
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 判定
# isdisjoint()
# 作用:判断两个集合是否不相交
# 语法:set.isdisjoint(set)
# 返回值:bool值
Set0 = {1, 2, 3, 4, 5}
Set1 = {1, 2, 3}
res = Set0.isdisjoint(Set1)
print(type(res), res)
# <class 'bool'> False
# issuperset()
# 作用:判断左侧的集合是否包含右侧的集合
# 语法:set.issuperset(set)
# 返回值:bool值
res = Set0.issuperset(Set1)
print(type(res), res)
# <class 'bool'> True
# issubset()
# 作用:判断左侧的集合是否包含于右侧的集合
# 语法:set.issubset(set)
# 返回值:bool类型
res = Set0.issubset(Set1)
print(type(res), res)
# <class 'bool'> False
时间日历
time模块
获取当前时间戳
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# time模块:提供处理时间和表示之间转换的功能
# 获取当前的时间戳
# 概念:从0时区的1970年1月1日0时0分(北京时间:1月1日08:00),到所给定日期的时间秒数,float类型
# 语法:
# import time
# time.time()
# 参数:无
# 返回值:当前时间到1979年1月1日0时0分(0时区)的秒数差
# 注意:此时北京时间为1月1日08:00
import time
res = time.time()
print(type(res), res)
# <class 'float'> 1583140537.2669754
获取时间元组
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 获取时间元组
# 概念:python时间函数将时间处理为9个数字元组
# 语法:localtime([seconds])
# 返回值:time.struct_time
# 注意:seconds可选时间戳,赋值后按所赋的值进行运算,默认为当前时间戳
# 返回值的符号含义
# 序号 含义 属性 值
# 0 4位数年 Tm_year 1970-
# 1 月 tm_mon 1-12
# 2 日 tm_mday 1-31
# 3 小时 tm_hour 0-23
# 4 分钟 tm_min 0-59
# 5 秒钟 tm_sec 0-61(60和61是闰秒)
# 6 一周的第几日 tm_wday 0-6(0是周日)
# 7 一年的第几日 tm_yday 1-366
# 8 夏令时 tm_isdst -1,0,1,-1决定是否为夏令时的标记
import time
res = time.localtime()
print(type(res), res)
# <class 'time.struct_time'> time.struct_time(tm_year=2020, tm_mon=3, tm_mday=2, tm_hour=17, tm_min=15, tm_sec=37, tm_wday=0, tm_yday=62, tm_isdst=0)
res = time.localtime(15840285.37283)
print(res)
# time.struct_time(tm_year=1970, tm_mon=7, tm_mday=3, tm_hour=16, tm_min=4, tm_sec=45, tm_wday=4, tm_yday=184, tm_isdst=0)
获取格式化的时间字符串
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 获取格式化时间
# 秒转化为格式化的时间
# ctime()
# 语法:time.ctime([seconds])
# 参数:seconds:如果传递了具体的值,则将seconds转化为格式化的时间,默认为当前时间戳
# 返回值:格式化的时间,str类型
import time
res = time.ctime()
print(type(res), res)
# <class 'str'> Mon Mar 2 17:30:18 2020
# 将时间元组(time.struct_time)转化为格式化的时间
# asctime()
# 语法:time.asctime(p_tuple)
# 参数:作用同ctime()中的seconds
# 返回值:格式化的时间,str类型
res = time.asctime()
print(type(res), res)
# <class 'str'> Mon Mar 2 17:30:18 2020
格式化日期字符串 <—> 时间戳
时间元组–>格式化日期
# 时间元组-->格式化日期
# 语法:time.strftime(格式字符串,时间元组(默认为当前时间的时间元组))
# 返回值:格式化的时间,str类型
# 格式字符串符号
# 符号 含义
# %y 两位数的年份表示(0-99)
# %Y 四位数的年份表示(1000-9999)
# %m 月份(01-12)
# %d 月中的一天(01-31)
# %H 24小时制小时数(0-23)
# %I 12小时制小时数(01-12)
# %M 分钟数(00-59)
# %S 秒数(00-59)
# %z 与UCT时区的偏移量
# %a 本地简化星期名称
# %A 本地完整星期名称
# %B 本地完整月份名称
# %b 本地缩写月份名称
# %c 本地适当的日期和时间表示
# %p AM或者PM表示
import time
res = time.strftime('%y-%m-%d %I:%M:%S %p')
print(type(res), res)
# <class 'str'> 20-03-02 06:18:09 PM
格式化日期转化为时间元组
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 格式化日期转化为时间元组
# 语法:time.strptime(格式化的时间字符串, 格式字符串)
import time
Time0 = '20-03-02 06:18:09 PM'
Time_struct = '%y-%m-%d %I:%M:%S %p'
Time1 = time.strptime(Time0, Time_struct)
print(Time1)
# time.struct_time(tm_year=2020, tm_mon=3, tm_mday=2, tm_hour=18, tm_min=18, tm_sec=9, tm_wday=0, tm_yday=62, tm_isdst=-1)
将时间元组转化为时间戳
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 将时间元组转化为时间戳
# 语法:time.mktime(时间元组)
import time
Time_struct = time.localtime()
res = time.mktime(Time_struct)
print(res)
# 1583145145.0
休眠
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 休眠
# 语法:time.sleep(seconds)
# 参数:seconds:休眠的秒数
import time
start = time.time()
for i in range(100):
print(i, end='\r')
time.sleep(0.1)
end = time.time()
print('耗时{},打印结束'.format(end - start))
# 耗时10.055064678192139,打印结束
calendar模块
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# calendar模块
# 作用:提供与日历相关的功能;给特定的月份或者年份打印文本日历
# 语法:
# import calendar
# calendar.month(year, month)
# 参数:year:想要打印的日历的年,month:想要打印的日历的月
import calendar
print(calendar.month(2020,4))
# April 2020
# Mo Tu We Th Fr Sa Su
# 1 2 3 4 5
# 6 7 8 9 10 11 12
# 13 14 15 16 17 18 19
# 20 21 22 23 24 25 26
# 27 28 29 30
datetime模块
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# datetime模块
