







电脑经常卡顿,我们很自然地会想到换一台配置更高的电脑。对企业而言也一样,例如当网站用户增加,并发就会增加,服务器资源(CPU、内存、磁盘)不够,那就换一台配置更高的服务器。然而有一个现实问题摆在面前,单台服务器的配置终究是有上限的。
集群的出现
不得不承认,有些人生来就是为改变世界、推动技术进步而生的。
我们想象一下,一节电池的能量可能很小,维持手电筒的照明都很吃力。但是将上千甚至上万节电池组合在一起,就造就了现如今欣欣向荣的新能源汽车行业。
早在1967年,IBM的吉恩•阿姆达尔出版了并行处理的开创性论文阿姆达尔定律。第一个被设计成集群的生产系统是20世纪60年代中期的Burroughs B5700,它允许多达四台计算机(每个计算机都有一个或两个处理器)紧密连接到一个公共磁盘存储系统,以平衡工作负载。与标准的多处理器系统不同,每台计算机都可以在不中断整体运行的情况下重新启动。
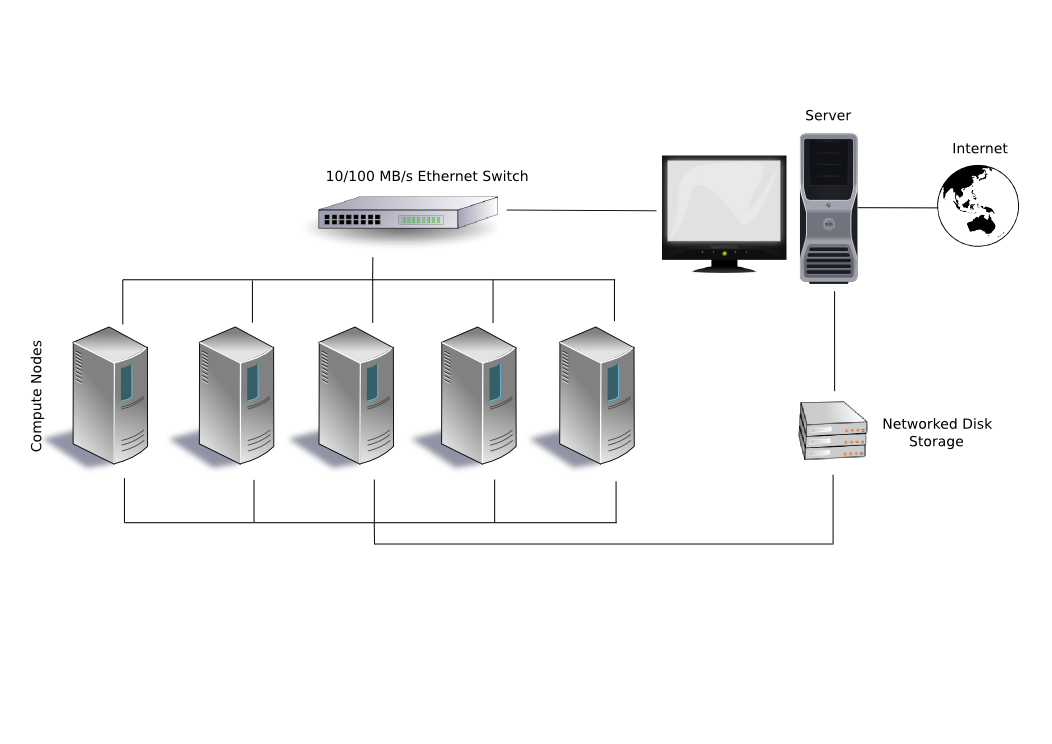
此时的集群适用于任务数多,但是每个任务消耗的资源少,只要把大量的任务平均分配到更多服务器上就可以。需要注意的是,集群是共享存储系统。
早期集群的问题
早期集群突破了单机性能的限制,解决了并发问题。但是随着互联网和移动互联网等技术的崛起,又有了新的挑战。
- 共享存储
集群共享存储,也就是只有一块物理存储设备。如果硬件坏了怎么办?有人会说可以做备份。但是多久备份一次,恢复备份需要多久时间,恢复期间服务不可用怎么办。
- 大任务处理
小任务比较多可以分散处理,但是如果一个任务本身就需要消耗很多计算资源呢?比如对1T的数据进行计数计算。这个任务不管落在哪台机器上都是灾难性的。
针对上述问题,该如何解决呢?
进阶
单台高配服务非常贵,那么有没有一种可能,将廉价的服务器组合起来使用,不仅可以平衡大量任务,还可以处理单个大任务,更重要的是再也不用担心数据磁盘突然坏掉。这些看似无法解决的问题,催生了分布式计算和分布式存储的发展。想要继续学习大数据相关技术,可以关注公众号:遇码,回复学习地图,获取全部教程。


















 461
461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