# python处理日期和时间的标准库,该模块内有datetime类、date类、time类
# 获取当天的日期,以及单独获取年、月、日、秒
# 语法:
# import datetime
# datetime.datetime.now()或者datetime.datetime.today()
# 返回值是datetime.datetime类
# 取出单个值:
# Time = datetime.datetime.today()
# Year = Time.year
# Month = Time.month
# Day = Time.day
# Hour = Time.hour
# Minute = Time.minute
# Second = Time.second
from datetime import datetime
Time0 = datetime.today()
Time1 = datetime.now()
print(type(Time0), Time0, Time1)
# <class 'datetime.datetime'> 2020-03-02 20:50:54.046957 2020-03-02 20:50:54.046957
print("Time0的年是{}".format(Time0.year))
print("Time0的月是{}".format(Time0.month))
print("Time0的日是{}".format(Time0.day))
print("Time0的时是{}".format(Time0.hour))
print("Time0的分是{}".format(Time0.minute))
print("Time0的秒是{}".format(Time0.second))
# Time0的年是2020
# Time0的月是3
# Time0的日是2
# Time0的时是20
# Time0的分是50
# Time0的秒是54
# 计算时间
# import datetime
# Delta = dateTime +/- datetime.timedelta(year=, month=, day=, hour=, minute=, second=)
# 生成datetime.datetime类
# Time = datetime.datetime(year, month, day, hour, minute, hour)
import datetime
Time = datetime.datetime.now()
print(Time, Time - datetime.timedelta(days=10, seconds=15))
# 2020-03-02 21:11:59.671481 2020-02-21 21:11:44.671481
Time0 = datetime.datetime(2020, 1, 23, 22, 30, 00)
print(type(Time0))
print(Time - Time0)
# <class 'datetime.datetime'>
# 38 days, 22:41:59.671481
函数
概念和定义
概念
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 概念
# 写一段代码实现某个功能,然后把这些代码集中到一块,起一个名字;下次就能根据这个名字使用这段代码
# 作用:
# 1.方便代码复用
# 2.分解任务,简化程序逻辑
# 3.使程序更加模块化
# 分类:内建函数、第三方函数、自定义函数
定义
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 函数的基本使用
# 简单定义:
# def 函数名():
# 代码块
# 调用:函数名()
# 注意:函数名的命名规则同变量命名规则
def Function():
for i in range(5):
print('i的值是', i)
print('i的i次方是', pow(i, i))
Function()
# i的值是 0
# i的i次方是 1
# i的值是 1
# i的i次方是 1
# i的值是 2
# i的i次方是 4
# i的值是 3
# i的i次方是 27
# i的值是 4
# i的i次方是 256
# 我记得0的0次幂没有意义,但是不知道为什么python的pow()函数算出来等于1,我用电脑自带的计算
# 机算了下也是等于0,网上查了下,也有解释,但是文科生看不懂
函数的参数
单个参数
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 单个参数
# 使用场景:需要动态调整函数体中的某一个处理信息
# 定义:
# def 函数名(参数):
# 代码块
# 调用:函数名(参数值)
# 形参与实参的概念:
# 定义中函数名中的参数为形参,即形式上的参数
# 调用中传递的参数值的具体数值是实参,即实际参数
def Function(x):
for i in range(5):
print('i的值是', i)
print('x的i次方是', pow(x, i))
Function(3)
# i的值是 0
# x的i次方是 1
# i的值是 1
# x的i次方是 3
# i的值是 2
# x的i次方是 9
# i的值是 3
# x的i次方是 27
# i的值是 4
# x的i次方是 81
多个参数
# 多个参数
# 使用场景:想要动态调整函数中的多个处理信息,以英文逗号做分割,接受多个参数
# 定义:
# def 函数名(参数1, 参数2,··· ):
# 代码块
# 调用:
# 方法一:
# 一一对应:函数名(参数值1, 参数值2,··· )
# 方法二:
# 关键字参数:函数名(参数=参数值, 参数=参数值,··· )
import math
def Function(num1, num2):
print(math.log(num2, num1))
Function(num2=100, num1=10)
# 2.0
不定长参数
# 不定长参数
# 使用场景:如果函数体中,需要处理参数,不确定长度,则可以以不定长参数方式接收参数
# 语法:
# 方式一:
# def 函数名(*args)
# 代码块 在代码块中会直接以元组的方式使用传递的参数
# 调用:函数名(参数1, 参数2, ···)
# 注意:args:为元组
def Function(*nums):
res = 0
for i in nums:
res += i
print(type(nums), res)
Function(10, 23, 44, 534)
# <class 'tuple'> 611
# 方式二:
# def 函数名(**dict):
# 代码块 在代码块中会直接以字典的方式使用传递的参数
# 调用:函数名(参数1=参数值1, 参数2=参数值2, 参数3=参数值3, ···)
def function(**inf):
print(type(inf), inf)
function(Name='Jack', age=17, address='30N, 100E')
# <class 'dict'> {'Name': 'Jack', 'age': 17, 'address': '30N, 100E'}
# 装包和拆包
# 装包
# 语法:def 函数名(*args): / def 函数名(**kwargs):
# 拆包
# 语法:*args / **kwargs
def function0(a, b, c): # 此处将接收到的1, 2, 3分别传递给a, b, c,并将值传入print()函数
print(pow(a + b, c)) # 此处将接收到的a, b, c的值带入公式计算
def function1(*args): # 此处将function1(1, 2, 3)传递来的1, 2, 3打包成元组(1, 2, 3)并传递给function0
function0(*args) # 此处将调用函数function0并将元组(1, 2, 3)拆包成1, 2, 3传入function0(arg)
function1(1, 2, 3) # 此处将1, 2, 3传递给function(*args)
# 27
def function2(name, age, address): # 此处将接收到的字典拆包并分别赋值给name、age、address三个参数并传递给print()函数
print(name, age, address) # 此处将接收到的三个参数值打印出来
def function3(**kwargs): # 此处将接收到的name='Jack', age=17, address='30N, 100E'打包成字典并传给function2
function2(**kwargs) # 此处将接收到的字典传递给function2
function3(name='Jack', age=17, address='30N, 100E') # 此处将name='Jack', age=17, address='30N, 100E'传入function3(**kwargs)
# Jack 17 30N, 100E
# 注意:在function1和function3调用函数时传递参数的参数名要与function0和function2中的参数名一致,否则会报错
# 缺省参数
# 使用场景:当我们使用一个函数的时候,大多数情况下使用的数据是一个固定值,或者主功能外的小功能实现的,则可以使用默认值,这种参数被称为‘缺省’
# 定义:
# def 函数名(参数1=默认值, 参数2=默认值, ···):
# 代码块 如果使用的时候没有传递参数则使用默认值运算
# 调用:函数名(参数值1, 参数值2, ···) 如果不填参数值就是缺省参数
def function(num0=9, num1=15):
print('衬衫的价格是{}磅{}便士'.format(num0, num1))
function()
# 衬衫的价格是9磅15便士
函数参数的注意事项
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 函数参数的注意事项
# python中参数之间使用的是引用传递(地址传递)
# 如果数据是可变类型,可以改变原件;如果数据是不可变类型,不能改变原件
# 值传递与地址传递:
# 值传递:传递过来的是一个数据的副本,修改副本不会对原件造成影响
# 地址传递:传递过来的是变量的地址,通过地址,可以操作同一变量
# 可变类型
def inf(x):
ID1 = id(x) # 获取传递完值后的x的地址
x.append(99)
ID2 = id(x) # 获取x的值改变后的x的地址
if ID0 == ID1: # 判断第一次赋值时x的地址是否和List的地址相同,即python是否是引用传递(地址传递)
print('python是引用传递(地址传递)')
if ID0 == ID2: # 判断x的值改变后的地址是否和List的地址相同,即可变类型是否会改变原件
print('可变类型会改变原件')
print(x)
List = [9, 15] # 设立一个可变类型
ID0 = id(List) # 获取List的内存地址
inf(List) # 调用inf()函数,并将List的地址传递到inf(x)中的x
print(List) # 查看List的值是否因为x的修改而改变
# python是引用传递(地址传递)
# 可变类型会改变原件
# [9, 15, 99]
# [9, 15, 99]
# 不可变类型
def information(y):
ID1 = id(y) # 获取第一次赋值时y的地址
y += ',所以你选择[B]项,并在试卷上将其标出。'
ID2 = id(y)
if ID0 == ID1: # 判断第一次赋值时x的地址是否和List的地址相同,即python是否是引用传递(地址传递)
print('python是引用传递(地址传递)')
if not ID0 == ID2: # 判断x的值改变后的地址是否和List的地址相同,即可变类型是否会改变原件
print('不可变类型不会改变原件')
print(y)
Str = '衬衫的价格是九磅十五便士' # 设立一个不可变类型
ID0 = id(Str) # 获取Str的地址
information(Str) # 调用information()函数,并将Str的地址传递到information(y)中的y
print(Str) # 查看Str的值是否发生改变
# python是引用传递(地址传递)
# 不可变类型不会改变原件
# 衬衫的价格是九磅十五便士,所以你选择[B]项,并在试卷上将其标出。
# 衬衫的价格是九磅十五便士
返回值
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 返回值
# return语句
# 使用场景:通过某个函数处理完数据后,想要拿到处理的结果
# 语法:
# def 函数名():
# 代码块
# return 数据
# 注意事项:
# 1.return语句之后的代码不会被执行
# 2.只能返回一次
# 3.如果想要返回多个数据,可以将这些数据包装成一个整体(列表、元组、集合)返回
from datetime import datetime
def function(a, b, c):
Time3 = b - a
Time4 = c - a
return [Time3, Time4]
Time0 = datetime.now()
Time1 = datetime(2021, 1, 12, 23, 59, 59)
Time2 = datetime(2020, 9, 30, 23, 59, 59)
res0 = function(Time0, Time1, Time2)[0]
res1 = function(Time0, Time1, Time2)[1]
print('当前距离国庆节还有{},距离春节还有{}。'.format(res0, res1))
# 当前距离国庆节还有315 days, 3:02:42.690698,距离春节还有211 days, 3:02:42.690698。
函数的使用描述
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 函数的使用描述
# 使用场景:编写第三方函数时,为了方便他人的使用,需要描述清楚所写函数的功能及使用方式等信息
# 定义格式:
# def 函数名():
# """
# 描述内容
# """
# 代码块
# 查看函数使用文档:help(函数名)
# 函数描述需要描述清楚的信息:
# 函数的功能
# 参数:含义,类型,是否可以省略,默认值
# 返回值:含义,类型
from datetime import datetime
def function(a, b, c):
"""帮助计算b与a,c与a的时间差
:param a:时间值1,datetime.datetime类型,不可选,没有默认值
:param b:时间值2,datetime.datetime类型,不可选,没有默认值
:param c:时间值3,datetime.datetime类型,不可选,没有默认值
:return:返回的值是计算b - a,c - a的结果,列表:[b - a, c - a]
"""
Time3 = b - a
Time4 = c - a
return [Time3, Time4]
help(FUnction)
# Help on Function Function in module __main__:
#
# Function(a, b, c)
# 帮助计算b与a,c与a的时间差
# :param a:时间值1,datetime.datetime类型,不可选,没有默认值
# :param b:时间值2,datetime.datetime类型,不可选,没有默认值
# :param c:时间值3,datetime.datetime类型,不可选,没有默认值
# :return:返回的值是计算b - a,c - a的结果,列表:[b - a, c - a]
偏函数
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 偏函数
# 使用场景:写一个参数比较多的函数的时候,有些函数在某些场景是一个固定值,为了简化使用,就可以创建一个新的函数,指定我
# 们要使用的函数的某个参数为某个固定的值,这个新函数就是偏函数
# 语法:
# 方式一:自己写一个
def Function0(a='磅', b=9, c=15, d='B'):
print('{}的价格为{}磅{}便士,所以你选择[{}]项,并在试卷上将其标出。'.format(a, b, c, d))
def newFunction(a, b, c): # 偏函数
Function0(a, b, c)
newFunction('书', 20, 15)
# 书的价格为20磅15便士,所以你选择[B]项,并在试卷上将其标出。
# 方式二:借助Functions模块中的partial()函数
# 语法:
# import Functions
# newFunction = Functions.partial
import functools
def Function1(a='衬衫', b=9, c=15, d='B'):
print('{}的价格为{}磅{}便士,所以你选择[{}]项,并在试卷上将其标出。'.format(a, b, c, d))
newFunction = functools.partial(Function1, d='B')
newFunction('书', 20, 15)
# 书的价格为20磅15便士,所以你选择[B]项,并在试卷上将其标出。
高阶函数
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 高阶函数
# 概念:当一个函数的参数接收的是另一个函数时,把这个函数称为高阶函数
# 例如:sorted(iterable, key, reverse)
List = [{'name': 'Jack', 'age': 14, 'address': "S54, 176E"}, {'name': 'Lisa', 'age': 15, 'address': '18N, 153W'}, {"name": 'Alice', 'age': 18, 'address': '14S, 11E'}]
def Function(x):
return x['age']
print(sorted(List, key=Function, reverse=True))
# [{'name': 'Alice', 'age': 18, 'address': '14S, 11E'}, {'name': 'Lisa', 'age': 15, 'address': '18N, 153W'}, {'name': 'Jack', 'age': 14, 'address': 'S54, 176E'}]
# 动态的计算数值
def Function(num0, num1, operator):
res = operator(num0, num1) # operator收到赋值operatorAnd,调用函数operatorAnd(),并将num0, num1的值传递到operatorAnd()中
print(res)
def operatorAnd(a, b):
return a + b
def operatorSubtract(a, b):
return a - b
def operatorMultiply(a, b):
return a * b
def operatorExcept(a, b):
return a / b
Function(4, 6, operatorAnd) # 此处将4, 6, operatorAnd分别赋值给Function中的num0, num1, operator
# 10
返回函数
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 返回函数
# 概念:指函数内部,返回的函数是另一个函数,把这样的操作称为“返回函数”
def Function0(operator): # 此处operator收到值后进行判断
def FunctionAnd(num0, num1, num2):
return num0 + num1 + num2
def FunctionSubtract(num0, num1, num2):
return num0 - num1 - num2
def FunctionMultiply(num0, num1, num2):
return num0 * num1 * num2
def FunctionExcept(num0, num1, num2):
return num0 / num1 / num2
if operator == '+': # 通过判断决定调用哪个函数
return FunctionAnd
elif operator == '-':
return FunctionSubtract
elif operator == '*':
return FunctionMultiply
elif operator == '/':
return FunctionExcept
operators = ['+', '-', "*", '/']
for operator in operators:
res0 = Function0(operator) # 此处调用Function0()函数,并将接收到的operator的值传入
res1 = res0(15, 16, 17) # 此处调用满足条件的函数,并将值传入
print(res1, end=' ')
# 48 -18 4080 0.05514705882352941
匿名函数
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 匿名函数
# 概念:又称lambda函数
# 语法:lambda 参数1, 参数2, ···: 表达式
# 注意:只能写一个表达式,不能return;表达式的结果就是返回值
Function = lambda x, y: pow(x, y)
print(Function(5, 6))
# 15625
闭包
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 闭包
# 概念:在函数嵌套的前提下,内层函数引用外层函数的变量(包括参数),外层函数又将内层函数当作返回值进行返回。即内层函数加所引用的外层变量,称为闭包
# 应用场景:外层函数根据不同的参数来生成不同作用功能的函数
# 案例:根据不同的配置,进行两个数值的计算
def Caculator(num0, num1, operator): # 2.收到两次参数值,并未调用暂存 # 4.将res1的参数值传递给Caculating()
def Caculating():
res0 = eval('{}{}{}'.format(num0, operator, num1)) # 收到Caculator()传入的值,并计算
print(res0)
return Caculating # 将def Caculating()返回给res1以及res2
res1 = Caculator(12, 13, '+') # 1.将函数Caculator()当作参数传递给res1并执行,此处res1变成函数类型,不调用则不会产生作用
res2 = Caculator(68, 85, '*') # 1.将函数Caculator()当作参数传递给res2并执行,此处res2变成函数类型,不调用则不会产生作用
res1() # 3.调用函数res1,即调用Caculating(),并将参数值激活Caculator()中的参数值
print(type(res1), type(res2))
# 25
# <class 'function'> <class 'function'>
# 注意事项:
# 1.闭包中如果要修改引用的外部变量,需要使用nonlocal 变量 声明,否则会被当作闭包内新定义的变量
def Caculator(num0, num1, operator):
def Caculating():
num1 = 996
res0 = eval('{}{}{}'.format(num0, operator, num1))
return res0
print(num1) # 获取num1没有被调用前的值
Caculating()
print(num1) # 如果Caculating()修改了num1的值,那么此时num1的值为996
return Caculating
res1 = Caculator(12, 13, '+')
res1()
# 13
# 13
def Caculator(num0, num1, operator):
def Caculating():
nonlocal num1
num1 = 996
res0 = eval('{}{}{}'.format(num0, operator, num1))
return res0
print(num1) # 获取num1没有被调用前的值
Caculating()
print(num1) # 如果Caculating()修改了num1的值,那么此时num1的值为996
return Caculating
res1 = Caculator(12, 13, '+')
res1()
# 13
# 996
# 闭包内引用了一个后期会发生变化的变量,一定要注意
def test0(): # 2.运行test0()函数
List = []
for i in range(1, 4): # 3.开始循环
def test1(num): # 4.运行函数test()1,未调用,跳过 # 6.以i为i开始运行
def inner(*args): # 7.运行函数inner(),未调用,跳过 # 13.函数被调用,开始运行
print(num) # 14输出num之前储存的值1
return inner # 8.返回inner
List.append(test1(i)) # 5.像列表添加test1(i),调用函数test1()并赋值参数i # 9.像列表添加inner(1),此时num赋值为1,并循环4-9
return List
newFunction = test0() # 1.此处将test0()函数当作变量赋值给newFunction,并调用 # 10.调用函数test0()完成,并将List的值赋给newFunction()
print(newFunction) # 11.此处打印newFunction()的值
newFunction[0]() # 12.调用newFunction中的第一个函数 # 15.调用结束,返回
newFunction[1]() # 16.调用newFunction中的第二个函数,并重复13、14并返回
newFunction[2]() # 1调用newFunction中的第三个函数,重复13、14并返回,结束运行
# [<function test0.<locals>.test1.<locals>.inner at 0x00000196CB39B0D0>, <function test0.<locals>.test1.<locals>.inner at 0x00000196CB39B040>, <function test0.<locals>.test1.<locals>.inner at 0x00000196CB39B160>]
# 1
# 2
# 3
装饰器
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 装饰器
# 作用:在函数名和函数体不改变的前提下,给函数附加一些代码
# 开放封闭原则:
# 1.写好的代码尽量不要修改
# 2.如果想要增加功能,在原先代码的基础上单独进行扩展
# 单一职责:同开放封闭原则
# 语法:
# 注意:
# 装饰器的执行时间:立即执行
# 装饰器的叠加:从上往下装饰,从下往上执行
# 对有参数的函数进行装饰:无论什么场景,保证函数调用参数个数一致,为了通用,可以采用不定长参数,结合拆包操作进行处理
# 需求:用户输入两个随机进制的数,计算两个数值的幂,如果结果>1e15,转换为十六进制数后再输出
num0, num1 = eval(input('请输入两个任意进制的数值(元组形式):'))
res = pow(int(num0), int(num1))
# 功能函数
def out0():
print(hex(res))
# 功能函数
def out1():
print(res)
# 逻辑区
if res > 1e15:
out0()
else:
out1()
# 请输入两个任意进制的数值(元组形式):(0b10111, 0b101110)
# 0x10f51d7b02a40949fd28043cf77861f67cc22296c35c6508c1c71
# 追加需求:同时打印用户输入的两个数值的十进制数
# 方法一:在功能函数内部添加打印代码
# 方法二:在逻辑区添加打印代码
num0, num1 = eval(input('请输入两个任意进制的数值(元组形式):'))
res = pow(int(num0), int(num1))
# 功能函数
def out0():
print(hex(res))
print(int(num0), int(num1))
# 功能函数
def out1():
print(res)
print(int(num0), int(num1))
# 逻辑区
if res > 1e15:
out0()
print(int(num0), int(num1))
else:
out1()
print(int(num0), int(num1))
# 请输入两个任意进制的数值(元组形式):(0b10111, 0b101110)
# 0x10f51d7b02a40949fd28043cf77861f67cc22296c35c6508c1c71
# 23 46
# 23 46
# 优化,减少代码冗余
# 建立新的函数并在逻辑区或者功能函数中调用
num0, num1 = eval(input('请输入两个任意进制的数值(元组形式):'))
res = pow(int(num0), int(num1))
def out2():
print(int(num0), int(num1))
# 功能函数
def out0():
print(hex(res))
out2()
# 功能函数
def out1():
print(res)
out2()
# 逻辑区
if res > 1e15:
out0()
out2()
else:
out1()
out2()
# 请输入两个任意进制的数值(元组形式):(0b10111, 0b101110)
# 0x10f51d7b02a40949fd28043cf77861f67cc22296c35c6508c1c71
# 23 46
# 23 46
# 追加需求:同时打印用户输入的两个数值的十进制数,同时满足单一职责或者开放封闭原则,即功能函数和逻辑区的代码不能变更
num0, num1 = eval(input('请输入两个任意进制的数值(元组形式):'))
res = pow(int(num0), int(num1))
def out2(func):
def out3():
print(int(num0), int(num1))
func()
return out3
# 功能函数
def out0():
print(hex(res))
# 功能函数
def out1():
print(res)
out0 = out2(out0)
out1 = out2(out1)
# 逻辑区
if res > 1e15:
out0()
else:
out1()
# 请输入两个任意进制的数值(元组形式):(0b10111, 0b101110)
# 23 46
# 0x10f51d7b02a40949fd28043cf77861f67cc22296c35c6508c1c71
# 使用装饰器,进行优化
num0, num1 = eval(input('请输入你想计算的数组(请输入元组):'))
res = pow(int(num0), int(num1))
def out2(func):
def out3():
print(int(num0), int(num1))
func()
return out3
@out2
def out0():
x = hex(res)
print(x)
@out2
def out1():
print(res)
if res > 10000000:
out0()
else:
out1()
# 请输入你想计算的数组(请输入元组):(0b10111, 0b101110)
# 23 46
# 0x10f51d7b02a40949fd28043cf77861f67cc22296c35c6508c1c71
# 装饰器注意事项:
# 1.装饰器的执行时间:立即执行
def func1(func):
print('如果打印,则是装饰器直接执行')
def func2():
print('开始'.center(40, '-'))
func()
return func2
@ func1
def func0():
for i in range(10):
print(i, end=' ')
# func0()
# 如果打印,则是装饰器直接执行
# 2.装饰器的叠加:从上往下装饰,从下往上执行:装饰器从上往下写,但代码内部执行是从下至上,当输出仍然按照装饰器原顺序
def func1(func):
def func2():
print('开始'.center(40, '-'))
func()
return func2
def func3(func):
def func4():
print('start'.center(40, '-'))
func()
return func4
@ func1
@ func3
def func0():
for i in range(10):
print(i, end=' ')
func0()
# -------------------开始-------------------
# -----------------start------------------
# 0 1 2 3 4 5 6 7 8 9
# 3.对有参数的函数进行装饰:无论什么场景,保证函数调用参数个数一致,为了通用,可以采用不定长参数,结合拆包操作进行处理
def hint(func):
def content(*args):
print('听力测试试音时间')
func(*args)
return content
@ hint
def hearing_test(*args):
print('衬衫的价格是{}磅{}便士···'.format(*args))
hearing_test(156, 2655)
# 听力测试试音时间
# 衬衫的价格是156磅2655便士···
# 4.对有返回值的函数进行装饰:无论什么场景,要保持函数返回值一致
def hint(func):
def content(*args):
print('听力测试试音时间')
res = func(*args) # 此处使用res接收hearing_test()中return传过来的值
print(res)
return content
@ hint
def hearing_test(num0, num1):
print('衬衫的价格是{}磅{}便士···'.format(num0, num1))
return '衬衫的价格是{}磅{}便士···'.format(num0, num1)
hearing_test(156, 2655)
# 听力测试试音时间
# 衬衫的价格是156磅2655便士···
# 衬衫的价格是156磅2655便士···
# 通过@装饰器(参数)的方式,调用这个函数,并传递参数;并把返回的值,再次当作装饰器进行使用
# 先计算@后面的内容,并把这个内容当作装饰器
import datetime
nationalDay = datetime.datetime(2020, 10, 1, 0, 0, 0)
nowTime = datetime.datetime.today()
timeDifference = nationalDay - nowTime
def parameter(now_time):
def clock(func):
def now(*args):
print('当前时间是:{}'.format(now_time))
func(*args)
return now
return clock
@ parameter(nowTime)
def prompt(time_difference):
print("距离国庆节还有:{}".format(time_difference))
prompt(timeDifference)
# 当前时间是:2020-03-07 15:42:29.165723
# 距离国庆节还有:207 days, 8:17:30.834277
生成器
含义及定义
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 生成器
# 含义:是一个特殊的迭代器(迭代器的抽象层级更高)
# 迭代器的特性:
# 惰性计算数据,更节省内存,即需要用到时才会调用产生
# 能够记录状态,并使用next()函数,访问下一个状态
# 具有可迭代特性
# 注意:打造一个自己的迭代器较为困难,需要很多方法,因而使用生成器
# 生成器生成方式
# 1.生成器表达式:(表达式 for循环 if判断语句)
Generator = (pow(i, 2) for i in range(1, 10000000) if i % 4 == 0)
print(Generator)
print(next(Generator))
# <generator object <genexpr> at 0x00000197C2AB2900>
# 16
# 2.生成器函数
# 函数包括yield语句
# 这个函数执行的结果就是生成器
def generator():
print("检验输出是否会直接开始".center(20, '*'))
yield 0
print('隔断'.center(20, '-'))
yield 1
print('隔断'.center(20, '-'))
yield 2
print('隔断'.center(20, '-'))
yield 3
print('隔断'.center(20, '-'))
yield 4
print('隔断'.center(20, '-'))
yield 5
print('隔断'.center(20, '-'))
yield 6
print('隔断'.center(20, '-'))
yield 7
print('隔断'.center(20, '-'))
yield 8
print('隔断'.center(20, '-'))
res = generator()
print(res)
# <generator object generator at 0x000001AB68312900> # 该结果为将print(next(res))注释后的运行结果,验证生成器只有被调用才会开始使用,如果是普通的函数,print("检验输出是否会直接开始".center(20, '*'))会直接输出
print(next(res))
# <generator object generator at 0x000002AF31792900> # 取消注释后的运行结果
# ****检验输出是否会直接开始*****
# 0
访问方式
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 产生数据的方式:生成器具有可迭代特性
# next()函数 等价于 generator.__next__()
# 使用for循环
def generator():
print("检验输出是否会直接开始".center(20, '*'))
for i in range(0, 10000):
yield i
print('隔断'.center(20, '-'))
res = generator()
print(res)
for i in range(4):
print(res.__next__())
# <generator object generator at 0x00000261645F2900>
# ****检验输出是否会直接开始*****
# 0
# ---------隔断---------
# 1
# ---------隔断---------
# 2
# ---------隔断---------
# 3
# send()方法:
# send方法有一个参数,指定的是上一次被挂起的yield语句的返回值
# 相较于generator.__next__()能够给yield语句传值
# 第一次调用需要使用generator.send(None),因为第一次调用时没有被挂起的yield来接受参数,会报错(TypeError: can't send non-None value to a just-started generator)
def generator():
print("检验输出是否会直接开始".center(20, '*'))
for num in range(0, 10000):
accept_parameter = yield num
print(accept_parameter)
print('隔断'.center(20, '-'))
res = generator()
print(res)
for i in range(4):
if i == 0:
res.send(None)
else:
res.send(123)
# <generator object generator at 0x0000023C7AF62900>
# ****检验输出是否会直接开始*****
# 123
# ---------隔断---------
# 123
# ---------隔断---------
# 123
# ---------隔断---------
关闭生成器
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 关闭生成器
# 语法:generator.close()
# 注意:如果继续掉用生成器会报错(StopIteration)
def generator():
print("检验输出是否会直接开始".center(20, '*'))
for num in range(0, 10000):
accept_parameter = yield num
print(accept_parameter)
print('隔断'.center(20, '-'))
res = generator()
print(res)
for i in range(4):
if i == 0:
res.send(None)
elif i == 3:
res.close()
else:
res.send('可以使用')
# <generator object generator at 0x000001FF2B3E2900>
# ****检验输出是否会直接开始*****
# 可以使用
# ---------隔断---------
# 可以使用
# ---------隔断---------
注意事项
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 注意:
# 使用for循环遍历生成器可以输出所有值,即最后一个yield语句后的代码也会被执行,而不会被阻断
def generator():
print("检验输出是否会直接开始".center(20, '*'))
for num in range(0, 4):
yield num
print('隔断'.center(20, '-'))
res = generator()
print(res)
for i in res:
print(i)
# <generator object generator at 0x0000029349902900>
# ****检验输出是否会直接开始*****
# 0
# ---------隔断---------
# 1
# ---------隔断---------
# 2
# ---------隔断---------
# 3
# ---------隔断---------
# 生成器中碰到return语句会立即停止(在函数中return后面的语句不会执行)
def generator():
print("检验输出是否会直接开始".center(20, '*'))
yield 0
print('隔断'.center(20, '-'))
yield 1
return 123
print('隔断'.center(20, '-'))
yield 2
print('隔断'.center(20, '-'))
res = generator()
for i in res:
print(i)
# ****检验输出是否会直接开始*****
# 0
# ---------隔断---------
# 1
# 生成器只能遍历一次(生成器是迭代器的一种,具有迭代器的特性
递归函数
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 递归函数
# 概念:在一个函数的内部继续调用该函数;传递和回归
# 语法:
# 对于知道结果的数据,直接返回
# 不直接知道结果的数据,进行分解
def factorial(num):
if num == 1:
return 1
else:
return num * factorial(num - 1)
res = factorial(10)
print(res)
# 3628800
作用域
基本概念
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 作用域
# 基本概念:
# 变量的作用范围:python是静态作用域,也就是说在python中,变量的作用域来源于它位于代码中的位置,在不同的代码中可能有不同的命名空间
# 命名空间:是作用于的具体体现形式,不同的具体的操作范围
# python-LEGB:
# L:Local:函数的命名空间,作用范围:当前整个函数体范围
# E:Enclosing function tools:外部嵌套函数的命名空间,作用范围:闭包函数
# G:Global:全局命名空间,作用范围:当前命名空间
# B:Bulitin:内建模块命名空间,作用范围:所有文件
# 注意:python中没有块级作用域(代码块中的if while for后面的代码块
# LEGB规则:从调用变量的代码的位置开始向外查找, L-->E-->G-->B 顺序查找
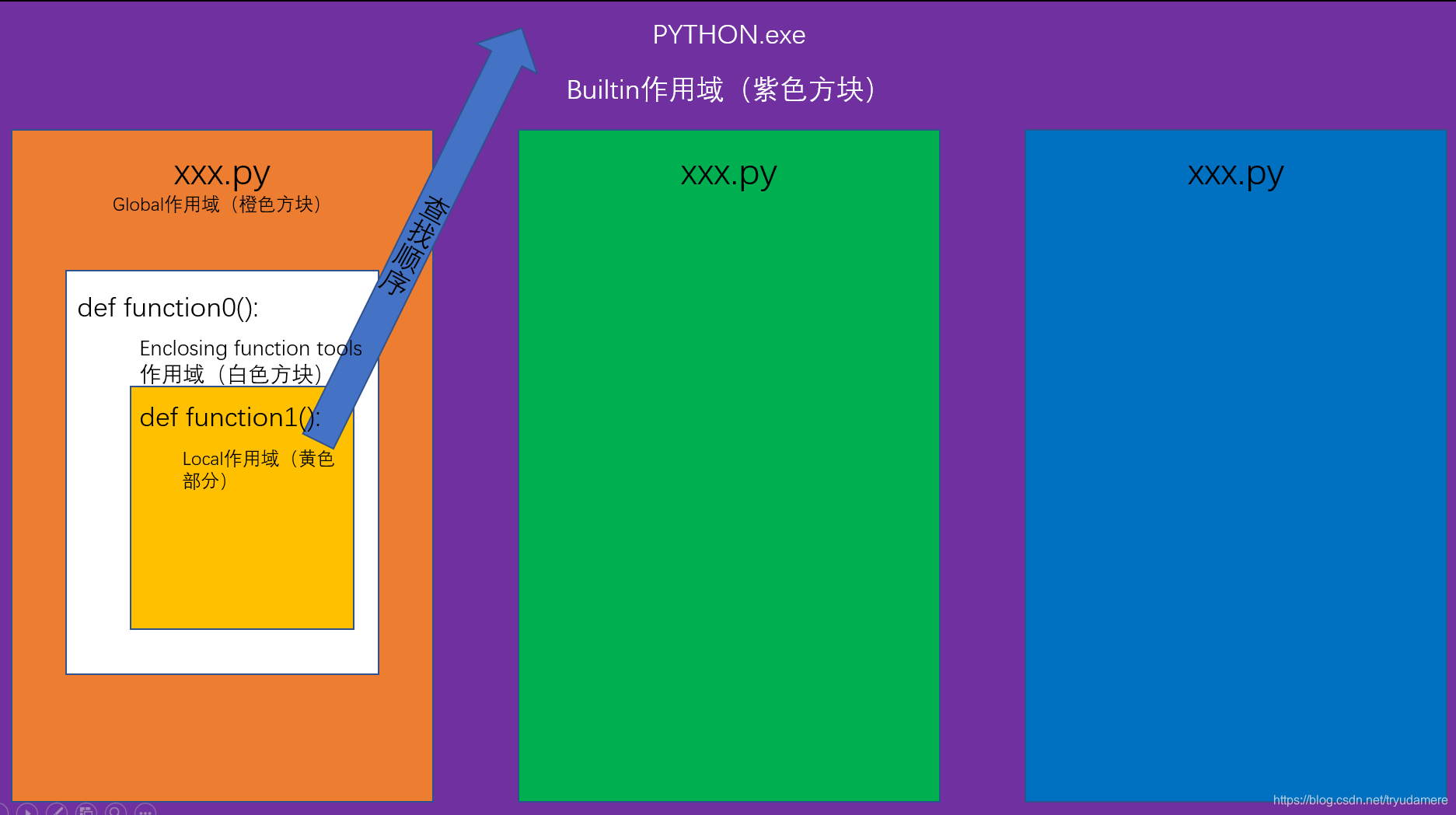
局部变量和全局变量:
# 基于命名空间的常见变量类型:
# 局部变量:
# 在一个函数内部定义的变量
# 作用域为函数内部
# 查看所有的局部变量:locals()
# 全局变量:
# 在函数外部,文件最外层定义的变量
# 作用域为整个文件
# 查看所有的全局变量:globals()
# 注意点:
# 访问原则:从内到外
# 结构规范:
# 全局变量:写在文件的最上部,使用g_xxx的格式
# 函数定义:在函数内部使用和修改全局变量或者外层函数变量需要使用global、nonlocal语句
# 全局变量和局部变量重名:
# 获取:就近原则
# 修改:global全局变量
g_num0 = 999
g_num1 = 1000
g_num2 = 1001
def function0():
l_num0 = 111
l_num1 = 112
g_num1 = 113
global g_num2
g_num2 +=g_num0
print(g_num1)
def function1():
nonlocal l_num1
l_num1 = 100
print(l_num0)
function1()
function0()
print(locals())
print(globals())
# 113
# 111
# {'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x000002650C130880>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': 'D:/时长两个月的python练习题/python基础/函数.py', '__cached__': None, 'g_num0': 999, 'g_num1': 1000, 'g_num2': 2000, 'function0': <function function0 at 0x000002650C371280>}
# {'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x000002650C130880>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': 'D:/时长两个月的python练习题/python基础/函数.py', '__cached__': None, 'g_num0': 999, 'g_num1': 1000, 'g_num2': 2000, 'function0': <function function0 at 0x000002650C371280>}
文件操作
概念
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 文件操作概念
# 文件介绍:
# 数据存放的容器
# 文件的作用:持久性的存储数据内容
# 文件组成:
# 文件名:如果是同级目录下,不允许有重名文件存在
# 扩展名:
# .jpeg、.avi、.doc、.xls、.html···
# 一般不同的文件名对应不同的文件格式。不同的文件格式,有着不同的储存方式,方便程序处理
# 文件内容:
# 文本文件:txt、doc、xls···
# 二进制文件:图片、音乐、视频
使用流程
打开
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 文件的使用流程
# 打开
# 语法:open(file, mode, encoding)
# 如果在操作txt文件下不指明encoding;默认使用GBK模式编辑
# mode:
# 'r'(默认模式):以只读方式打开文件;文件的指针放在文件的开头;如果文件不存在,会报错;该模式下写入内容会报错
# 'w':以只写的方式打开文件;文件指针放在文件的开头;写入的新内容时会删掉原有的旧内容;文件不存在会创造一个新文件;该模式下读取内容会报错
# 'a':以追加的模式(只写)打开文件,指针指向文件末尾;文件不存在时会创造一个新文件;该模式下读取内容会报错
# '增加b'(rb、wb、ab):以二进制形式进行操作文件写读;如果文件是二进制(图片、音频、视频),则选择此项
# '增加+'(r+、w+、a+、rb+、wb+、ab+):代表以读写模式打开
# r+ == r + w:
# 与'r'模式的区别:增加了写入的操作
# 与'w'模式的区别:
# 如果只是进行写的操作,不是先删除再写入,而是部分替换
# 如果先进行读的操作,再进行写的操作,新增内容会增加在原内容的后面,而不会覆盖原内容,因为读的操作将文件的指针放到了原内容的末尾
# w+ == w + r:
# 与'w'模式的区别:增加了读取的操作,如果只是读取会清空原内容并返回空字符串
# 与'r'模式的区别:
# 如果只是进行读取,会清空原内容,返回值为空字符串
# 如果进行先写入,再读取的操作,不会清空写入的内容,因为写入后将文件的指针移到文件的末尾,使得读取操作没有可清空的内容
# a+ == a + r:文件指针位于文件末尾
# 与'a'模式的区别:增加了读取的操作,但需要使用file.seek(0)将文件指针调到文首再读取;如果原内容是奇数行,会先换行再写入
# 与'w'模式的区别:写入不会清除原内容
# rb+、wb+、ab+:暂没发现区别
定位和读取
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 读写:
# 定位:
# 语法:file.seek(offset, whence)
# 参数:offset:偏移量,指针没有位于末尾时为正数,指针位于末尾时为负数,whence:值为0(开头,默认),1(当前位置),2(文件末尾)
# 返回值:
# 注意:文本文件操作下(不带b)whence值只能赋0,如果想要写1 / 2,必须在二进制文件操作模式下(带b)
# 查看当前指针位置:
# 语法:file.tell()
# 返回值:当前指针的位置,int类型
# 注意:指针计数是从0开始的,而不是1
File = open('123.txt', 'w+')
File.write('abcdefghijklmnopqrstuvwxyz')
File.seek(3)
print(File.tell())
content = File.read()
print(content)
print(File.tell())
# 3
# defghijklmnopqrstuvwxyz
# 26
# 读
# 语法:file.read(n)
# 作用:获取指针后的内容
# 参数:n:不指定时为len(file.read()),指定时为从指针位置向后取n个
# 返回值:读取的内容
File = open('123.txt', 'r') # 此处的File为上面代码建立的
res = File.read()
print(res)
File.seek(3)
print(File.read(10))
File.readline(3)
# abcdefghijklmnopqrstuvwxyz
# defghijklm
# 语法:file.readline([limit])
# 作用:读取每行的内容
# 参数:limit:限制输出的每行的个数,原文中一行没打印完的的留作下次单独打印
# 返回值:读取的内容
File = open('letter.txt', 'w+')
File.write('aaaa\nbbbb\ncccc\ndddd\neeee\nffff\ngggg\n')
File.seek(0)
while True:
res = File.readline(3)
if res != '':
print(res)
print('隔断'.center(30, '*'))
else:
break
# aaa
# **************隔断**************
# a
#
# **************隔断**************
# bbb
# **************隔断**************
# b
#
# **************隔断**************
# ccc
# **************隔断**************
# c
#
# **************隔断**************
# ddd
# **************隔断**************
# d
#
# **************隔断**************
# eee
# **************隔断**************
# e
#
# **************隔断**************
# fff
# **************隔断**************
# f
#
# **************隔断**************
# ggg
# **************隔断**************
# g
#
# **************隔断**************
# 语法:file.readlines(hint)
# 作用:读取原文并将原文当作列表返回
# 参数:hint:int类型,最多读取的行数;等价于math.ceil(hint / n),n为每行字符的个数,假设每行个数相等
File = open('letter.txt', 'w+')
File.write('aaaa\nbbbb\ncccc\ndddd\neeee\nffff\ngggg\n')
File.seek(0)
res = File.readlines(28)
print(res)
# ['aaaa\n', 'bbbb\n', 'cccc\n', 'dddd\n', 'eeee\n', 'ffff\n']
for循环
```python
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# for循环
# 作用:直接遍历文件;或者readlines()函数形成的行列表
# 返回值:返回的是每行的内容
File = open('定风波_苏轼.txt', 'w+', encoding='utf-8')
File.write('莫听穿林打叶声,何妨吟啸且徐行。\n竹杖芒鞋轻胜马,谁怕? 一蓑烟雨任平生。\n料峭春风吹酒醒,微冷,山头斜照却相迎。\n回首向来萧瑟处,归去,也无风雨也无晴。')
File.seek(0)
for line in File:
for character in line:
print(character, end=' ')
print('\n')
File.seek(0)
content = File.readlines()
for Character in content:
print(Character)
# 莫 听 穿 林 打 叶 声 , 何 妨 吟 啸 且 徐 行 。
# 竹 杖 芒 鞋 轻 胜 马 , 谁 怕 ? 一 蓑 烟 雨 任 平 生 。 # 产生空格的原因:文件读取时每读完一行会自动增加一个空行,为了解决这个现象将print()函数的参数end设值为' ' ,原本自动增加空行的print('\n', '\n')函数的end参数值也被改为' ',所以会在除第一行以外的语句句首加上end的值
# 料 峭 春 风 吹 酒 醒 , 微 冷 , 山 头 斜 照 却 相 迎 。
# 回 首 向 来 萧 瑟 处 , 归 去 , 也 无 风 雨 也 无 晴 。
# 莫听穿林打叶声,何妨吟啸且徐行。
# 竹杖芒鞋轻胜马,谁怕? 一蓑烟雨任平生。
# 料峭春风吹酒醒,微冷,山头斜照却相迎。
# 回首向来萧瑟处,归去,也无风雨也无晴。
读取文件的方法选择
```python
# 注意:
# 一般文件比较大的时候,使用readline()方法,因为readline()按行加载节省内存,但相较于其他两种方法性能较低
# 其他两个方法可一次读取所有文件,虽然占用内存高,但性能好
判断文件是否可读
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# file.readable()
# 作用:判断当前文件是否可读
# 返回值:bool类型
File = open('蜀道难_李白.txt', 'w+', encoding='utf-8')
File.write('噫吁嚱,危乎高哉!\n蜀道之难,难于上青天!\n蚕丛及鱼凫,开国何茫然!\n尔来四万八千岁,不与秦塞通人烟。\n西当太白有鸟道,可以横绝峨眉巅。\n地崩山摧壮士死,然后天梯石栈相钩连。\n上有六龙回日之高标,下有冲波逆折之回川。\n黄鹤之飞尚不得过,猿猱欲度愁攀援。(攀援 一作:攀缘)\n青泥何盘盘,百步九折萦岩峦。\n扪参历井仰胁息,以手抚膺坐长叹。\n问君西游何时还?畏途巉岩不可攀。\n但见悲鸟号古木,雄飞雌从绕林间。\n又闻子规啼夜月,愁空山。\n蜀道之难,难于上青天,使人听此凋朱颜!\n连峰去天不盈尺,枯松倒挂倚绝壁。\n飞湍瀑流争喧豗,砯崖转石万壑雷。\n其险也如此,嗟尔远道之人胡为乎来哉!(也如此 一作:也若此)\n剑阁峥嵘而崔嵬,一夫当关,万夫莫开。\n所守或匪亲,化为狼与豺。\n朝避猛虎,夕避长蛇,\n磨牙吮血,杀人如麻。\n锦城虽云乐,不如早还家。\n蜀道之难,难于上青天,侧身西望长咨嗟!')
res = File.readable()
print(res)
# True
写入与判断是否可写入
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# file.write() / file.writable
# 作用:写入内容和判断文件是否可读
# write()返回写入内容的长度;writable()返回bool值
File = open('春望_杜甫.txt', 'a')
if File.writable():
print(type(File.writable()))
res = File.write('国破山河在,城春草木深。\n感时花溅泪,恨别鸟惊心。\n烽火连三月,家书抵万金。\n白头搔更短,浑欲不胜簪。')
print(res)
File.close()
# <class 'bool'>
# 51
关闭文件和刷新缓冲区
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 关闭文件和刷新缓冲区
# file.close() / file.flush()
# 作用:close()关闭文件,flush()刷新缓冲区数据到磁盘
# 为什么关闭文件:释放系统资源;立即清空缓冲区的数据到磁盘
os模块
重命名
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 重命名
# 语法:
# import os
# os.rename(src, dst) / os.renames(old, new)
# 作用:
# rename():修改单级目录/文件名称 / renames():修改多级目录/文件名称
# 参数:
# rename():src:想要修改的文件名,dst:想要修改成的文件名
# renames():old:想要修改的文件名或者目录名,new:想要修改成的文件名或者目录名
删除
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 删除
# 语法:
# os.remove(path) / os.rmdir(path) / os.removedirs(name)
# 参数:path(1):文件路径,path(2):目录路径,name:目录路径
# 注意:
# 如果文件不存在会报错(FileNotFoundError)
# rmdir()和removedirs()删除的文件如果不为空,会报错(FileNotFoundError)
# rmdir()不能递归删除目录
# removedirs()可以递归删除目录
创建文件夹
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 创建文件夹
# 语法:
# import os
# os.mkdir(path[, mode])
# 参数:
# path:文件夹路径及名称
# mode:数字权限
# 默认为0o777 ==> 0o4+2+1 4+2+! 4+2+1
# 数字权限:
# 文件拥有者、同组用户、其他用户:
# 读(r):4
# 写(w):2
# 可执行:1
# 注意:
# 不能递归创建,否则会报错
# 不能创建同名文件夹,否则会报错
获取当前目录
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 语法:
# import os
# os.getcwd()
# 返回值:字符串
改变默认目录
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 改变默认目录
# 语法:
# import os
# os.chdir(path)
# 参数:path:想要改变成的路径
# 返回值:字符串
获取目录列表内容
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 获取目录内容列表
# 语法:
# import os
# os.listdir(path)
# 参数:path:想要获取的文件路径。默认为:'./'获取当前目录的所有内容;'../'获取上一级目录的内容
# 返回值:列表
# 注意:只能返回一级

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









